 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjectness-Guided Open Set Visual Search and Closed Set Detection
Dec 11, 2020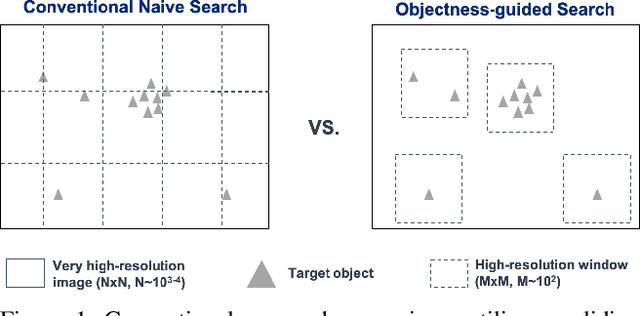

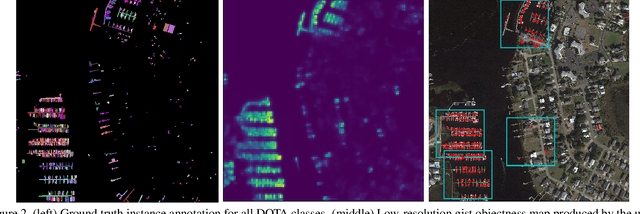
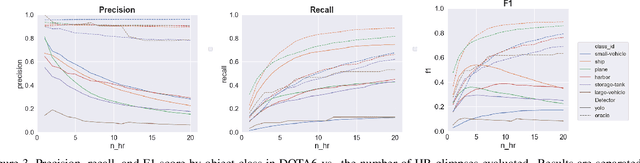
Searching for small objects in large images is currently challenging for deep learning systems, but is a task with numerous applications including remote sensing and medical imaging. Thorough scanning of very large images is computationally expensive, particularly at resolutions sufficient to capture small objects. The smaller an object of interest, the more likely it is to be obscured by clutter or otherwise deemed insignificant. We examine these issues in the context of two complementary problems: closed-set object detection and open-set target search. First, we present a method for predicting pixel-level objectness from a low resolution gist image, which we then use to select regions for subsequent evaluation at high resolution. This approach has the benefit of not being fixed to a predetermined grid, allowing fewer costly high-resolution glimpses than existing methods. Second, we propose a novel strategy for open-set visual search that seeks to find all objects in an image of the same class as a given target reference image. We interpret both detection problems through a probabilistic, Bayesian lens, whereby the objectness maps produced by our method serve as priors in a maximum-a-posteriori approach to the detection step. We evaluate the end-to-end performance of both the combination of our patch selection strategy with this target search approach and the combination of our patch selection strategy with standard object detection methods. Both our patch selection and target search approaches are seen to significantly outperform baseline strategies.
