 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy in Deep Learning: A Survey
May 09, 2020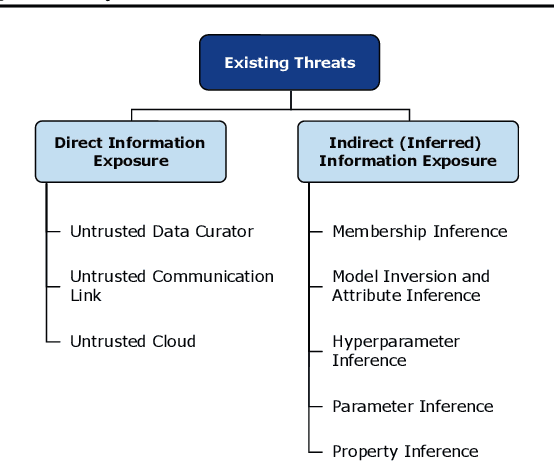


The ever-growing advances of deep learning in many areas including vision, recommendation systems, natural language processing, etc., have led to the adoption of Deep Neural Networks (DNNs) in production systems. The availability of large datasets and high computational power are the main contributors to these advances. The datasets are usually crowdsourced and may contain sensitive information. This poses serious privacy concerns as this data can be misused or leaked through various vulnerabilities. Even if the cloud provider and the communication link is trusted, there are still threats of inference attacks where an attacker could speculate properties of the data used for training, or find the underlying model architecture and parameters. In this survey, we review the privacy concerns brought by deep learning, and the mitigating techniques introduced to tackle these issues. We also show that there is a gap in the literature regarding test-time inference privacy, and propose possible future research directions.
Split Learning for collaborative deep learning in healthcare
Dec 27, 2019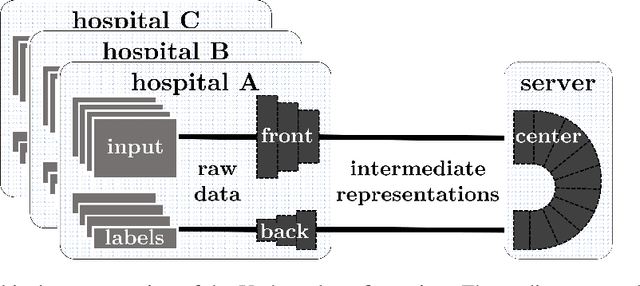
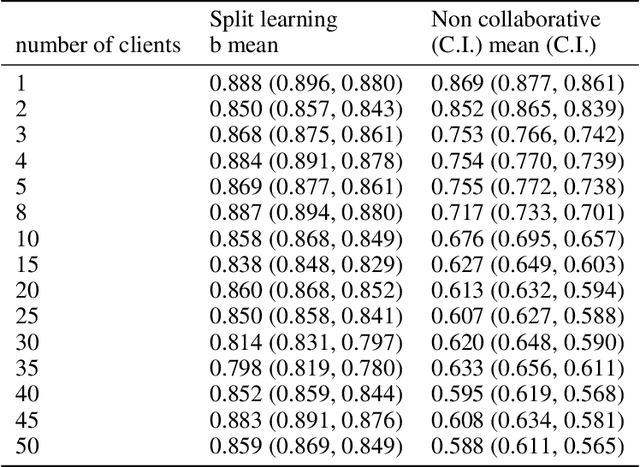
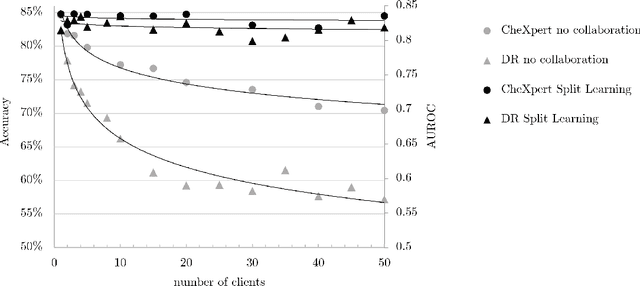
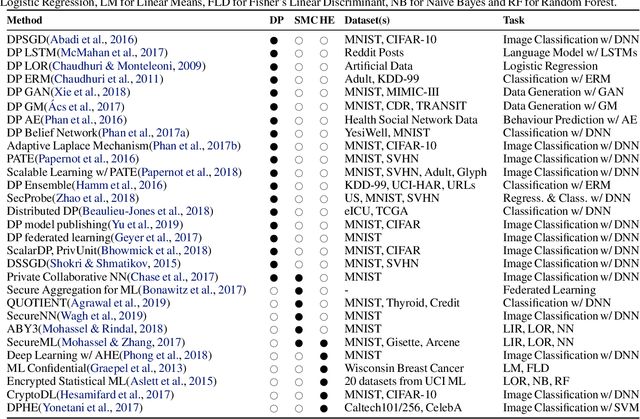
Shortage of labeled data has been holding the surge of deep learning in healthcare back, as sample sizes are often small, patient information cannot be shared openly, and multi-center collaborative studies are a burden to set up. Distributed machine learning methods promise to mitigate these problems. We argue for a split learning based approach and apply this distributed learning method for the first time in the medical field to compare performance against (1) centrally hosted and (2) non collaborative configurations for a range of participants. Two medical deep learning tasks are used to compare split learning to conventional single and multi center approaches: a binary classification problem of a data set of 9000 fundus photos, and multi-label classification problem of a data set of 156,535 chest X-rays. The several distributed learning setups are compared for a range of 1-50 distributed participants. Performance of the split learning configuration remained constant for any number of clients compared to a single center study, showing a marked difference compared to the non collaborative configuration after 2 clients (p < 0.001) for both sets. Our results affirm the benefits of collaborative training of deep neural networks in health care. Our work proves the significant benefit of distributed learning in healthcare, and paves the way for future real-world implementations.
