 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLudwig: a type-based declarative deep learning toolbox
Sep 17, 2019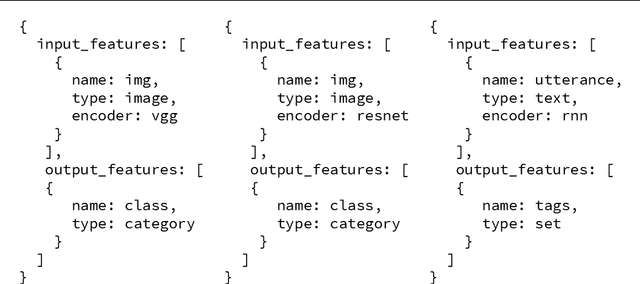
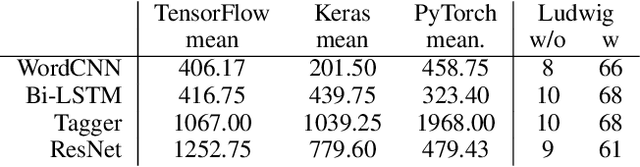
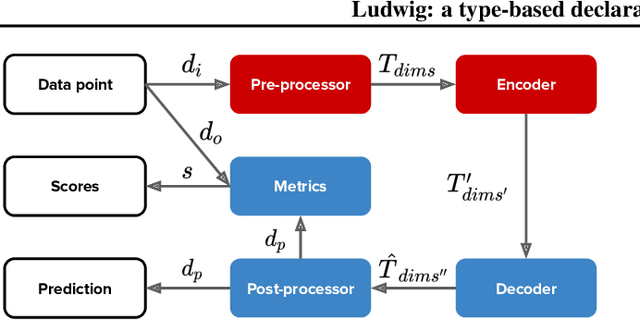
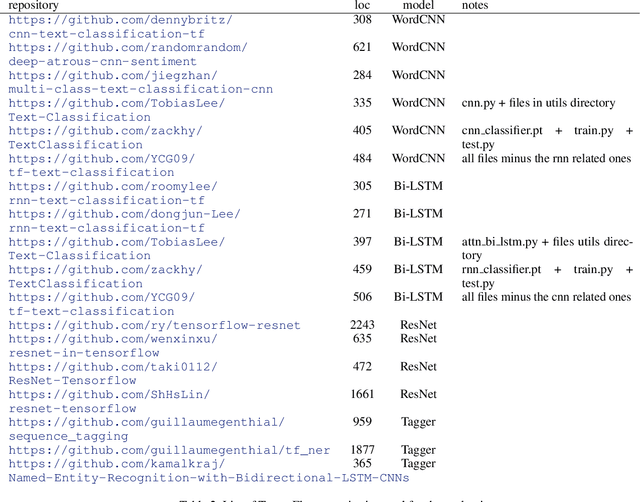
In this work we present Ludwig, a flexible, extensible and easy to use toolbox which allows users to train deep learning models and use them for obtaining predictions without writing code. Ludwig implements a novel approach to deep learning model building based on two main abstractions: data types and declarative configuration files. The data type abstraction allows for easier code and sub-model reuse, and the standardized interfaces imposed by this abstraction allow for encapsulation and make the code easy to extend. Declarative model definition configuration files enable inexperienced users to obtain effective models and increase the productivity of expert users. Alongside these two innovations, Ludwig introduces a general modularized deep learning architecture called Encoder-Combiner-Decoder that can be instantiated to perform a vast amount of machine learning tasks. These innovations make it possible for engineers, scientists from other fields and, in general, a much broader audience to adopt deep learning models for their tasks, concretely helping in its democratization.
