 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFirst is Better Than Last for Training Data Influence
Feb 24, 2022
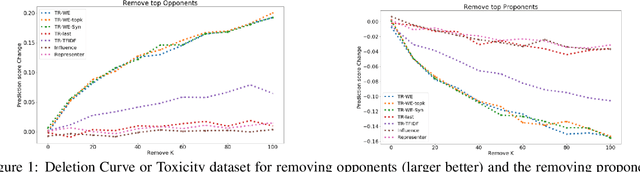

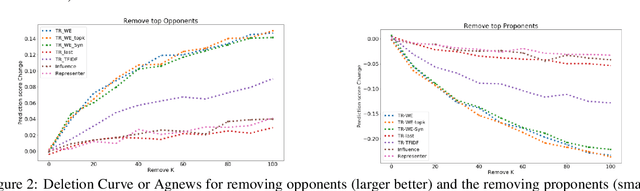
The ability to identify influential training examples enables us to debug training data and explain model behavior. Existing techniques are based on the flow of influence through the model parameters. For large models in NLP applications, it is often computationally infeasible to study this flow through all model parameters, therefore techniques usually pick the last layer of weights. Our first observation is that for classification problems, the last layer is reductive and does not encode sufficient input level information. Deleting influential examples, according to this measure, typically does not change the model's behavior much. We propose a technique called TracIn-WE that modifies a method called TracIn to operate on the word embedding layer instead of the last layer. This could potentially have the opposite concern, that the word embedding layer does not encode sufficient high level information. However, we find that gradients (unlike embeddings) do not suffer from this, possibly because they chain through higher layers. We show that TracIn-WE significantly outperforms other data influence methods applied on the last layer by 4-10 times on the case deletion evaluation on three language classification tasks. In addition, TracIn-WE can produce scores not just at the training data level, but at the word training data level, a further aid in debugging.
Masked prediction tasks: a parameter identifiability view
Feb 18, 2022The vast majority of work in self-supervised learning, both theoretical and empirical (though mostly the latter), have largely focused on recovering good features for downstream tasks, with the definition of "good" often being intricately tied to the downstream task itself. This lens is undoubtedly very interesting, but suffers from the problem that there isn't a "canonical" set of downstream tasks to focus on -- in practice, this problem is usually resolved by competing on the benchmark dataset du jour. In this paper, we present an alternative lens: one of parameter identifiability. More precisely, we consider data coming from a parametric probabilistic model, and train a self-supervised learning predictor with a suitably chosen parametric form. Then, we ask whether we can read off the ground truth parameters of the probabilistic model from the optimal predictor. We focus on the widely used self-supervised learning method of predicting masked tokens, which is popular for both natural languages and visual data. While incarnations of this approach have already been successfully used for simpler probabilistic models (e.g. learning fully-observed undirected graphical models), we focus instead on latent-variable models capturing sequential structures -- namely Hidden Markov Models with both discrete and conditionally Gaussian observations. We show that there is a rich landscape of possibilities, out of which some prediction tasks yield identifiability, while others do not. Our results, borne of a theoretical grounding of self-supervised learning, could thus potentially beneficially inform practice. Moreover, we uncover close connections with uniqueness of tensor rank decompositions -- a widely used tool in studying identifiability through the lens of the method of moments.
Understanding Why Generalized Reweighting Does Not Improve Over ERM
Feb 16, 2022


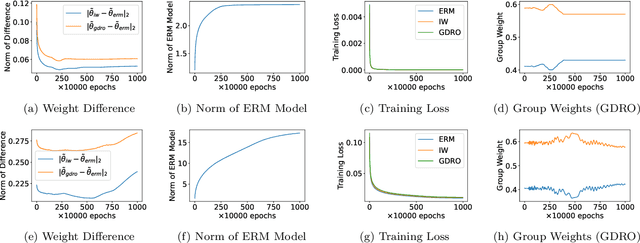
Empirical risk minimization (ERM) is known in practice to be non-robust to distributional shift where the training and the test distributions are different. A suite of approaches, such as importance weighting, and variants of distributionally robust optimization (DRO), have been proposed to solve this problem. But a line of recent work has empirically shown that these approaches do not significantly improve over ERM in real applications with distribution shift. The goal of this work is to obtain a comprehensive theoretical understanding of this intriguing phenomenon. We first posit the class of Generalized Reweighting (GRW) algorithms, as a broad category of approaches that iteratively update model parameters based on iterative reweighting of the training samples. We show that when overparameterized models are trained under GRW, the resulting models are close to that obtained by ERM. We also show that adding small regularization which does not greatly affect the empirical training accuracy does not help. Together, our results show that a broad category of what we term GRW approaches are not able to achieve distributionally robust generalization. Our work thus has the following sobering takeaway: to make progress towards distributionally robust generalization, we either have to develop non-GRW approaches, or perhaps devise novel classification/regression loss functions that are adapted to the class of GRW approaches.