Advances and Open Problems in Federated Learning
Dec 10, 2019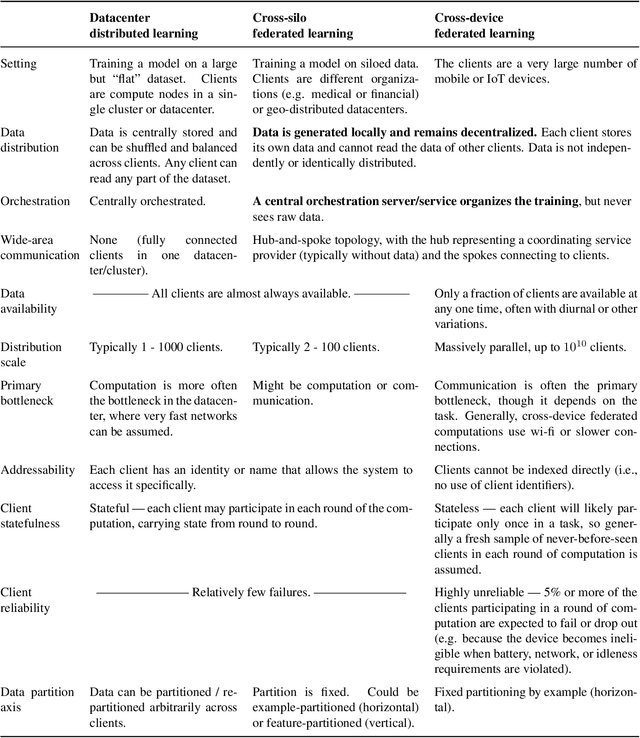
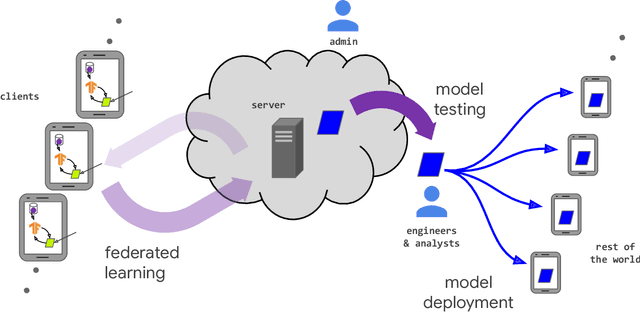
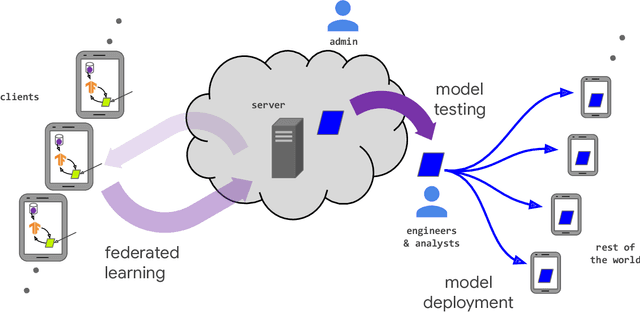

Federated learning (FL) is a machine learning setting where many clients (e.g. mobile devices or whole organizations) collaboratively train a model under the orchestration of a central server (e.g. service provider), while keeping the training data decentralized. FL embodies the principles of focused data collection and minimization, and can mitigate many of the systemic privacy risks and costs resulting from traditional, centralized machine learning and data science approaches. Motivated by the explosive growth in FL research, this paper discusses recent advances and presents an extensive collection of open problems and challenges.
