 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSGaussian: Progressive Rate-Distortion Compression and Segmentation for 3D Gaussian Splatting
Jan 19, 2026We present the first unified framework for rate-distortion-optimized compression and segmentation of 3D Gaussian Splatting (3DGS). While 3DGS has proven effective for both real-time rendering and semantic scene understanding, prior works have largely treated these tasks independently, leaving their joint consideration unexplored. Inspired by recent advances in rate-distortion-optimized 3DGS compression, this work integrates semantic learning into the compression pipeline to support decoder-side applications--such as scene editing and manipulation--that extend beyond traditional scene reconstruction and view synthesis. Our scheme features a lightweight implicit neural representation-based hyperprior, enabling efficient entropy coding of both color and semantic attributes while avoiding costly grid-based hyperprior as seen in many prior works. To facilitate compression and segmentation, we further develop compression-guided segmentation learning, consisting of quantization-aware training to enhance feature separability and a quality-aware weighting mechanism to suppress unreliable Gaussian primitives. Extensive experiments on the LERF and 3D-OVS datasets demonstrate that our approach significantly reduces transmission cost while preserving high rendering quality and strong segmentation performance.
Learning Optimal Linear Block Transform by Rate Distortion Minimization
Nov 27, 2024



Linear block transform coding remains a fundamental component of image and video compression. Although the Discrete Cosine Transform (DCT) is widely employed in all current compression standards, its sub-optimality has sparked ongoing research into discovering more efficient alternative transforms even for fields where it represents a consolidated tool. In this paper, we introduce a novel linear block transform called the Rate Distortion Learned Transform (RDLT), a data-driven transform specifically designed to minimize the rate-distortion (RD) cost when approximating residual blocks. Our approach builds on the latest end-to-end learned compression frameworks, adopting back-propagation and stochastic gradient descent for optimization. However, unlike the nonlinear transforms used in variational autoencoder (VAE)-based methods, the goal is to create a simpler yet optimal linear block transform, ensuring practical integration into existing image and video compression standards. Differently from existing data-driven methods that design transforms based on sample covariance matrices, such as the Karhunen-Lo\`eve Transform (KLT), the proposed RDLT is directly optimized from an RD perspective. Experimental results show that this transform significantly outperforms the DCT or other existing data-driven transforms. Additionally, it is shown that when simulating the integration of our RDLT into a VVC-like image compression framework, the proposed transform brings substantial improvements. All the code used in our experiments has been made publicly available at [1].
ComNeck: Bridging Compressed Image Latents and Multimodal LLMs via Universal Transform-Neck
Jul 29, 2024



This paper presents the first-ever study of adapting compressed image latents to suit the needs of downstream vision tasks that adopt Multimodal Large Language Models (MLLMs). MLLMs have extended the success of large language models to modalities (e.g. images) beyond text, but their billion scale hinders deployment on resource-constrained end devices. While cloud-hosted MLLMs could be available, transmitting raw, uncompressed images captured by end devices to the cloud requires an efficient image compression system. To address this, we focus on emerging neural image compression and propose a novel framework with a lightweight transform-neck and a surrogate loss to adapt compressed image latents for MLLM-based vision tasks. The proposed framework is generic and applicable to multiple application scenarios, where the neural image codec can be (1) pre-trained for human perception without updating, (2) fully updated for joint human and machine perception, or (3) fully updated for only machine perception. The transform-neck trained with the surrogate loss is universal, for it can serve various downstream vision tasks enabled by a variety of MLLMs that share the same visual encoder. Our framework has the striking feature of excluding the downstream MLLMs from training the transform-neck, and potentially the neural image codec as well. This stands out from most existing coding for machine approaches that involve downstream networks in training and thus could be impractical when the networks are MLLMs. Extensive experiments on different neural image codecs and various MLLM-based vision tasks show that our method achieves great rate-accuracy performance with much less complexity, demonstrating its effectiveness.
Transformer-based Image Compression with Variable Image Quality Objectives
Sep 22, 2023



This paper presents a Transformer-based image compression system that allows for a variable image quality objective according to the user's preference. Optimizing a learned codec for different quality objectives leads to reconstructed images with varying visual characteristics. Our method provides the user with the flexibility to choose a trade-off between two image quality objectives using a single, shared model. Motivated by the success of prompt-tuning techniques, we introduce prompt tokens to condition our Transformer-based autoencoder. These prompt tokens are generated adaptively based on the user's preference and input image through learning a prompt generation network. Extensive experiments on commonly used quality metrics demonstrate the effectiveness of our method in adapting the encoding and/or decoding processes to a variable quality objective. While offering the additional flexibility, our proposed method performs comparably to the single-objective methods in terms of rate-distortion performance.