Modeling Multi-Action Policy for Task-Oriented Dialogues
Aug 30, 2019
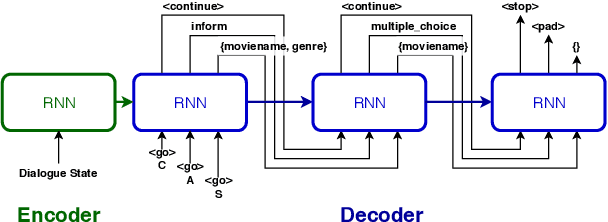
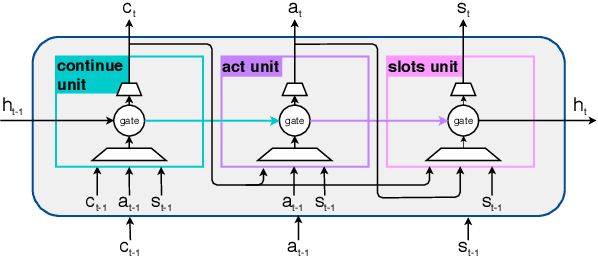

Dialogue management (DM) plays a key role in the quality of the interaction with the user in a task-oriented dialogue system. In most existing approaches, the agent predicts only one DM policy action per turn. This significantly limits the expressive power of the conversational agent and introduces unwanted turns of interactions that may challenge users' patience. Longer conversations also lead to more errors and the system needs to be more robust to handle them. In this paper, we compare the performance of several models on the task of predicting multiple acts for each turn. A novel policy model is proposed based on a recurrent cell called gated Continue-Act-Slots (gCAS) that overcomes the limitations of the existing models. Experimental results show that gCAS outperforms other approaches. The code is available at https://leishu02.github.io/
Flexibly-Structured Model for Task-Oriented Dialogues
Aug 06, 2019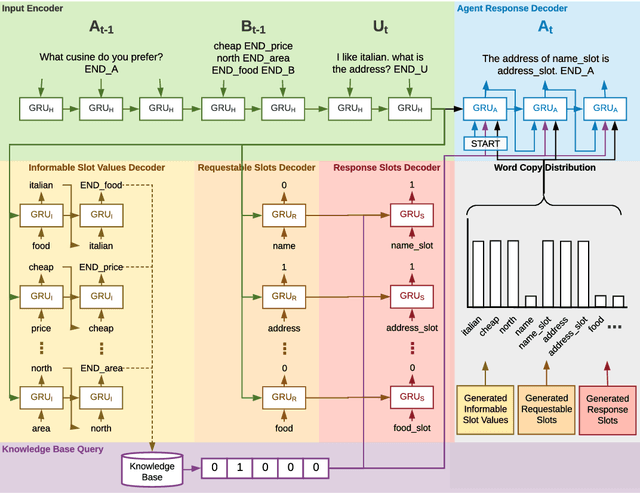
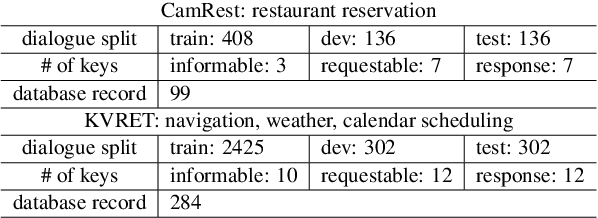

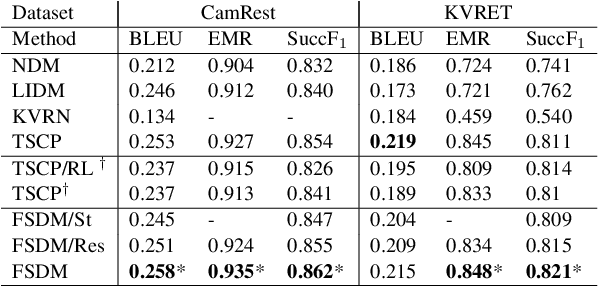
This paper proposes a novel end-to-end architecture for task-oriented dialogue systems. It is based on a simple and practical yet very effective sequence-to-sequence approach, where language understanding and state tracking tasks are modeled jointly with a structured copy-augmented sequential decoder and a multi-label decoder for each slot. The policy engine and language generation tasks are modeled jointly following