 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferable Physical Attack against Object Detection with Separable Attention
May 19, 2022
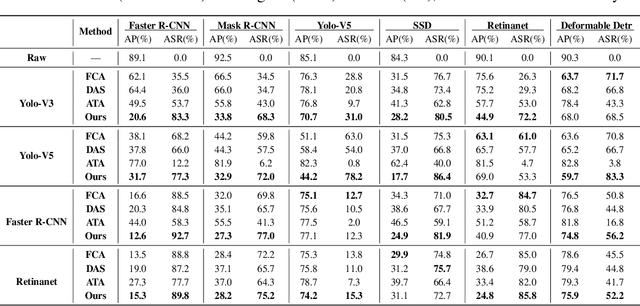
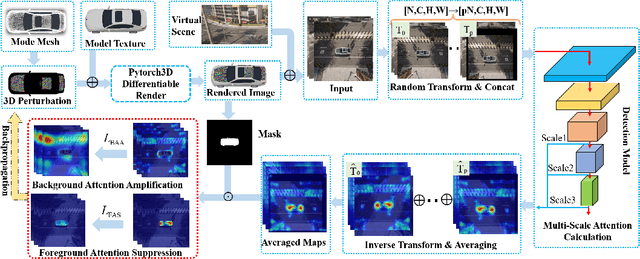
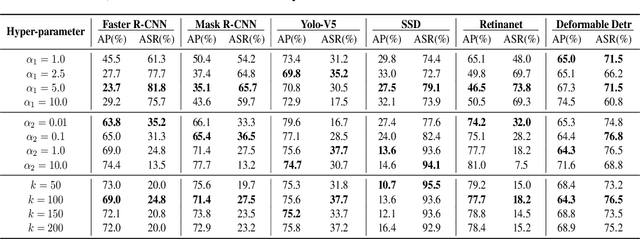
Transferable adversarial attack is always in the spotlight since deep learning models have been demonstrated to be vulnerable to adversarial samples. However, existing physical attack methods do not pay enough attention on transferability to unseen models, thus leading to the poor performance of black-box attack.In this paper, we put forward a novel method of generating physically realizable adversarial camouflage to achieve transferable attack against detection models. More specifically, we first introduce multi-scale attention maps based on detection models to capture features of objects with various resolutions. Meanwhile, we adopt a sequence of composite transformations to obtain the averaged attention maps, which could curb model-specific noise in the attention and thus further boost transferability. Unlike the general visualization interpretation methods where model attention should be put on the foreground object as much as possible, we carry out attack on separable attention from the opposite perspective, i.e. suppressing attention of the foreground and enhancing that of the background. Consequently, transferable adversarial camouflage could be yielded efficiently with our novel attention-based loss function. Extensive comparison experiments verify the superiority of our method to state-of-the-art methods.
Self-aligned Spatial Feature Extraction Network for UAV Vehicle Re-identification
Jan 08, 2022
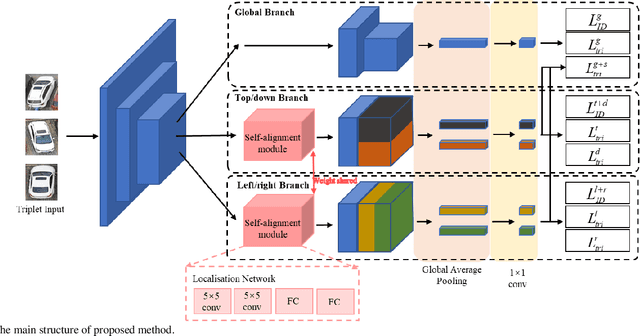

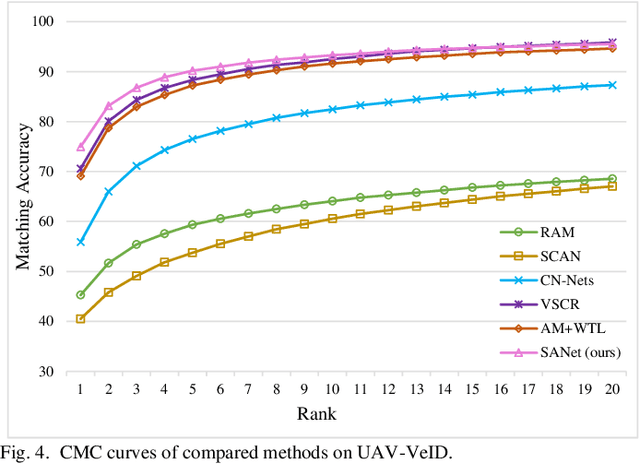
