 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSquare Root Graphical Models: Multivariate Generalizations of Univariate Exponential Families that Permit Positive Dependencies
Jun 10, 2016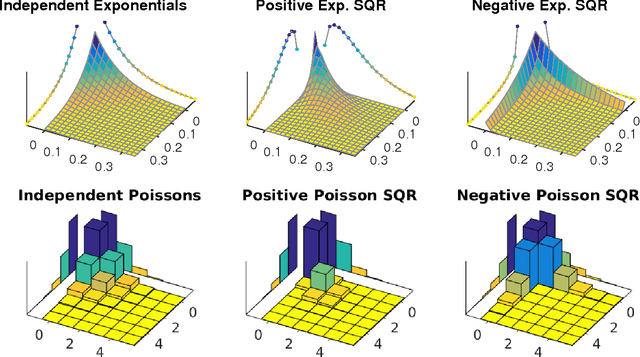
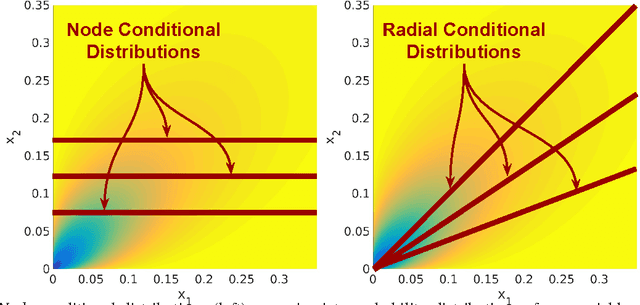
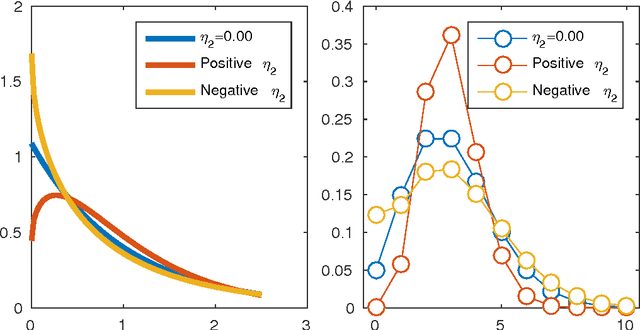
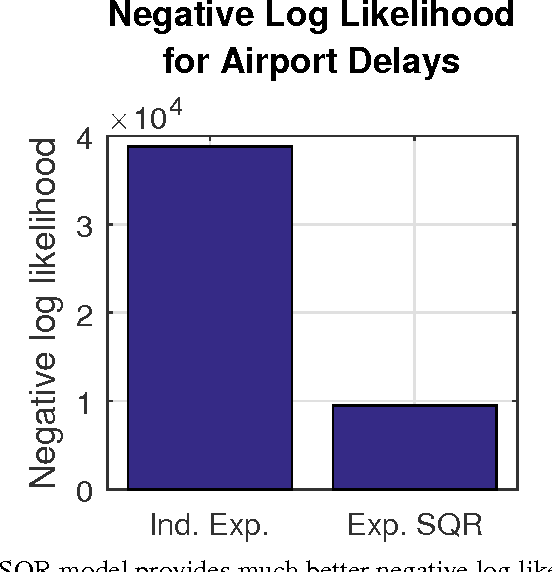
We develop Square Root Graphical Models (SQR), a novel class of parametric graphical models that provides multivariate generalizations of univariate exponential family distributions. Previous multivariate graphical models [Yang et al. 2015] did not allow positive dependencies for the exponential and Poisson generalizations. However, in many real-world datasets, variables clearly have positive dependencies. For example, the airport delay time in New York---modeled as an exponential distribution---is positively related to the delay time in Boston. With this motivation, we give an example of our model class derived from the univariate exponential distribution that allows for almost arbitrary positive and negative dependencies with only a mild condition on the parameter matrix---a condition akin to the positive definiteness of the Gaussian covariance matrix. Our Poisson generalization allows for both positive and negative dependencies without any constraints on the parameter values. We also develop parameter estimation methods using node-wise regressions with $\ell_1$ regularization and likelihood approximation methods using sampling. Finally, we demonstrate our exponential generalization on a synthetic dataset and a real-world dataset of airport delay times.
