 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Distributed Larger-Than-Memory Subset Selection With Pairwise Submodular Functions
Feb 26, 2024



Many learning problems hinge on the fundamental problem of subset selection, i.e., identifying a subset of important and representative points. For example, selecting the most significant samples in ML training cannot only reduce training costs but also enhance model quality. Submodularity, a discrete analogue of convexity, is commonly used for solving subset selection problems. However, existing algorithms for optimizing submodular functions are sequential, and the prior distributed methods require at least one central machine to fit the target subset. In this paper, we relax the requirement of having a central machine for the target subset by proposing a novel distributed bounding algorithm with provable approximation guarantees. The algorithm iteratively bounds the minimum and maximum utility values to select high quality points and discard the unimportant ones. When bounding does not find the complete subset, we use a multi-round, partition-based distributed greedy algorithm to identify the remaining subset. We show that these algorithms find high quality subsets on CIFAR-100 and ImageNet with marginal or no loss in quality compared to centralized methods, and scale to a dataset with 13 billion points.
Simulated Overparameterization
Feb 07, 2024



In this work, we introduce a novel paradigm called Simulated Overparametrization (SOP). SOP merges the computational efficiency of compact models with the advanced learning proficiencies of overparameterized models. SOP proposes a unique approach to model training and inference, where a model with a significantly larger number of parameters is trained in such a way that a smaller, efficient subset of these parameters is used for the actual computation during inference. Building upon this framework, we present a novel, architecture agnostic algorithm called "majority kernels", which seamlessly integrates with predominant architectures, including Transformer models. Majority kernels enables the simulated training of overparameterized models, resulting in performance gains across architectures and tasks. Furthermore, our approach adds minimal overhead to the cost incurred (wall clock time) at training time. The proposed approach shows strong performance on a wide variety of datasets and models, even outperforming strong baselines such as combinatorial optimization methods based on submodular optimization.
A Weighted K-Center Algorithm for Data Subset Selection
Dec 17, 2023The success of deep learning hinges on enormous data and large models, which require labor-intensive annotations and heavy computation costs. Subset selection is a fundamental problem that can play a key role in identifying smaller portions of the training data, which can then be used to produce similar models as the ones trained with full data. Two prior methods are shown to achieve impressive results: (1) margin sampling that focuses on selecting points with high uncertainty, and (2) core-sets or clustering methods such as k-center for informative and diverse subsets. We are not aware of any work that combines these methods in a principled manner. To this end, we develop a novel and efficient factor 3-approximation algorithm to compute subsets based on the weighted sum of both k-center and uncertainty sampling objective functions. To handle large datasets, we show a parallel algorithm to run on multiple machines with approximation guarantees. The proposed algorithm achieves similar or better performance compared to other strong baselines on vision datasets such as CIFAR-10, CIFAR-100, and ImageNet.
Improving Length-Generalization in Transformers via Task Hinting
Oct 01, 2023It has been observed in recent years that transformers have problems with length generalization for certain types of reasoning and arithmetic tasks. In particular, the performance of a transformer model trained on tasks (say addition) up to a certain length (e.g., 5 digit numbers) drops sharply when applied to longer instances of the same problem. This work proposes an approach based on task hinting towards addressing length generalization. Our key idea is that while training the model on task-specific data, it is helpful to simultaneously train the model to solve a simpler but related auxiliary task as well. We study the classical sorting problem as a canonical example to evaluate our approach. We design a multitask training framework and show that task hinting significantly improve length generalization. For sorting we show that it is possible to train models on data consisting of sequences having length at most $20$, and improve the test accuracy on sequences of length $100$ from less than 1% (for standard training) to more than 92% (via task hinting). Our study uncovers several interesting aspects of length generalization. We observe that while several auxiliary tasks may seem natural a priori, their effectiveness in improving length generalization differs dramatically. We further use probing and visualization-based techniques to understand the internal mechanisms via which the model performs the task, and propose a theoretical construction consistent with the observed learning behaviors of the model. Based on our construction, we show that introducing a small number of length dependent parameters into the training procedure can further boost the performance on unseen lengths. Finally, we also show the efficacy of our task hinting based approach beyond sorting, giving hope that these techniques will be applicable in broader contexts.