Domain-Adjusted Regression or: ERM May Already Learn Features Sufficient for Out-of-Distribution Generalization
Feb 14, 2022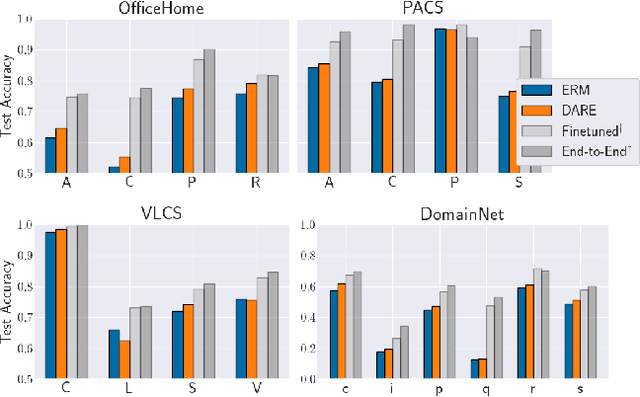
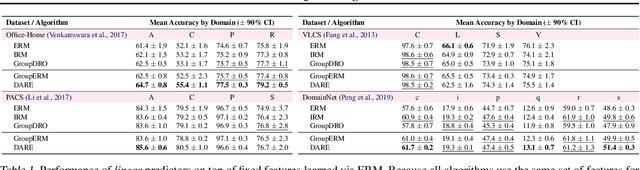
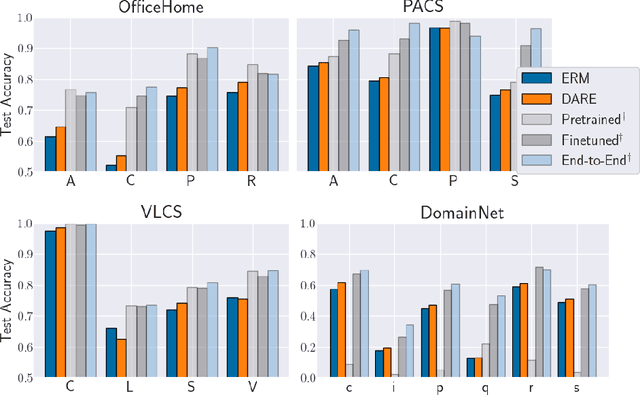
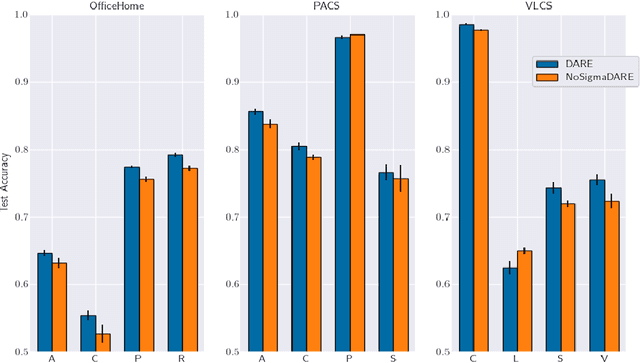
A common explanation for the failure of deep networks to generalize out-of-distribution is that they fail to recover the "correct" features. Focusing on the domain generalization setting, we challenge this notion with a simple experiment which suggests that ERM already learns sufficient features and that the current bottleneck is not feature learning, but robust regression. We therefore argue that devising simpler methods for learning predictors on existing features is a promising direction for future research. Towards this end, we introduce Domain-Adjusted Regression (DARE), a convex objective for learning a linear predictor that is provably robust under a new model of distribution shift. Rather than learning one function, DARE performs a domain-specific adjustment to unify the domains in a canonical latent space and learns to predict in this space. Under a natural model, we prove that the DARE solution is the minimax-optimal predictor for a constrained set of test distributions. Further, we provide the first finite-environment convergence guarantee to the minimax risk, improving over existing results which show a "threshold effect". Evaluated on finetuned features, we find that DARE compares favorably to prior methods, consistently achieving equal or better performance.