TransTIC: Transferring Transformer-based Image Compression from Human Visualization to Machine Perception
Jun 08, 2023



This work aims for transferring a Transformer-based image compression codec from human vision to machine perception without fine-tuning the codec. We propose a transferable Transformer-based image compression framework, termed TransTIC. Inspired by visual prompt tuning, we propose an instance-specific prompt generator to inject instance-specific prompts to the encoder and task-specific prompts to the decoder. Extensive experiments show that our proposed method is capable of transferring the codec to various machine tasks and outshining the competing methods significantly. To our best knowledge, this work is the first attempt to utilize prompting on the low-level image compression task.
Transformer-based Variable-rate Image Compression with Region-of-interest Control
May 18, 2023This paper proposes a transformer-based learned image compression system. It is capable of achieving variable-rate compression with a single model while supporting the region-of-interest (ROI) functionality. Inspired by prompt tuning, we introduce prompt generation networks to condition the transformer-based autoencoder of compression. Our prompt generation networks generate content-adaptive tokens according to the input image, an ROI mask, and a rate parameter. The separation of the ROI mask and the rate parameter allows an intuitive way to achieve variable-rate and ROI coding simultaneously. Extensive experiments validate the effectiveness of our proposed method and confirm its superiority over the other competing methods.
Neural Frank-Wolfe Policy Optimization for Region-of-Interest Intra-Frame Coding with HEVC/H.265
Sep 27, 2022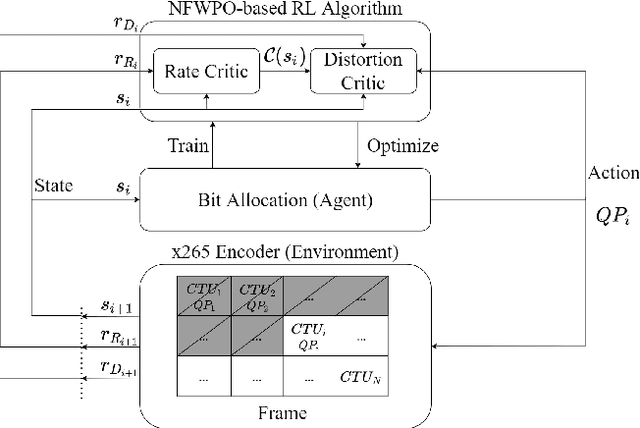
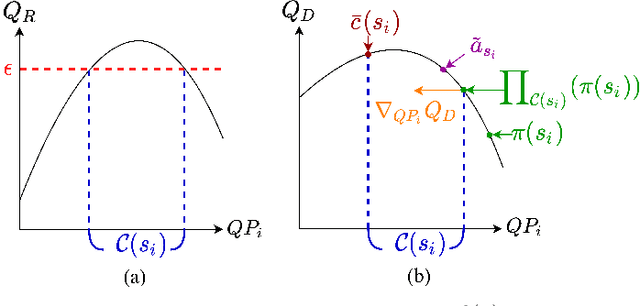
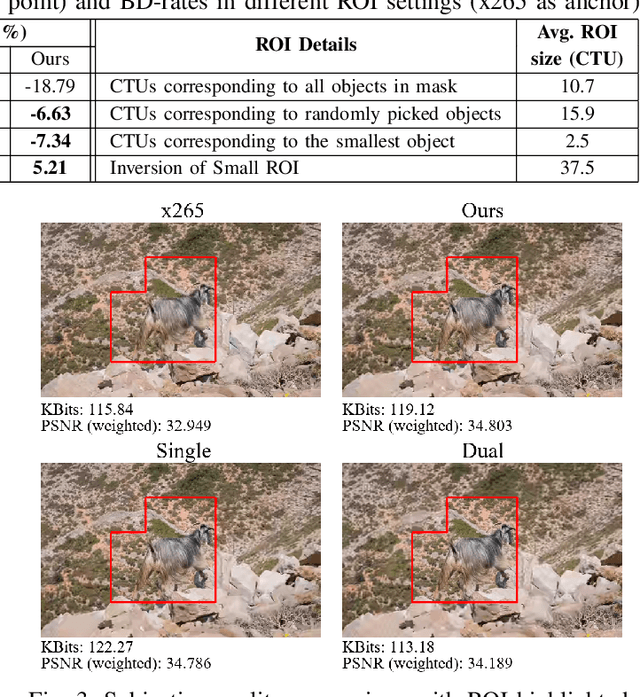
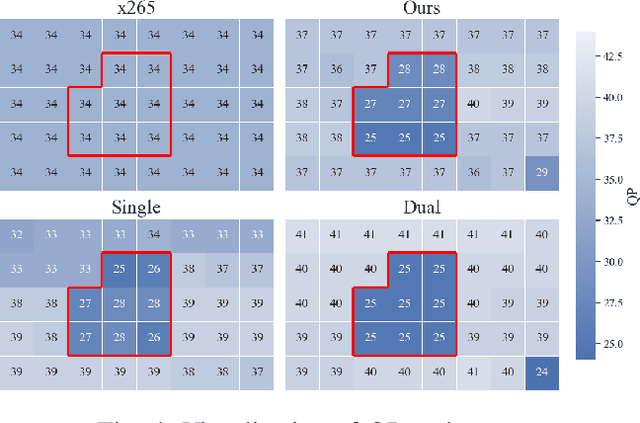
This paper presents a reinforcement learning (RL) framework that utilizes Frank-Wolfe policy optimization to solve Coding-Tree-Unit (CTU) bit allocation for Region-of-Interest (ROI) intra-frame coding. Most previous RL-based methods employ the single-critic design, where the rewards for distortion minimization and rate regularization are weighted by an empirically chosen hyper-parameter. Recently, the dual-critic design is proposed to update the actor by alternating the rate and distortion critics. However, its convergence is not guaranteed. To address these issues, we introduce Neural Frank-Wolfe Policy Optimization (NFWPO) in formulating the CTU-level bit allocation as an action-constrained RL problem. In this new framework, we exploit a rate critic to predict a feasible set of actions. With this feasible set, a distortion critic is invoked to update the actor to maximize the ROI-weighted image quality subject to a rate constraint. Experimental results produced with x265 confirm the superiority of the proposed method to the other baselines.