Generalized Root Models: Beyond Pairwise Graphical Models for Univariate Exponential Families
Jun 02, 2016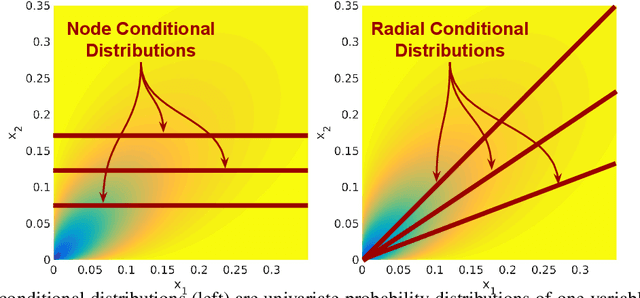
We present a novel k-way high-dimensional graphical model called the Generalized Root Model (GRM) that explicitly models dependencies between variable sets of size k > 2---where k = 2 is the standard pairwise graphical model. This model is based on taking the k-th root of the original sufficient statistics of any univariate exponential family with positive sufficient statistics, including the Poisson and exponential distributions. As in the recent work with square root graphical (SQR) models [Inouye et al. 2016]---which was restricted to pairwise dependencies---we give the conditions of the parameters that are needed for normalization using the radial conditionals similar to the pairwise case [Inouye et al. 2016]. In particular, we show that the Poisson GRM has no restrictions on the parameters and the exponential GRM only has a restriction akin to negative definiteness. We develop a simple but general learning algorithm based on L1-regularized node-wise regressions. We also present a general way of numerically approximating the log partition function and associated derivatives of the GRM univariate node conditionals---in contrast to [Inouye et al. 2016], which only provided algorithm for estimating the exponential SQR. To illustrate GRM, we model word counts with a Poisson GRM and show the associated k-sized variable sets. We finish by discussing methods for reducing the parameter space in various situations.
Exponential Family Matrix Completion under Structural Constraints
Sep 15, 2015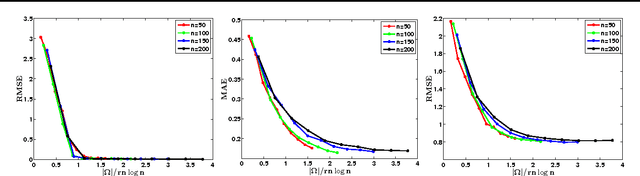
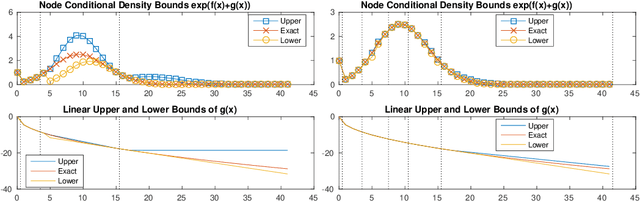
We consider the matrix completion problem of recovering a structured matrix from noisy and partial measurements. Recent works have proposed tractable estimators with strong statistical guarantees for the case where the underlying matrix is low--rank, and the measurements consist of a subset, either of the exact individual entries, or of the entries perturbed by additive Gaussian noise, which is thus implicitly suited for thin--tailed continuous data. Arguably, common applications of matrix completion require estimators for (a) heterogeneous data--types, such as skewed--continuous, count, binary, etc., (b) for heterogeneous noise models (beyond Gaussian), which capture varied uncertainty in the measurements, and (c) heterogeneous structural constraints beyond low--rank, such as block--sparsity, or a superposition structure of low--rank plus elementwise sparseness, among others. In this paper, we provide a vastly unified framework for generalized matrix completion by considering a matrix completion setting wherein the matrix entries are sampled from any member of the rich family of exponential family distributions; and impose general structural constraints on the underlying matrix, as captured by a general regularizer $\mathcal{R}(.)$. We propose a simple convex regularized $M$--estimator for the generalized framework, and provide a unified and novel statistical analysis for this general class of estimators. We finally corroborate our theoretical results on simulated datasets.
