 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards causal generative scene models via competition of experts
Apr 27, 2020

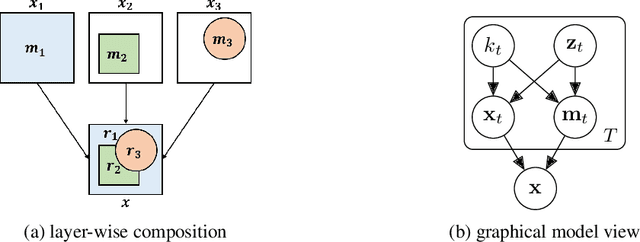
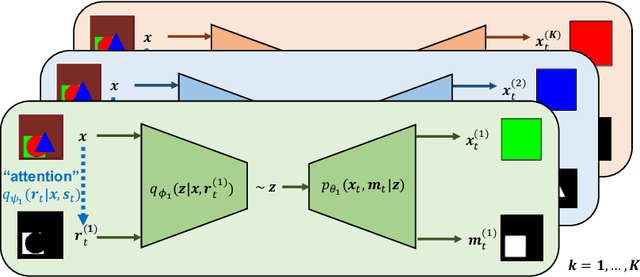
Learning how to model complex scenes in a modular way with recombinable components is a pre-requisite for higher-order reasoning and acting in the physical world. However, current generative models lack the ability to capture the inherently compositional and layered nature of visual scenes. While recent work has made progress towards unsupervised learning of object-based scene representations, most models still maintain a global representation space (i.e., objects are not explicitly separated), and cannot generate scenes with novel object arrangement and depth ordering. Here, we present an alternative approach which uses an inductive bias encouraging modularity by training an ensemble of generative models (experts). During training, experts compete for explaining parts of a scene, and thus specialise on different object classes, with objects being identified as parts that re-occur across multiple scenes. Our model allows for controllable sampling of individual objects and recombination of experts in physically plausible ways. In contrast to other methods, depth layering and occlusion are handled correctly, moving this approach closer to a causal generative scene model. Experiments on simple toy data qualitatively demonstrate the conceptual advantages of the proposed approach.
Rehabilitating the ColorChecker Dataset for Illuminant Estimation
Sep 17, 2018
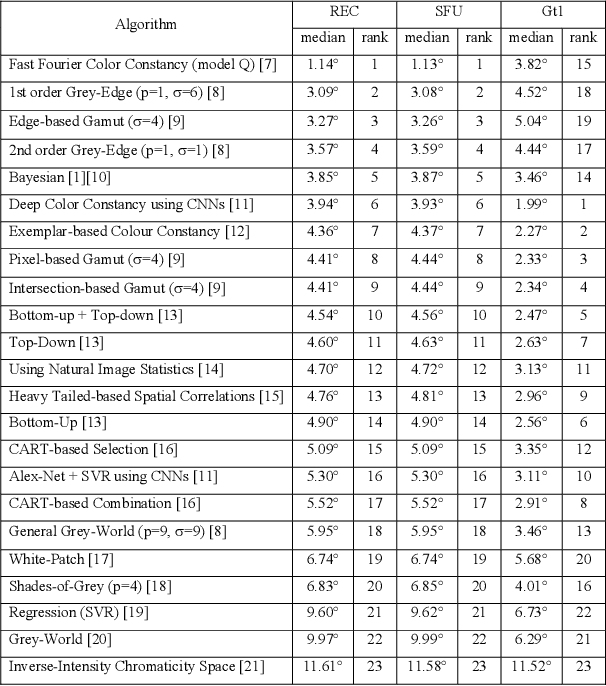
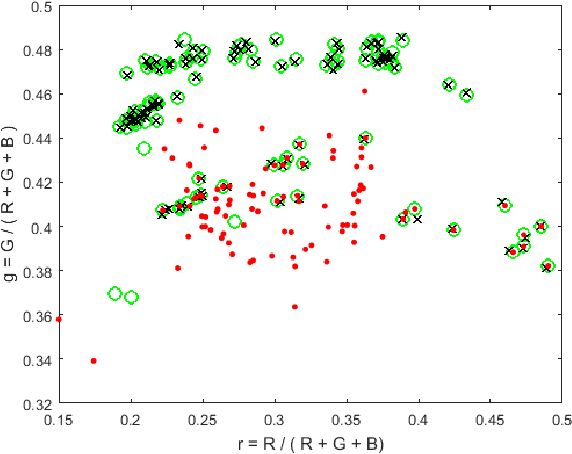
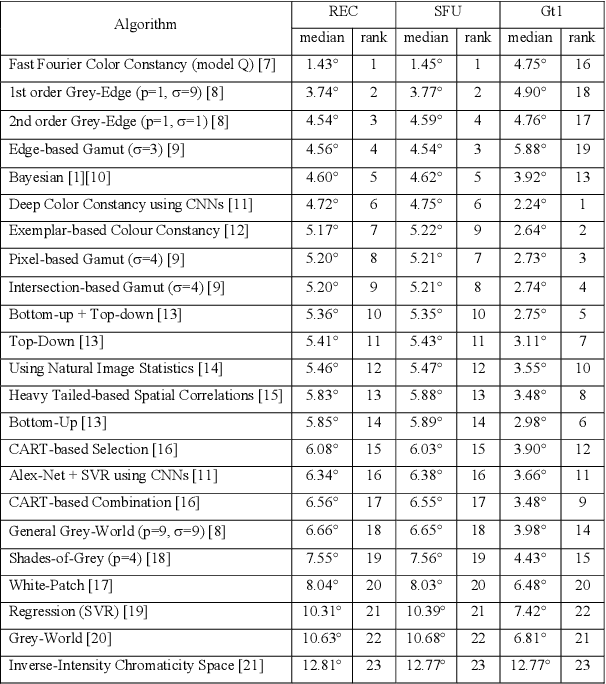
In a previous work, it was shown that there is a curious problem with the benchmark ColorChecker dataset for illuminant estimation. To wit, this dataset has at least 3 different sets of ground-truths. Typically, for a single algorithm a single ground-truth is used. But then different algorithms, whose performance is measured with respect to different ground-truths, are compared against each other and then ranked. This makes no sense. We show in this paper that there are also errors in how each ground-truth set was calculated. As a result, all performance