 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaRa: Latents and Rays for Multi-Camera Bird's-Eye-View Semantic Segmentation
Jun 27, 2022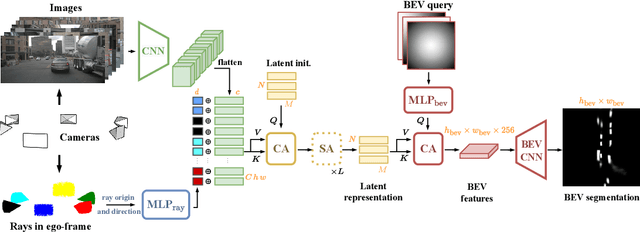
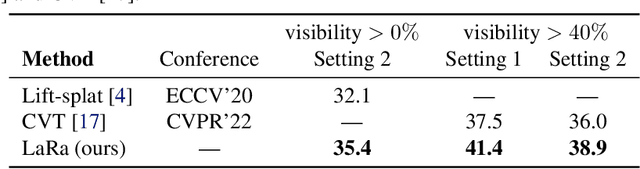

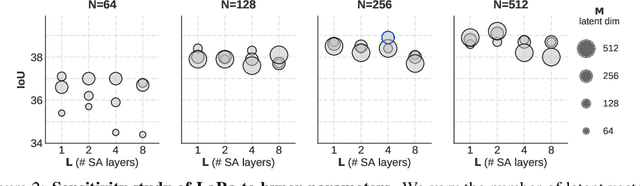
Recent works in autonomous driving have widely adopted the bird's-eye-view (BEV) semantic map as an intermediate representation of the world. Online prediction of these BEV maps involves non-trivial operations such as multi-camera data extraction as well as fusion and projection into a common top-view grid. This is usually done with error-prone geometric operations (e.g., homography or back-projection from monocular depth estimation) or expensive direct dense mapping between image pixels and pixels in BEV (e.g., with MLP or attention). In this work, we present 'LaRa', an efficient encoder-decoder, transformer-based model for vehicle semantic segmentation from multiple cameras. Our approach uses a system of cross-attention to aggregate information over multiple sensors into a compact, yet rich, collection of latent representations. These latent representations, after being processed by a series of self-attention blocks, are then reprojected with a second cross-attention in the BEV space. We demonstrate that our model outperforms on nuScenes the best previous works using transformers.
HULC: 3D Human Motion Capture with Pose Manifold Sampling and Dense Contact Guidance
