 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaplacian Multi-scale Flow Matching for Generative Modeling
Feb 23, 2026In this paper, we present Laplacian multiscale flow matching (LapFlow), a novel framework that enhances flow matching by leveraging multi-scale representations for image generative modeling. Our approach decomposes images into Laplacian pyramid residuals and processes different scales in parallel through a mixture-of-transformers (MoT) architecture with causal attention mechanisms. Unlike previous cascaded approaches that require explicit renoising between scales, our model generates multi-scale representations in parallel, eliminating the need for bridging processes. The proposed multi-scale architecture not only improves generation quality but also accelerates the sampling process and promotes scaling flow matching methods. Through extensive experimentation on CelebA-HQ and ImageNet, we demonstrate that our method achieves superior sample quality with fewer GFLOPs and faster inference compared to single-scale and multi-scale flow matching baselines. The proposed model scales effectively to high-resolution generation (up to 1024$\times$1024) while maintaining lower computational overhead.
Rethinking the Design Space of Reinforcement Learning for Diffusion Models: On the Importance of Likelihood Estimation Beyond Loss Design
Feb 04, 2026Reinforcement learning has been widely applied to diffusion and flow models for visual tasks such as text-to-image generation. However, these tasks remain challenging because diffusion models have intractable likelihoods, which creates a barrier for directly applying popular policy-gradient type methods. Existing approaches primarily focus on crafting new objectives built on already heavily engineered LLM objectives, using ad hoc estimators for likelihood, without a thorough investigation into how such estimation affects overall algorithmic performance. In this work, we provide a systematic analysis of the RL design space by disentangling three factors: i) policy-gradient objectives, ii) likelihood estimators, and iii) rollout sampling schemes. We show that adopting an evidence lower bound (ELBO) based model likelihood estimator, computed only from the final generated sample, is the dominant factor enabling effective, efficient, and stable RL optimization, outweighing the impact of the specific policy-gradient loss functional. We validate our findings across multiple reward benchmarks using SD 3.5 Medium, and observe consistent trends across all tasks. Our method improves the GenEval score from 0.24 to 0.95 in 90 GPU hours, which is $4.6\times$ more efficient than FlowGRPO and $2\times$ more efficient than the SOTA method DiffusionNFT without reward hacking.
Clarify Before You Draw: Proactive Agents for Robust Text-to-CAD Generation
Feb 03, 2026Large language models have recently enabled text-to-CAD systems that synthesize parametric CAD programs (e.g., CadQuery) from natural language prompts. In practice, however, geometric descriptions can be under-specified or internally inconsistent: critical dimensions may be missing and constraints may conflict. Existing fine-tuned models tend to reactively follow user instructions and hallucinate dimensions when the text is ambiguous. To address this, we propose a proactive agentic framework for text-to-CadQuery generation, named ProCAD, that resolves specification issues before code synthesis. Our framework pairs a proactive clarifying agent, which audits the prompt and asks targeted clarification questions only when necessary to produce a self-consistent specification, with a CAD coding agent that translates the specification into an executable CadQuery program. We fine-tune the coding agent on a curated high-quality text-to-CadQuery dataset and train the clarifying agent via agentic SFT on clarification trajectories. Experiments show that proactive clarification significantly improves robustness to ambiguous prompts while keeping interaction overhead low. ProCAD outperforms frontier closed-source models, including Claude Sonnet 4.5, reducing the mean Chamfer distance by 79.9 percent and lowering the invalidity ratio from 4.8 percent to 0.9 percent. Our code and datasets will be made publicly available.
Efficient Mixed Dimension Embeddings for Matrix Factorization
May 18, 2022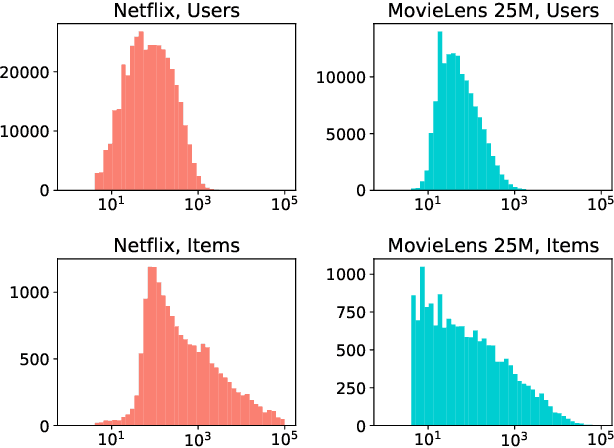
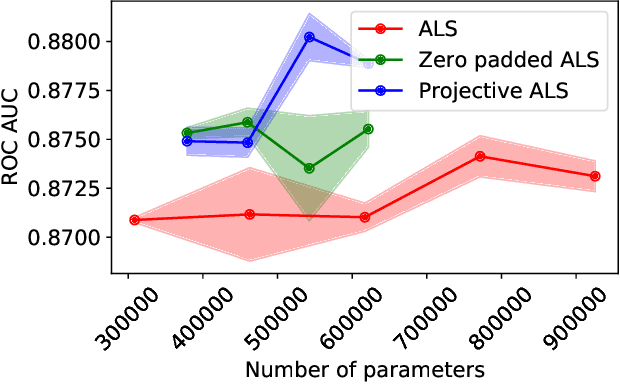
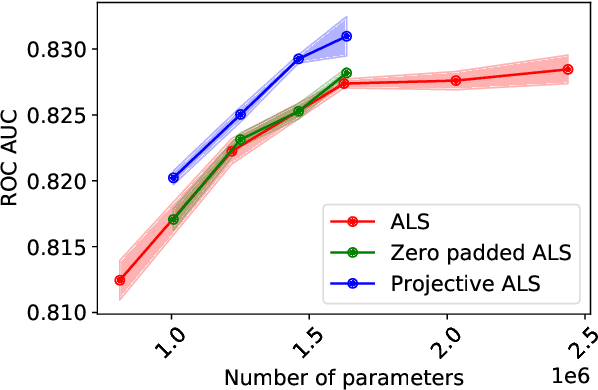
Despite the prominence of neural network approaches in the field of recommender systems, simple methods such as matrix factorization with quadratic loss are still used in industry for several reasons. These models can be trained with alternating least squares, which makes them easy to implement in a massively parallel manner, thus making it possible to utilize billions of events from real-world datasets. Large-scale recommender systems need to account for severe popularity skew in the distributions of users and items, so a lot of research is focused on implementing sparse, mixed dimension or shared embeddings to reduce both the number of parameters and overfitting on rare users and items. In this paper we propose two matrix factorization models with mixed dimension embeddings, which can be optimized in a massively parallel fashion using the alternating least squares approach.