 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring the Knowledge Acquisition-Utilization Gap in Pretrained Language Models
May 24, 2023While pre-trained language models (PLMs) have shown evidence of acquiring vast amounts of knowledge, it remains unclear how much of this parametric knowledge is actually usable in performing downstream tasks. We propose a systematic framework to measure parametric knowledge utilization in PLMs. Our framework first extracts knowledge from a PLM's parameters and subsequently constructs a downstream task around this extracted knowledge. Performance on this task thus depends exclusively on utilizing the model's possessed knowledge, avoiding confounding factors like insufficient signal. As an instantiation, we study factual knowledge of PLMs and measure utilization across 125M to 13B parameter PLMs. We observe that: (1) PLMs exhibit two gaps - in acquired vs. utilized knowledge, (2) they show limited robustness in utilizing knowledge under distribution shifts, and (3) larger models close the acquired knowledge gap but the utilized knowledge gap remains. Overall, our study provides insights into PLMs' capabilities beyond their acquired knowledge.
Deep Learning on a Healthy Data Diet: Finding Important Examples for Fairness
Nov 25, 2022



Data-driven predictive solutions predominant in commercial applications tend to suffer from biases and stereotypes, which raises equity concerns. Prediction models may discover, use, or amplify spurious correlations based on gender or other protected personal characteristics, thus discriminating against marginalized groups. Mitigating gender bias has become an important research focus in natural language processing (NLP) and is an area where annotated corpora are available. Data augmentation reduces gender bias by adding counterfactual examples to the training dataset. In this work, we show that some of the examples in the augmented dataset can be not important or even harmful for fairness. We hence propose a general method for pruning both the factual and counterfactual examples to maximize the model's fairness as measured by the demographic parity, equality of opportunity, and equality of odds. The fairness achieved by our method surpasses that of data augmentation on three text classification datasets, using no more than half of the examples in the augmented dataset. Our experiments are conducted using models of varying sizes and pre-training settings.
Local Structure Matters Most in Most Languages
Nov 09, 2022



Many recent perturbation studies have found unintuitive results on what does and does not matter when performing Natural Language Understanding (NLU) tasks in English. Coding properties, such as the order of words, can often be removed through shuffling without impacting downstream performances. Such insight may be used to direct future research into English NLP models. As many improvements in multilingual settings consist of wholesale adaptation of English approaches, it is important to verify whether those studies replicate or not in multilingual settings. In this work, we replicate a study on the importance of local structure, and the relative unimportance of global structure, in a multilingual setting. We find that the phenomenon observed on the English language broadly translates to over 120 languages, with a few caveats.
Detecting Languages Unintelligible to Multilingual Models through Local Structure Probes
Nov 09, 2022



Providing better language tools for low-resource and endangered languages is imperative for equitable growth. Recent progress with massively multilingual pretrained models has proven surprisingly effective at performing zero-shot transfer to a wide variety of languages. However, this transfer is not universal, with many languages not currently understood by multilingual approaches. It is estimated that only 72 languages possess a "small set of labeled datasets" on which we could test a model's performance, the vast majority of languages not having the resources available to simply evaluate performances on. In this work, we attempt to clarify which languages do and do not currently benefit from such transfer. To that end, we develop a general approach that requires only unlabelled text to detect which languages are not well understood by a cross-lingual model. Our approach is derived from the hypothesis that if a model's understanding is insensitive to perturbations to text in a language, it is likely to have a limited understanding of that language. We construct a cross-lingual sentence similarity task to evaluate our approach empirically on 350, primarily low-resource, languages.
