 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Deraining via Self-supervised Reinforcement Learning
Mar 27, 2024



The quality of images captured outdoors is often affected by the weather. One factor that interferes with sight is rain, which can obstruct the view of observers and computer vision applications that rely on those images. The work aims to recover rain images by removing rain streaks via Self-supervised Reinforcement Learning (RL) for image deraining (SRL-Derain). We locate rain streak pixels from the input rain image via dictionary learning and use pixel-wise RL agents to take multiple inpainting actions to remove rain progressively. To our knowledge, this work is the first attempt where self-supervised RL is applied to image deraining. Experimental results on several benchmark image-deraining datasets show that the proposed SRL-Derain performs favorably against state-of-the-art few-shot and self-supervised deraining and denoising methods.
Offline Imitation of Badminton Player Behavior via Experiential Contexts and Brownian Motion
Mar 19, 2024In the dynamic and rapid tactic involvements of turn-based sports, badminton stands out as an intrinsic paradigm that requires alter-dependent decision-making of players. While the advancement of learning from offline expert data in sequential decision-making has been witnessed in various domains, how to rally-wise imitate the behaviors of human players from offline badminton matches has remained underexplored. Replicating opponents' behavior benefits players by allowing them to undergo strategic development with direction before matches. However, directly applying existing methods suffers from the inherent hierarchy of the match and the compounding effect due to the turn-based nature of players alternatively taking actions. In this paper, we propose RallyNet, a novel hierarchical offline imitation learning model for badminton player behaviors: (i) RallyNet captures players' decision dependencies by modeling decision-making processes as a contextual Markov decision process. (ii) RallyNet leverages the experience to generate context as the agent's intent in the rally. (iii) To generate more realistic behavior, RallyNet leverages Geometric Brownian Motion (GBM) to model the interactions between players by introducing a valuable inductive bias for learning player behaviors. In this manner, RallyNet links player intents with interaction models with GBM, providing an understanding of interactions for sports analytics. We extensively validate RallyNet with the largest available real-world badminton dataset consisting of men's and women's singles, demonstrating its ability to imitate player behaviors. Results reveal RallyNet's superiority over offline imitation learning methods and state-of-the-art turn-based approaches, outperforming them by at least 16% in mean rule-based agent normalization score. Furthermore, we discuss various practical use cases to highlight RallyNet's applicability.
PPO-Clip Attains Global Optimality: Towards Deeper Understandings of Clipping
Dec 19, 2023Proximal Policy Optimization algorithm employing a clipped surrogate objective (PPO-Clip) is a prominent exemplar of the policy optimization methods. However, despite its remarkable empirical success, PPO-Clip lacks theoretical substantiation to date. In this paper, we contribute to the field by establishing the first global convergence results of a PPO-Clip variant in both tabular and neural function approximation settings. Our findings highlight the $O(1/\sqrt{T})$ min-iterate convergence rate specifically in the context of neural function approximation. We tackle the inherent challenges in analyzing PPO-Clip through three central concepts: (i) We introduce a generalized version of the PPO-Clip objective, illuminated by its connection with the hinge loss. (ii) Employing entropic mirror descent, we establish asymptotic convergence for tabular PPO-Clip with direct policy parameterization. (iii) Inspired by the tabular analysis, we streamline convergence analysis by introducing a two-step policy improvement approach. This decouples policy search from complex neural policy parameterization using a regression-based update scheme. Furthermore, we gain deeper insights into the efficacy of PPO-Clip by interpreting these generalized objectives. Our theoretical findings also mark the first characterization of the influence of the clipping mechanism on PPO-Clip convergence. Importantly, the clipping range affects only the pre-constant of the convergence rate.
Accelerated Policy Gradient: On the Nesterov Momentum for Reinforcement Learning
Oct 18, 2023Policy gradient methods have recently been shown to enjoy global convergence at a $\Theta(1/t)$ rate in the non-regularized tabular softmax setting. Accordingly, one important research question is whether this convergence rate can be further improved, with only first-order updates. In this paper, we answer the above question from the perspective of momentum by adapting the celebrated Nesterov's accelerated gradient (NAG) method to reinforcement learning (RL), termed \textit{Accelerated Policy Gradient} (APG). To demonstrate the potential of APG in achieving faster global convergence, we formally show that with the true gradient, APG with softmax policy parametrization converges to an optimal policy at a $\tilde{O}(1/t^2)$ rate. To the best of our knowledge, this is the first characterization of the global convergence rate of NAG in the context of RL. Notably, our analysis relies on one interesting finding: Regardless of the initialization, APG could end up reaching a locally nearly-concave regime, where APG could benefit significantly from the momentum, within finite iterations. By means of numerical validation, we confirm that APG exhibits $\tilde{O}(1/t^2)$ rate as well as show that APG could significantly improve the convergence behavior over the standard policy gradient.
