 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Accurate Low-Rank Factorization of Compressively-Sensed Data
May 30, 2018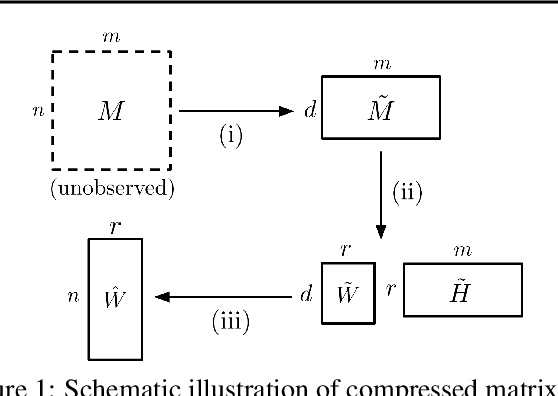
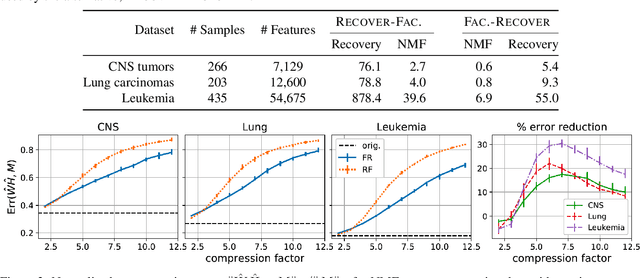
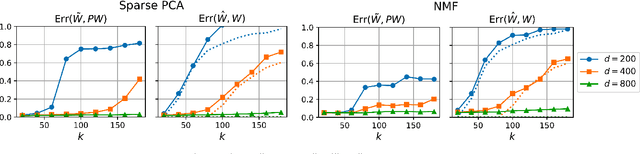
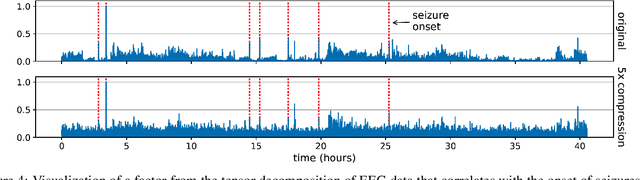
We consider the question of accurately and efficiently computing low-rank matrix or tensor factorizations given data compressed via random projections. This problem arises naturally in the many settings in which data is acquired via compressive sensing. We examine the approach of first performing factorization in the compressed domain, and then reconstructing the original high-dimensional factors from the recovered (compressed) factors. In both the tensor and matrix settings, we establish conditions under which this natural approach will provably recover the original factors. We support these theoretical results with experiments on synthetic data and demonstrate the practical applicability of our methods on real-world gene expression and EEG time series data.
Sketching Linear Classifiers over Data Streams
Apr 06, 2018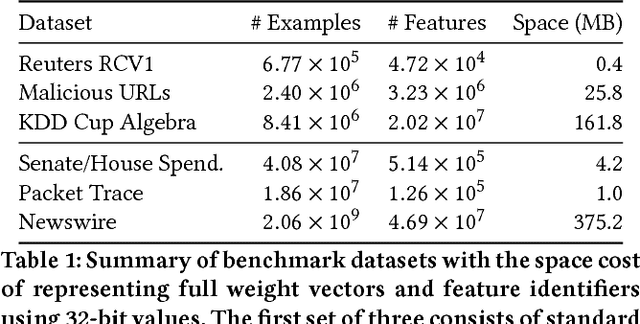
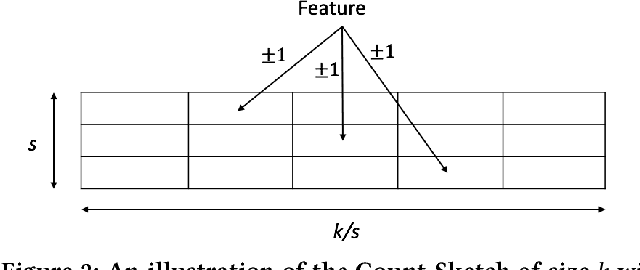
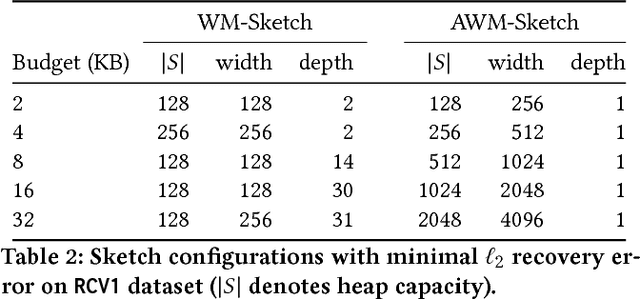
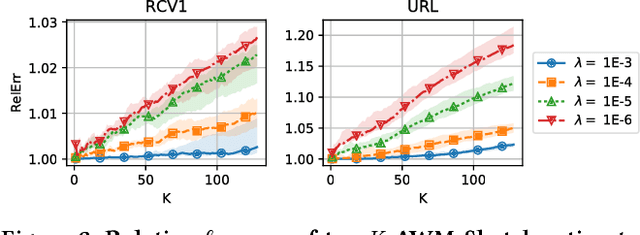
We introduce a new sub-linear space sketch---the Weight-Median Sketch---for learning compressed linear classifiers over data streams while supporting the efficient recovery of large-magnitude weights in the model. This enables memory-limited execution of several statistical analyses over streams, including online feature selection, streaming data explanation, relative deltoid detection, and streaming estimation of pointwise mutual information. Unlike related sketches that capture the most frequently-occurring features (or items) in a data stream, the Weight-Median Sketch captures the features that are most discriminative of one stream (or class) compared to another. The Weight-Median Sketch adopts the core data structure used in the Count-Sketch, but, instead of sketching counts, it captures sketched gradient updates to the model parameters. We provide a theoretical analysis that establishes recovery guarantees for batch and online learning, and demonstrate empirical improvements in memory-accuracy trade-offs over alternative memory-budgeted methods, including count-based sketches and feature hashing.