Demystifying Neural Language Models' Insensitivity to Word-Order
Jul 29, 2021



Recent research analyzing the sensitivity of natural language understanding models to word-order perturbations have shown that the state-of-the-art models in several language tasks may have a unique way to understand the text that could seldom be explained with conventional syntax and semantics. In this paper, we investigate the insensitivity of natural language models to word-order by quantifying perturbations and analysing their effect on neural models' performance on language understanding tasks in GLUE benchmark. Towards that end, we propose two metrics - the Direct Neighbour Displacement (DND) and the Index Displacement Count (IDC) - that score the local and global ordering of tokens in the perturbed texts and observe that perturbation functions found in prior literature affect only the global ordering while the local ordering remains relatively unperturbed. We propose perturbations at the granularity of sub-words and characters to study the correlation between DND, IDC and the performance of neural language models on natural language tasks. We find that neural language models - pretrained and non-pretrained Transformers, LSTMs, and Convolutional architectures - require local ordering more so than the global ordering of tokens. The proposed metrics and the suite of perturbations allow a systematic way to study the (in)sensitivity of neural language understanding models to varying degree of perturbations.
Memory Augmented Optimizers for Deep Learning
Jun 20, 2021
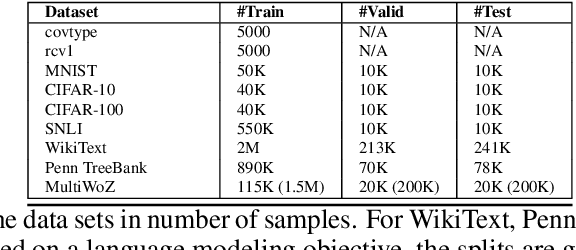
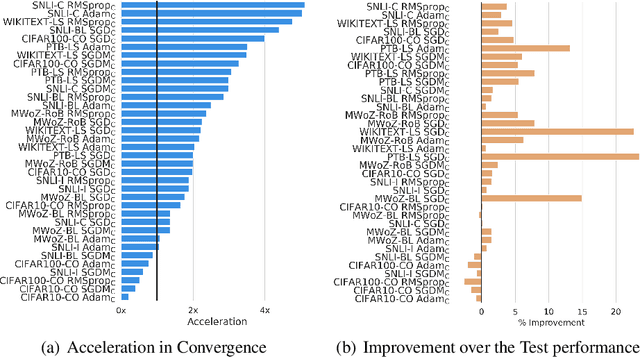
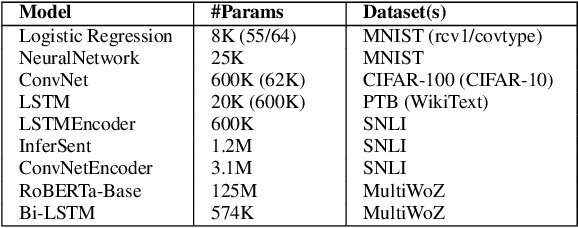
Popular approaches for minimizing loss in data-driven learning often involve an abstraction or an explicit retention of the history of gradients for efficient parameter updates. The aggregated history of gradients nudges the parameter updates in the right direction even when the gradients at any given step are not informative. Although the history of gradients summarized in meta-parameters or explicitly stored in memory has been shown effective in theory and practice, the question of whether $all$ or only a subset of the gradients in the history are sufficient in deciding the parameter updates remains unanswered. In this paper, we propose a framework of memory-augmented gradient descent optimizers that retain a limited view of their gradient history in their internal memory. Such optimizers scale well to large real-life datasets, and our experiments show that the memory augmented extensions of standard optimizers enjoy accelerated convergence and improved performance on a majority of computer vision and language tasks that we considered. Additionally, we prove that the proposed class of optimizers with fixed-size memory converge under assumptions of strong convexity, regardless of which gradients are selected or how they are linearly combined to form the update step.
Do Encoder Representations of Generative Dialogue Models Encode Sufficient Information about the Task ?
