 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Diffusion: Score Matching for General Corruptions
Sep 12, 2022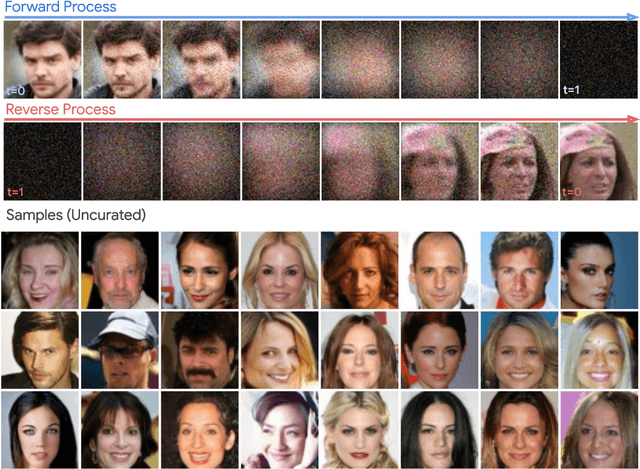

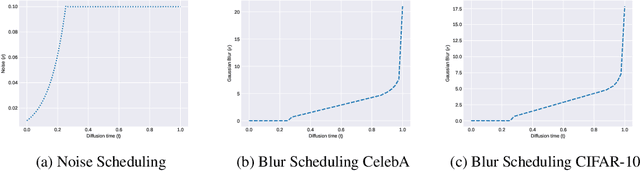

We define a broader family of corruption processes that generalizes previously known diffusion models. To reverse these general diffusions, we propose a new objective called Soft Score Matching that provably learns the score function for any linear corruption process and yields state of the art results for CelebA. Soft Score Matching incorporates the degradation process in the network and trains the model to predict a clean image that after corruption matches the diffused observation. We show that our objective learns the gradient of the likelihood under suitable regularity conditions for the family of corruption processes. We further develop a principled way to select the corruption levels for general diffusion processes and a novel sampling method that we call Momentum Sampler. We evaluate our framework with the corruption being Gaussian Blur and low magnitude additive noise. Our method achieves state-of-the-art FID score $1.85$ on CelebA-64, outperforming all previous linear diffusion models. We also show significant computational benefits compared to vanilla denoising diffusion.
MaxViT: Multi-Axis Vision Transformer
Apr 04, 2022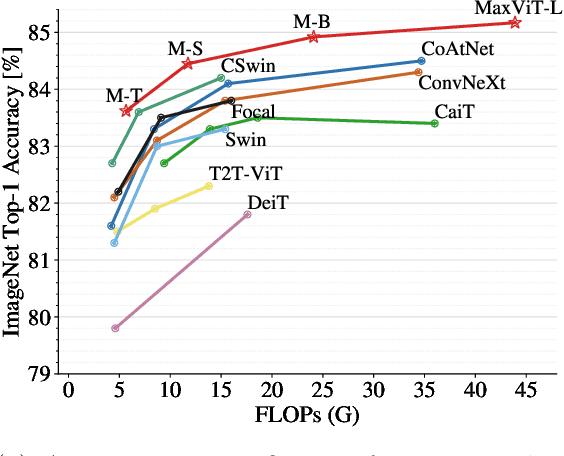

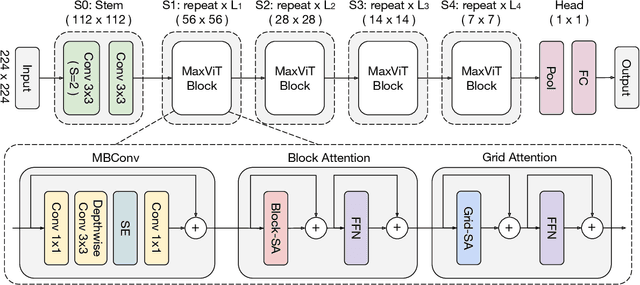
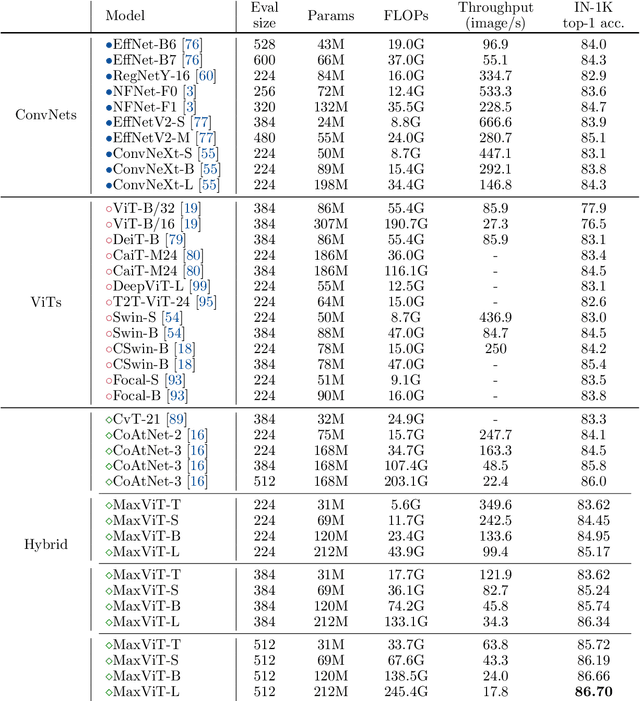
Transformers have recently gained significant attention in the computer vision community. However, the lack of scalability of self-attention mechanisms with respect to image size has limited their wide adoption in state-of-the-art vision backbones. In this paper we introduce an efficient and scalable attention model we