 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS$^2$R: Teaching LLMs to Self-verify and Self-correct via Reinforcement Learning
Feb 18, 2025



Recent studies have demonstrated the effectiveness of LLM test-time scaling. However, existing approaches to incentivize LLMs' deep thinking abilities generally require large-scale data or significant training efforts. Meanwhile, it remains unclear how to improve the thinking abilities of less powerful base models. In this work, we introduce S$^2$R, an efficient framework that enhances LLM reasoning by teaching models to self-verify and self-correct during inference. Specifically, we first initialize LLMs with iterative self-verification and self-correction behaviors through supervised fine-tuning on carefully curated data. The self-verification and self-correction skills are then further strengthened by both outcome-level and process-level reinforcement learning, with minimized resource requirements, enabling the model to adaptively refine its reasoning process during inference. Our results demonstrate that, with only 3.1k self-verifying and self-correcting behavior initialization samples, Qwen2.5-math-7B achieves an accuracy improvement from 51.0\% to 81.6\%, outperforming models trained on an equivalent amount of long-CoT distilled data. Extensive experiments and analysis based on three base models across both in-domain and out-of-domain benchmarks validate the effectiveness of S$^2$R. Our code and data are available at https://github.com/NineAbyss/S2R.
FireFlow: Fast Inversion of Rectified Flow for Image Semantic Editing
Dec 10, 2024



Though Rectified Flows (ReFlows) with distillation offers a promising way for fast sampling, its fast inversion transforms images back to structured noise for recovery and following editing remains unsolved. This paper introduces FireFlow, a simple yet effective zero-shot approach that inherits the startling capacity of ReFlow-based models (such as FLUX) in generation while extending its capabilities to accurate inversion and editing in $8$ steps. We first demonstrate that a carefully designed numerical solver is pivotal for ReFlow inversion, enabling accurate inversion and reconstruction with the precision of a second-order solver while maintaining the practical efficiency of a first-order Euler method. This solver achieves a $3\times$ runtime speedup compared to state-of-the-art ReFlow inversion and editing techniques, while delivering smaller reconstruction errors and superior editing results in a training-free mode. The code is available at $\href{https://github.com/HolmesShuan/FireFlow}{this URL}$.
GLBench: A Comprehensive Benchmark for Graph with Large Language Models
Jul 11, 2024



The emergence of large language models (LLMs) has revolutionized the way we interact with graphs, leading to a new paradigm called GraphLLM. Despite the rapid development of GraphLLM methods in recent years, the progress and understanding of this field remain unclear due to the lack of a benchmark with consistent experimental protocols. To bridge this gap, we introduce GLBench, the first comprehensive benchmark for evaluating GraphLLM methods in both supervised and zero-shot scenarios. GLBench provides a fair and thorough evaluation of different categories of GraphLLM methods, along with traditional baselines such as graph neural networks. Through extensive experiments on a collection of real-world datasets with consistent data processing and splitting strategies, we have uncovered several key findings. Firstly, GraphLLM methods outperform traditional baselines in supervised settings, with LLM-as-enhancers showing the most robust performance. However, using LLMs as predictors is less effective and often leads to uncontrollable output issues. We also notice that no clear scaling laws exist for current GraphLLM methods. In addition, both structures and semantics are crucial for effective zero-shot transfer, and our proposed simple baseline can even outperform several models tailored for zero-shot scenarios. The data and code of the benchmark can be found at https://github.com/NineAbyss/GLBench.
TernaryLLM: Ternarized Large Language Model
Jun 11, 2024



Large language models (LLMs) have achieved remarkable performance on Natural Language Processing (NLP) tasks, but they are hindered by high computational costs and memory requirements. Ternarization, an extreme form of quantization, offers a solution by reducing memory usage and enabling energy-efficient floating-point additions. However, applying ternarization to LLMs faces challenges stemming from outliers in both weights and activations. In this work, observing asymmetric outliers and non-zero means in weights, we introduce Dual Learnable Ternarization (DLT), which enables both scales and shifts to be learnable. We also propose Outlier-Friendly Feature Knowledge Distillation (OFF) to recover the information lost in extremely low-bit quantization. The proposed OFF can incorporate semantic information and is insensitive to outliers. At the core of OFF is maximizing the mutual information between features in ternarized and floating-point models using cosine similarity. Extensive experiments demonstrate that our TernaryLLM surpasses previous low-bit quantization methods on the standard text generation and zero-shot benchmarks for different LLM families. Specifically, for one of the most powerful open-source models, LLaMA-3, our approach (W1.58A16) outperforms the previous state-of-the-art method (W2A16) by 5.8 in terms of perplexity on C4 and by 8.2% in terms of average accuracy on zero-shot tasks.