* 20 pages, 9 figures
On Graphical Models via Univariate Exponential Family Distributions
Sep 05, 2015



Undirected graphical models, or Markov networks, are a popular class of statistical models, used in a wide variety of applications. Popular instances of this class include Gaussian graphical models and Ising models. In many settings, however, it might not be clear which subclass of graphical models to use, particularly for non-Gaussian and non-categorical data. In this paper, we consider a general sub-class of graphical models where the node-wise conditional distributions arise from exponential families. This allows us to derive multivariate graphical model distributions from univariate exponential family distributions, such as the Poisson, negative binomial, and exponential distributions. Our key contributions include a class of M-estimators to fit these graphical model distributions; and rigorous statistical analysis showing that these M-estimators recover the true graphical model structure exactly, with high probability. We provide examples of genomic and proteomic networks learned via instances of our class of graphical models derived from Poisson and exponential distributions.
Vector-Space Markov Random Fields via Exponential Families
May 19, 2015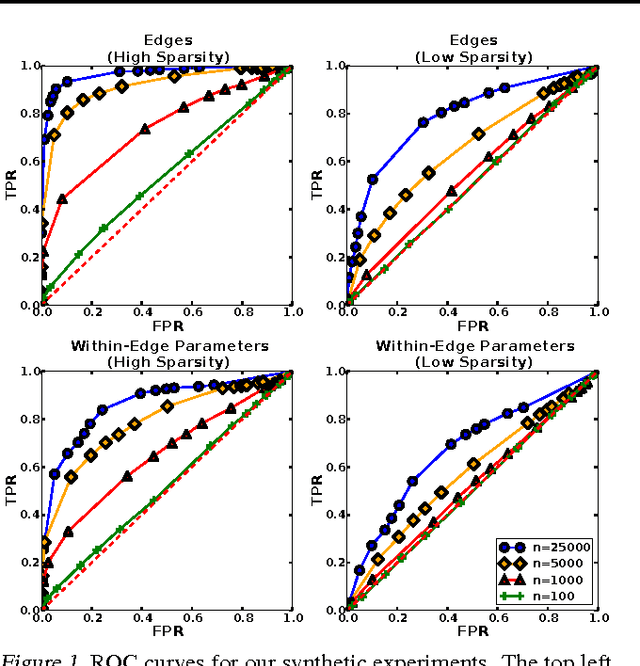
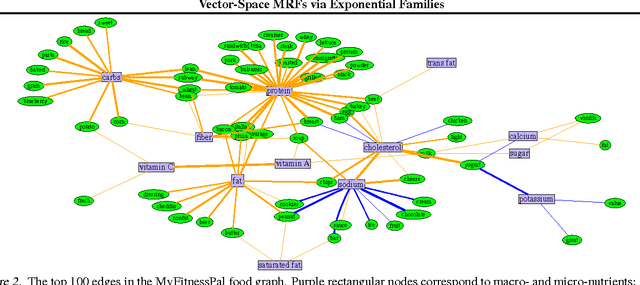
We present Vector-Space Markov Random Fields (VS-MRFs), a novel class of undirected graphical models where each variable can belong to an arbitrary vector space. VS-MRFs generalize a recent line of work on scalar-valued, uni-parameter exponential family and mixed graphical models, thereby greatly broadening the class of exponential families available (e.g., allowing multinomial and Dirichlet distributions). Specifically, VS-MRFs are the joint graphical model distributions where the node-conditional distributions belong to generic exponential families with general vector space domains. We also present a sparsistent $M$-estimator for learning our class of MRFs that recovers the correct set of edges with high probability. We validate our approach via a set of synthetic data experiments as well as a real-world case study of over four million foods from the popular diet tracking app MyFitnessPal. Our results demonstrate that our algorithm performs well empirically and that VS-MRFs are capable of capturing and highlighting interesting structure in complex, real-world data. All code for our algorithm is open source and publicly available.