Jun 20, 2021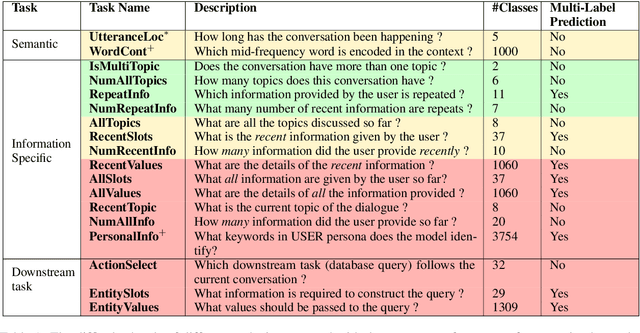
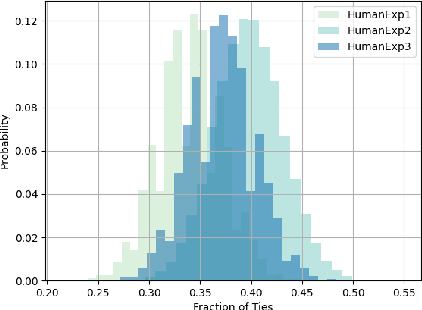
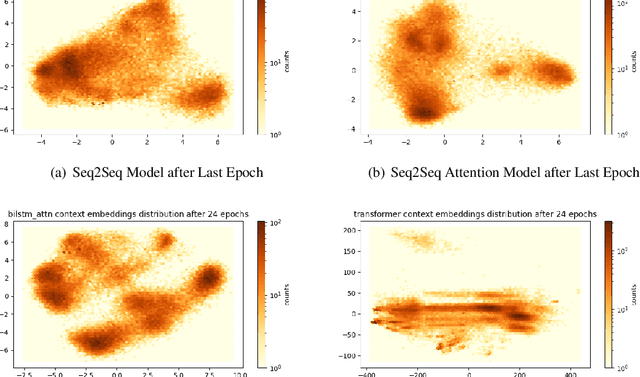
Predicting the next utterance in dialogue is contingent on encoding of users' input text to generate appropriate and relevant response in data-driven approaches. Although the semantic and syntactic quality of the language generated is evaluated, more often than not, the encoded representation of input is not evaluated. As the representation of the encoder is essential for predicting the appropriate response, evaluation of encoder representation is a challenging yet important problem. In this work, we showcase evaluating the text generated through human or automatic metrics is not sufficient to appropriately evaluate soundness of the language understanding of dialogue models and, to that end, propose a set of probe tasks to evaluate encoder representation of different language encoders commonly used in dialogue models. From experiments, we observe that some of the probe tasks are easier and some are harder for even sophisticated model architectures to learn. And, through experiments we observe that RNN based architectures have lower performance on automatic metrics on text generation than transformer model but perform better than the transformer model on the probe tasks indicating that RNNs might preserve task information better than the Transformers.
A Brief Study on the Effects of Training Generative Dialogue Models with a Semantic loss
Jun 20, 2021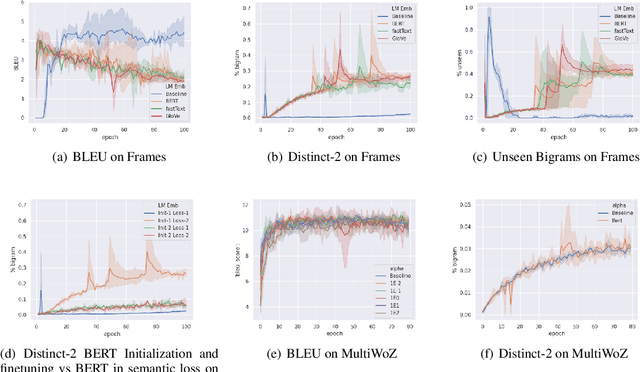
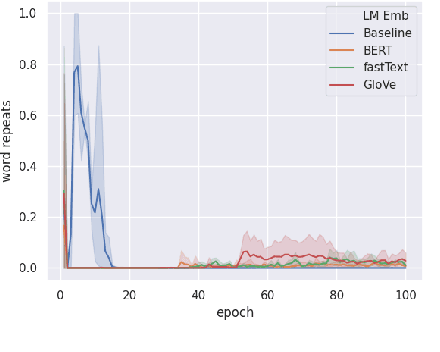

Neural models trained for next utterance generation in dialogue task learn to mimic the n-gram sequences in the training set with training objectives like negative log-likelihood (NLL) or cross-entropy. Such commonly used training objectives do not foster generating alternate responses to a context. But, the effects of minimizing an alternate training objective that fosters a model to generate alternate response and score it on semantic similarity has not been well studied. We hypothesize that a language generation model can improve on its diversity by learning to generate alternate text during training and minimizing a semantic loss as an auxiliary objective. We explore this idea on two different sized data sets on the task of next utterance generation in goal oriented dialogues. We make two observations (1) minimizing a semantic objective improved diversity in responses in the smaller data set (Frames) but only as-good-as minimizing the NLL in the larger data set (MultiWoZ) (2) large language model embeddings can be more useful as a semantic loss objective than as initialization for token embeddings.