call multi-axis attention, which consists of two aspects: blocked local and dilated global attention. These design choices allow global-local spatial interactions on arbitrary input resolutions with only linear complexity. We also present a new architectural element by effectively blending our proposed attention model with convolutions, and accordingly propose a simple hierarchical vision backbone, dubbed MaxViT, by simply repeating the basic building block over multiple stages. Notably, MaxViT is able to "see" globally throughout the entire network, even in earlier, high-resolution stages. We demonstrate the effectiveness of our model on a broad spectrum of vision tasks. On image classification, MaxViT achieves state-of-the-art performance under various settings: without extra data, MaxViT attains 86.5\% ImageNet-1K top-1 accuracy; with ImageNet-21K pre-training, our model achieves 88.7\% top-1 accuracy. For downstream tasks, MaxViT as a backbone delivers favorable performance on object detection as well as visual aesthetic assessment. We also show that our proposed model expresses strong generative modeling capability on ImageNet, demonstrating the superior potential of MaxViT blocks as a universal vision module. We will make the code and models publicly available.
MAXIM: Multi-Axis MLP for Image Processing
Jan 09, 2022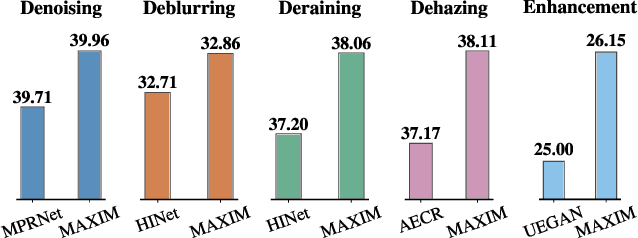
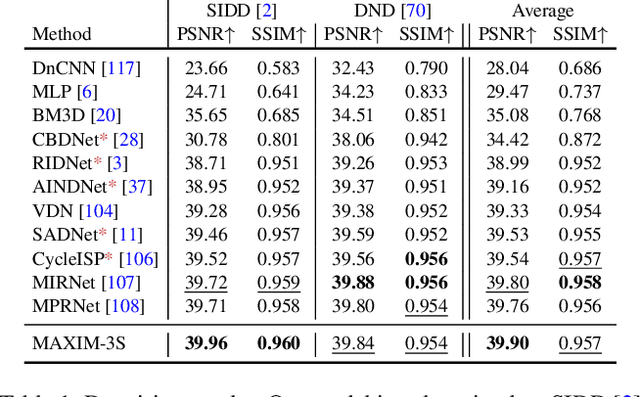
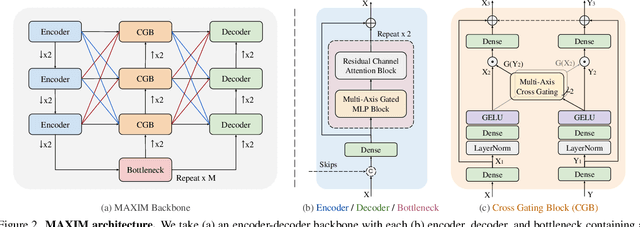
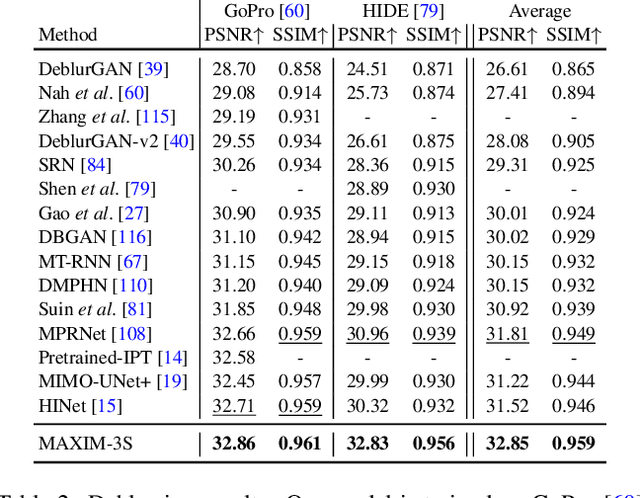
Recent progress on Transformers and multi-layer perceptron (MLP) models provide new network architectural designs for computer vision tasks. Although these models proved to be effective in many vision tasks such as image recognition, there remain challenges in adapting them for low-level