Compared with existing vehicle re-identification (ReID) tasks conducted with datasets collected by fixed surveillance cameras, vehicle ReID for unmanned aerial vehicle (UAV) is still under-explored and could be more challenging. Vehicles with the same color and type show extremely similar appearance from the UAV's perspective so that mining fine-grained characteristics becomes necessary. Recent works tend to extract distinguishing information by regional features and component features. The former requires input images to be aligned and the latter entails detailed annotations, both of which are difficult to meet in UAV application. In order to extract efficient fine-grained features and avoid tedious annotating work, this letter develops an unsupervised self-aligned network consisting of three branches. The network introduced a self-alignment module to convert the input images with variable orientations to a uniform orientation, which is implemented under the constraint of triple loss function designed with spatial features. On this basis, spatial features, obtained by vertical and horizontal segmentation methods, and global features are integrated to improve the representation ability in embedded space. Extensive experiments are conducted on UAV-VeID dataset, and our method achieves the best performance compared with recent ReID works.
Few-shot Object Detection with Self-adaptive Attention Network for Remote Sensing Images
Sep 26, 2020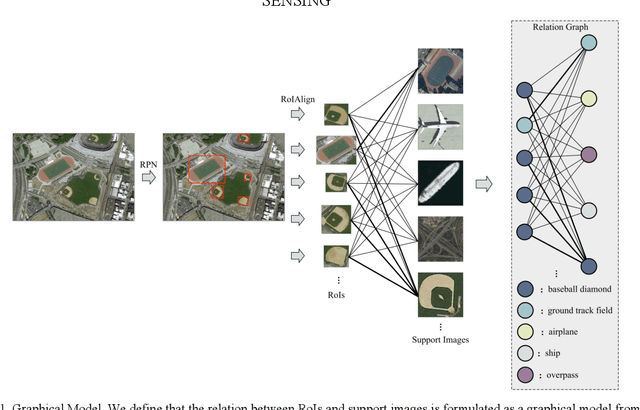
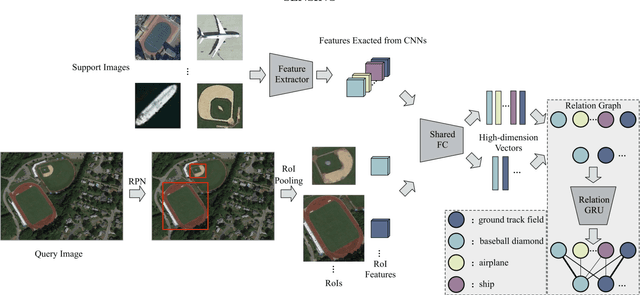
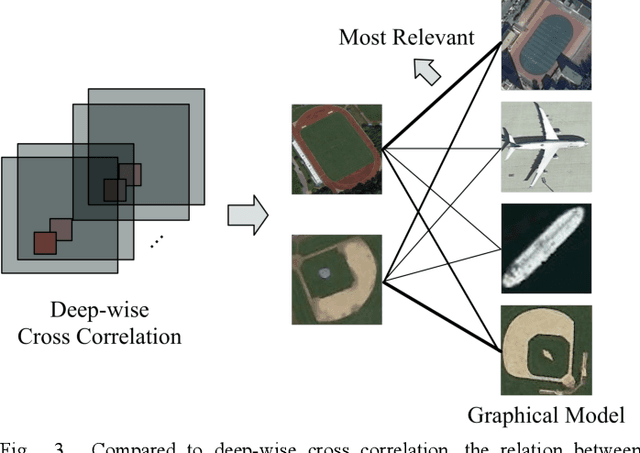
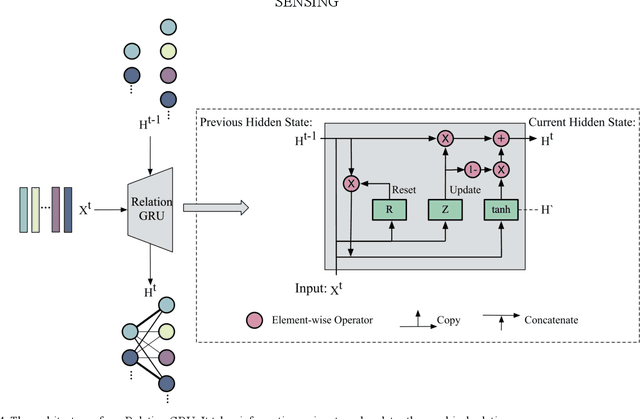
In remote sensing field, there are many applications of object detection in recent years, which demands a great number of labeled data. However, we may be faced with some cases where only limited data are available. In this paper, we proposed a few-shot object detector which is designed for detecting novel objects provided with only a few examples. Particularly, in order to fit the object detection