Boosted CVaR Classification
Nov 10, 2021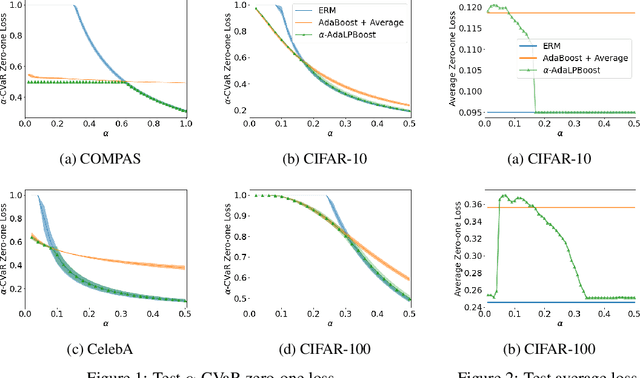
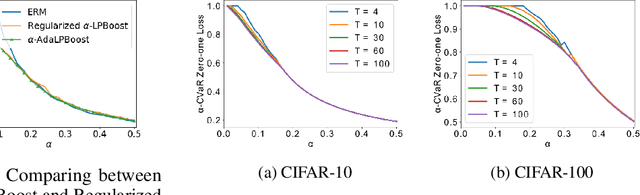
Many modern machine learning tasks require models with high tail performance, i.e. high performance over the worst-off samples in the dataset. This problem has been widely studied in fields such as algorithmic fairness, class imbalance, and risk-sensitive decision making. A popular approach to maximize the model's tail performance is to minimize the CVaR (Conditional Value at Risk) loss, which computes the average risk over the tails of the loss. However, for classification tasks where models are evaluated by the zero-one loss, we show that if the classifiers are deterministic, then the minimizer of the average zero-one loss also minimizes the CVaR zero-one loss, suggesting that CVaR loss minimization is not helpful without additional assumptions. We circumvent this negative result by minimizing the CVaR loss over randomized classifiers, for which the minimizers of the average zero-one loss and the CVaR zero-one loss are no longer the same, so minimizing the latter can lead to better tail performance. To learn such randomized classifiers, we propose the Boosted CVaR Classification framework which is motivated by a direct relationship between CVaR and a classical boosting algorithm called LPBoost. Based on this framework, we design an algorithm called $\alpha$-AdaLPBoost. We empirically evaluate our proposed algorithm on four benchmark datasets and show that it achieves higher tail performance than deterministic model training methods.
Analyzing and Improving the Optimization Landscape of Noise-Contrastive Estimation
Oct 21, 2021
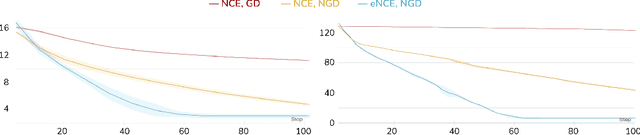
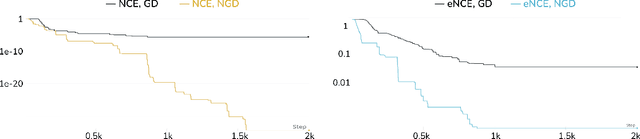
Noise-contrastive estimation (NCE) is a statistically consistent method for learning unnormalized probabilistic models. It has been empirically observed that the choice of the noise distribution is crucial for NCE's performance. However, such observations have never been made formal or quantitative. In fact, it is not even clear whether the difficulties arising from a poorly chosen noise distribution are statistical or algorithmic in nature. In this work, we formally pinpoint reasons for NCE's poor performance when an inappropriate noise distribution is used. Namely, we prove these challenges arise due to an ill-behaved (more precisely, flat) loss landscape. To address this, we introduce a variant of NCE called "eNCE" which uses an exponential loss and for which normalized gradient descent addresses the landscape issues provably when the target and noise distributions are in a given exponential family.
