 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Planar Ising Models
Feb 03, 2015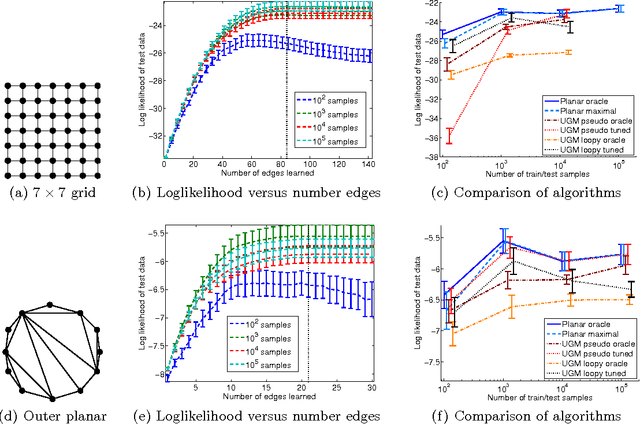
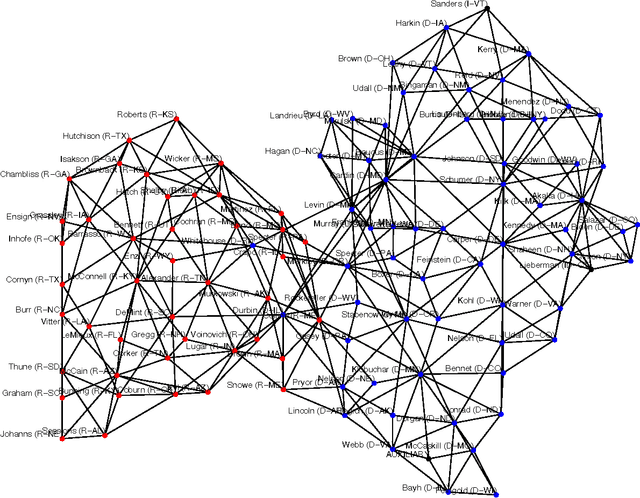
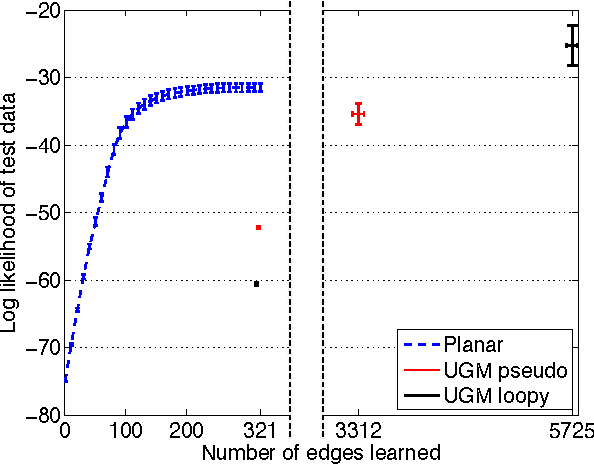
Inference and learning of graphical models are both well-studied problems in statistics and machine learning that have found many applications in science and engineering. However, exact inference is intractable in general graphical models, which suggests the problem of seeking the best approximation to a collection of random variables within some tractable family of graphical models. In this paper, we focus on the class of planar Ising models, for which exact inference is tractable using techniques of statistical physics. Based on these techniques and recent methods for planarity testing and planar embedding, we propose a simple greedy algorithm for learning the best planar Ising model to approximate an arbitrary collection of binary random variables (possibly from sample data). Given the set of all pairwise correlations among variables, we select a planar graph and optimal planar Ising model defined on this graph to best approximate that set of correlations. We demonstrate our method in simulations and for the application of modeling senate voting records.
Fast Exact Matrix Completion with Finite Samples
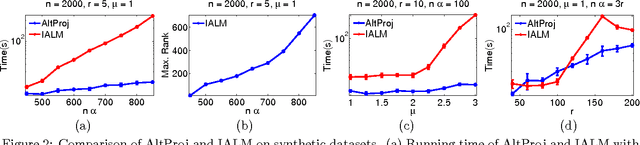
Nov 04, 2014Matrix completion is the problem of recovering a low rank matrix by observing a small fraction of its entries. A series of recent works [KOM12,JNS13,HW14] have proposed fast non-convex optimization based iterative algorithms to solve this problem. However, the sample complexity in all these results is sub-optimal in its dependence on the rank, condition number and the desired accuracy. In this paper, we present a fast iterative algorithm that solves the matrix completion problem by observing $O(nr^5 \log^3 n)$ entries, which is independent of the condition number and the desired accuracy. The run time of our algorithm is $O(nr^7\log^3 n\log 1/\epsilon)$ which is near linear in the dimension of the matrix. To the best of our knowledge, this is the first near linear time algorithm for exact matrix completion with finite sample complexity (i.e. independent of $\epsilon$). Our algorithm is based on a well known projected gradient descent method, where the projection is onto the (non-convex) set of low rank matrices. There are two key ideas in our result: 1) our argument is based on a $\ell_{\infty}$ norm potential function (as opposed to the spectral norm) and provides a novel way to obtain perturbation bounds for it. 2) we prove and use a natural extension of the Davis-Kahan theorem to obtain perturbation bounds on the best low rank approximation of matrices with good eigen-gap. Both of these ideas may be of independent interest.