settings, our proposed few-shot detector concentrates on the relations that lie in the level of objects instead of the full image with the assistance of Self-Adaptive Attention Network (SAAN). The SAAN can fully leverage the object-level relations through a relation GRU unit and simultaneously attach attention on object features in a self-adaptive way according to the object-level relations to avoid some situations where the additional attention is useless or even detrimental. Eventually, the detection results are produced from the features that are added with attention and thus are able to be detected simply. The experiments demonstrate the effectiveness of the proposed method in few-shot scenes.
Few-shot Object Detection with Feature Attention Highlight Module in Remote Sensing Images
Sep 03, 2020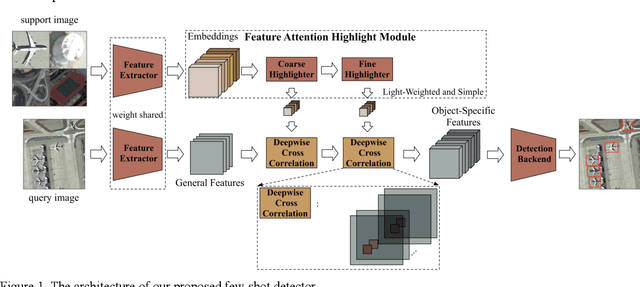
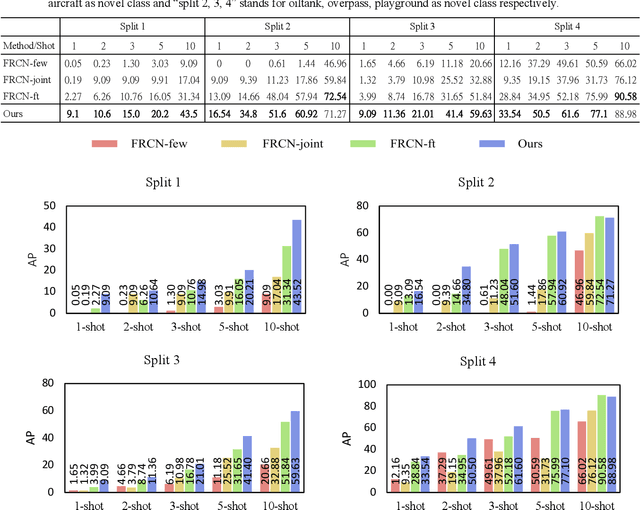
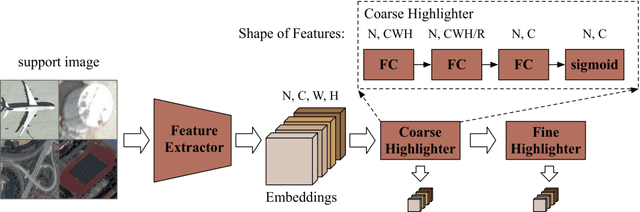
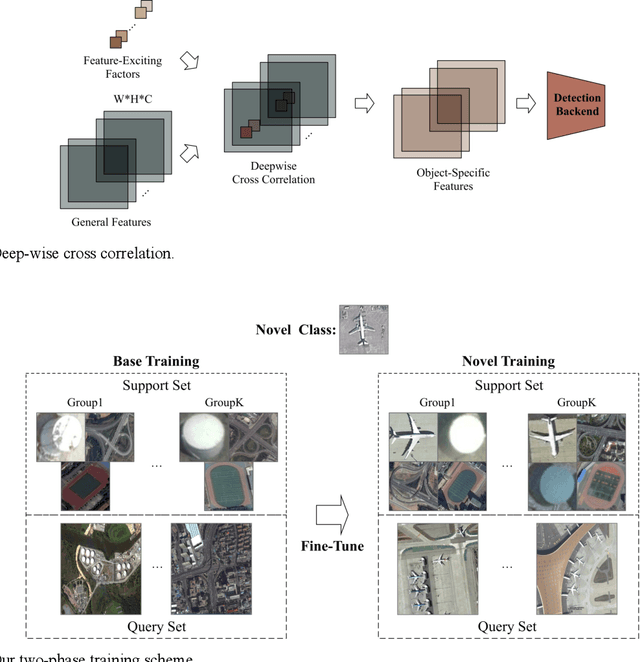
In recent years, there are many applications of object detection in remote sensing field, which demands a great number of labeled data. However, in many cases, data is extremely rare. In this paper, we proposed a few-shot object detector which is designed for detecting novel objects based on only a few examples. Through fully leveraging labeled base classes, our model that is composed of a feature-extractor, a feature attention highlight module as well as a two-stage detection backend can quickly adapt to novel classes. The pre-trained feature extractor whose parameters are shared produces general features. While the feature attention highlight module is designed to be light-weighted and simple in order to fit the few-shot cases. Although it is simple, the information provided by it in a serial way is helpful to make the general features to be specific for few-shot objects. Then the object-specific features are delivered to the two-stage detection backend for the detection results. The experiments demonstrate the effectiveness of the proposed method for few-shot cases.