FILM: Following Instructions in Language with Modular Methods
Oct 18, 2021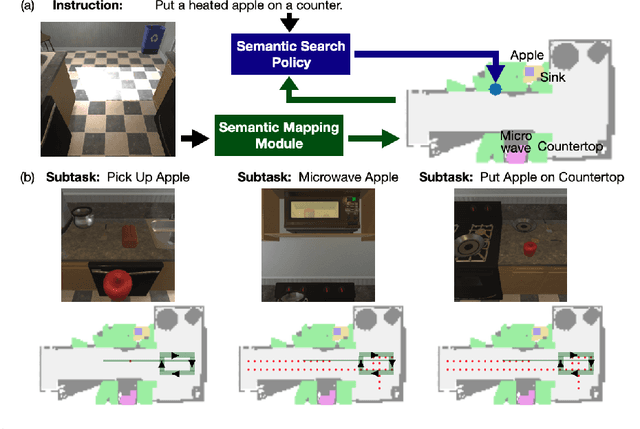
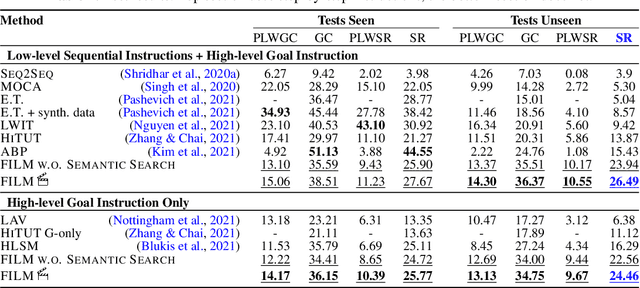
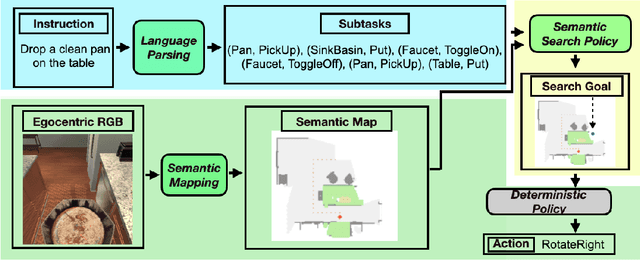
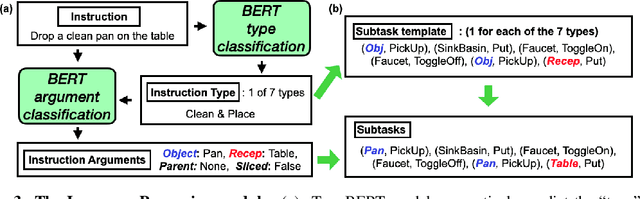
Recent methods for embodied instruction following are typically trained end-to-end using imitation learning. This requires the use of expert trajectories and low-level language instructions. Such approaches assume learned hidden states will simultaneously integrate semantics from the language and vision to perform state tracking, spatial memory, exploration, and long-term planning. In contrast, we propose a modular method with structured representations that (1) builds a semantic map of the scene, and (2) performs exploration with a semantic search policy, to achieve the natural language goal. Our modular method achieves SOTA performance (24.46%) with a substantial (8.17 % absolute) gap from previous work while using less data by eschewing both expert trajectories and low-level instructions. Leveraging low-level language, however, can further increase our performance (26.49%). Our findings suggest that an explicit spatial memory and a semantic search policy can provide a stronger and more general representation for state-tracking and guidance, even in the absence of expert trajectories or low-level instructions.