ZeroG: Investigating Cross-dataset Zero-shot Transferability in Graphs
Feb 17, 2024



With the development of foundation models such as large language models, zero-shot transfer learning has become increasingly significant. This is highlighted by the generative capabilities of NLP models like GPT-4, and the retrieval-based approaches of CV models like CLIP, both of which effectively bridge the gap between seen and unseen data. In the realm of graph learning, the continuous emergence of new graphs and the challenges of human labeling also amplify the necessity for zero-shot transfer learning, driving the exploration of approaches that can generalize across diverse graph data without necessitating dataset-specific and label-specific fine-tuning. In this study, we extend such paradigms to zero-shot transferability in graphs by introducing ZeroG, a new framework tailored to enable cross-dataset generalization. Addressing the inherent challenges such as feature misalignment, mismatched label spaces, and negative transfer, we leverage a language model to encode both node attributes and class semantics, ensuring consistent feature dimensions across datasets. We also propose a prompt-based subgraph sampling module that enriches the semantic information and structure information of extracted subgraphs using prompting nodes and neighborhood aggregation, respectively. We further adopt a lightweight fine-tuning strategy that reduces the risk of overfitting and maintains the zero-shot learning efficacy of the language model. The results underscore the effectiveness of our model in achieving significant cross-dataset zero-shot transferability, opening pathways for the development of graph foundation models. Especially, ZeroG, as a zero-shot method, can even achieve results comparable to those of semi-supervised learning on Pubmed.
A Survey of Graph Meets Large Language Model: Progress and Future Directions
Nov 28, 2023Graph plays a significant role in representing and analyzing complex relationships in real-world applications such as citation networks, social networks, and biological data. Recently, Large Language Models (LLMs), which have achieved tremendous success in various domains, have also been leveraged in graph-related tasks to surpass traditional Graph Neural Networks (GNNs) based methods and yield state-of-the-art performance. In this survey, we first present a comprehensive review and analysis of existing methods that integrate LLMs with graphs. First of all, we propose a new taxonomy, which organizes existing methods into three categories based on the role (i.e., enhancer, predictor, and alignment component) played by LLMs in graph-related tasks. Then we systematically survey the representative methods along the three categories of the taxonomy. Finally, we discuss the remaining limitations of existing studies and highlight promising avenues for future research. The relevant papers are summarized and will be consistently updated at: https://github.com/yhLeeee/Awesome-LLMs-in-Graph-tasks.