Statistical Loss and Analysis for Deep Learning in Hyperspectral Image Classification
Dec 28, 2019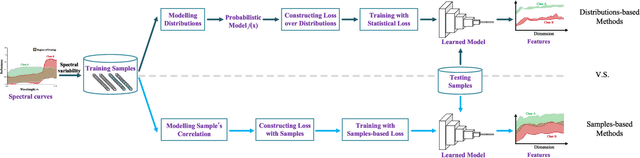
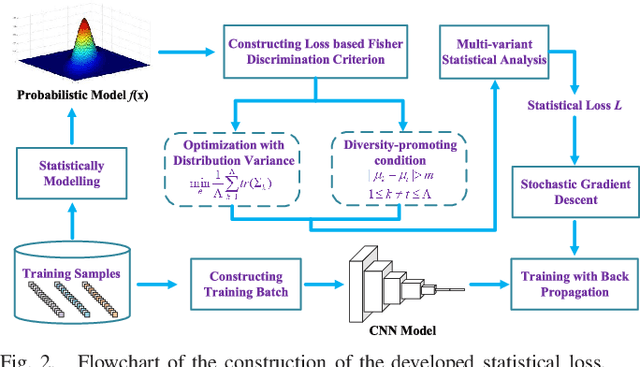

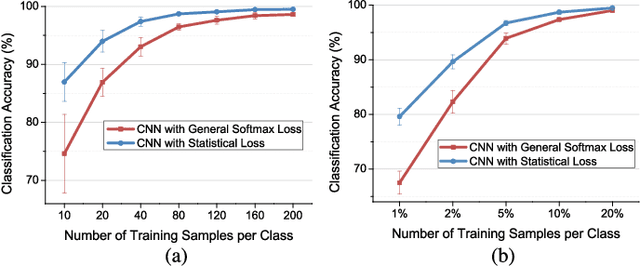
Nowadays, deep learning methods, especially the convolutional neural networks (CNNs), have shown impressive performance on extracting abstract and high-level features from the hyperspectral image. However, general training process of CNNs mainly considers the pixel-wise information or the samples' correlation to formulate the penalization while ignores the statistical properties especially the spectral variability of each class in the hyperspectral image. These samples-based penalizations would lead to the uncertainty of the training process due to the imbalanced and limited number of training samples. To overcome this problem, this work characterizes each class from the hyperspectral image as a statistical distribution and further develops a novel statistical loss with the distributions, not directly with samples for deep learning. Based on the Fisher discrimination criterion, the loss penalizes the sample variance of each class distribution to decrease the intra-class variance of the training samples. Moreover, an additional diversity-promoting condition is added to enlarge the inter-class variance between different class distributions and this could better discriminate samples from different classes in hyperspectral image. Finally, the statistical estimation form of the statistical loss is developed with the training samples through multi-variant statistical analysis. Experiments over the real-world hyperspectral images show the effectiveness of the developed statistical loss for deep learning.