Non-convex Robust PCA
Oct 28, 2014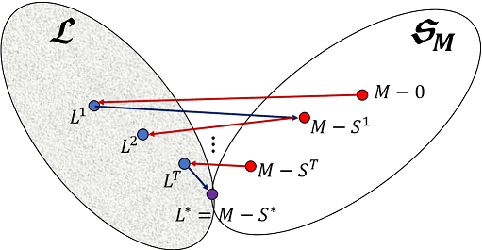


We propose a new method for robust PCA -- the task of recovering a low-rank matrix from sparse corruptions that are of unknown value and support. Our method involves alternating between projecting appropriate residuals onto the set of low-rank matrices, and the set of sparse matrices; each projection is {\em non-convex} but easy to compute. In spite of this non-convexity, we establish exact recovery of the low-rank matrix, under the same conditions that are required by existing methods (which are based on convex optimization). For an $m \times n$ input matrix ($m \leq n)$, our method has a running time of $O(r^2mn)$ per iteration, and needs $O(\log(1/\epsilon))$ iterations to reach an accuracy of $\epsilon$. This is close to the running time of simple PCA via the power method, which requires $O(rmn)$ per iteration, and $O(\log(1/\epsilon))$ iterations. In contrast, existing methods for robust PCA, which are based on convex optimization, have $O(m^2n)$ complexity per iteration, and take $O(1/\epsilon)$ iterations, i.e., exponentially more iterations for the same accuracy. Experiments on both synthetic and real data establishes the improved speed and accuracy of our method over existing convex implementations.
Learning Sparsely Used Overcomplete Dictionaries via Alternating Minimization
Jul 28, 2014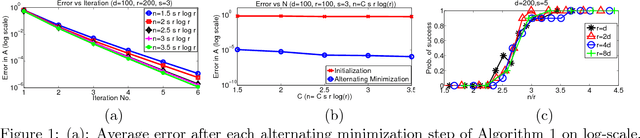
We consider the problem of sparse coding, where each sample consists of a sparse linear combination of a set of dictionary atoms, and the task is to learn both the dictionary elements and the mixing coefficients. Alternating minimization is a popular heuristic for sparse coding, where the dictionary and the coefficients are estimated in alternate steps, keeping the other fixed. Typically, the coefficients are estimated via $\ell_1$ minimization, keeping the dictionary fixed, and the dictionary is estimated through least squares, keeping the coefficients fixed. In this paper, we establish local linear convergence for this variant of alternating minimization and establish that the basin of attraction for the global optimum (corresponding to the true dictionary and the coefficients) is $\order{1/s^2}$, where $s$ is the sparsity level in each sample and the dictionary satisfies RIP. Combined with the recent results of approximate dictionary estimation, this yields provable guarantees for exact recovery of both the dictionary elements and the coefficients, when the dictionary elements are incoherent.
A Clustering Approach to Learn Sparsely-Used Overcomplete Dictionaries
Jul 07, 2014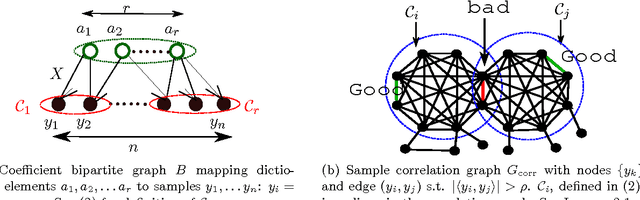
We consider the problem of learning overcomplete dictionaries in the context of sparse coding, where each sample selects a sparse subset of dictionary elements. Our main result is a strategy to approximately recover the unknown dictionary using an efficient algorithm. Our algorithm is a clustering-style procedure, where each cluster is used to estimate a dictionary element. The resulting solution can often be further cleaned up to obtain a high accuracy estimate, and we provide one simple scenario where $\ell_1$-regularized regression can be used for such a second stage.
Low-rank Matrix Completion using Alternating Minimization
Dec 03, 2012Alternating minimization represents a widely applicable and empirically successful approach for finding low-rank matrices that best fit the given data. For example, for the problem of low-rank matrix completion, this method is believed to be one of the most accurate and efficient, and formed a major component of the winning entry in the Netflix Challenge. In the alternating minimization approach, the low-rank target matrix is written in a bi-linear form, i.e. $X = UV^\dag$; the algorithm then alternates between finding the best $U$ and the best $V$. Typically, each alternating step in isolation is convex and tractable. However the overall problem becomes non-convex and there has been almost no theoretical understanding of when this approach yields a good result. In this paper we present first theoretical analysis of the performance of alternating minimization for matrix completion, and the related problem of matrix sensing. For both these problems, celebrated recent results have shown that they become well-posed and tractable once certain (now standard) conditions are imposed on the problem. We show that alternating minimization also succeeds under similar conditions. Moreover, compared to existing results, our paper shows that alternating minimization guarantees faster (in particular, geometric) convergence to the true matrix, while allowing a simpler analysis.