that. The copy-augmented sequential decoder deals with new or unknown values in the conversation, while the multi-label decoder combined with the sequential decoder ensures the explicit assignment of values to slots. On the generation part, slot binary classifiers are used to improve performance. This architecture is scalable to real-world scenarios and is shown through an empirical evaluation to achieve state-of-the-art performance on both the Cambridge Restaurant dataset and the Stanford in-car assistant dataset\footnote{The code is available at \url{https://github.com/uber-research/FSDM}}
Collaborative Multi-Agent Dialogue Model Training Via Reinforcement Learning
Jul 24, 2019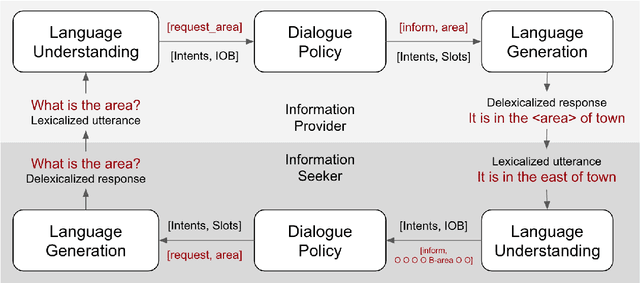

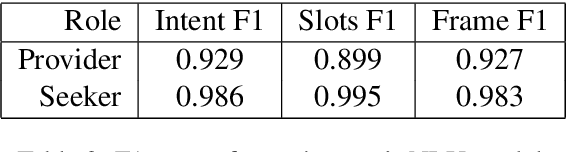
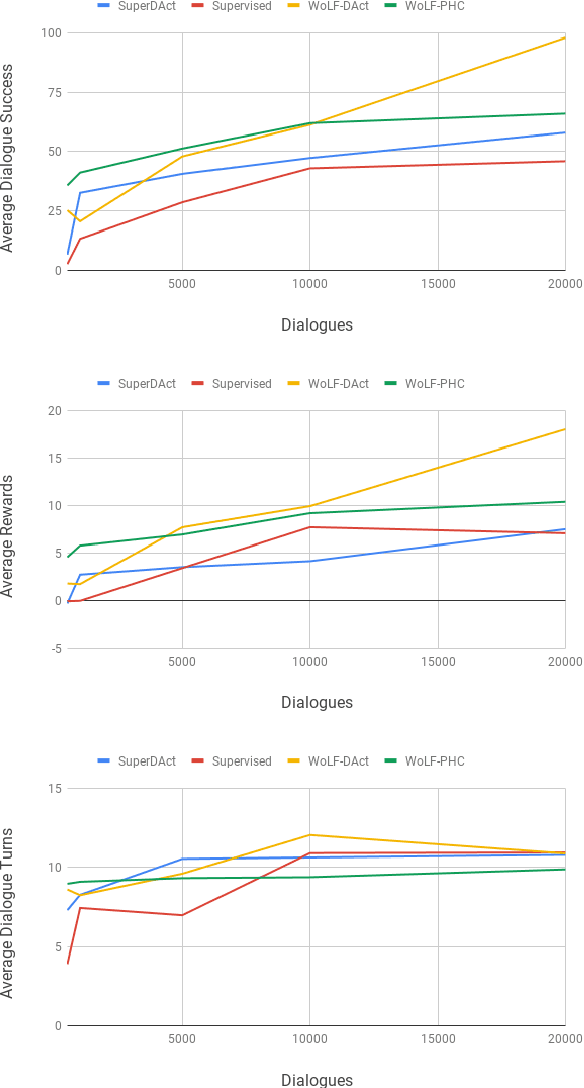
We present the first complete attempt at concurrently training conversational agents that communicate only via self-generated language. Using DSTC2 as seed data, we trained natural language understanding (NLU) and generation (NLG) networks for each agent and let the agents interact online. We model the interaction as a stochastic collaborative game where each agent (player) has a role ("assistant", "tourist", "eater", etc.) and their own objectives, and can only interact via natural language they generate. Each agent, therefore, needs to learn to operate optimally in an environment with multiple sources of uncertainty (its own NLU and NLG, the other agent's NLU, Policy, and NLG). In our evaluation, we show that the stochastic-game agents outperform deep learning based supervised baselines.