Random Projections for Adversarial Attack Detection
Dec 11, 2020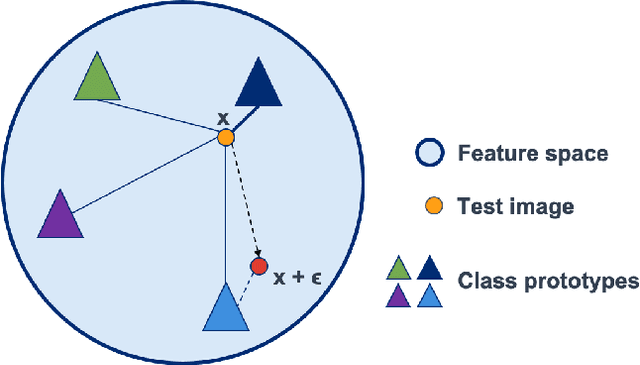
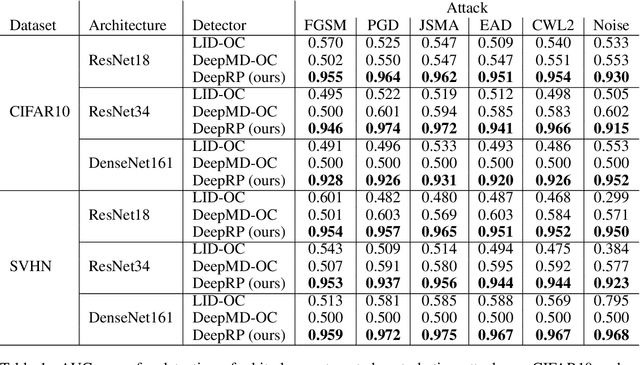
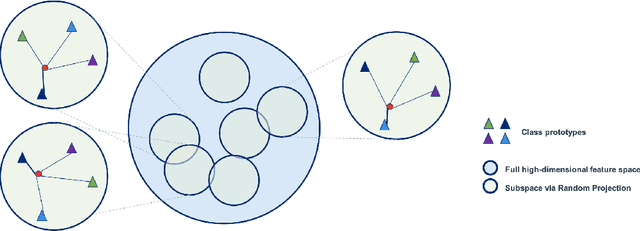
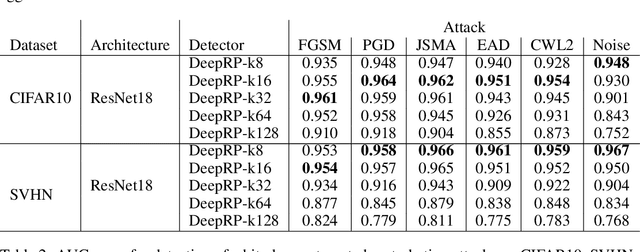
Whilst adversarial attack detection has received considerable attention, it remains a fundamentally challenging problem from two perspectives. First, while threat models can be well-defined, attacker strategies may still vary widely within those constraints. Therefore, detection should be considered as an open-set problem, standing in contrast to most current detection strategies. These methods take a closed-set view and train binary detectors, thus biasing detection toward attacks seen during detector training. Second, information is limited at test time and confounded by nuisance factors including the label and underlying content of the image. Many of the current high-performing techniques use training sets for dealing with some of these issues, but can be limited by the overall size and diversity of those sets during the detection step. We address these challenges via a novel strategy based on random subspace analysis. We present a technique that makes use of special properties of random projections, whereby we can characterize the behavior of clean and adversarial examples across a diverse set of subspaces. We then leverage the self-consistency (or inconsistency) of model activations to discern clean from adversarial examples. Performance evaluation demonstrates that our technique outperforms ($>0.92$ AUC) competing state of the art (SOTA) attack strategies, while remaining truly agnostic to the attack method itself. It also requires significantly less training data, composed only of clean examples, when compared to competing SOTA methods, which achieve only chance performance, when evaluated in a more rigorous testing scenario.
