 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFact4ac at the Financial Misinformation Detection Challenge Task: Reference-Free Financial Misinformation Detection via Fine-Tuning and Few-Shot Prompting of Large Language Models
Apr 16, 2026The proliferation of financial misinformation poses a severe threat to market stability and investor trust, misleading market behavior and creating critical information asymmetry. Detecting such misleading narratives is inherently challenging, particularly in real-world scenarios where external evidence or supplementary references for cross-verification are strictly unavailable. This paper presents our winning methodology for the "Reference-Free Financial Misinformation Detection" shared task. Built upon the recently proposed RFC-BENCH framework (Jiang et al. 2026), this task challenges models to determine the veracity of financial claims by relying solely on internal semantic understanding and contextual consistency, rather than external fact-checking. To address this formidable evaluation setup, we propose a comprehensive framework that capitalizes on the reasoning capabilities of state-of-the-art Large Language Models (LLMs). Our approach systematically integrates in-context learning, specifically zero-shot and few-shot prompting strategies, with Parameter-Efficient Fine-Tuning (PEFT) via Low-Rank Adaptation (LoRA) to optimally align the models with the subtle linguistic cues of financial manipulation. Our proposed system demonstrated superior efficacy, successfully securing the first-place ranking on both official leaderboards. Specifically, we achieved an accuracy of 95.4% on the public test set and 96.3% on the private test set, highlighting the robustness of our method and contributing to the acceleration of context-aware misinformation detection in financial Natural Language Processing. Our models (14B and 32B) are available at https://huggingface.co/KaiNKaiho.
Improving Robustness of Retrieval Augmented Translation via Shuffling of Suggestions
Oct 11, 2022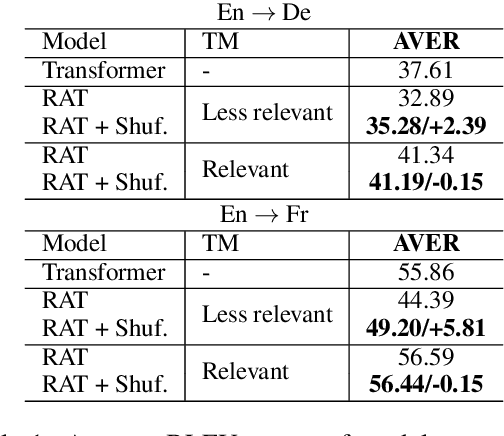

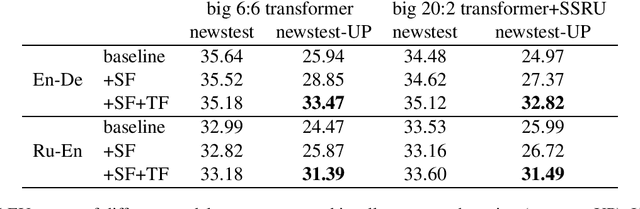
Several recent studies have reported dramatic performance improvements in neural machine translation (NMT) by augmenting translation at inference time with fuzzy-matches retrieved from a translation memory (TM). However, these studies all operate under the assumption that the TMs available at test time are highly relevant to the testset. We demonstrate that for existing retrieval augmented translation methods, using a TM with a domain mismatch to the test set can result in substantially worse performance compared to not using a TM at all. We propose a simple method to expose fuzzy-match NMT systems during training and show that it results in a system that is much more tolerant (regaining up to 5.8 BLEU) to inference with TMs with domain mismatch. Also, the model is still competitive to the baseline when fed with suggestions from relevant TMs.
Improving Retrieval Augmented Neural Machine Translation by Controlling Source and Fuzzy-Match Interactions