Sometimes We Want Translationese
Apr 15, 2021
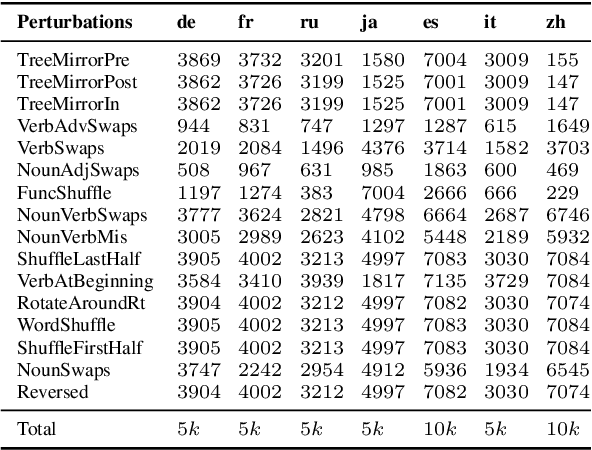

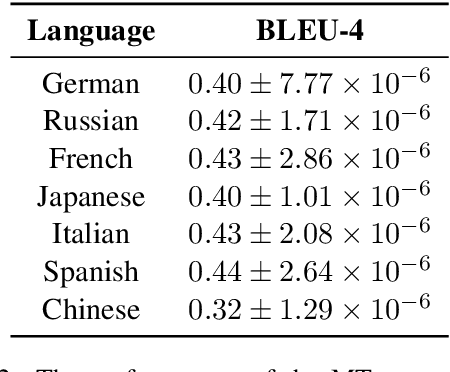
Rapid progress in Neural Machine Translation (NMT) systems over the last few years has been driven primarily towards improving translation quality, and as a secondary focus, improved robustness to input perturbations (e.g. spelling and grammatical mistakes). While performance and robustness are important objectives, by over-focusing on these, we risk overlooking other important properties. In this paper, we draw attention to the fact that for some applications, faithfulness to the original (input) text is important to preserve, even if it means introducing unusual language patterns in the (output) translation. We propose a simple, novel way to quantify whether an NMT system exhibits robustness and faithfulness, focusing on the case of word-order perturbations. We explore a suite of functions to perturb the word order of source sentences without deleting or injecting tokens, and measure the effects on the target side in terms of both robustness and faithfulness. Across several experimental conditions, we observe a strong tendency towards robustness rather than faithfulness. These results allow us to better understand the trade-off between faithfulness and robustness in NMT, and opens up the possibility of developing systems where users have more autonomy and control in selecting which property is best suited for their use case.