Optimal Decision-Theoretic Classification Using Non-Decomposable Performance Metrics
May 07, 2015
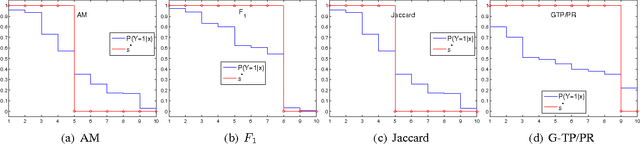
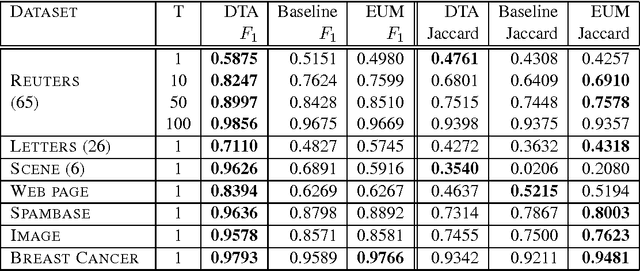
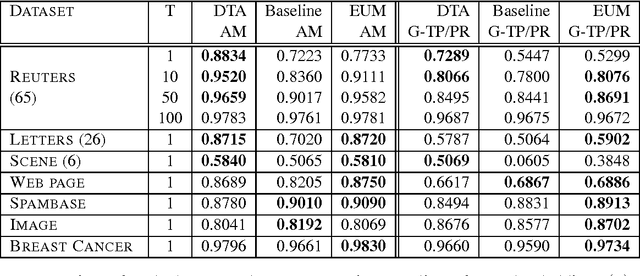
We provide a general theoretical analysis of expected out-of-sample utility, also referred to as decision-theoretic classification, for non-decomposable binary classification metrics such as F-measure and Jaccard coefficient. Our key result is that the expected out-of-sample utility for many performance metrics is provably optimized by a classifier which is equivalent to a signed thresholding of the conditional probability of the positive class. Our analysis bridges a gap in the literature on binary classification, revealed in light of recent results for non-decomposable metrics in population utility maximization style classification. Our results identify checkable properties of a performance metric which are sufficient to guarantee a probability ranking principle. We propose consistent estimators for optimal expected out-of-sample classification. As a consequence of the probability ranking principle, computational requirements can be reduced from exponential to cubic complexity in the general case, and further reduced to quadratic complexity in special cases. We provide empirical results on simulated and benchmark datasets evaluating the performance of the proposed algorithms for decision-theoretic classification and comparing them to baseline and state-of-the-art methods in population utility maximization for non-decomposable metrics.
Proximal Quasi-Newton for Computationally Intensive L1-regularized M-estimators
Jan 23, 2015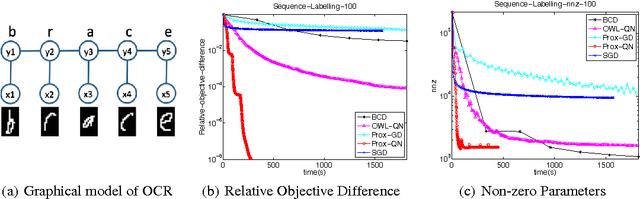
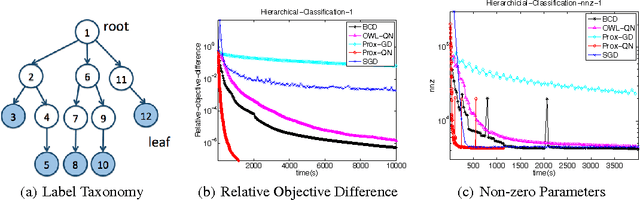
We consider the class of optimization problems arising from computationally intensive L1-regularized M-estimators, where the function or gradient values are very expensive to compute. A particular instance of interest is the L1-regularized MLE for learning Conditional Random Fields (CRFs), which are a popular class of statistical models for varied structured prediction problems such as sequence labeling, alignment, and classification with label taxonomy. L1-regularized MLEs for CRFs are particularly expensive to optimize since computing the gradient values requires an expensive inference step. In this work, we propose the use of a carefully constructed proximal quasi-Newton algorithm for such computationally intensive M-estimation problems, where we employ an aggressive active set selection technique. In a key contribution of the paper, we show that the proximal quasi-Newton method is provably super-linearly convergent, even in the absence of strong convexity, by leveraging a restricted variant of strong convexity. In our experiments, the proposed algorithm converges considerably faster than current state-of-the-art on the problems of sequence labeling and hierarchical classification.