Reversed Image Signal Processing and RAW Reconstruction. AIM 2022 Challenge Report
Oct 20, 2022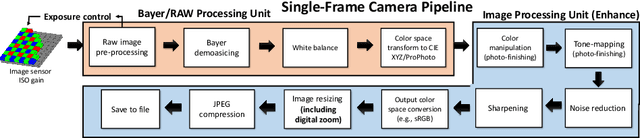
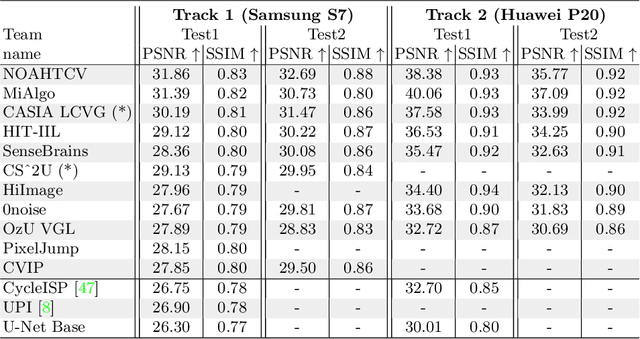
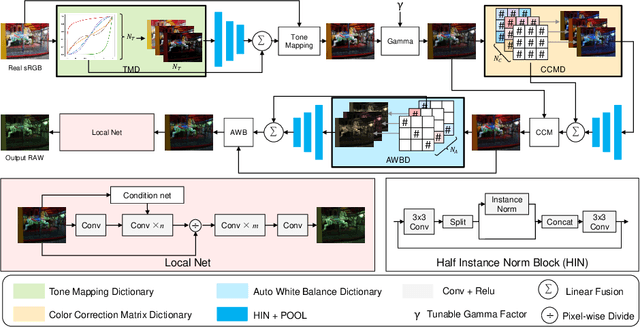
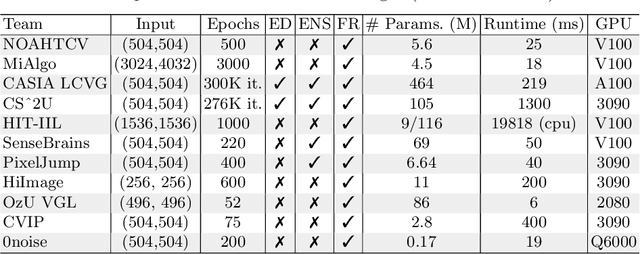
Cameras capture sensor RAW images and transform them into pleasant RGB images, suitable for the human eyes, using their integrated Image Signal Processor (ISP). Numerous low-level vision tasks operate in the RAW domain (e.g. image denoising, white balance) due to its linear relationship with the scene irradiance, wide-range of information at 12bits, and sensor designs. Despite this, RAW image datasets are scarce and more expensive to collect than the already large and public RGB datasets. This paper introduces the AIM 2022 Challenge on Reversed Image Signal Processing and RAW Reconstruction. We aim to recover raw sensor images from the corresponding RGBs without metadata and, by doing this, "reverse" the ISP transformation. The proposed methods and benchmark establish the state-of-the-art for this low-level vision inverse problem, and generating realistic raw sensor readings can potentially benefit other tasks such as denoising and super-resolution.
Soft Threshold Ternary Networks
Apr 04, 2022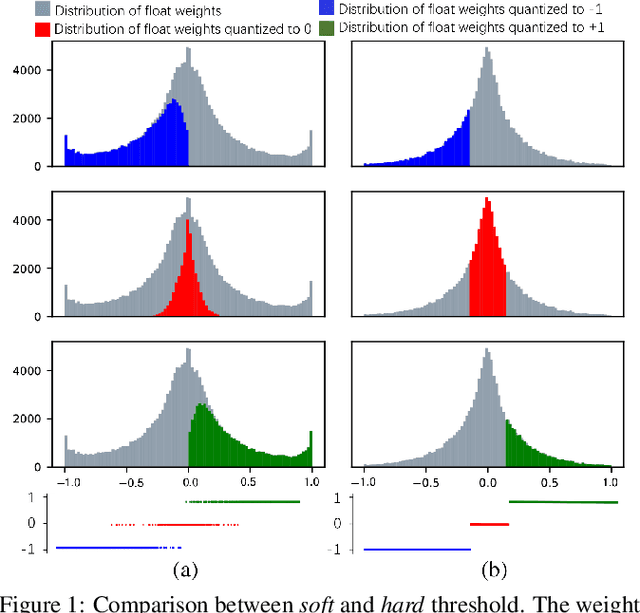

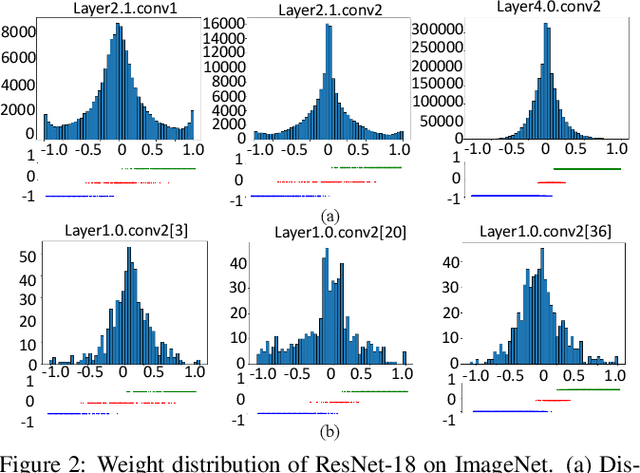

Large neural networks are difficult to deploy on mobile devices because of intensive computation and storage. To alleviate it, we study ternarization, a balance between efficiency and accuracy that quantizes both weights and activations into ternary values. In previous ternarized neural networks, a hard threshold {\Delta} is introduced to determine quantization intervals. Although the selection of {\Delta} greatly affects the training results, previous works estimate {\Delta} via an approximation or treat it as a hyper-parameter, which is suboptimal. In this paper, we present the Soft Threshold Ternary Networks (STTN), which enables the model to automatically determine quantization intervals instead