vision. The inflexibility to support high-resolution images and limitations of local attention are perhaps the main bottlenecks for using Transformers and MLPs in image restoration. In this work we present a multi-axis MLP based architecture, called MAXIM, that can serve as an efficient and flexible general-purpose vision backbone for image processing tasks. MAXIM uses a UNet-shaped hierarchical structure and supports long-range interactions enabled by spatially-gated MLPs. Specifically, MAXIM contains two MLP-based building blocks: a multi-axis gated MLP that allows for efficient and scalable spatial mixing of local and global visual cues, and a cross-gating block, an alternative to cross-attention, which accounts for cross-feature mutual conditioning. Both these modules are exclusively based on MLPs, but also benefit from being both global and `fully-convolutional', two properties that are desirable for image processing. Our extensive experimental results show that the proposed MAXIM model achieves state-of-the-art performance on more than ten benchmarks across a range of image processing tasks, including denoising, deblurring, deraining, dehazing, and enhancement while requiring fewer or comparable numbers of parameters and FLOPs than competitive models.
Deblurring via Stochastic Refinement
Dec 28, 2021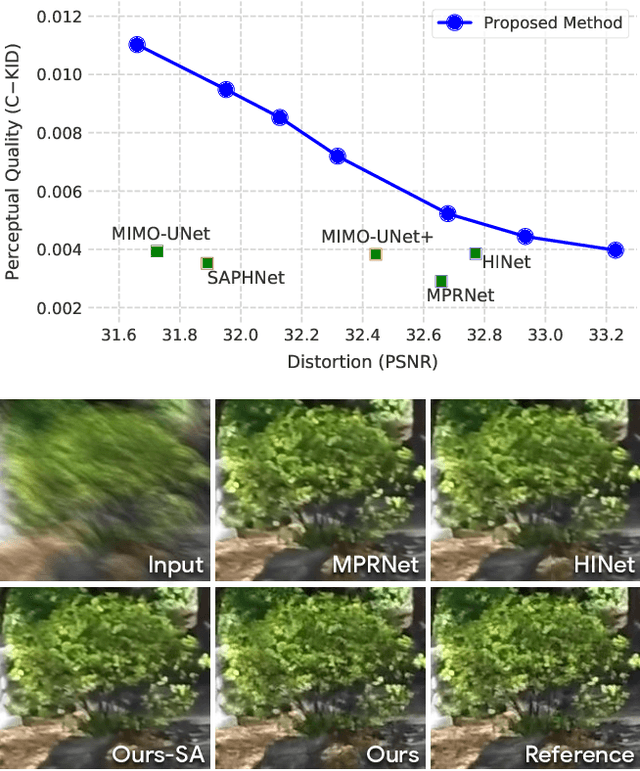
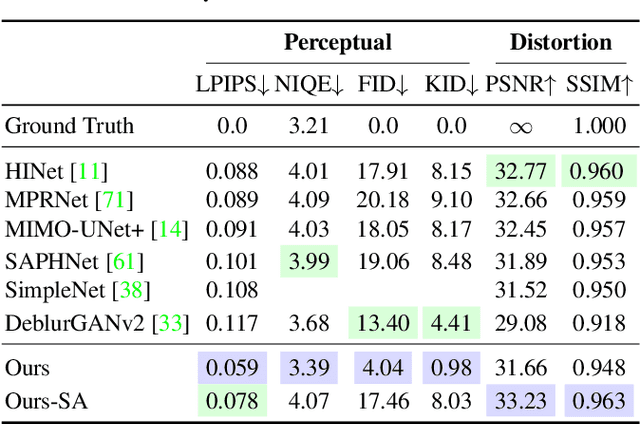
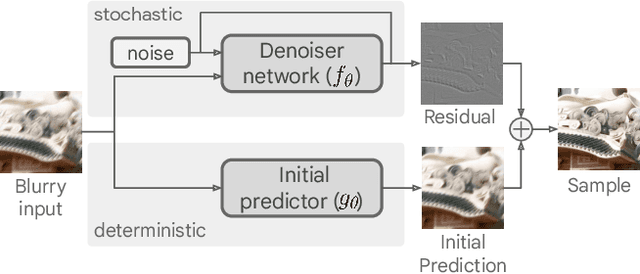

Image deblurring is an ill-posed problem with multiple plausible solutions for a given input image. However, most existing methods produce a deterministic estimate of the clean image and are trained to minimize pixel-level distortion. These metrics are known to be poorly correlated with human perception, and often lead to unrealistic