Heavy-tailed Streaming Statistical Estimation
Aug 25, 2021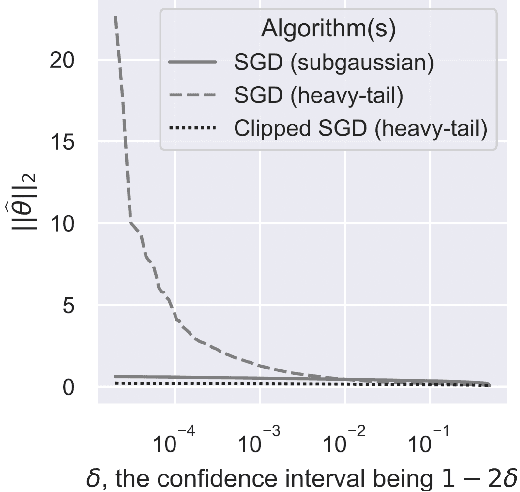
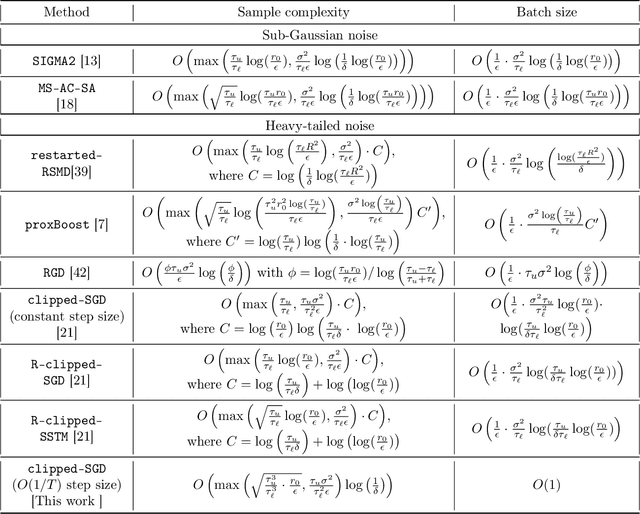
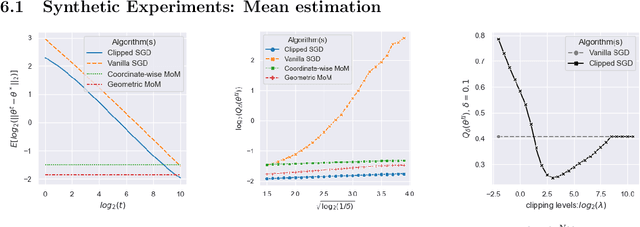
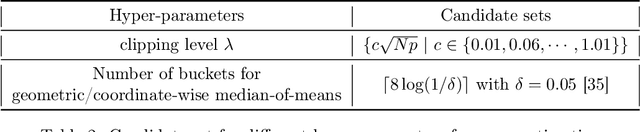
We consider the task of heavy-tailed statistical estimation given streaming $p$-dimensional samples. This could also be viewed as stochastic optimization under heavy-tailed distributions, with an additional $O(p)$ space complexity constraint. We design a clipped stochastic gradient descent algorithm and provide an improved analysis, under a more nuanced condition on the noise of the stochastic gradients, which we show is critical when analyzing stochastic optimization problems arising from general statistical estimation problems. Our results guarantee convergence not just in expectation but with exponential concentration, and moreover does so using $O(1)$ batch size. We provide consequences of our results for mean estimation and linear regression. Finally, we provide empirical corroboration of our results and algorithms via synthetic experiments for mean estimation and linear regression.
Learning latent causal graphs via mixture oracles
Jun 29, 2021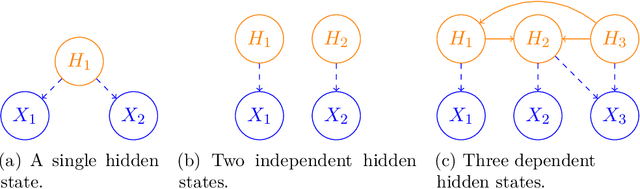
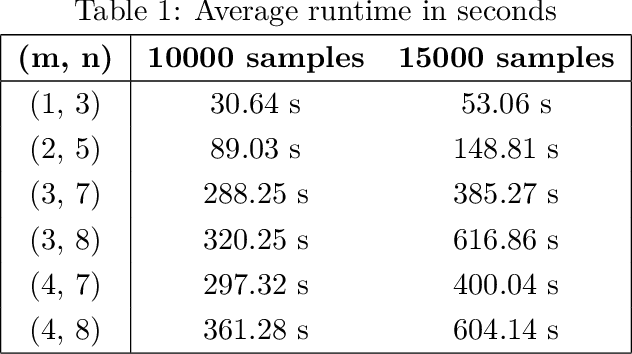
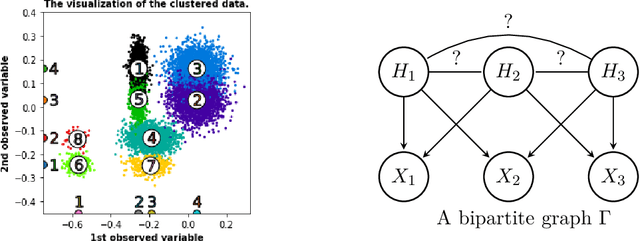
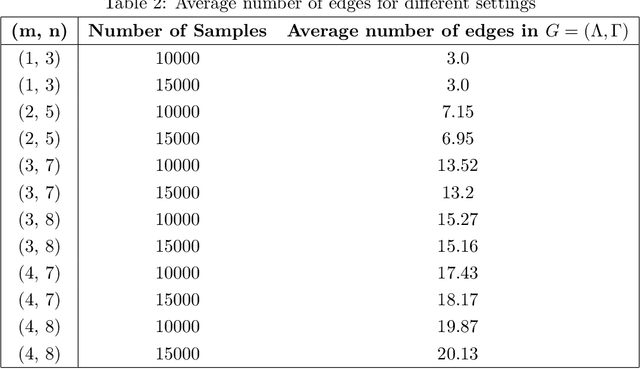
We study the problem of reconstructing a causal graphical model from data in the presence of latent variables. The main problem of interest is recovering the causal structure over the latent variables while allowing for general, potentially