ExpertMatcher: Automating ML Model Selection for Clients using Hidden Representations
Oct 09, 2019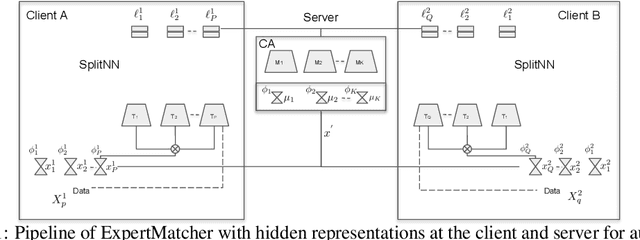
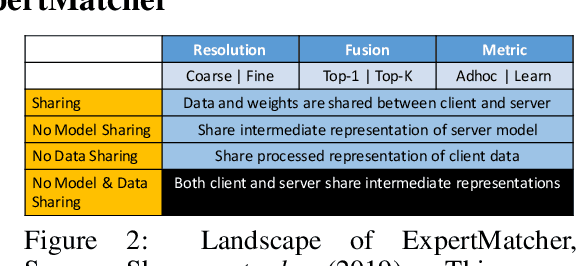

Recently, there has been the development of Split Learning, a framework for distributed computation where model components are split between the client and server (Vepakomma et al., 2018b). As Split Learning scales to include many different model components, there needs to be a method of matching client-side model components with the best server-side model components. A solution to this problem was introduced in the ExpertMatcher (Sharma et al., 2019) framework, which uses autoencoders to match raw data to models. In this work, we propose an extension of ExpertMatcher, where matching can be performed without the need to share the client's raw data representation. The technique is applicable to situations where there are local clients and centralized expert ML models, but the sharing of raw data is constrained.
ExpertMatcher: Automating ML Model Selection for Users in Resource Constrained Countries
Oct 05, 2019
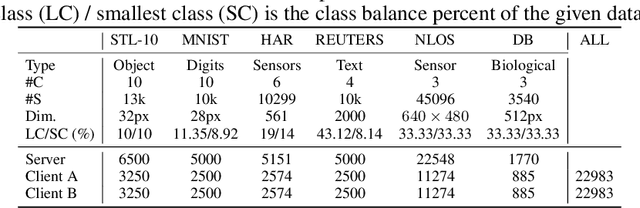
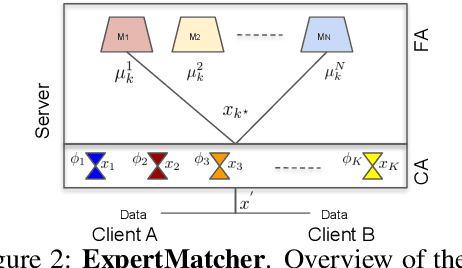
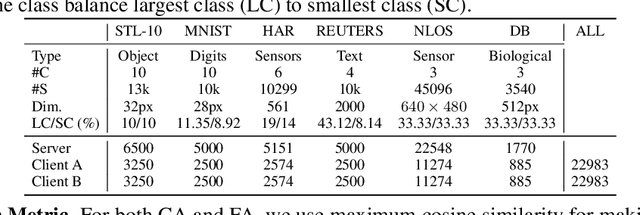
In this work we introduce ExpertMatcher, a method for automating deep learning model selection using autoencoders. Specifically, we are interested in performing inference on data sources that are distributed across many clients using pretrained expert ML networks on a centralized server. The ExpertMatcher assigns the most relevant model(s) in the central server given the client's data representation. This allows resource-constrained clients in developing countries to utilize the most relevant ML models for their given task without having to evaluate the performance of each ML model. The method is generic and can be beneficial in any setup where there are local clients and numerous centralized expert ML models.