of depending on a hard threshold. Concretely, we replace the original ternary kernel with the addition of two binary kernels at training time, where ternary values are determined by the combination of two corresponding binary values. At inference time, we add up the two binary kernels to obtain a single ternary kernel. Our method dramatically outperforms current state-of-the-arts, lowering the performance gap between full-precision networks and extreme low bit networks. Experiments on ImageNet with ResNet-18 (Top-1 66.2%) achieves new state-of-the-art. Update: In this version, we further fine-tune the experimental hyperparameters and training procedure. The latest STTN shows that ResNet-18 with ternary weights and ternary activations achieves up to 68.2% Top-1 accuracy on ImageNet. Code is available at: github.com/WeixiangXu/STTN.
Differentially Private Federated Learning with Local Regularization and Sparsification
Mar 21, 2022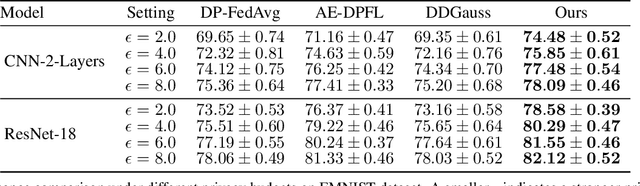
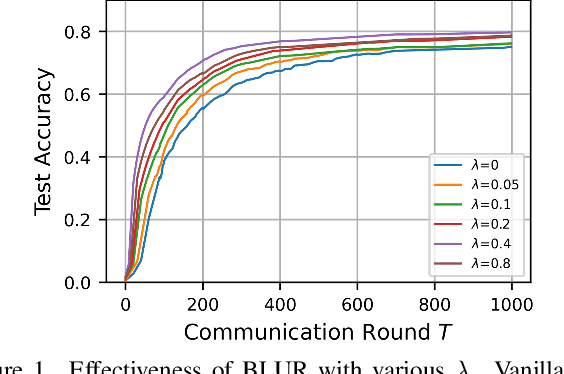
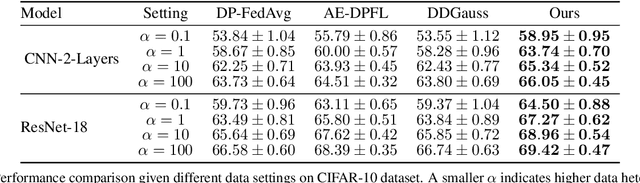
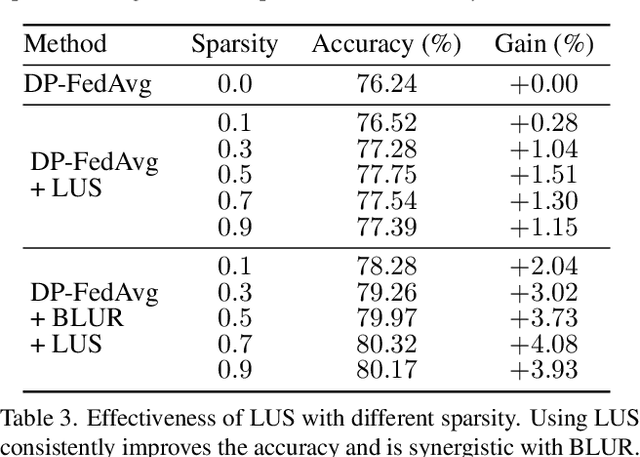
User-level differential privacy (DP) provides certifiable privacy guarantees to the information that is specific to any user's data in federated learning. Existing methods that ensure user-level DP come at the cost of severe accuracy decrease. In this paper, we study the cause of model performance degradation in federated learning under user-level DP guarantee. We find the key to solving this issue is to naturally restrict the norm of local updates before executing operations that guarantee DP. To this end, we propose two techniques, Bounded Local Update Regularization and Local Update Sparsification, to increase model quality without sacrificing privacy. We provide theoretical analysis on the convergence of our framework and give rigorous privacy guarantees. Extensive experiments show that our framework significantly improves the privacy-utility trade-off over the state-of-the-arts for federated learning with user-level DP guarantee.