reconstructions. We present an alternative framework for blind deblurring based on conditional diffusion models. Unlike existing techniques, we train a stochastic sampler that refines the output of a deterministic predictor and is capable of producing a diverse set of plausible reconstructions for a given input. This leads to a significant improvement in perceptual quality over existing state-of-the-art methods across multiple standard benchmarks. Our predict-and-refine approach also enables much more efficient sampling compared to typical diffusion models. Combined with a carefully tuned network architecture and inference procedure, our method is competitive in terms of distortion metrics such as PSNR. These results show clear benefits of our diffusion-based method for deblurring and challenge the widely used strategy of producing a single, deterministic reconstruction.
Solving Image PDEs with a Shallow Network
Oct 15, 2021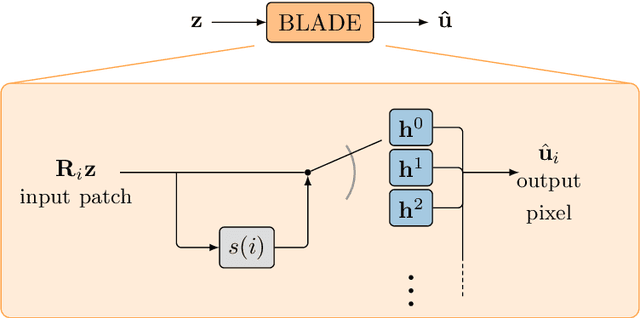
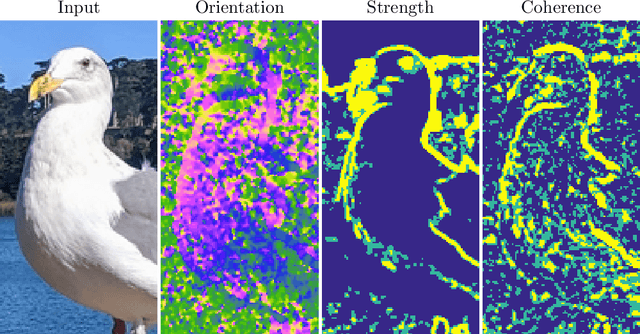
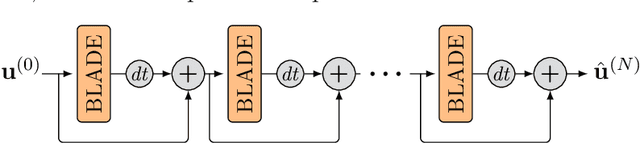
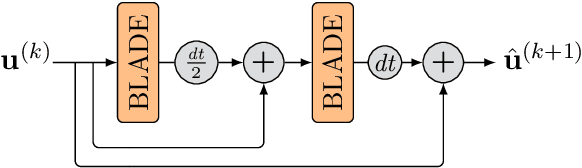
Partial differential equations (PDEs) are typically used as models of physical processes but are also of great interest in PDE-based image processing. However, when it comes to their use in imaging, conventional numerical methods for solving PDEs tend to require very fine grid resolution for stability, and as a result have impractically high computational cost. This work applies BLADE (Best Linear Adaptive Enhancement), a shallow learnable filtering framework, to PDE solving, and shows that the resulting approach is efficient and accurate, operating more reliably at coarse grid resolutions than classical methods. As such, the model can be flexibly used for a wide variety of problems in imaging.