Deep Manifold Embedding for Hyperspectral Image Classification
Dec 24, 2019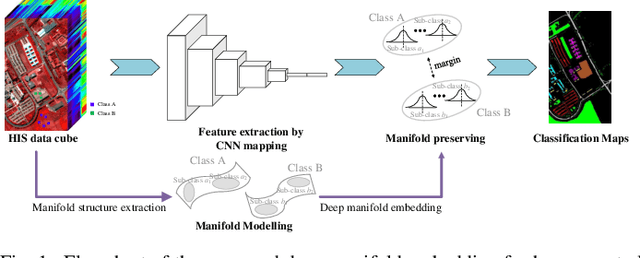

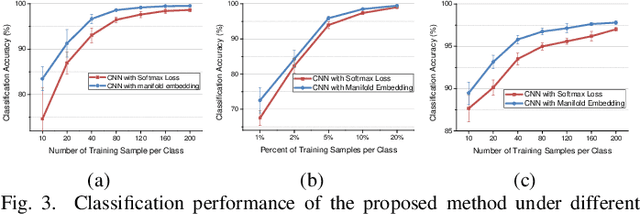
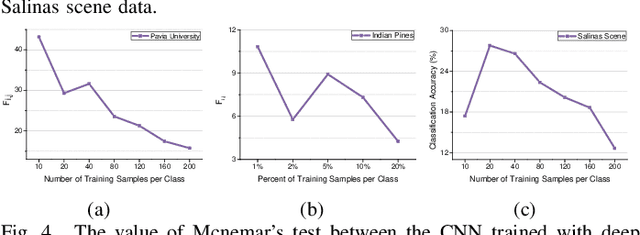
Deep learning methods have played a more and more important role in hyperspectral image classification. However, the general deep learning methods mainly take advantage of the information of sample itself or the pairwise information between samples while ignore the intrinsic data structure within the whole data. To tackle this problem, this work develops a novel deep manifold embedding method(DMEM) for hyperspectral image classification. First, each class in the image is modelled as a specific nonlinear manifold and the geodesic distance is used to measure the correlation between the samples. Then, based on the hierarchical clustering, the manifold structure of the data can be captured and each nonlinear data manifold can be divided into several sub-classes. Finally, considering the distribution of each sub-class and the correlation between different subclasses, the DMEM is constructed to preserve the estimated geodesic distances on the data manifold between the learned low dimensional features of different samples. Experiments over three real-world hyperspectral image datasets have demonstrated the effectiveness of the proposed method.
Hyperspectral Image Classification With Context-Aware Dynamic Graph Convolutional Network
Sep 26, 2019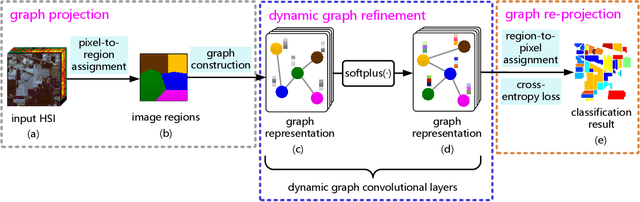
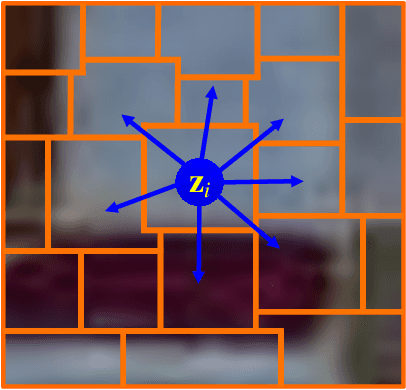

In hyperspectral image (HSI) classification, spatial context has demonstrated its significance in achieving promising performance. However, conventional spatial context-based methods simply assume that spatially neighboring pixels should correspond to the same land-cover class, so they often fail to correctly discover the contextual relations among pixels in complex situations, and thus leading to imperfect classification results on some irregular or inhomogeneous regions such as class boundaries. To address this deficiency, we develop a new HSI classification method based on the recently proposed Graph Convolutional Network (GCN), as it can flexibly encode the relations among arbitrarily structured non-Euclidean data. Different from traditional GCN, there are two novel strategies adopted by our method to further exploit the contextual relations for accurate HSI classification. First, since the receptive field of traditional GCN is often limited to fairly small neighborhood, we proposed to capture long range contextual relations in HSI by performing successive graph convolutions on a learned region-induced graph which is transformed from the original 2D image grids. Second, we refine the graph edge weight and the connective relationships among image regions by learning the improved adjacency matrix and the 'edge filter', so that the graph can be gradually refined to adapt to the representations generated by each graph convolutional layer. Such updated graph will in turn result in accurate region representations, and vice versa. The experiments carried out on three real-world benchmark datasets demonstrate that the proposed method yields significant improvement in the classification performance when compared with some state-of-the-art approaches.