Parallax: Visualizing and Understanding the Semantics of Embedding Spaces via Algebraic Formulae
May 28, 2019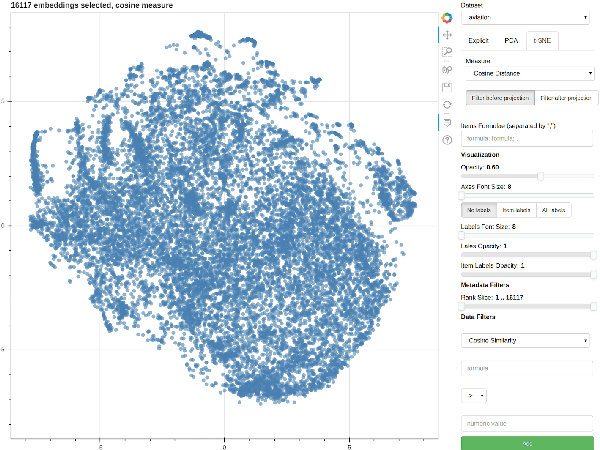
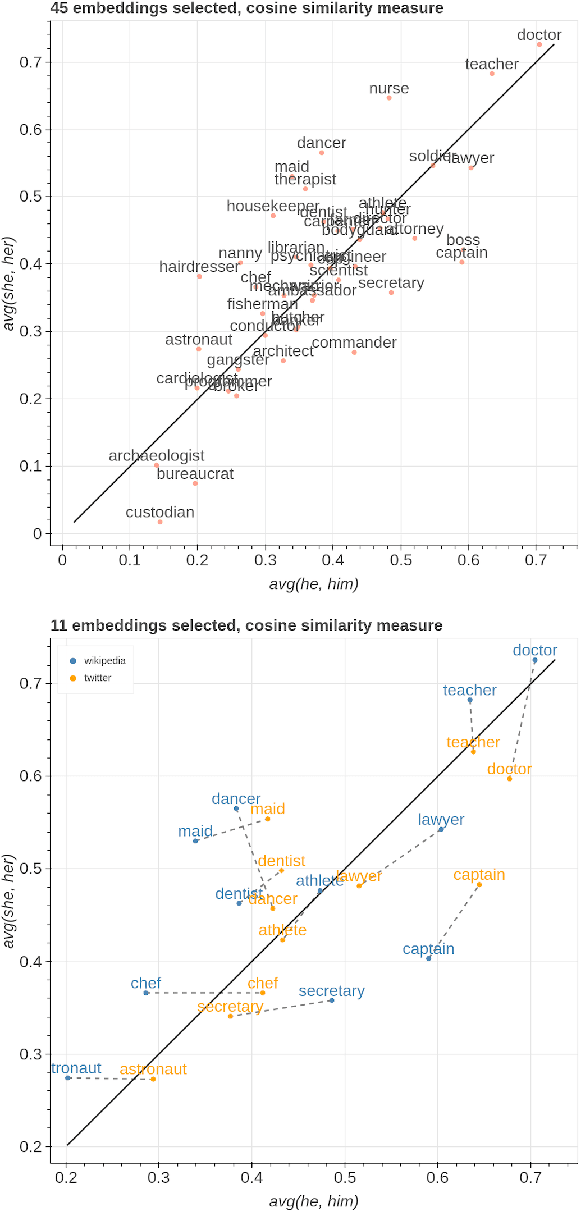
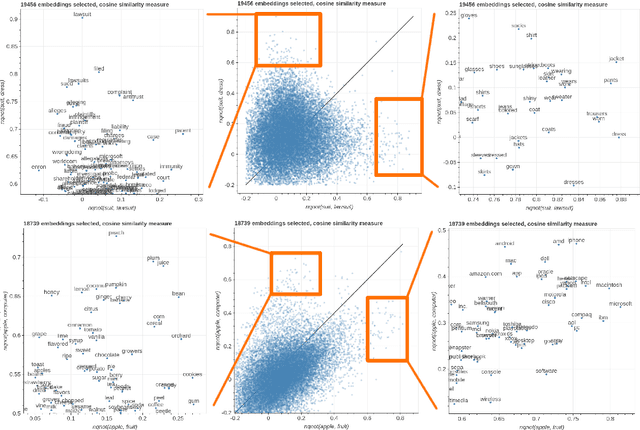
Embeddings are a fundamental component of many modern machine learning and natural language processing models. Understanding them and visualizing them is essential for gathering insights about the information they capture and the behavior of the models. State of the art in analyzing embeddings consists in projecting them in two-dimensional planes without any interpretable semantics associated to the axes of the projection, which makes detailed analyses and comparison among multiple sets of embeddings challenging. In this work, we propose to use explicit axes defined as algebraic formulae over embeddings to project them into a lower dimensional, but semantically meaningful subspace, as a simple yet effective analysis and visualization methodology. This methodology assigns an interpretable semantics to the measures of variability and the axes of visualizations, allowing for both comparisons among different sets of embeddings and fine-grained inspection of the embedding spaces. We demonstrate the power of the proposed methodology through a series of case studies that make use of visualizations constructed around the underlying methodology and through a user study. The results show how the methodology is effective at providing more profound insights than classical projection methods and how it is widely applicable to many other use cases.