nonlinear dependence between the variables. In many practical problems, the dependence between raw observations (e.g. pixels in an image) is much less relevant than the dependence between certain high-level, latent features (e.g. concepts or objects), and this is the setting of interest. We provide conditions under which both the latent representations and the underlying latent causal model are identifiable by a reduction to a mixture oracle. The proof is constructive, and leads to several algorithms for explicitly reconstructing the full graphical model. We discuss efficient algorithms and provide experiments illustrating the algorithms in practice.
Improving Compositional Generalization in Classification Tasks via Structure Annotations
Jun 19, 2021
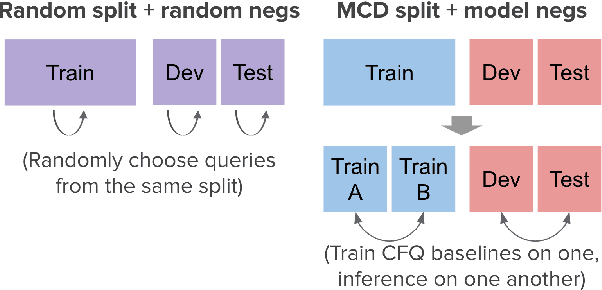
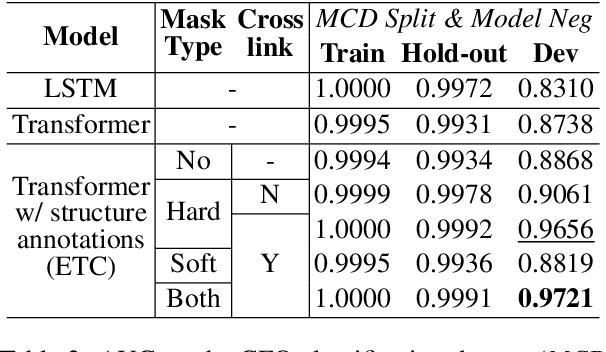
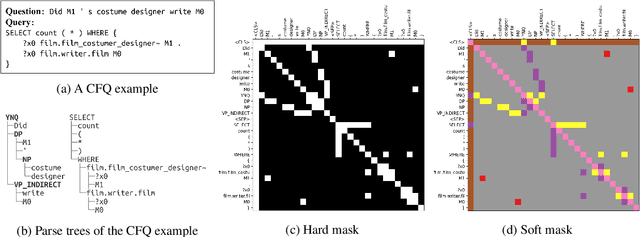
Compositional generalization is the ability to generalize systematically to a new data distribution by combining known components. Although humans seem to have a great ability to generalize compositionally, state-of-the-art neural models struggle to do so. In this work, we study compositional generalization in classification tasks and present two main contributions. First, we study ways to convert a natural language sequence-to-sequence dataset to a classification dataset that also requires compositional generalization. Second, we show that providing structural hints (specifically, providing parse trees and entity links as attention masks for a Transformer model) helps compositional generalization.