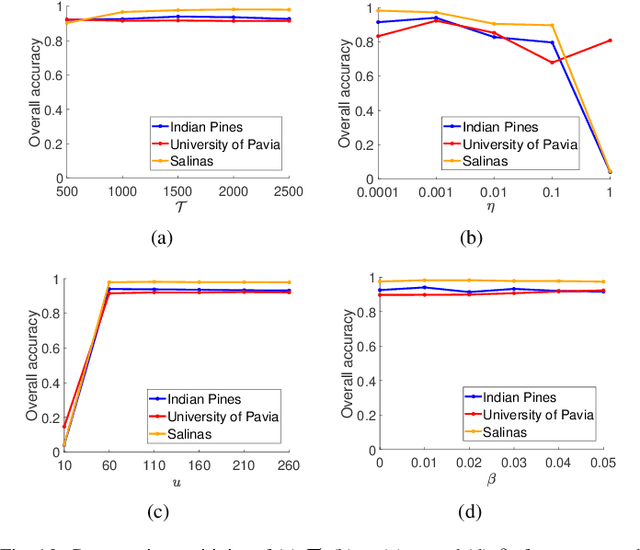
Multi-scale Dynamic Graph Convolutional Network for Hyperspectral Image Classification
May 14, 2019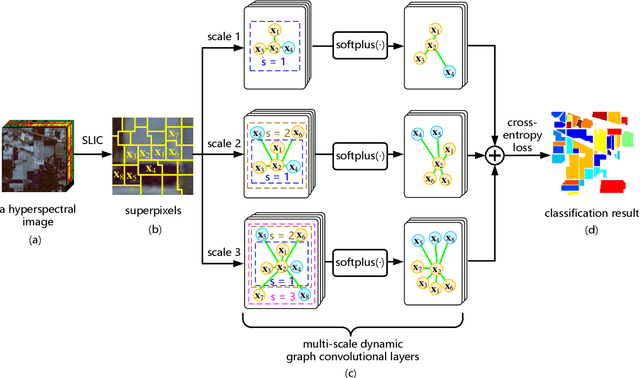
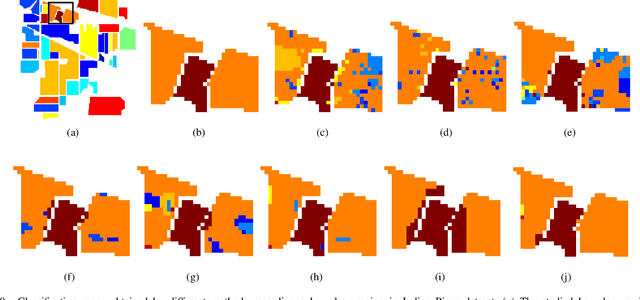
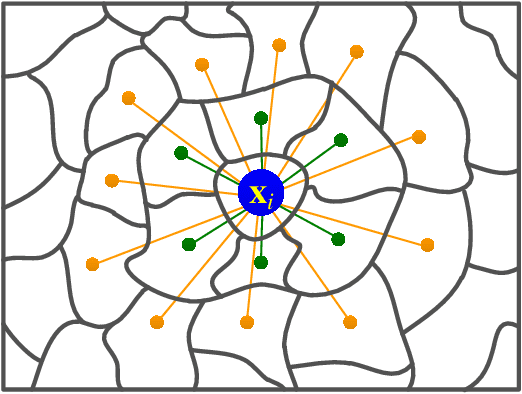
Convolutional Neural Network (CNN) has demonstrated impressive ability to represent hyperspectral images and to achieve promising results in hyperspectral image classification. However, traditional CNN models can only operate convolution on regular square image regions with fixed size and weights, so they cannot universally adapt to the distinct local regions with various object distributions and geometric appearances. Therefore, their classification performances are still to be improved, especially in class boundaries. To alleviate this shortcoming, we consider employing the recently proposed Graph Convolutional Network (GCN) for hyperspectral image classification, as it can conduct the convolution on arbitrarily structured non-Euclidean data and is applicable to the irregular image regions represented by graph topological information. Different from the commonly used GCN models which work on a fixed graph, we enable the graph to be dynamically updated along with the graph convolution process, so that these two steps can be benefited from each other to gradually produce the discriminative embedded features as well as a refined graph. Moreover, to comprehensively deploy the multi-scale