rankings based on the ColorChecker dataset - and there are scores of these - are inaccurate. In this paper, we re-generate a new 'recommended' set of ground-truth based on the calculation methodology described by Shi and Funt. We then review the performance evaluation of a range of illuminant estimation algorithms. Compared with the legacy ground-truths, we find that the difference in how algorithms perform can be large, with many local rankings of algorithms being reversed. Finally, we draw the readers attention to our new 'open' data repository which, we hope, will allow the ColorChecker set to be rehabilitated and once again to become a useful benchmark for illuminant estimation algorithms.
Deep Directional Statistics: Pose Estimation with Uncertainty Quantification
May 09, 2018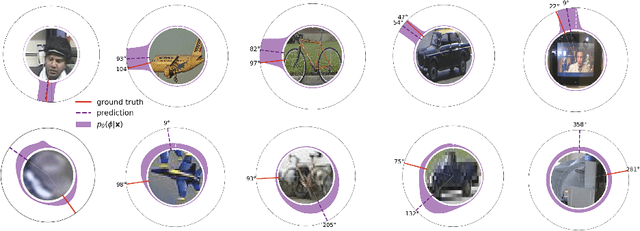

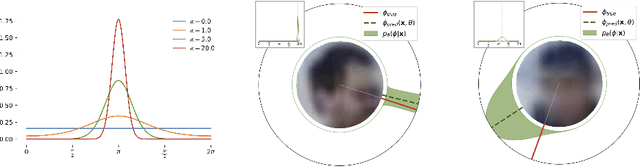
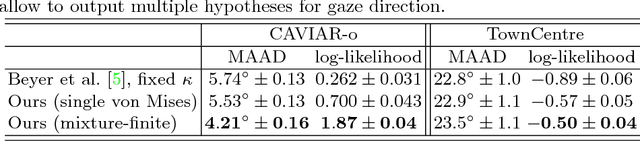
Modern deep learning systems successfully solve many perception tasks such as object pose estimation when the input image is of high quality. However, in challenging imaging conditions such as on low-resolution images or when the image is corrupted by imaging artifacts, current systems degrade considerably in accuracy. While a loss in performance is unavoidable, we would like our models to quantify their uncertainty in order to achieve robustness against images of varying quality. Probabilistic deep learning models combine the expressive power of deep learning with uncertainty quantification. In this paper, we propose a novel probabilistic deep learning model for the task of angular regression. Our model uses von Mises distributions to predict a distribution over object pose angle. Whereas a single von Mises distribution is making strong assumptions about the shape of the distribution, we extend the basic model to predict a mixture of von Mises distributions. We show how to learn a mixture model using a finite and infinite number of mixture components. Our model allows for likelihood-based training and efficient inference at test time. We demonstrate on a number of challenging pose estimation datasets that our model produces calibrated probability predictions and competitive or superior point estimates compared to the current state-of-the-art.