May 24, 2022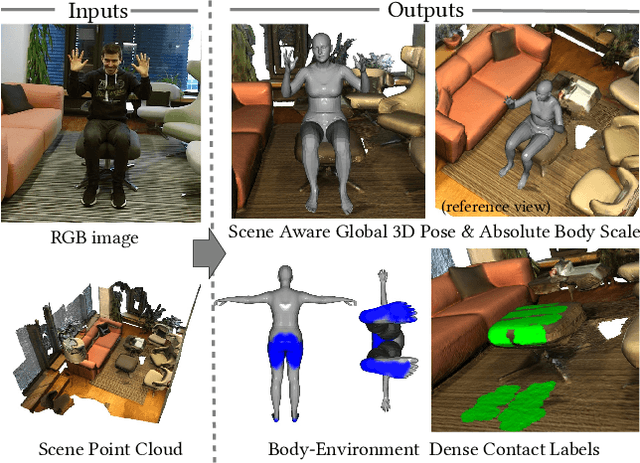
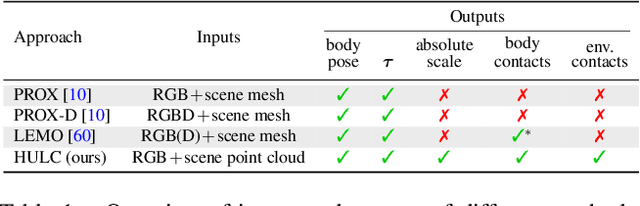
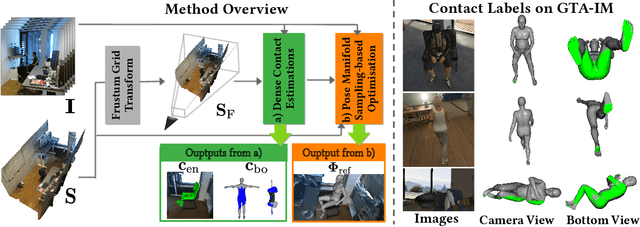
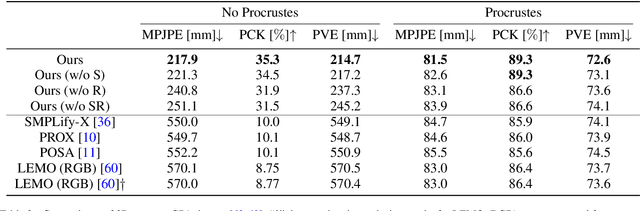
Marker-less monocular 3D human motion capture (MoCap) with scene interactions is a challenging research topic relevant for extended reality, robotics and virtual avatar generation. Due to the inherent depth ambiguity of monocular settings, 3D motions captured with existing methods often contain severe artefacts such as incorrect body-scene inter-penetrations, jitter and body floating. To tackle these issues, we propose HULC, a new approach for 3D human MoCap which is aware of the scene geometry. HULC estimates 3D poses and dense body-environment surface contacts for improved 3D localisations, as well as the absolute scale of the subject. Furthermore, we introduce a 3D pose trajectory optimisation based on a novel pose manifold sampling that resolves erroneous body-environment inter-penetrations. Although the proposed method requires less structured inputs compared to existing scene-aware monocular MoCap algorithms, it produces more physically-plausible poses: HULC significantly and consistently outperforms the existing approaches in various experiments and on different metrics.
Multi-Head Distillation for Continual Unsupervised Domain Adaptation in Semantic Segmentation
Apr 25, 2022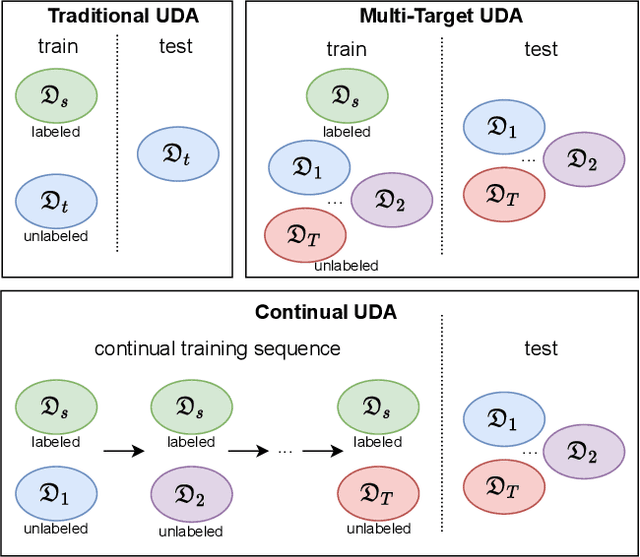
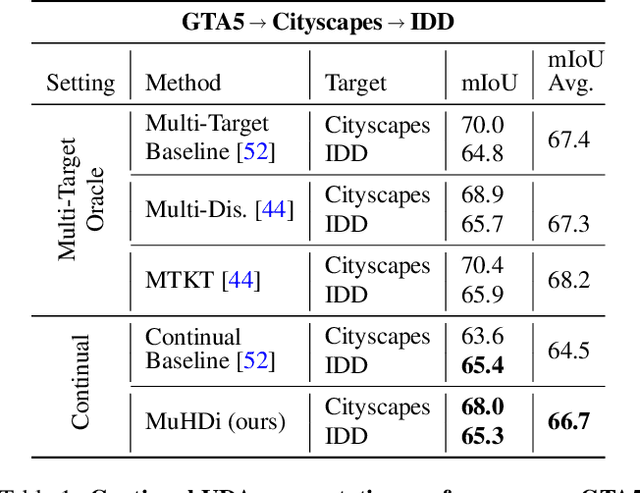