MUSIQ: Multi-scale Image Quality Transformer
Aug 12, 2021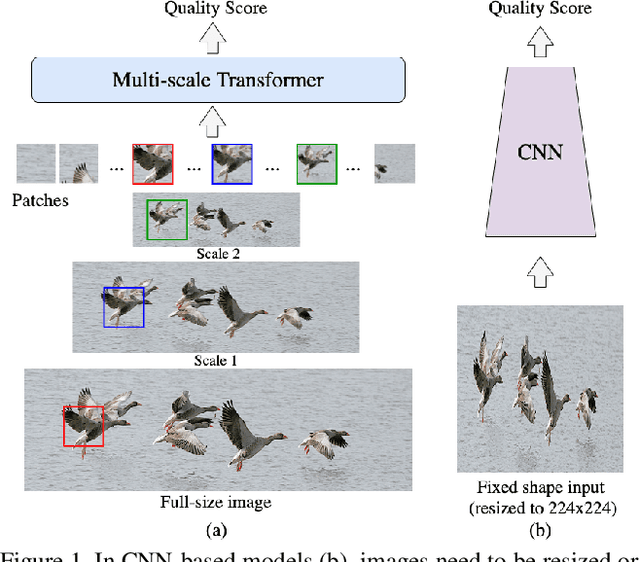
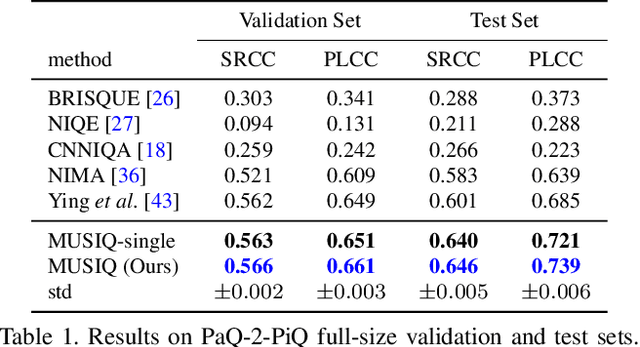
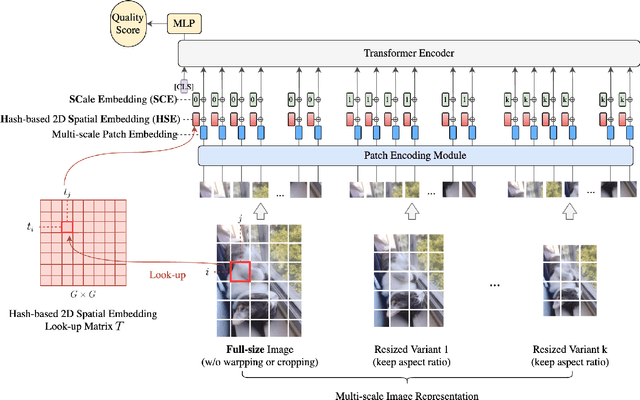
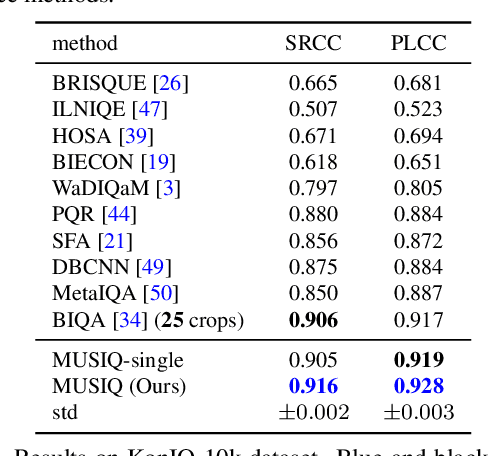
Image quality assessment (IQA) is an important research topic for understanding and improving visual experience. The current state-of-the-art IQA methods are based on convolutional neural networks (CNNs). The performance of CNN-based models is often compromised by the fixed shape constraint in batch training. To accommodate this, the input images are usually resized and cropped to a fixed shape, causing image quality degradation. To address this, we design a multi-scale image quality Transformer (MUSIQ) to process native resolution images with varying sizes and aspect ratios. With a multi-scale image representation, our proposed method can capture image quality at different granularities. Furthermore, a novel hash-based 2D spatial embedding and a scale embedding is proposed to support the positional embedding in the multi-scale representation. Experimental results verify that our method can achieve state-of-the-art performance on multiple large scale IQA datasets such as PaQ-2-PiQ, SPAQ and KonIQ-10k.