Keep it SMPL: Automatic Estimation of 3D Human Pose and Shape from a Single Image
Jul 27, 2016
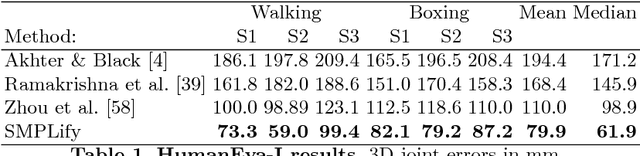

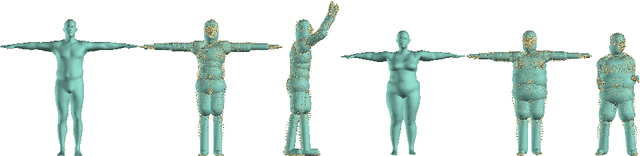
We describe the first method to automatically estimate the 3D pose of the human body as well as its 3D shape from a single unconstrained image. We estimate a full 3D mesh and show that 2D joints alone carry a surprising amount of information about body shape. The problem is challenging because of the complexity of the human body, articulation, occlusion, clothing, lighting, and the inherent ambiguity in inferring 3D from 2D. To solve this, we first use a recently published CNN-based method, DeepCut, to predict (bottom-up) the 2D body joint locations. We then fit (top-down) a recently published statistical body shape model, called SMPL, to the 2D joints. We do so by minimizing an objective function that penalizes the error between the projected 3D model joints and detected 2D joints. Because SMPL captures correlations in human shape across the population, we are able to robustly fit it to very little data. We further leverage the 3D model to prevent solutions that cause interpenetration. We evaluate our method, SMPLify, on the Leeds Sports, HumanEva, and Human3.6M datasets, showing superior pose accuracy with respect to the state of the art.
DeepCut: Joint Subset Partition and Labeling for Multi Person Pose Estimation
Apr 26, 2016
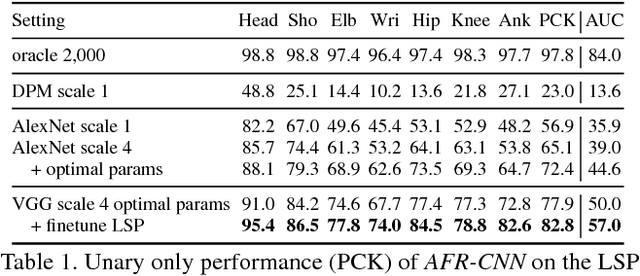
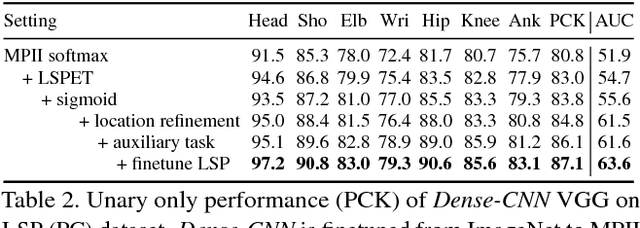
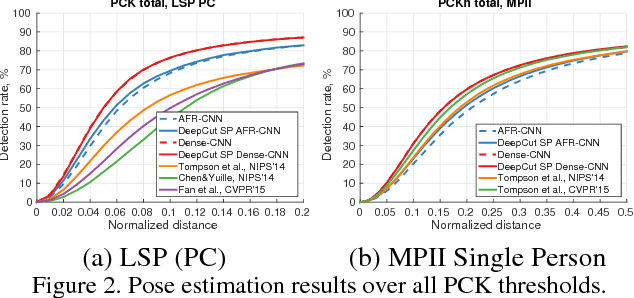
This paper considers the task of articulated human pose estimation of multiple people in real world images. We propose an approach that jointly solves the tasks of detection and pose estimation: it infers the number of persons in a scene, identifies occluded body parts, and disambiguates body parts between people in close proximity of each other. This joint formulation is in contrast to previous strategies, that address the problem by first detecting people and subsequently estimating their body pose. We propose a partitioning and labeling formulation of a set of body-part hypotheses generated with CNN-based part detectors. Our formulation, an instance of an integer linear program, implicitly performs non-maximum suppression on the set of part candidates and groups them to form configurations of body parts respecting geometric and appearance constraints. Experiments on four different datasets demonstrate state-of-the-art results for both single person and multi person pose estimation. Models and code available at http://pose.mpi-inf.mpg.de.