Unnatural Language Inference
Dec 30, 2020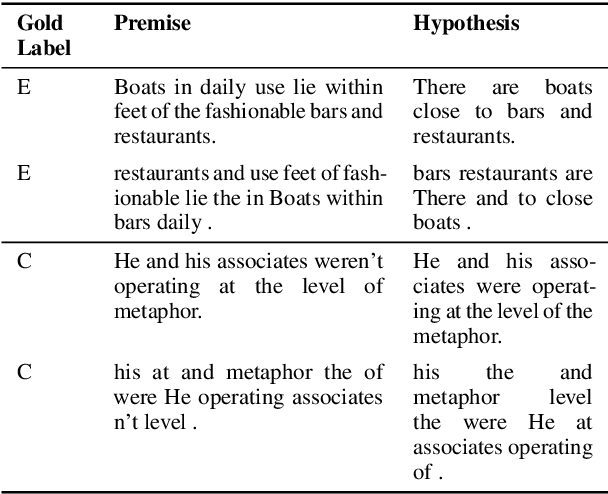
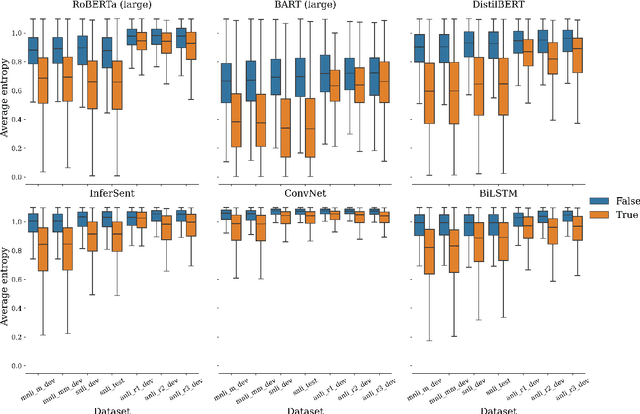
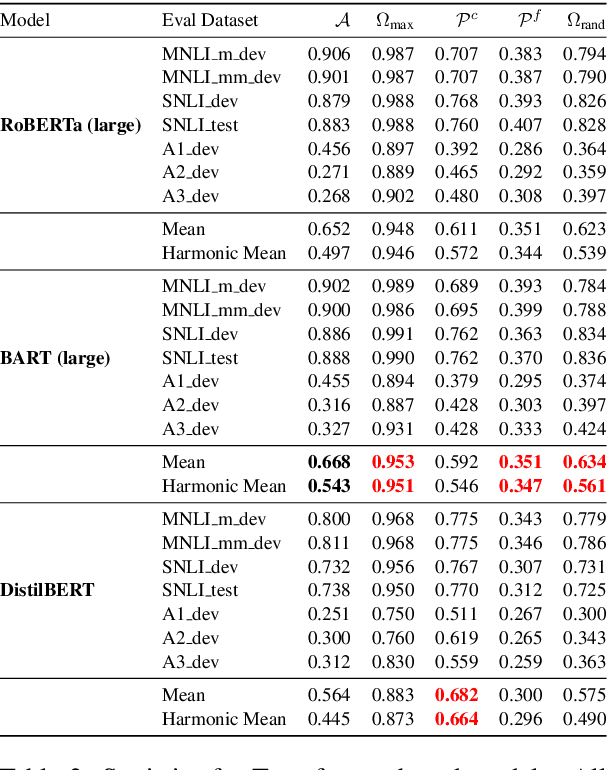
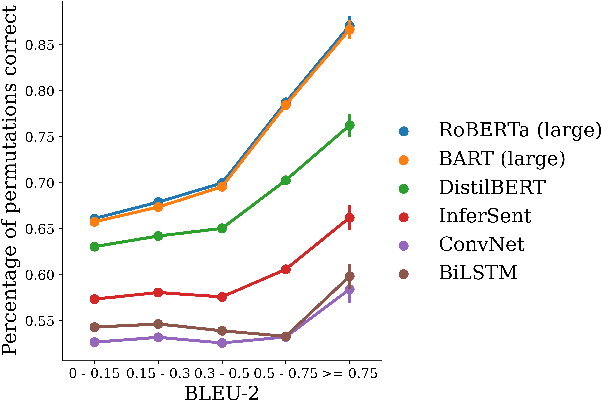
Natural Language Understanding has witnessed a watershed moment with the introduction of large pre-trained Transformer networks. These models achieve state-of-the-art on various tasks, notably including Natural Language Inference (NLI). Many studies have shown that the large representation space imbibed by the models encodes some syntactic and semantic information. However, to really "know syntax", a model must recognize when its input violates syntactic rules and calculate inferences accordingly. In this work, we find that state-of-the-art NLI models, such as RoBERTa and BART are invariant to, and sometimes even perform better on, examples with randomly reordered words. With iterative search, we are able to construct randomized versions of NLI test sets, which contain permuted hypothesis-premise pairs with the same words as the original, yet are classified with perfect accuracy by large pre-trained models, as well as pre-Transformer state-of-the-art encoders. We find the issue to be language and model invariant, and hence investigate the root cause. To partially alleviate this effect, we propose a simple training methodology. Our findings call into question the idea that our natural language understanding models, and the tasks used for measuring their progress, genuinely require a human-like understanding of syntax.