Rényi Generative Adversarial Networks
Jun 03, 2020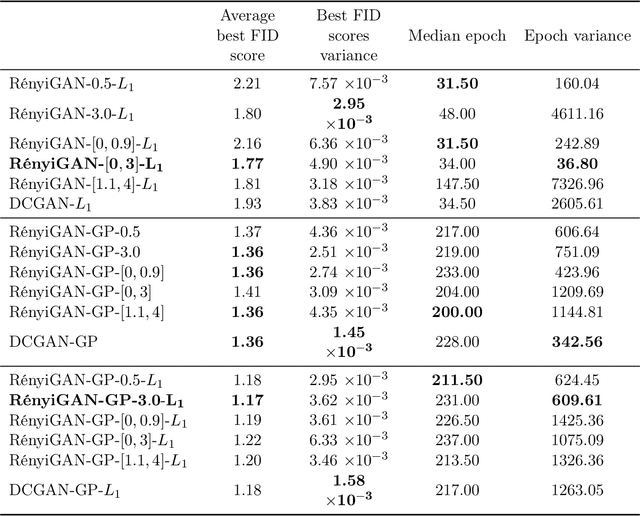
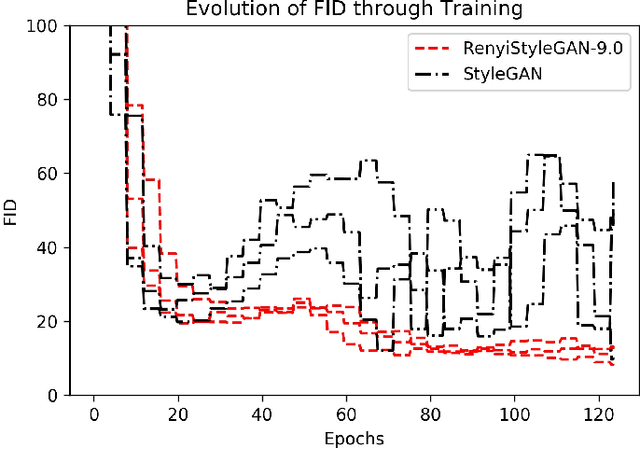
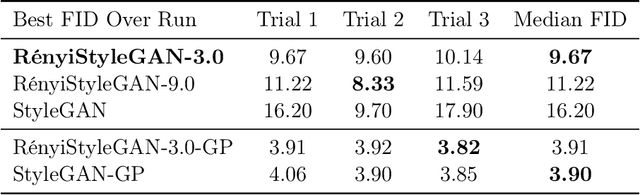
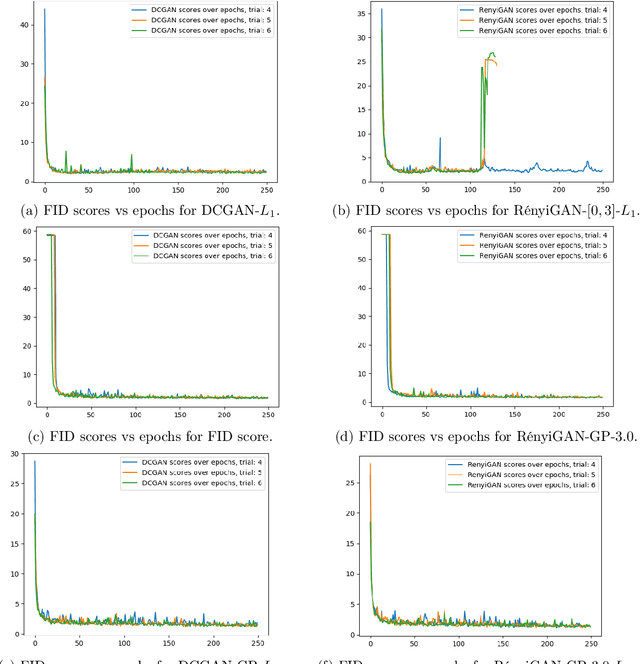
We propose a loss function for generative adversarial networks (GANs) using R\'{e}nyi information measures with parameter $\alpha$. More specifically, we formulate GAN's generator loss function in terms of R\'{e}nyi cross-entropy functionals. We demonstrate that for any $\alpha$, this generalized loss function preserves the equilibrium point satisfied by the original GAN loss based on the Jensen-Renyi divergence, a natural extension of the Jensen-Shannon divergence. We also prove that the R\'{e}nyi-centric loss function reduces to the original GAN loss function as $\alpha \to 1$. We show empirically that the proposed loss function, when implemented on both DCGAN (with $L_1$ normalization) and StyleGAN architectures, confers performance benefits by virtue of the extra degree of freedom provided by the parameter $\alpha$. More specifically, we show improvements with regard to: (a) the quality of the generated images as measured via the Fr\'echet Inception Distance (FID) score (e.g., best FID=8.33 for RenyiStyleGAN vs 9.7 for StyleGAN when evaluated over 64$\times$64 CelebA images) and (b) training stability. While it was applied to GANs in this study, the proposed approach is generic and can be used in other applications of information theory to deep learning, e.g., AI bias or privacy.