The Sample Complexity of Multi-Distribution Learning for VC Classes
Jul 22, 2023Multi-distribution learning is a natural generalization of PAC learning to settings with multiple data distributions. There remains a significant gap between the known upper and lower bounds for PAC-learnable classes. In particular, though we understand the sample complexity of learning a VC dimension d class on $k$ distributions to be $O(\epsilon^{-2} \ln(k)(d + k) + \min\{\epsilon^{-1} dk, \epsilon^{-4} \ln(k) d\})$, the best lower bound is $\Omega(\epsilon^{-2}(d + k \ln(k)))$. We discuss recent progress on this problem and some hurdles that are fundamental to the use of game dynamics in statistical learning.
Best-Effort Adaptation
May 10, 2023We study a problem of best-effort adaptation motivated by several applications and considerations, which consists of determining an accurate predictor for a target domain, for which a moderate amount of labeled samples are available, while leveraging information from another domain for which substantially more labeled samples are at one's disposal. We present a new and general discrepancy-based theoretical analysis of sample reweighting methods, including bounds holding uniformly over the weights. We show how these bounds can guide the design of learning algorithms that we discuss in detail. We further show that our learning guarantees and algorithms provide improved solutions for standard domain adaptation problems, for which few labeled data or none are available from the target domain. We finally report the results of a series of experiments demonstrating the effectiveness of our best-effort adaptation and domain adaptation algorithms, as well as comparisons with several baselines. We also discuss how our analysis can benefit the design of principled solutions for fine-tuning.
Congested Bandits: Optimal Routing via Short-term Resets
Jan 23, 2023

For traffic routing platforms, the choice of which route to recommend to a user depends on the congestion on these routes -- indeed, an individual's utility depends on the number of people using the recommended route at that instance. Motivated by this, we introduce the problem of Congested Bandits where each arm's reward is allowed to depend on the number of times it was played in the past $\Delta$ timesteps. This dependence on past history of actions leads to a dynamical system where an algorithm's present choices also affect its future pay-offs, and requires an algorithm to plan for this. We study the congestion aware formulation in the multi-armed bandit (MAB) setup and in the contextual bandit setup with linear rewards. For the multi-armed setup, we propose a UCB style algorithm and show that its policy regret scales as $\tilde{O}(\sqrt{K \Delta T})$. For the linear contextual bandit setup, our algorithm, based on an iterative least squares planner, achieves policy regret $\tilde{O}(\sqrt{dT} + \Delta)$. From an experimental standpoint, we corroborate the no-regret properties of our algorithms via a simulation study.
On the Adversarial Robustness of Mixture of Experts
Oct 19, 2022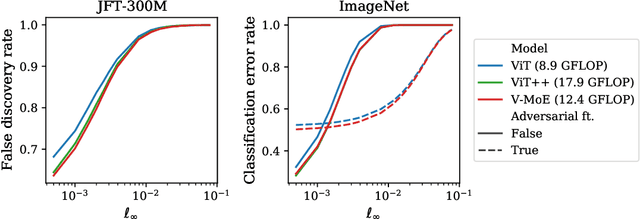
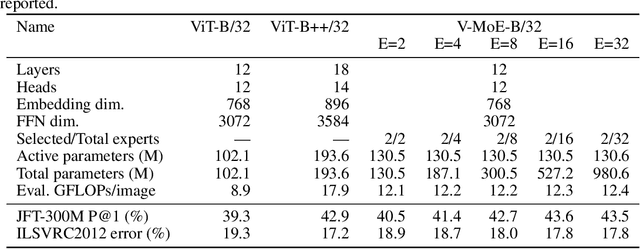
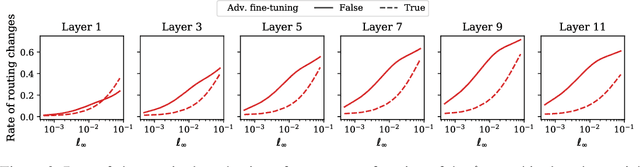
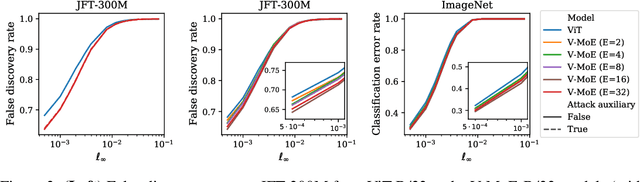