Value-Biased Maximum Likelihood Estimation for Model-based Reinforcement Learning in Discounted Linear MDPs
Oct 17, 2023



We consider the infinite-horizon linear Markov Decision Processes (MDPs), where the transition probabilities of the dynamic model can be linearly parameterized with the help of a predefined low-dimensional feature mapping. While the existing regression-based approaches have been theoretically shown to achieve nearly-optimal regret, they are computationally rather inefficient due to the need for a large number of optimization runs in each time step, especially when the state and action spaces are large. To address this issue, we propose to solve linear MDPs through the lens of Value-Biased Maximum Likelihood Estimation (VBMLE), which is a classic model-based exploration principle in the adaptive control literature for resolving the well-known closed-loop identification problem of Maximum Likelihood Estimation. We formally show that (i) VBMLE enjoys $\widetilde{O}(d\sqrt{T})$ regret, where $T$ is the time horizon and $d$ is the dimension of the model parameter, and (ii) VBMLE is computationally more efficient as it only requires solving one optimization problem in each time step. In our regret analysis, we offer a generic convergence result of MLE in linear MDPs through a novel supermartingale construct and uncover an interesting connection between linear MDPs and online learning, which could be of independent interest. Finally, the simulation results show that VBMLE significantly outperforms the benchmark method in terms of both empirical regret and computation time.
Towards Human-Like RL: Taming Non-Naturalistic Behavior in Deep RL via Adaptive Behavioral Costs in 3D Games
Sep 27, 2023In this paper, we propose a new approach called Adaptive Behavioral Costs in Reinforcement Learning (ABC-RL) for training a human-like agent with competitive strength. While deep reinforcement learning agents have recently achieved superhuman performance in various video games, some of these unconstrained agents may exhibit actions, such as shaking and spinning, that are not typically observed in human behavior, resulting in peculiar gameplay experiences. To behave like humans and retain similar performance, ABC-RL augments behavioral limitations as cost signals in reinforcement learning with dynamically adjusted weights. Unlike traditional constrained policy optimization, we propose a new formulation that minimizes the behavioral costs subject to a constraint of the value function. By leveraging the augmented Lagrangian, our approach is an approximation of the Lagrangian adjustment, which handles the trade-off between the performance and the human-like behavior. Through experiments conducted on 3D games in DMLab-30 and Unity ML-Agents Toolkit, we demonstrate that ABC-RL achieves the same performance level while significantly reducing instances of shaking and spinning. These findings underscore the effectiveness of our proposed approach in promoting more natural and human-like behavior during gameplay.
Coordinate Ascent for Off-Policy RL with Global Convergence Guarantees
Dec 10, 2022



We revisit the domain of off-policy policy optimization in RL from the perspective of coordinate ascent. One commonly-used approach is to leverage the off-policy policy gradient to optimize a surrogate objective -- the total discounted in expectation return of the target policy with respect to the state distribution of the behavior policy. However, this approach has been shown to suffer from the distribution mismatch issue, and therefore significant efforts are needed for correcting this mismatch either via state distribution correction or a counterfactual method. In this paper, we rethink off-policy learning via Coordinate Ascent Policy Optimization (CAPO), an off-policy actor-critic algorithm that decouples policy improvement from the state distribution of the behavior policy without using the policy gradient. This design obviates the need for distribution correction or importance sampling in the policy improvement step of off-policy policy gradient. We establish the global convergence of CAPO with general coordinate selection and then further quantify the convergence rates of several instances of CAPO with popular coordinate selection rules, including the cyclic and the randomized variants of CAPO. We then extend CAPO to neural policies for a more practical implementation. Through experiments, we demonstrate that CAPO provides a competitive approach to RL in practice.