Addressing Artificial Intelligence Bias in Retinal Disease Diagnostics
May 08, 2020
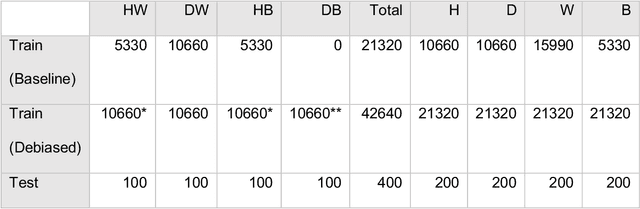
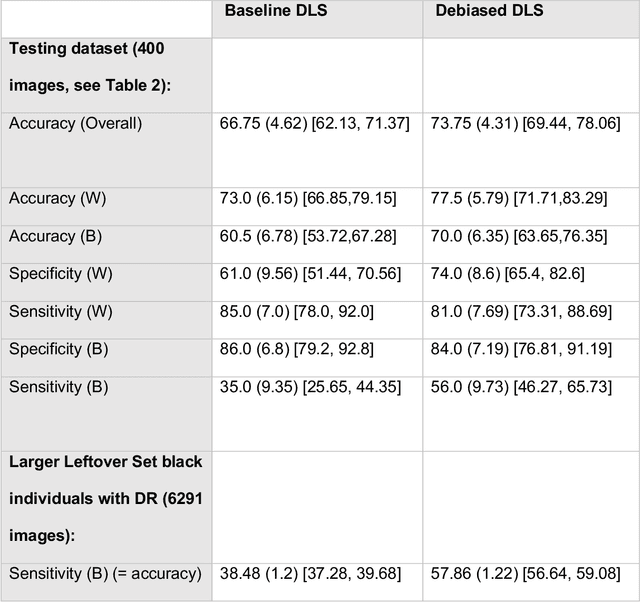
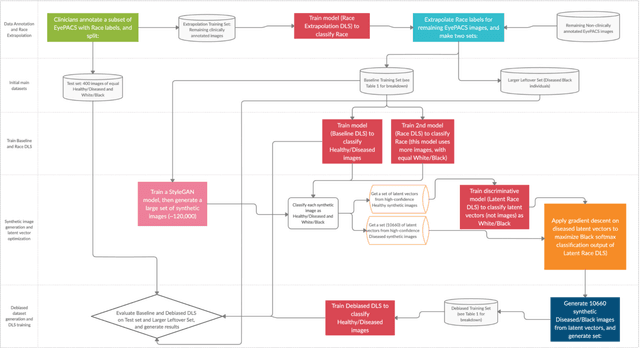
This study evaluated novel AI and deep learning generative methods to address AI bias for retinal diagnostic applications when specifically applied to diabetic retinopathy (DR). Bias often results from data imbalance. We specifically considered here a strong form of data imbalance corresponding to domain shift, where AI classifiers are faced at inference time with data and concepts they were not trained on initially (here the concept of diseased black individuals). A baseline DR diagnostics DLS designed to solve a two-class problem of referable vs not referable DR was used. We modified the public domain Kaggle-EyePACS dataset (88,692 fundi and 44,346 individuals), which was originally designed to be diverse with regard to ethnicity, as follows: 1) we expanded it to include clinician-annotated labels for race since those were not publicly available; 2) we excluded training exemplars for diseased black individuals in training, but not testing, to construct a new scenario of data imbalance with domain shift. For this domain shifted scenario, the accuracy (95% confidence intervals [CI]) of the baseline DR diagnostics DLS for whites was 73.0% (66.9%,79.2%) vs. blacks of 60.5% (53.5%,67.3%], demonstrating disparity of AI performance as measured by accuracy across races. By contrast, an AI approach leveraging generative models was used to train a new diagnostic DLS with additional synthetically generated data for the missing subpopulation (diseased blacks), which achieved accuracy for whites of 77.5% (71.7%,83.3%) and for blacks of 70.0% (63.7%,76.4%), demonstrating closer parity in accuracy across races. The new debiased DLS also showed improvement in sensitivity of over 21% for blacks, with the same level of specificity, when compared with the baseline DLS. These findings demonstrate the potential benefits of using novel generative methods for debiasing AI.