Manifold: A Model-Agnostic Framework for Interpretation and Diagnosis of Machine Learning Models
Aug 01, 2018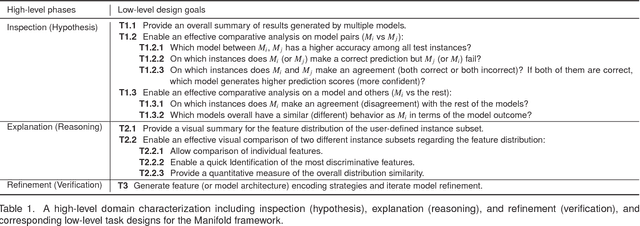
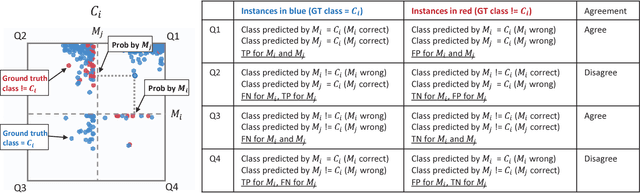

Interpretation and diagnosis of machine learning models have gained renewed interest in recent years with breakthroughs in new approaches. We present Manifold, a framework that utilizes visual analysis techniques to support interpretation, debugging, and comparison of machine learning models in a more transparent and interactive manner. Conventional techniques usually focus on visualizing the internal logic of a specific model type (i.e., deep neural networks), lacking the ability to extend to a more complex scenario where different model types are integrated. To this end, Manifold is designed as a generic framework that does not rely on or access the internal logic of the model and solely observes the input (i.e., instances or features) and the output (i.e., the predicted result and probability distribution). We describe the workflow of Manifold as an iterative process consisting of three major phases that are commonly involved in the model development and diagnosis process: inspection (hypothesis), explanation (reasoning), and refinement (verification). The visual components supporting these tasks include a scatterplot-based visual summary that overviews the models' outcome and a customizable tabular view that reveals feature discrimination. We demonstrate current applications of the framework on the classification and regression tasks and discuss other potential machine learning use scenarios where Manifold can be applied.
An Intriguing Failing of Convolutional Neural Networks and the CoordConv Solution
Jul 09, 2018

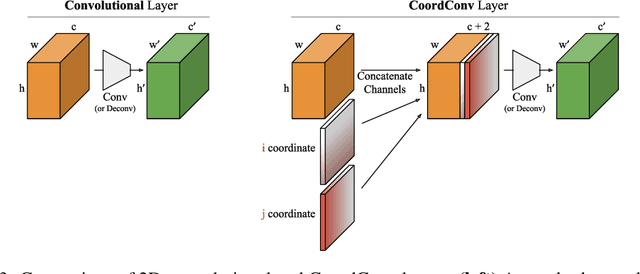
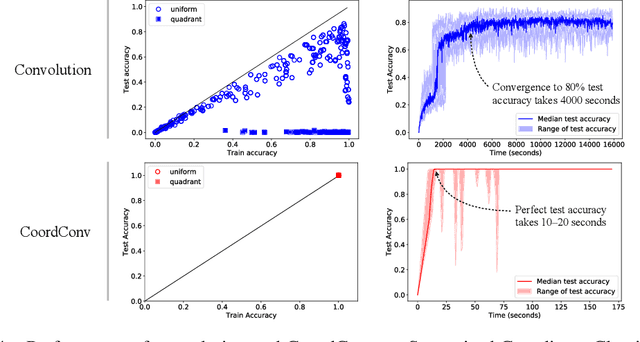
Few ideas have enjoyed as large an impact on deep learning as convolution. For any problem involving pixels or spatial representations, common intuition holds that convolutional neural networks may be appropriate. In this paper we show a striking counterexample to this intuition via the seemingly trivial coordinate transform problem, which simply requires learning a mapping between coordinates in (x,y) Cartesian space and one-hot pixel space. Although convolutional networks would seem appropriate for this task, we show that they fail spectacularly. We demonstrate and carefully analyze the failure first on a toy problem, at which point a simple fix becomes obvious. We call this solution CoordConv, which works by giving convolution access to its own input coordinates through the use of extra coordinate channels. Without sacrificing the computational and parametric efficiency of ordinary convolution, CoordConv allows networks to learn either perfect translation invariance or varying degrees of translation dependence, as required by the task. CoordConv solves the coordinate transform problem with perfect generalization and 150 times faster with 10--100 times fewer parameters than convolution. This stark contrast raises the question: to what extent has this inability of convolution persisted insidiously inside other tasks, subtly hampering performance from within? A complete answer to this question will require further investigation, but we show preliminary evidence that swapping convolution for CoordConv can improve models on a diverse set of tasks. Using CoordConv in a GAN produced less mode collapse as the transform between high-level spatial latents and pixels becomes easier to learn. A Faster R-CNN detection model trained on MNIST detection showed 24% better IOU when using CoordConv, and in the RL domain agents playing Atari games benefit significantly from the use of CoordConv layers.