Q-Pensieve: Boosting Sample Efficiency of Multi-Objective RL Through Memory Sharing of Q-Snapshots
Dec 06, 2022Many real-world continuous control problems are in the dilemma of weighing the pros and cons, multi-objective reinforcement learning (MORL) serves as a generic framework of learning control policies for different preferences over objectives. However, the existing MORL methods either rely on multiple passes of explicit search for finding the Pareto front and therefore are not sample-efficient, or utilizes a shared policy network for coarse knowledge sharing among policies. To boost the sample efficiency of MORL, we propose Q-Pensieve, a policy improvement scheme that stores a collection of Q-snapshots to jointly determine the policy update direction and thereby enables data sharing at the policy level. We show that Q-Pensieve can be naturally integrated with soft policy iteration with convergence guarantee. To substantiate this concept, we propose the technique of Q replay buffer, which stores the learned Q-networks from the past iterations, and arrive at a practical actor-critic implementation. Through extensive experiments and an ablation study, we demonstrate that with much fewer samples, the proposed algorithm can outperform the benchmark MORL methods on a variety of MORL benchmark tasks.
Neural Frank-Wolfe Policy Optimization for Region-of-Interest Intra-Frame Coding with HEVC/H.265
Sep 27, 2022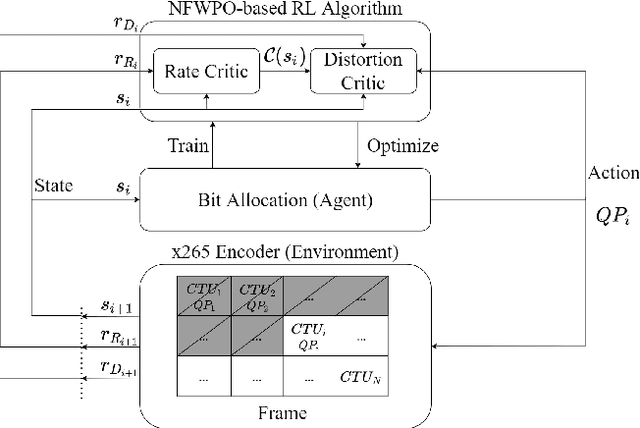
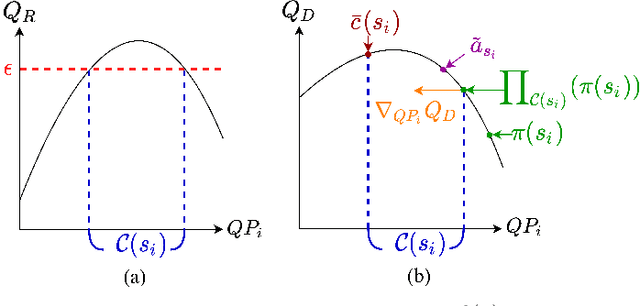
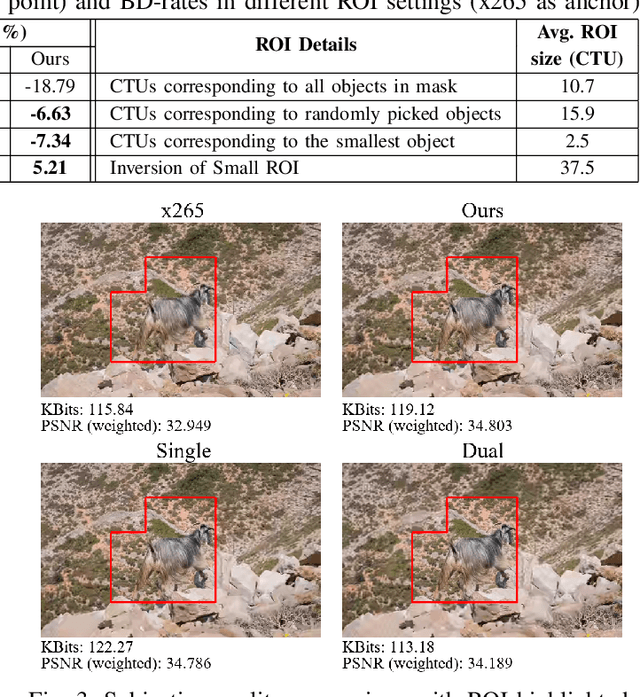
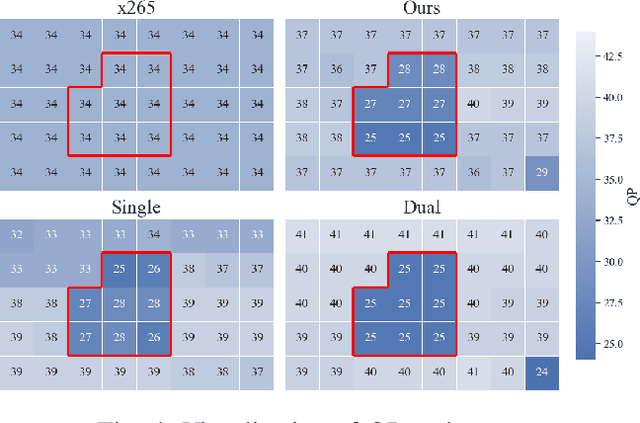
This paper presents a reinforcement learning (RL) framework that utilizes Frank-Wolfe policy optimization to solve Coding-Tree-Unit (CTU) bit allocation for Region-of-Interest (ROI) intra-frame coding. Most previous RL-based methods employ the single-critic design, where the rewards for distortion minimization and rate regularization are weighted by an empirically chosen hyper-parameter. Recently, the