Q-ViT: Fully Differentiable Quantization for Vision Transformer
Jan 19, 2022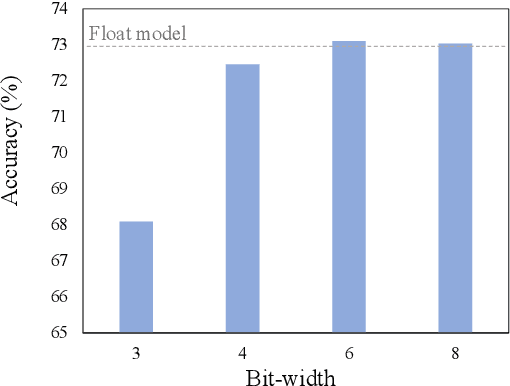
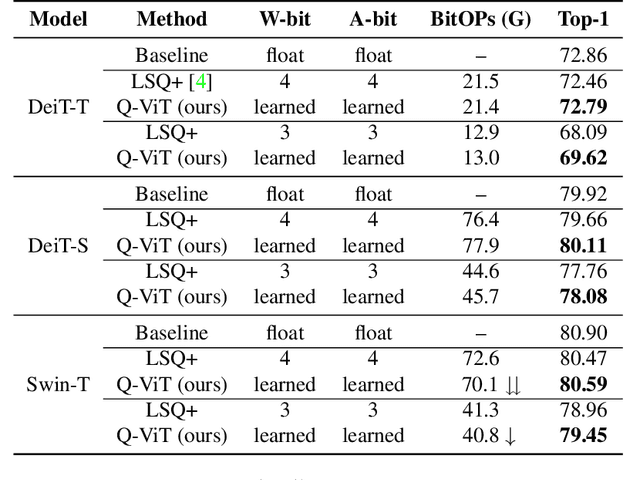
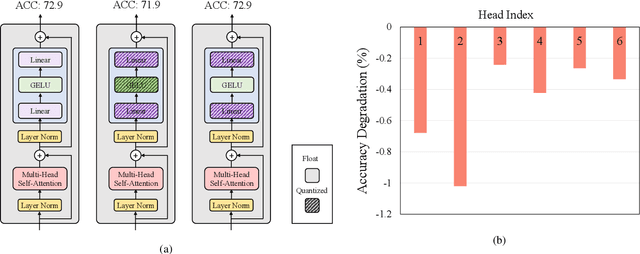

In this paper, we propose a fully differentiable quantization method for vision transformer (ViT) named as Q-ViT, in which both of the quantization scales and bit-widths are learnable parameters. Specifically, based on our observation that heads in ViT display different quantization robustness, we leverage head-wise bit-width to squeeze the size of Q-ViT while preserving performance. In addition, we propose a novel technique named switchable scale to resolve the convergence problem in the joint training of quantization scales and bit-widths. In this way, Q-ViT pushes the limits of ViT quantization to 3-bit without heavy performance drop. Moreover, we analyze the quantization robustness of every architecture component of ViT and show that the Multi-head Self-Attention (MSA) and the Gaussian Error Linear Units (GELU) are the key aspects for ViT quantization. This study provides some insights for further research about ViT quantization. Extensive experiments on different ViT models, such as DeiT and Swin Transformer show the effectiveness of our quantization method. In particular, our method outperforms the state-of-the-art uniform quantization method by 1.5% on DeiT-Tiny.