information inherited by hyperspectral images, we establish multiple input graphs with different neighborhood scales to extensively exploit the diversified spectral-spatial correlations at multiple scales. Therefore, our method is termed 'Multi-scale Dynamic Graph Convolutional Network' (MDGCN). The experimental results on three typical benchmark datasets firmly demonstrate the superiority of the proposed MDGCN to other state-of-the-art methods in both qualitative and quantitative aspects.
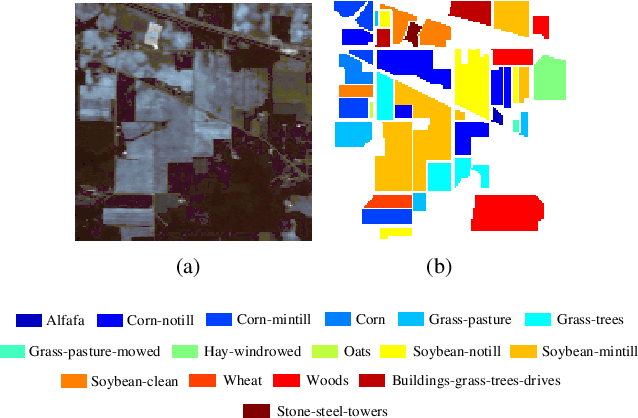
A novel statistical metric learning for hyperspectral image classification
May 13, 2019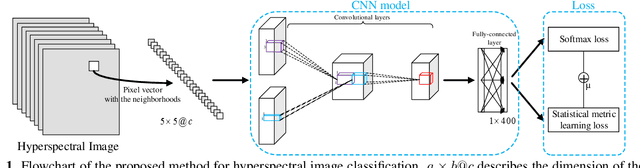
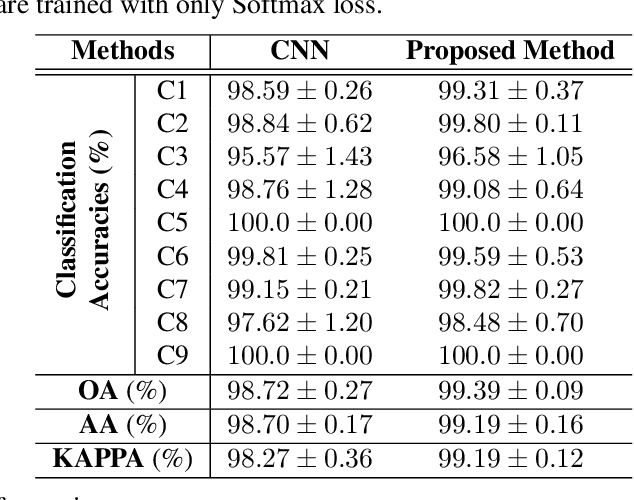

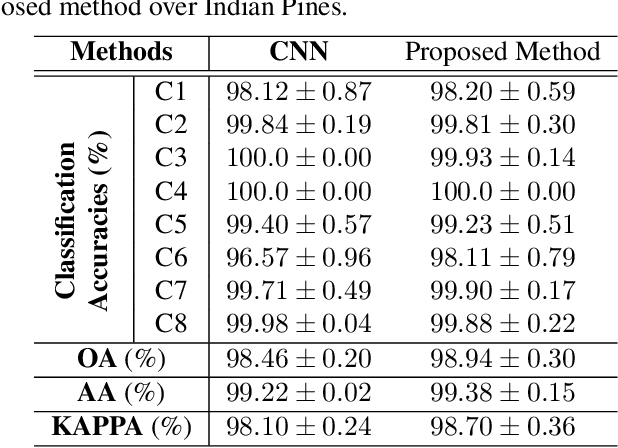
In this paper, a novel statistical metric learning is developed for spectral-spatial classification of the hyperspectral image. First, the standard variance of the samples of each class in each batch is used to decrease the intra-class variance within each class. Then, the distances between the means of different classes are used to penalize the inter-class variance of the training samples. Finally, the standard variance between the means of different classes is added as an additional diversity term to repulse different classes from each other. Experiments have conducted over two real-world hyperspectral image datasets and the experimental results have shown the effectiveness of the proposed statistical metric learning.