COMISR: Compression-Informed Video Super-Resolution
May 04, 2021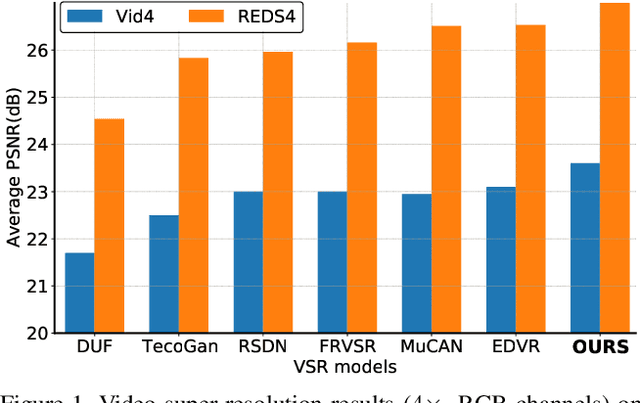
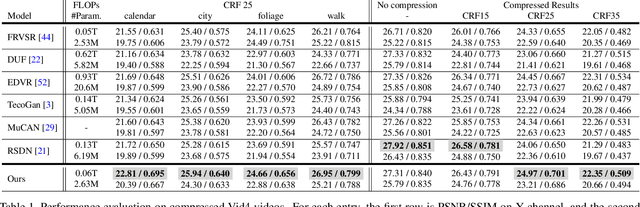
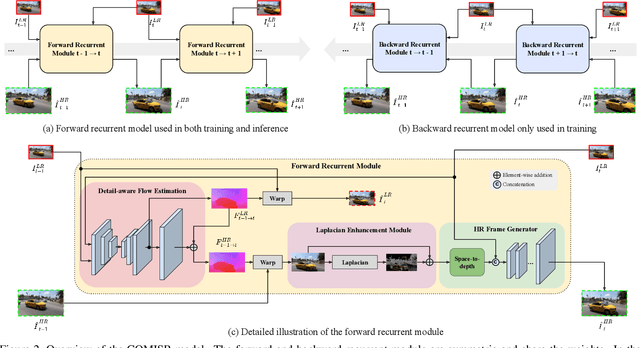
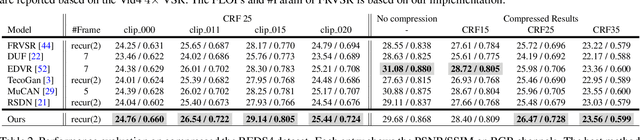
Most video super-resolution methods focus on restoring high-resolution video frames from low-resolution videos without taking into account compression. However, most videos on the web or mobile devices are compressed, and the compression can be severe when the bandwidth is limited. In this paper, we propose a new compression-informed video super-resolution model to restore high-resolution content without introducing artifacts caused by compression. The proposed model consists of three modules for video super-resolution: bi-directional recurrent warping, detail-preserving flow estimation, and Laplacian enhancement. All these three modules are used to deal with compression properties such as the location of the intra-frames in the input and smoothness in the output frames. For thorough performance evaluation, we conducted extensive experiments on standard datasets with a wide range of compression rates, covering many real video use cases. We showed that our method not only recovers high-resolution content on uncompressed frames from the widely-used benchmark datasets, but also achieves state-of-the-art performance in super-resolving compressed videos based on numerous quantitative metrics. We also evaluated the proposed method by simulating streaming from YouTube to demonstrate its effectiveness and robustness.