Maximal adversarial perturbations for obfuscation: Hiding certain attributes while preserving rest
Sep 27, 2019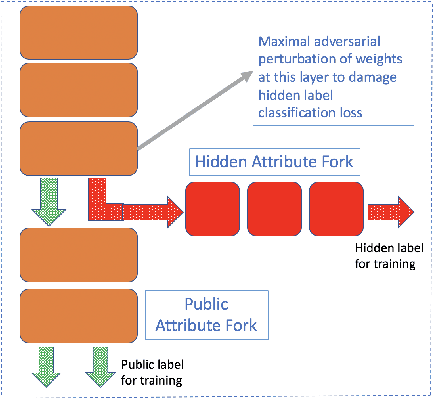
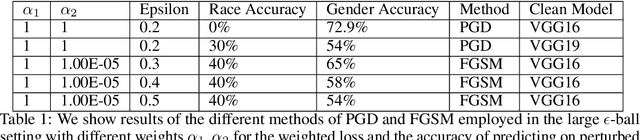
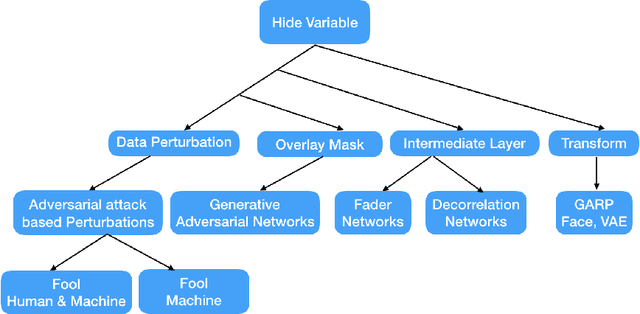

In this paper we investigate the usage of adversarial perturbations for the purpose of privacy from human perception and model (machine) based detection. We employ adversarial perturbations for obfuscating certain variables in raw data while preserving the rest. Current adversarial perturbation methods are used for data poisoning with minimal perturbations of the raw data such that the machine learning model's performance is adversely impacted while the human vision cannot perceive the difference in the poisoned dataset due to minimal nature of perturbations. We instead apply relatively maximal perturbations of raw data to conditionally damage model's classification of one attribute while preserving the model performance over another attribute. In addition, the maximal nature of perturbation helps adversely impact human perception in classifying hidden attribute apart from impacting model performance. We validate our result qualitatively by showing the obfuscated dataset and quantitatively by showing the inability of models trained on clean data to predict the hidden attribute from the perturbed dataset while being able to predict the rest of attributes.
Detailed comparison of communication efficiency of split learning and federated learning
Sep 18, 2019
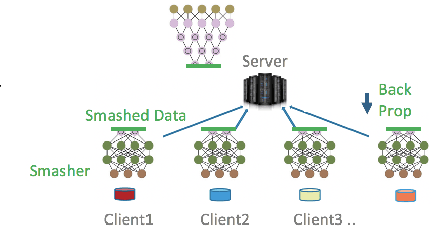
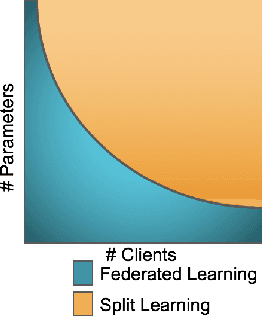
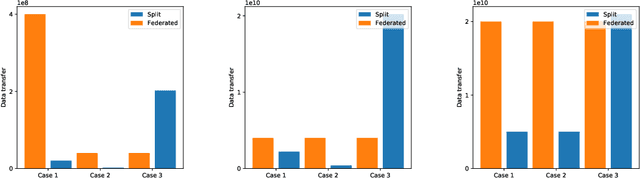
We compare communication efficiencies of two compelling distributed machine learning approaches of split learning and federated learning. We show useful settings under which each method outperforms the other in terms of communication efficiency. We consider various practical scenarios of distributed learning setup and juxtapose the two methods under various real-life scenarios. We consider settings of small and large number of clients as well as small models (1M - 6M parameters), large models (10M - 200M parameters) and very large models (1 Billion-100 Billion parameters). We show that increasing number of clients or increasing model size favors split learning setup over the federated while increasing the number of data samples while keeping the number of clients or model size low makes federated learning more communication efficient.
Data Markets to support AI for All: Pricing, Valuation and Governance
May 14, 2019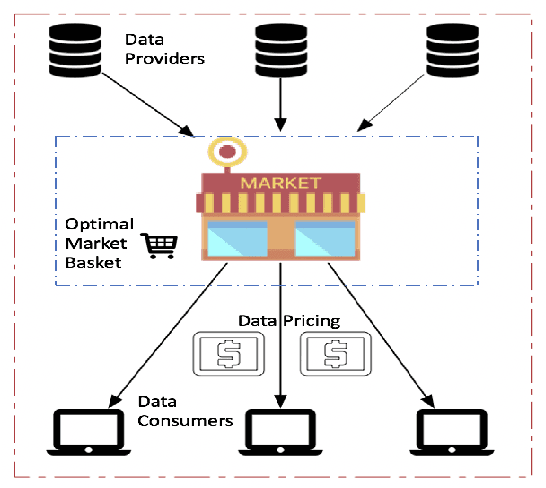
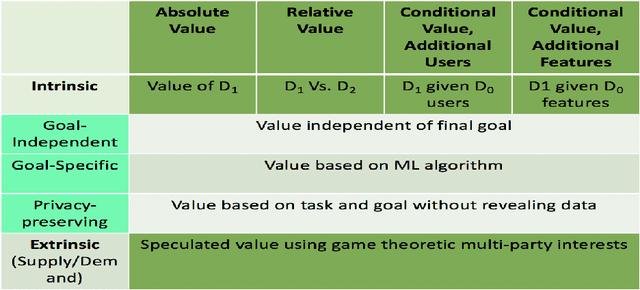
We discuss a data market technique based on intrinsic (relevance and uniqueness) as well as extrinsic value (influenced by supply and demand) of data. For intrinsic value, we explain how to perform valuation of data in absolute terms (i.e just by itself), or relatively (i.e in comparison to multiple datasets) or in conditional terms (i.e valuating new data given currently existing data).