Oct 10, 2022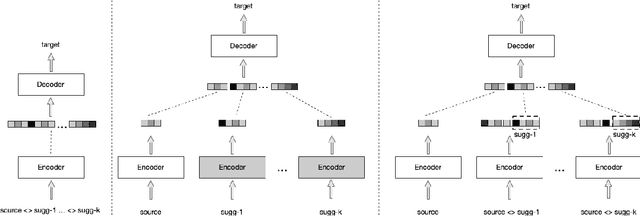
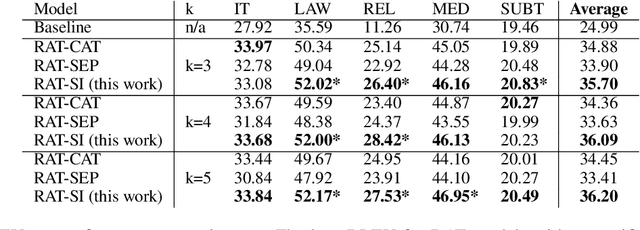
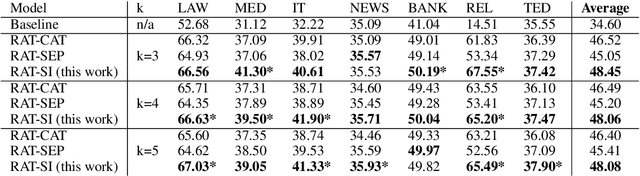
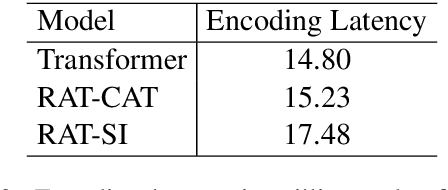
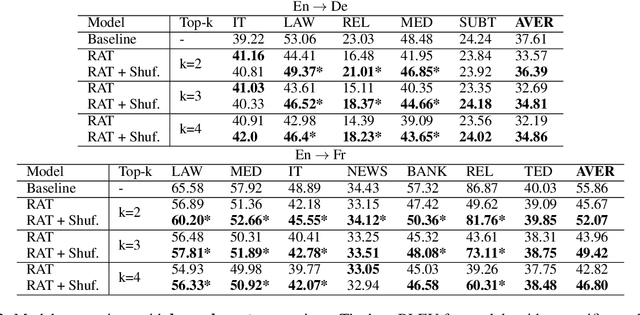
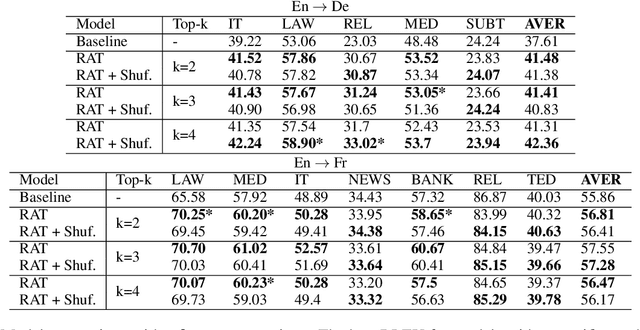
We explore zero-shot adaptation, where a general-domain model has access to customer or domain specific parallel data at inference time, but not during training. We build on the idea of Retrieval Augmented Translation (RAT) where top-k in-domain fuzzy matches are found for the source sentence, and target-language translations of those fuzzy-matched sentences are provided to the translation model at inference time. We propose a novel architecture to control interactions between a source sentence and the top-k fuzzy target-language matches, and compare it to architectures from prior work. We conduct experiments in two language pairs (En-De and En-Fr) by training models on WMT data and testing them with five and seven multi-domain datasets, respectively. Our approach consistently outperforms the alternative architectures, improving BLEU across language pair, domain, and number k of fuzzy matches.
Sockeye 3: Fast Neural Machine Translation with PyTorch
Jul 12, 2022
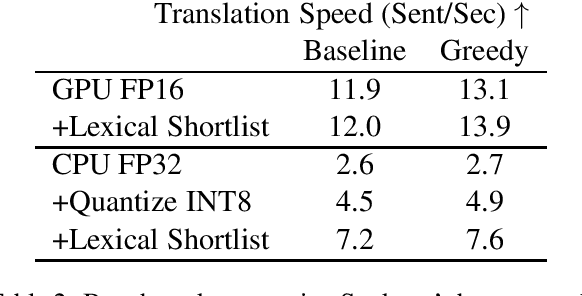

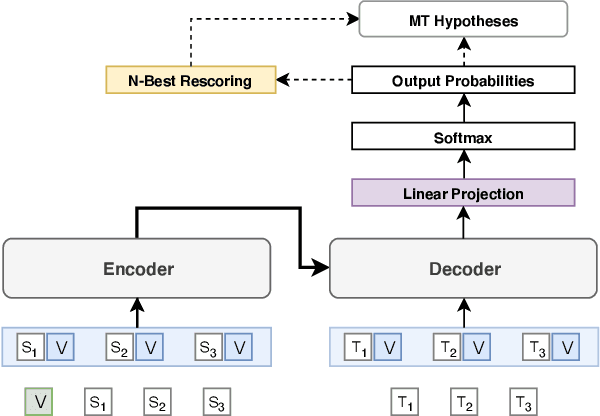
Sockeye 3 is the latest version of the Sockeye toolkit for Neural Machine Translation (NMT). Now based on PyTorch, Sockeye 3 provides faster model implementations and more advanced features with a further streamlined codebase. This enables broader experimentation with faster iteration, efficient training of stronger and faster models, and the flexibility to move new ideas quickly from research to production. When running comparable models, Sockeye 3 is up to 126% faster than other PyTorch implementations on GPUs and up to 292% faster on CPUs. Sockeye 3 is open source software released under the Apache 2.0 license.
Machine Translation Verbosity Control for Automatic Dubbing
Oct 08, 2021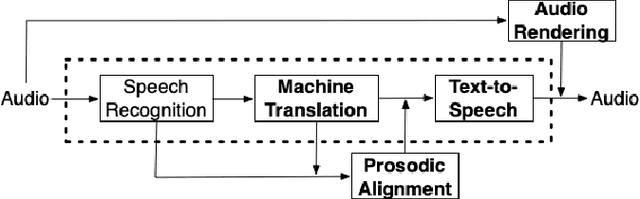
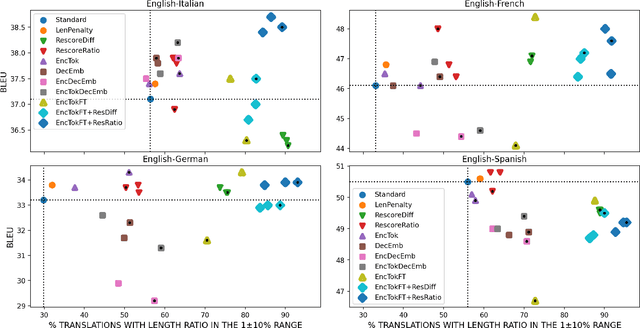
Automatic dubbing aims at seamlessly replacing the speech in a video document with synthetic speech in a different language. The task implies many challenges, one of which is generating translations that not only convey the original content, but also match the duration of the corresponding utterances. In this paper, we focus on the problem of controlling the verbosity of machine translation output, so that subsequent steps of our automatic dubbing pipeline can generate dubs of better quality. We propose new methods to control the verbosity of MT output and compare them against the state of the art with both intrinsic and extrinsic evaluations. For our experiments we use a public data set to dub English speeches into French, Italian, German and Spanish. Finally, we report extensive subjective tests that measure the impact of MT verbosity control on the final quality of dubbed video clips.