NoScope: Optimizing Neural Network Queries over Video at Scale
Aug 08, 2017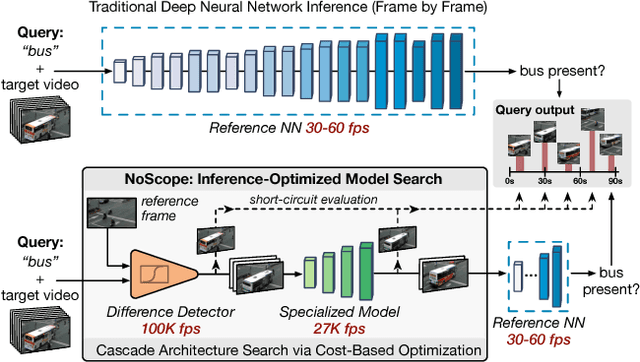


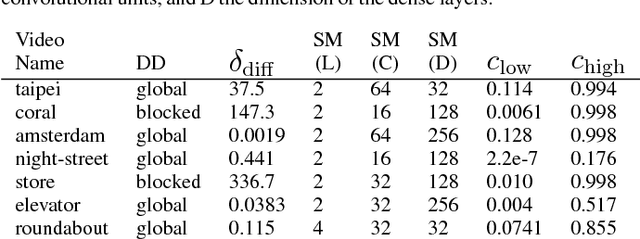
Recent advances in computer vision-in the form of deep neural networks-have made it possible to query increasing volumes of video data with high accuracy. However, neural network inference is computationally expensive at scale: applying a state-of-the-art object detector in real time (i.e., 30+ frames per second) to a single video requires a $4000 GPU. In response, we present NoScope, a system for querying videos that can reduce the cost of neural network video analysis by up to three orders of magnitude via inference-optimized model search. Given a target video, object to detect, and reference neural network, NoScope automatically searches for and trains a sequence, or cascade, of models that preserves the accuracy of the reference network but is specialized to the target video and are therefore far less computationally expensive. NoScope cascades two types of models: specialized models that forego the full generality of the reference model but faithfully mimic its behavior for the target video and object; and difference detectors that highlight temporal differences across frames. We show that the optimal cascade architecture differs across videos and objects, so NoScope uses an efficient cost-based optimizer to search across models and cascades. With this approach, NoScope achieves two to three order of magnitude speed-ups (265-15,500x real-time) on binary classification tasks over fixed-angle webcam and surveillance video while maintaining accuracy within 1-5% of state-of-the-art neural networks.
Infrastructure for Usable Machine Learning: The Stanford DAWN Project
Jun 09, 2017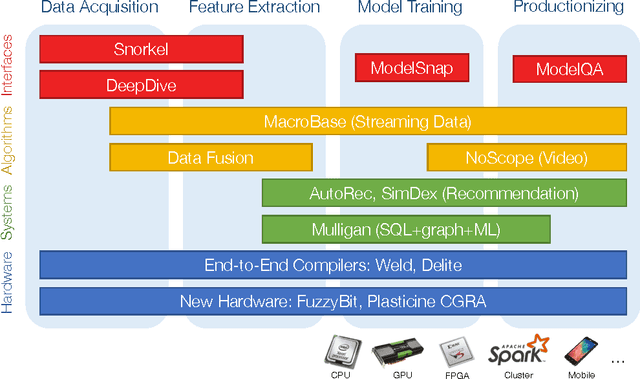
Despite incredible recent advances in machine learning, building machine learning applications remains prohibitively time-consuming and expensive for all but the best-trained, best-funded engineering organizations. This expense comes not from a need for new and improved statistical models but instead from a lack of systems and tools for supporting end-to-end machine learning application development, from data preparation and labeling to productionization and monitoring. In this document, we outline opportunities for infrastructure supporting usable, end-to-end machine learning applications in the context of the nascent DAWN (Data Analytics for What's Next) project at Stanford.