Jacks of All Trades, Masters Of None: Addressing Distributional Shift and Obtrusiveness via Transparent Patch Attacks
May 01, 2020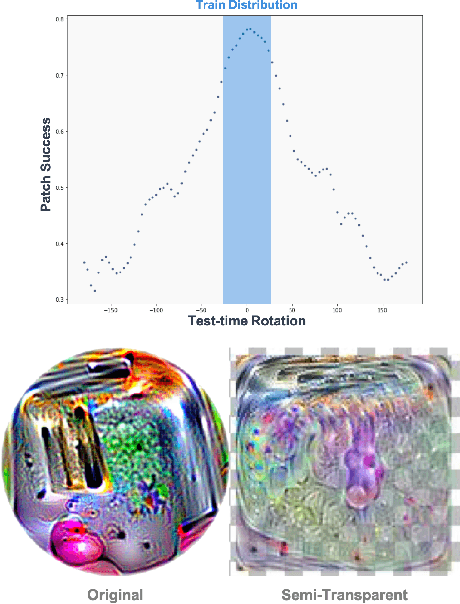
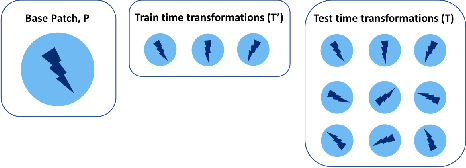
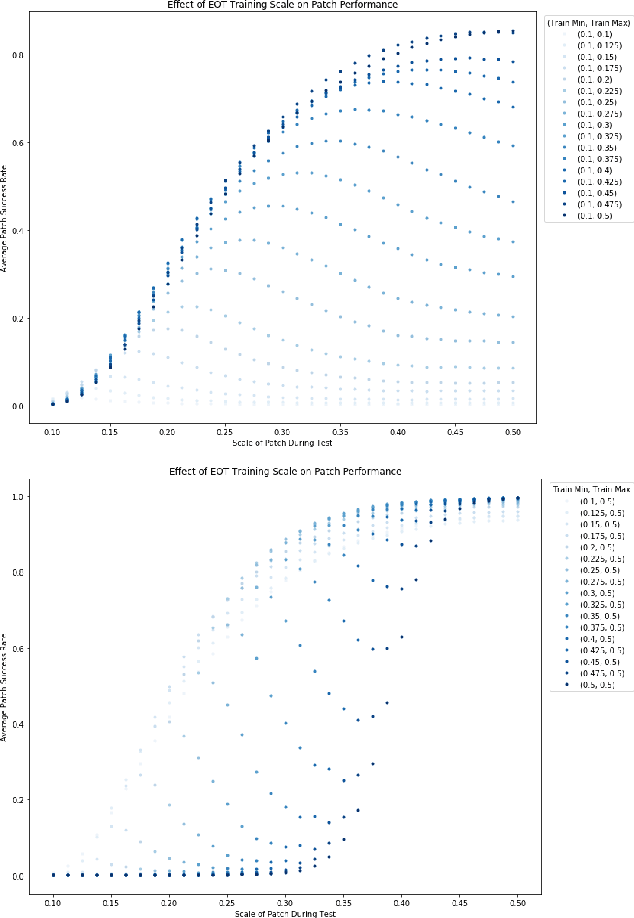
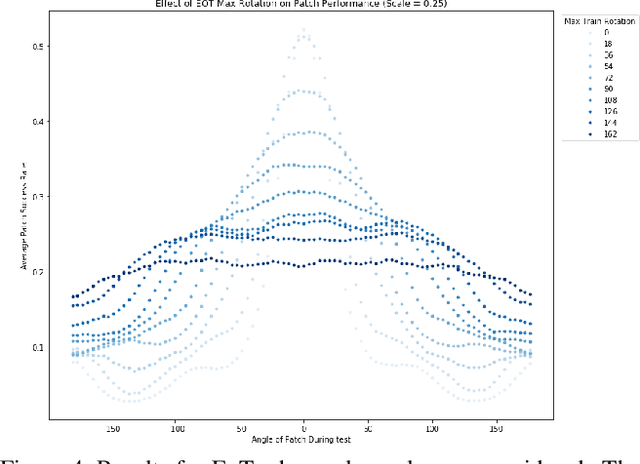
We focus on the development of effective adversarial patch attacks and -- for the first time -- jointly address the antagonistic objectives of attack success and obtrusiveness via the design of novel semi-transparent patches. This work is motivated by our pursuit of a systematic performance analysis of patch attack robustness with regard to geometric transformations. Specifically, we first elucidate a) key factors underpinning patch attack success and b) the impact of distributional shift between training and testing/deployment when cast under the Expectation over Transformation (EoT) formalism. By focusing our analysis on three principal classes of transformations (rotation, scale, and location), our findings provide quantifiable insights into the design of effective patch attacks and demonstrate that scale, among all factors, significantly impacts patch attack success. Working from these findings, we then focus on addressing how to overcome the principal limitations of scale for the deployment of attacks in real physical settings: namely the obtrusiveness of large patches. Our strategy is to turn to the novel design of irregularly-shaped, semi-transparent partial patches which we construct via a new optimization process that jointly addresses the antagonistic goals of mitigating obtrusiveness and maximizing effectiveness. Our study -- we hope -- will help encourage more focus in the community on the issues of obtrusiveness, scale, and success in patch attacks.
Unsupervised Semantic Attribute Discovery and Control in Generative Models
Feb 25, 2020