Adversarial robustness is a key desirable property of neural networks. It has been empirically shown to be affected by their sizes, with larger networks being typically more robust. Recently, Bubeck and Sellke proved a lower bound on the Lipschitz constant of functions that fit the training data in terms of their number of parameters. This raises an interesting open question, do -- and can -- functions with more parameters, but not necessarily more computational cost, have better robustness? We study this question for sparse Mixture of Expert models (MoEs), that make it possible to scale up the model size for a roughly constant computational cost. We theoretically show that under certain conditions on the routing and the structure of the data, MoEs can have significantly smaller Lipschitz constants than their dense counterparts. The robustness of MoEs can suffer when the highest weighted experts for an input implement sufficiently different functions. We next empirically evaluate the robustness of MoEs on ImageNet using adversarial attacks and show they are indeed more robust than dense models with the same computational cost. We make key observations showing the robustness of MoEs to the choice of experts, highlighting the redundancy of experts in models trained in practice.
Agnostic Learning of General ReLU Activation Using Gradient Descent
Aug 04, 2022We provide a convergence analysis of gradient descent for the problem of agnostically learning a single ReLU function under Gaussian distributions. Unlike prior work that studies the setting of zero bias, we consider the more challenging scenario when the bias of the ReLU function is non-zero. Our main result establishes that starting from random initialization, in a polynomial number of iterations gradient descent outputs, with high probability, a ReLU function that achieves a competitive error guarantee when compared to the error of the best ReLU function. We also provide finite sample guarantees, and these techniques generalize to a broader class of marginal distributions beyond Gaussians.
Individual Preference Stability for Clustering
Jul 07, 2022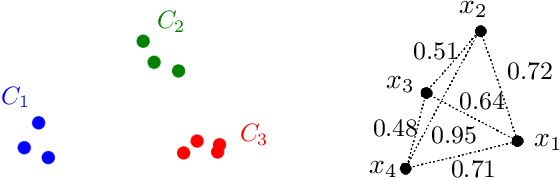

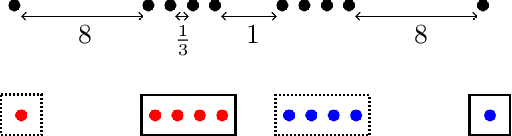
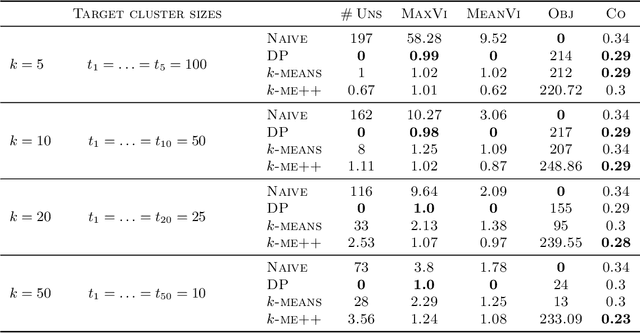
In this paper, we propose a natural notion of individual preference (IP) stability for clustering, which asks that every data point, on average, is closer to the points in its own cluster than to the points in any other cluster. Our notion can be motivated from several perspectives, including game theory and algorithmic fairness. We study several questions related to our proposed notion. We first show that deciding whether a given data set allows for an IP-stable clustering in general is NP-hard. As a result, we explore the design of efficient algorithms for finding IP-stable clusterings in some restricted metric spaces. We present a polytime algorithm to find a clustering satisfying exact IP-stability on the real line, and an efficient algorithm to find an IP-stable 2-clustering for a tree metric. We also consider relaxing the stability constraint, i.e., every data point should not be too far from its own cluster compared to any other cluster. For this case, we provide polytime algorithms with different guarantees. We evaluate some of our algorithms and several standard clustering approaches on real data sets.