On the Information Theoretic Limits of Learning Ising Models
Dec 05, 2014We provide a general framework for computing lower-bounds on the sample complexity of recovering the underlying graphs of Ising models, given i.i.d samples. While there have been recent results for specific graph classes, these involve fairly extensive technical arguments that are specialized to each specific graph class. In contrast, we isolate two key graph-structural ingredients that can then be used to specify sample complexity lower-bounds. Presence of these structural properties makes the graph class hard to learn. We derive corollaries of our main result that not only recover existing recent results, but also provide lower bounds for novel graph classes not considered previously. We also extend our framework to the random graph setting and derive corollaries for Erd\H{o}s-R\'{e}nyi graphs in a certain dense setting.
A General Framework for Mixed Graphical Models
Nov 02, 2014
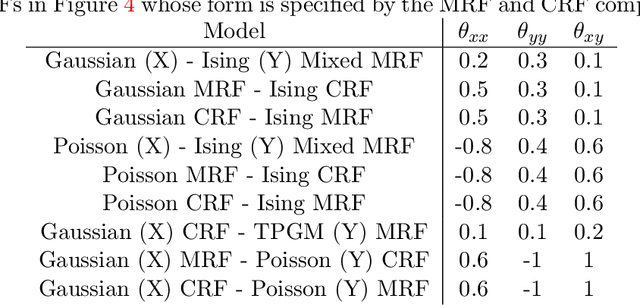
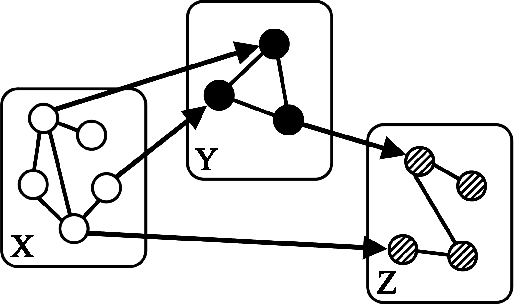
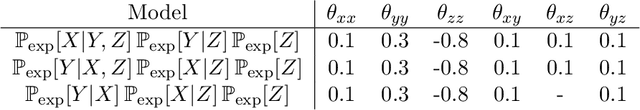
"Mixed Data" comprising a large number of heterogeneous variables (e.g. count, binary, continuous, skewed continuous, among other data types) are prevalent in varied areas such as genomics and proteomics, imaging genetics, national security, social networking, and Internet advertising. There have been limited efforts at statistically modeling such mixed data jointly, in part because of the lack of computationally amenable multivariate distributions that can capture direct dependencies between such mixed variables of different types. In this paper, we address this by introducing a novel class of Block Directed Markov Random Fields (BDMRFs). Using the basic building block of node-conditional univariate exponential families from Yang et al. (2012), we introduce a class of mixed conditional random field distributions, that are then chained according to a block-directed acyclic graph to form our class of Block Directed Markov Random Fields (BDMRFs). The Markov independence graph structure underlying a BDMRF thus has both directed and undirected edges. We introduce conditions under which these distributions exist and are normalizable, study several instances of our models, and propose scalable penalized conditional likelihood estimators with statistical guarantees for recovering the underlying network structure. Simulations as well as an application to learning mixed genomic networks from next generation sequencing expression data and mutation data demonstrate the versatility of our methods.