dual-critic design is proposed to update the actor by alternating the rate and distortion critics. However, its convergence is not guaranteed. To address these issues, we introduce Neural Frank-Wolfe Policy Optimization (NFWPO) in formulating the CTU-level bit allocation as an action-constrained RL problem. In this new framework, we exploit a rate critic to predict a feasible set of actions. With this feasible set, a distortion critic is invoked to update the actor to maximize the ROI-weighted image quality subject to a rate constraint. Experimental results produced with x265 confirm the superiority of the proposed method to the other baselines.
Neural Contextual Bandits via Reward-Biased Maximum Likelihood Estimation
Mar 08, 2022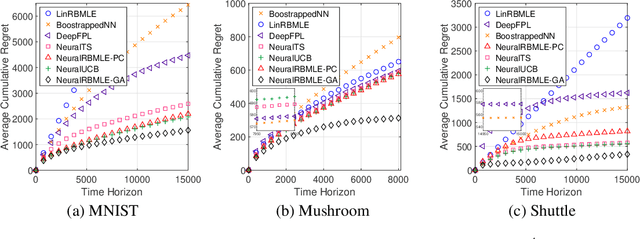
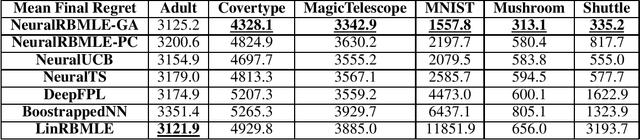
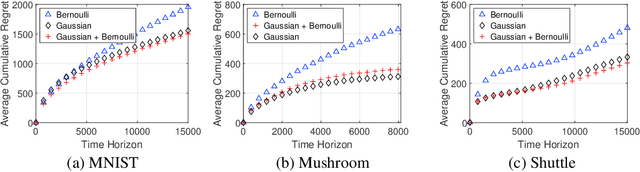
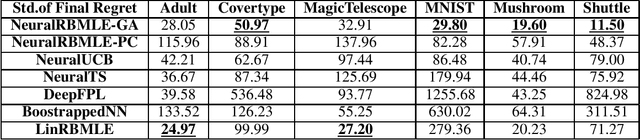
Reward-biased maximum likelihood estimation (RBMLE) is a classic principle in the adaptive control literature for tackling explore-exploit trade-offs. This paper studies the stochastic contextual bandit problem with general bounded reward functions and proposes NeuralRBMLE, which adapts the RBMLE principle by adding a bias term to the log-likelihood to enforce exploration. NeuralRBMLE leverages the representation power of neural networks and directly encodes exploratory behavior in the parameter space, without constructing confidence intervals of the estimated rewards. We propose two variants of NeuralRBMLE algorithms: The first variant directly obtains the RBMLE estimator by gradient ascent, and the second variant simplifies RBMLE to a simple index policy through an approximation. We show that both algorithms achieve $\widetilde{\mathcal{O}}(\sqrt{T})$ regret. Through extensive experiments, we demonstrate that the NeuralRBMLE algorithms achieve comparable or better empirical regrets than the state-of-the-art methods on real-world datasets with non-linear reward functions.