Greedy Learning of Markov Network Structure
Feb 08, 2012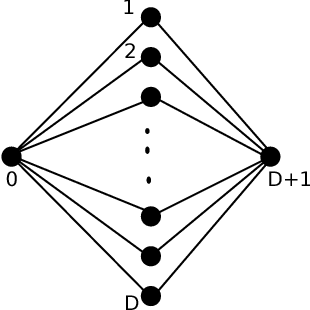
We propose a new yet natural algorithm for learning the graph structure of general discrete graphical models (a.k.a. Markov random fields) from samples. Our algorithm finds the neighborhood of a node by sequentially adding nodes that produce the largest reduction in empirical conditional entropy; it is greedy in the sense that the choice of addition is based only on the reduction achieved at that iteration. Its sequential nature gives it a lower computational complexity as compared to other existing comparison-based techniques, all of which involve exhaustive searches over every node set of a certain size. Our main result characterizes the sample complexity of this procedure, as a function of node degrees, graph size and girth in factor-graph representation. We subsequently specialize this result to the case of Ising models, where we provide a simple transparent characterization of sample complexity as a function of model and graph parameters. For tree graphs, our algorithm is the same as the classical Chow-Liu algorithm, and in that sense can be considered the extension of the same to graphs with cycles.
Finding the Graph of Epidemic Cascades
Feb 08, 2012
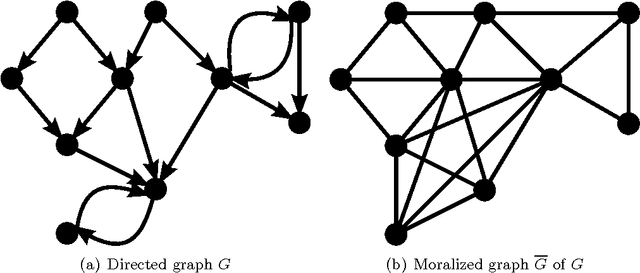
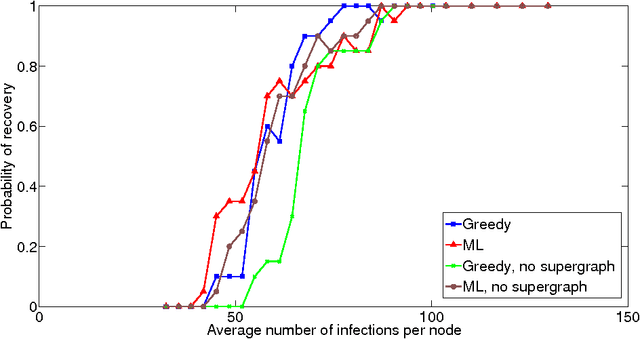
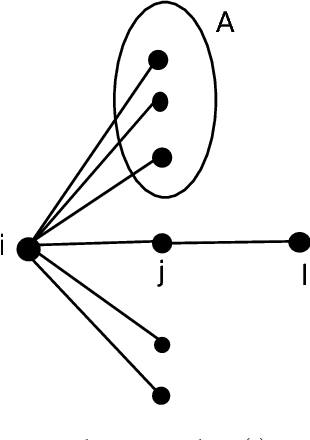
We consider the problem of finding the graph on which an epidemic cascade spreads, given only the times when each node gets infected. While this is a problem of importance in several contexts -- offline and online social networks, e-commerce, epidemiology, vulnerabilities in infrastructure networks -- there has been very little work, analytical or empirical, on finding the graph. Clearly, it is impossible to do so from just one cascade; our interest is in learning the graph from a small number of cascades. For the classic and popular "independent cascade" SIR epidemics, we analytically establish the number of cascades required by both the global maximum-likelihood (ML) estimator, and a natural greedy algorithm. Both results are based on a key observation: the global graph learning problem decouples into $n$ local problems -- one for each node. For a node of degree $d$, we show that its neighborhood can be reliably found once it has been infected $O(d^2 \log n)$ times (for ML on general graphs) or $O(d\log n)$ times (for greedy on trees). We also provide a corresponding information-theoretic lower bound of $\Omega(d\log n)$; thus our bounds are essentially tight. Furthermore, if we are given side-information in the form of a super-graph of the actual graph (as is often the case), then the number of cascade samples required -- in all cases -- becomes independent of the network size $n$. Finally, we show that for a very general SIR epidemic cascade model, the Markov graph of infection times is obtained via the moralization of the network graph.