3D Object Class Detection in the Wild
Mar 17, 2015
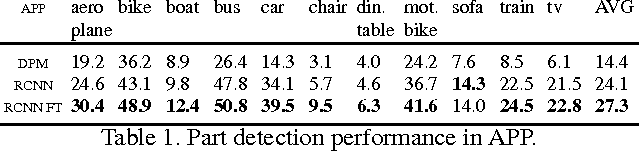


Object class detection has been a synonym for 2D bounding box localization for the longest time, fueled by the success of powerful statistical learning techniques, combined with robust image representations. Only recently, there has been a growing interest in revisiting the promise of computer vision from the early days: to precisely delineate the contents of a visual scene, object by object, in 3D. In this paper, we draw from recent advances in object detection and 2D-3D object lifting in order to design an object class detector that is particularly tailored towards 3D object class detection. Our 3D object class detection method consists of several stages gradually enriching the object detection output with object viewpoint, keypoints and 3D shape estimates. Following careful design, in each stage it constantly improves the performance and achieves state-ofthe-art performance in simultaneous 2D bounding box and viewpoint estimation on the challenging Pascal3D+ dataset.
Multi-View Priors for Learning Detectors from Sparse Viewpoint Data
Feb 16, 2014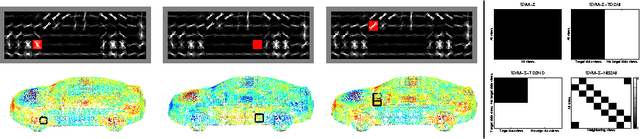
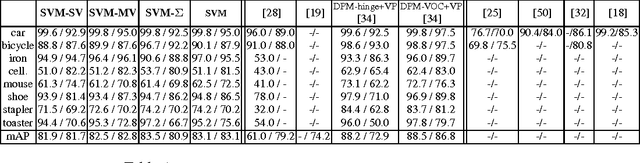
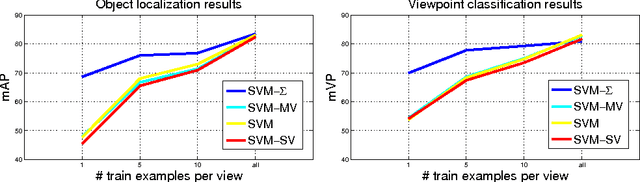
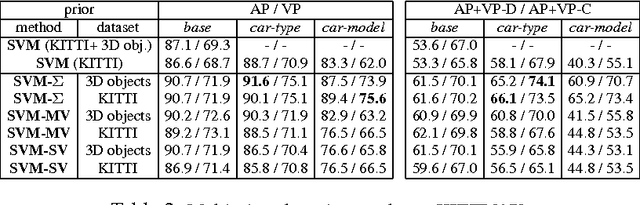
While the majority of today's object class models provide only 2D bounding boxes, far richer output hypotheses are desirable including viewpoint, fine-grained category, and 3D geometry estimate. However, models trained to provide richer output require larger amounts of training data, preferably well covering the relevant aspects such as viewpoint and fine-grained categories. In this paper, we address this issue from the perspective of transfer learning, and design an object class model that explicitly leverages correlations between visual features. Specifically, our model represents prior distributions over permissible multi-view detectors in a parametric way -- the priors are learned once from training data of a source object class, and can later be used to facilitate the learning of a detector for a target class. As we show in our experiments, this transfer is not only beneficial for detectors based on basic-level category representations, but also enables the robust learning of detectors that represent classes at finer levels of granularity, where training data is typically even scarcer and more unbalanced. As a result, we report largely improved performance in simultaneous 2D object localization and viewpoint estimation on a recent dataset of challenging street scenes.