Action-Constrained Reinforcement Learning for Frame-Level Bit Allocation in HEVC/H.265 through Frank-Wolfe Policy Optimization
Mar 10, 2022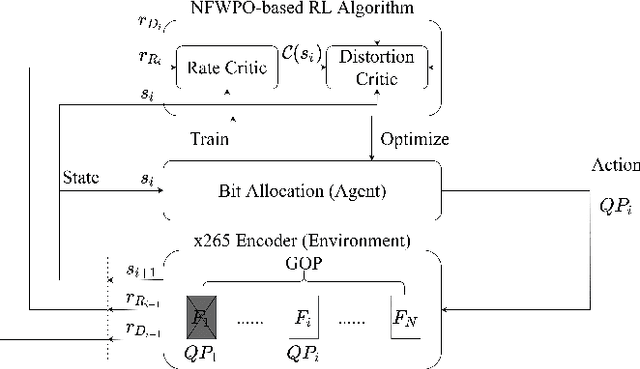
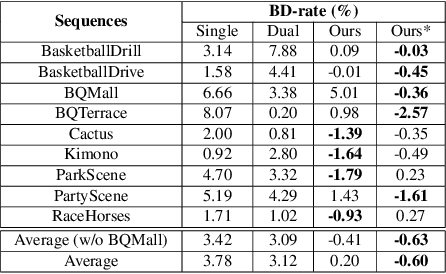
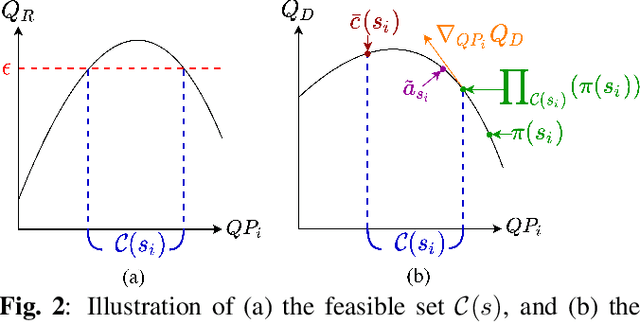
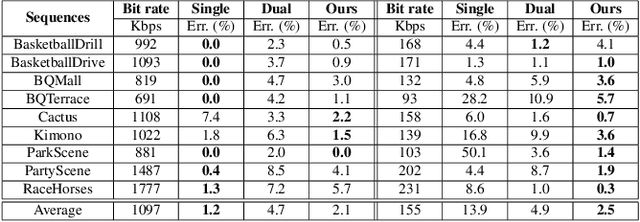
This paper presents a reinforcement learning (RL) framework that leverages Frank-Wolfe policy optimization to address frame-level bit allocation for HEVC/H.265. Most previous RL-based approaches adopt the single-critic design, which weights the rewards for distortion minimization and rate regularization by an empirically chosen hyper-parameter. More recently, the dual-critic design is proposed to update the actor network by alternating the rate and distortion critics. However, the convergence of training is not guaranteed. To address this issue, we introduce Neural Frank-Wolfe Policy Optimization (NFWPO) in formulating the frame-level bit allocation as an action-constrained RL problem. In this new framework, the rate critic serves to specify a feasible action set, and the distortion critic updates the actor network towards maximizing the reconstruction quality while conforming to the action constraint. Experimental results show that when trained to optimize the video multi-method assessment fusion (VMAF) metric, our NFWPO-based model outperforms both the single-critic and the dual-critic methods. It also demonstrates comparable rate-distortion performance to the 2-pass average bit rate control of x265.