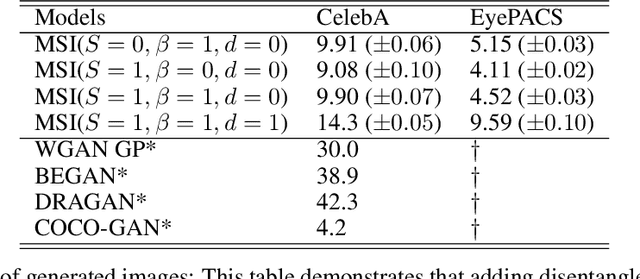
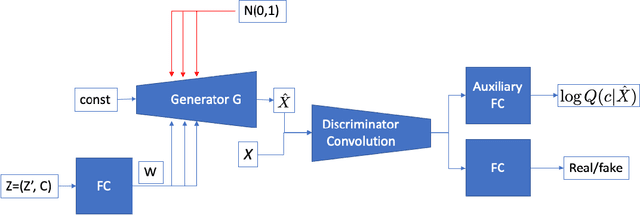

This work focuses on the ability to control via latent space factors semantic image attributes in generative models, and the faculty to discover mappings from factors to attributes in an unsupervised fashion. The discovery of controllable semantic attributes is of special importance, as it would facilitate higher level tasks such as unsupervised representation learning to improve anomaly detection, or the controlled generation of novel data for domain shift and imbalanced datasets. The ability to control semantic attributes is related to the disentanglement of latent factors, which dictates that latent factors be "uncorrelated" in their effects. Unfortunately, despite past progress, the connection between control and disentanglement remains, at best, confused and entangled, requiring clarifications we hope to provide in this work. To this end, we study the design of algorithms for image generation that allow unsupervised discovery and control of semantic attributes.We make several contributions: a) We bring order to the concepts of control and disentanglement, by providing an analytical derivation that connects mutual information maximization, which promotes attribute control, to total correlation minimization, which relates to disentanglement. b) We propose hybrid generative model architectures that use mutual information maximization with multi-scale style transfer. c) We introduce a novel metric to characterize the performance of semantic attributes control. We report experiments that appear to demonstrate, quantitatively and qualitatively, the ability of the proposed model to perform satisfactory control while still preserving competitive visual quality. We compare to other state of the art methods (e.g., Frechet inception distance (FID)= 9.90 on CelebA and 4.52 on EyePACS).