Deep 3D-to-2D Watermarking: Embedding Messages in 3D Meshes and Extracting Them from 2D Renderings
Apr 29, 2021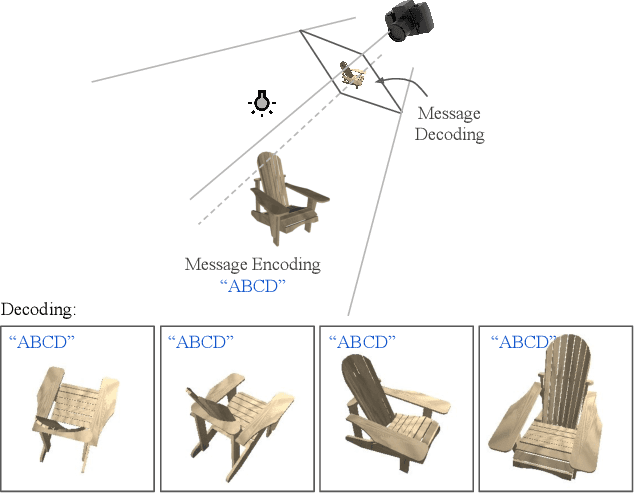
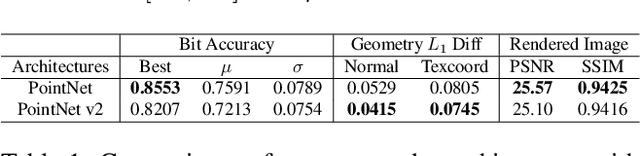
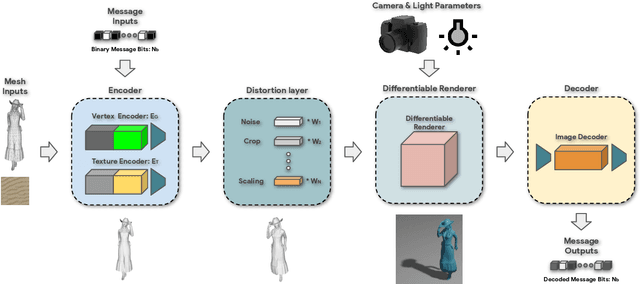

Digital watermarking is widely used for copyright protection. Traditional 3D watermarking approaches or commercial software are typically designed to embed messages into 3D meshes, and later retrieve the messages directly from distorted/undistorted watermarked 3D meshes. Retrieving messages from 2D renderings of such meshes, however, is still challenging and underexplored. We introduce a novel end-to-end learning framework to solve this problem through: 1) an encoder to covertly embed messages in both mesh geometry and textures; 2) a differentiable renderer to render watermarked 3D objects from different camera angles and under varied lighting conditions; 3) a decoder to recover the messages from 2D rendered images. From extensive experiments, we show that our models learn to embed information visually imperceptible to humans, and to reconstruct the embedded information from 2D renderings robust to 3D distortions. In addition, we demonstrate that our method can be generalized to work with different renderers, such as ray tracers and real-time renderers.
Removing Pixel Noises and Spatial Artifacts with Generative Diversity Denoising Methods
Apr 03, 2021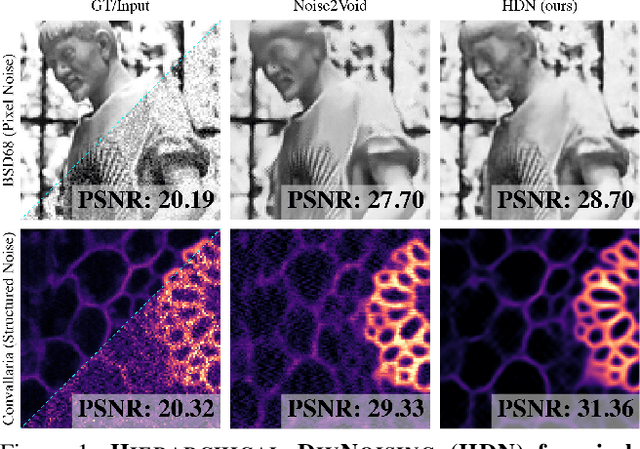
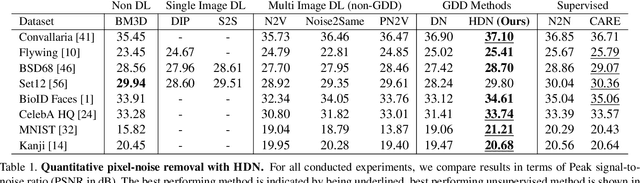
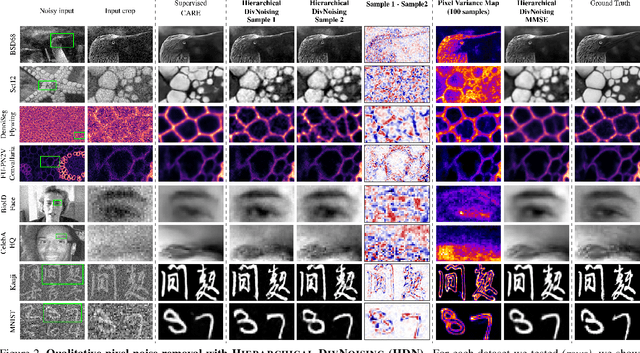

Image denoising and artefact removal are complex inverse problems admitting many potential solutions. Variational Autoencoders (VAEs) can be used to learn a whole distribution of sensible solutions, from which one can sample efficiently. However, such a generative approach to image restoration is only studied in the context of pixel-wise noise removal (e.g. Poisson or Gaussian noise). While important, a plethora of application domains suffer from imaging artefacts (structured noises) that alter groups of pixels in correlated ways. In this work we show, for the first time, that generative diversity denoising (GDD) approaches can learn to remove structured noises without supervision. To this