COTA: Improving the Speed and Accuracy of Customer Support through Ranking and Deep Networks
Jul 03, 2018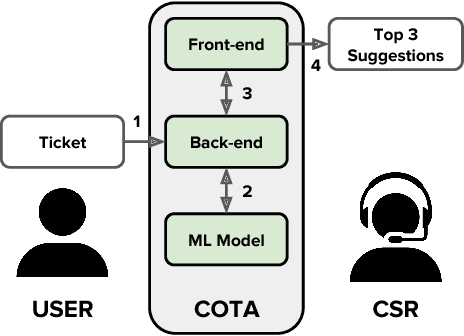
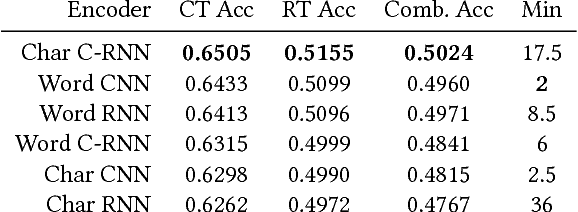
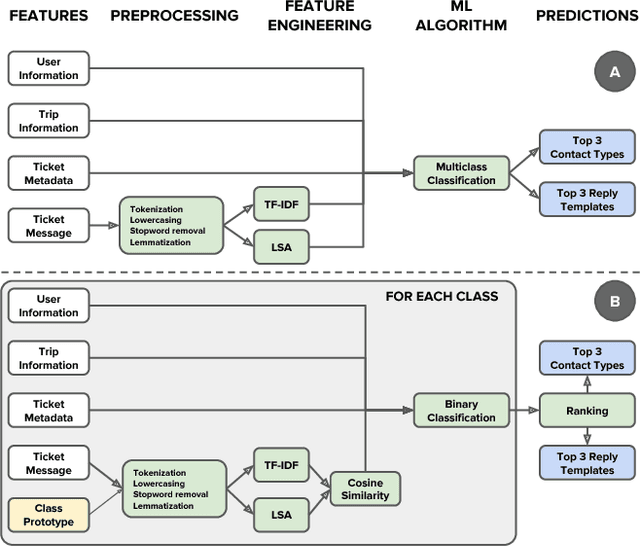

For a company looking to provide delightful user experiences, it is of paramount importance to take care of any customer issues. This paper proposes COTA, a system to improve speed and reliability of customer support for end users through automated ticket classification and answers selection for support representatives. Two machine learning and natural language processing techniques are demonstrated: one relying on feature engineering (COTA v1) and the other exploiting raw signals through deep learning architectures (COTA v2). COTA v1 employs a new approach that converts the multi-classification task into a ranking problem, demonstrating significantly better performance in the case of thousands of classes. For COTA v2, we propose an Encoder-Combiner-Decoder, a novel deep learning architecture that allows for heterogeneous input and output feature types and injection of prior knowledge through network architecture choices. This paper compares these models and their variants on the task of ticket classification and answer selection, showing model COTA v2 outperforms COTA v1, and analyzes their inner workings and shortcomings. Finally, an A/B test is conducted in a production setting validating the real-world impact of COTA in reducing issue resolution time by 10 percent without reducing customer satisfaction.