An End-to-End Joint Unsupervised Learning of Deep Model and Pseudo-Classes for Remote Sensing Scene Representation
Mar 18, 2019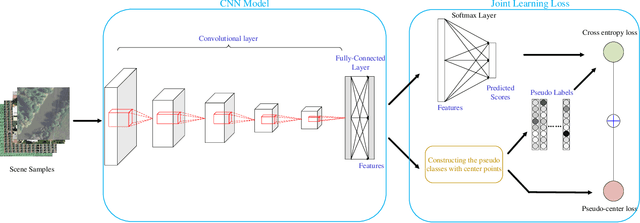
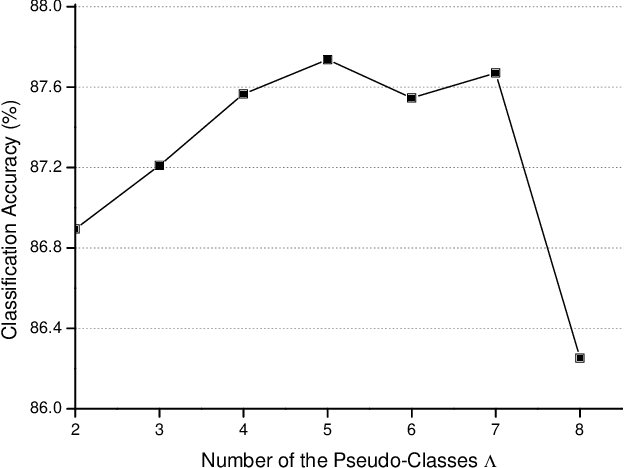
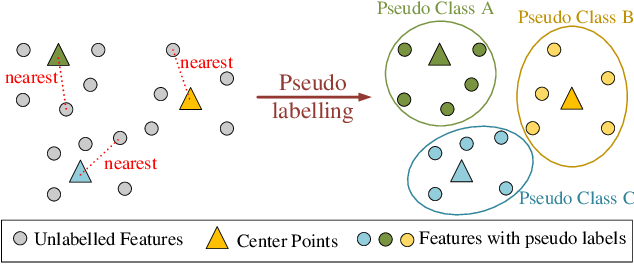

This work develops a novel end-to-end deep unsupervised learning method based on convolutional neural network (CNN) with pseudo-classes for remote sensing scene representation. First, we introduce center points as the centers of the pseudo classes and the training samples can be allocated with pseudo labels based on the center points. Therefore, the CNN model, which is used to extract features from the scenes, can be trained supervised with the pseudo labels. Moreover, a pseudo-center loss is developed to decrease the variance between the samples and the corresponding pseudo center point. The pseudo-center loss is important since it can update both the center points with the training samples and the CNN model with the center points in the training process simultaneously. Finally, joint learning of the pseudo-center loss and the pseudo softmax loss which is formulated with the samples and the pseudo labels is developed for unsupervised remote sensing scene representation to obtain discriminative representations from the scenes. Experiments are conducted over two commonly used remote sensing scene datasets to validate the effectiveness of the proposed method and the experimental results show the superiority of the proposed method when compared with other state-of-the-art methods.