Sparse Inverse Covariance Matrix Estimation Using Quadratic Approximation
Jun 13, 2013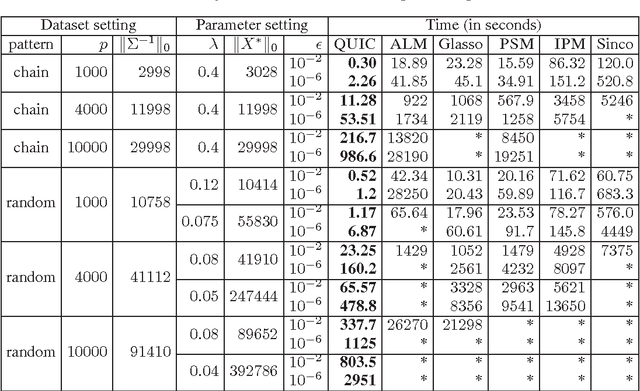
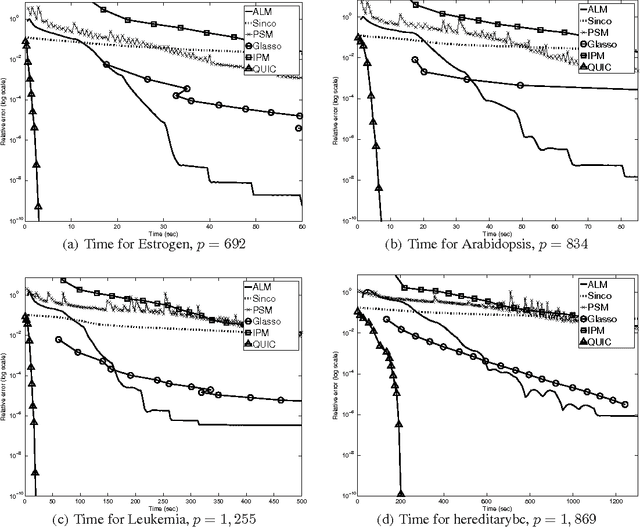
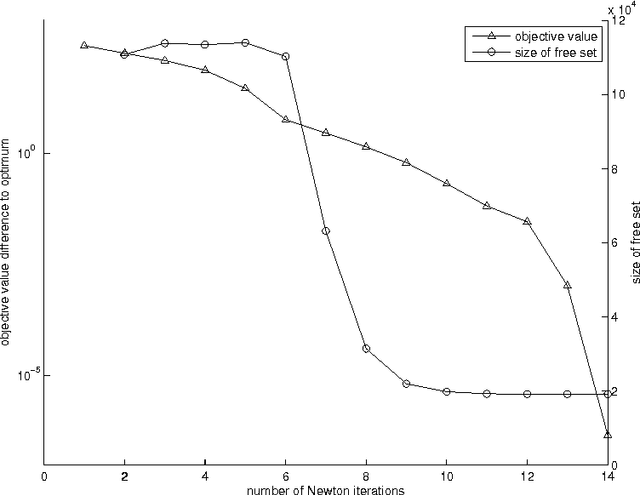
The L1-regularized Gaussian maximum likelihood estimator (MLE) has been shown to have strong statistical guarantees in recovering a sparse inverse covariance matrix, or alternatively the underlying graph structure of a Gaussian Markov Random Field, from very limited samples. We propose a novel algorithm for solving the resulting optimization problem which is a regularized log-determinant program. In contrast to recent state-of-the-art methods that largely use first order gradient information, our algorithm is based on Newton's method and employs a quadratic approximation, but with some modifications that leverage the structure of the sparse Gaussian MLE problem. We show that our method is superlinearly convergent, and present experimental results using synthetic and real-world application data that demonstrate the considerable improvements in performance of our method when compared to other state-of-the-art methods.