Occupancy Map Prediction Using Generative and Fully Convolutional Networks for Vehicle Navigation
Mar 06, 2018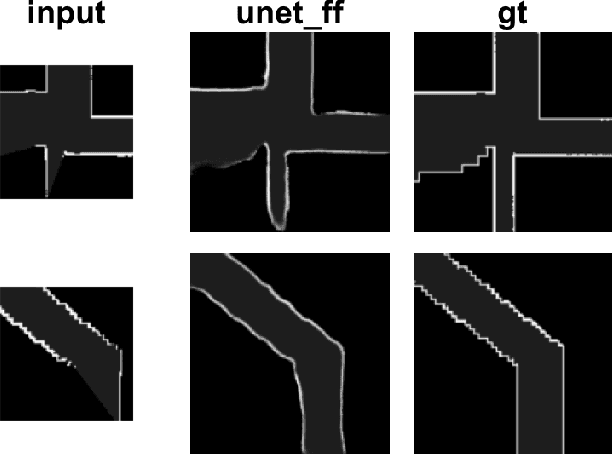
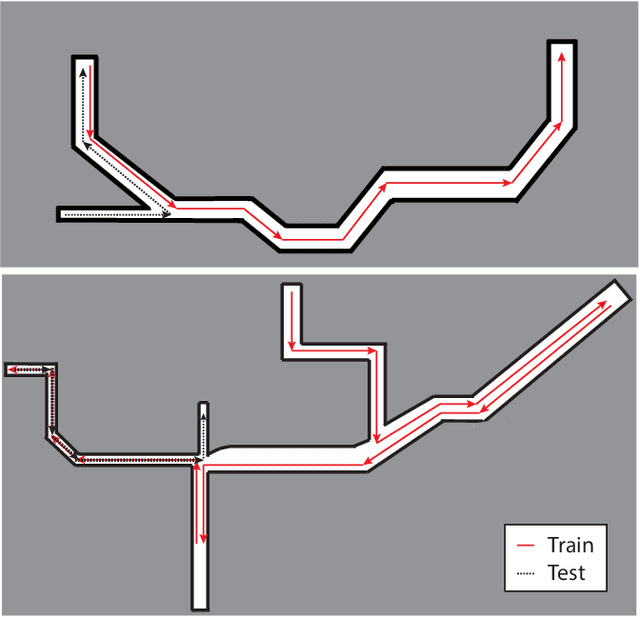

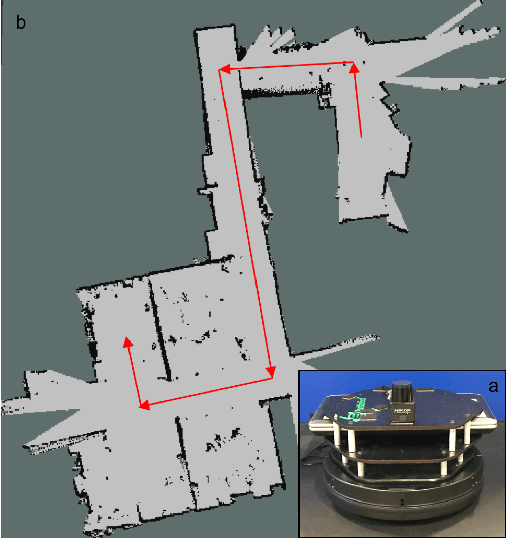
Fast, collision-free motion through unknown environments remains a challenging problem for robotic systems. In these situations, the robot's ability to reason about its future motion is often severely limited by sensor field of view (FOV). By contrast, biological systems routinely make decisions by taking into consideration what might exist beyond their FOV based on prior experience. In this paper, we present an approach for predicting occupancy map representations of sensor data for future robot motions using deep neural networks. We evaluate several deep network architectures, including purely generative and adversarial models. Testing on both simulated and real environments we demonstrated performance both qualitatively and quantitatively, with SSIM similarity measure up to 0.899. We showed that it is possible to make predictions about occupied space beyond the physical robot's FOV from simulated training data. In the future, this method will allow robots to navigate through unknown environments in a faster, safer manner.