No Peek: A Survey of private distributed deep learning
Dec 08, 2018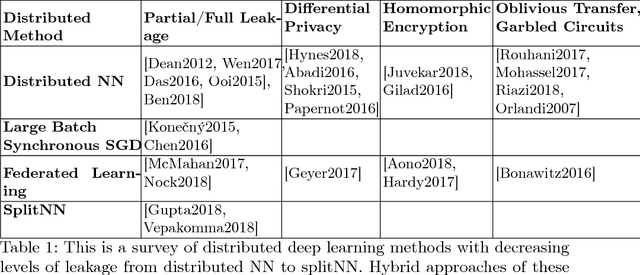
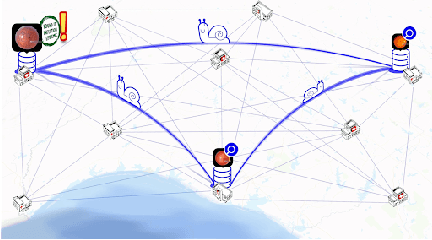
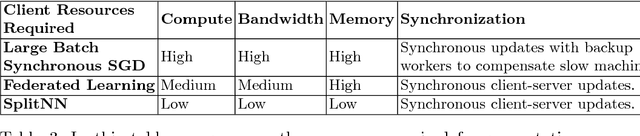
We survey distributed deep learning models for training or inference without accessing raw data from clients. These methods aim to protect confidential patterns in data while still allowing servers to train models. The distributed deep learning methods of federated learning, split learning and large batch stochastic gradient descent are compared in addition to private and secure approaches of differential privacy, homomorphic encryption, oblivious transfer and garbled circuits in the context of neural networks. We study their benefits, limitations and trade-offs with regards to computational resources, data leakage and communication efficiency and also share our anticipated future trends.
Split learning for health: Distributed deep learning without sharing raw patient data
Dec 03, 2018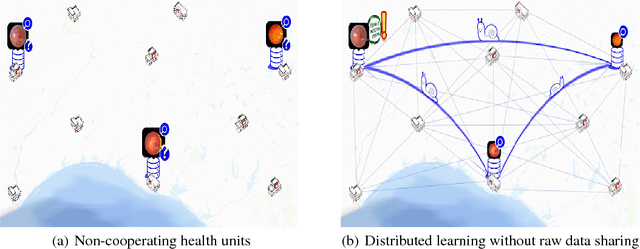

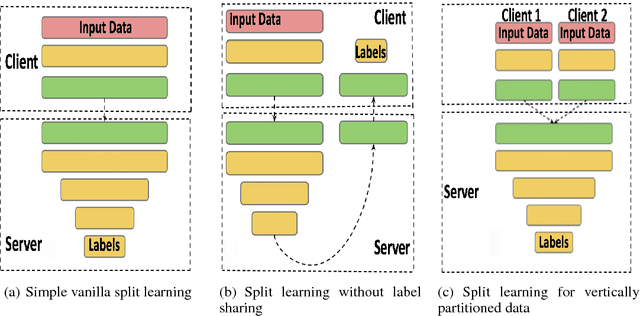

Can health entities collaboratively train deep learning models without sharing sensitive raw data? This paper proposes several configurations of a distributed deep learning method called SplitNN to facilitate such collaborations. SplitNN does not share raw data or model details with collaborating institutions. The proposed configurations of splitNN cater to practical settings of i) entities holding different modalities of patient data, ii) centralized and local health entities collaborating on multiple tasks and iii) learning without sharing labels. We compare performance and resource efficiency trade-offs of splitNN and other distributed deep learning methods like federated learning, large batch synchronous stochastic gradient descent and show highly encouraging results for splitNN.