end, we investigate two existing GDD architectures, introduce a new one based on hierarchical VAEs, and compare their performances against a total of seven state-of-the-art baseline methods on five sources of structured noise (including tomography reconstruction artefacts and microscopy artefacts). We find that GDD methods outperform all unsupervised baselines and in many cases not lagging far behind supervised results (in some occasions even superseding them). In addition to structured noise removal, we also show that our new GDD method produces new state-of-the-art (SOTA) results on seven out of eight benchmark datasets for pixel-noise removal. Finally, we offer insights into the daunting question of how GDD methods distinguish structured noise, which we like to see removed, from image signals, which we want to see retained.
Patch Craft: Video Denoising by Deep Modeling and Patch Matching
Mar 25, 2021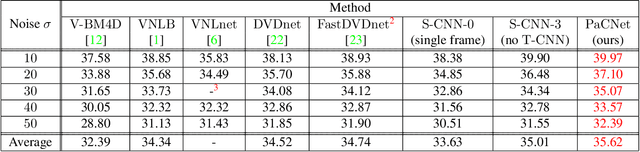
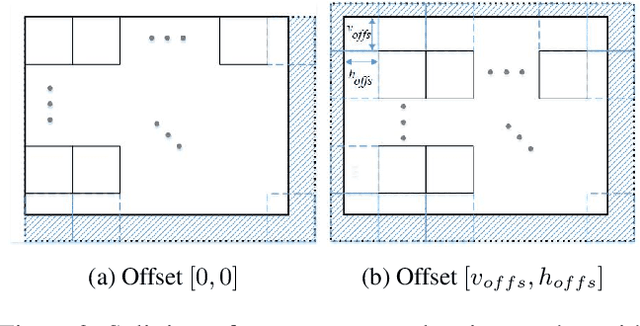
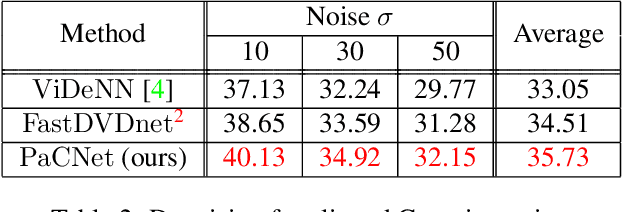

The non-local self-similarity property of natural images has been exploited extensively for solving various image processing problems. When it comes to video sequences, harnessing this force is even more beneficial due to the temporal redundancy. In the context of image and video denoising, many classically-oriented algorithms employ self-similarity, splitting the data into overlapping patches, gathering groups of similar ones and processing these together somehow. With the emergence of convolutional neural networks (CNN), the patch-based framework has been abandoned. Most CNN denoisers operate on the whole image, leveraging non-local relations only implicitly by using a large receptive field. This work proposes a novel approach for leveraging self-similarity in the context of video denoising, while still relying on a regular convolutional architecture. We introduce a concept of patch-craft frames - artificial frames that are similar to the real ones, built by tiling matched patches. Our algorithm augments video sequences with patch-craft frames and feeds them to a CNN. We demonstrate the substantial boost in denoising performance obtained with the proposed approach.