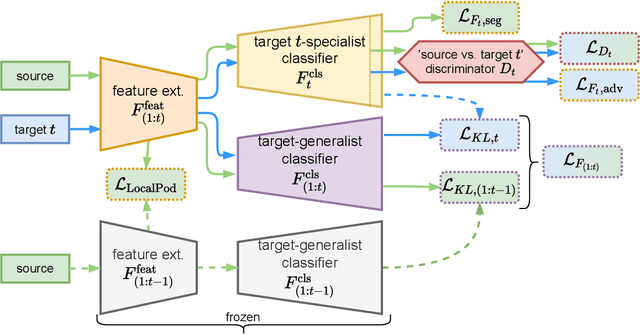
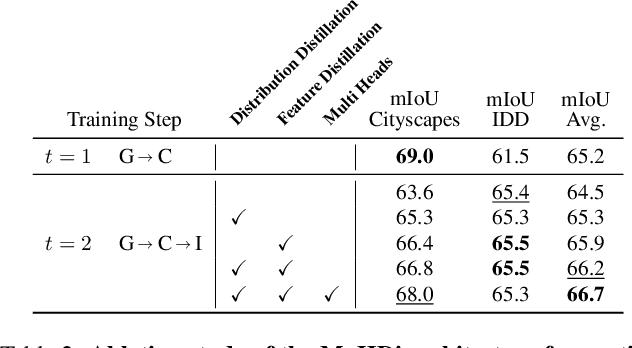
Unsupervised Domain Adaptation (UDA) is a transfer learning task which aims at training on an unlabeled target domain by leveraging a labeled source domain. Beyond the traditional scope of UDA with a single source domain and a single target domain, real-world perception systems face a variety of scenarios to handle, from varying lighting conditions to many cities around the world. In this context, UDAs with several domains increase the challenges with the addition of distribution shifts within the different target domains. This work focuses on a novel framework for learning UDA, continuous UDA, in which models operate on multiple target domains discovered sequentially, without access to previous target domains. We propose MuHDi, for Multi-Head Distillation, a method that solves the catastrophic forgetting problem, inherent in continual learning tasks. MuHDi performs distillation at multiple levels from the previous model as well as an auxiliary target-specialist segmentation head. We report both extensive ablation and experiments on challenging multi-target UDA semantic segmentation benchmarks to validate the proposed learning scheme and architecture.
Drive&Segment: Unsupervised Semantic Segmentation of Urban Scenes via Cross-modal Distillation
Mar 21, 2022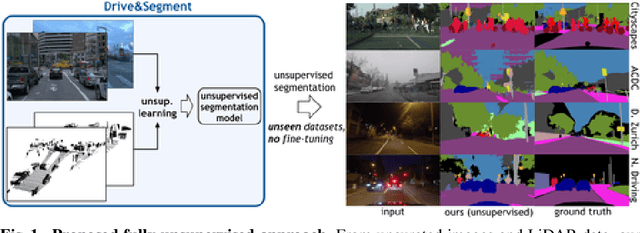
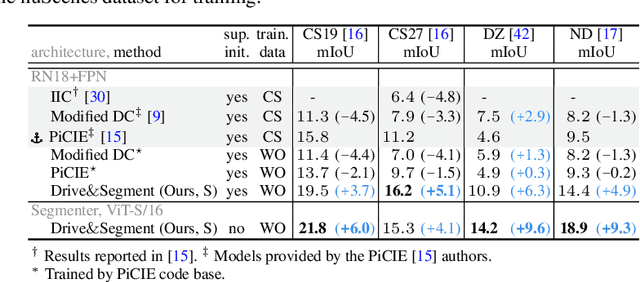
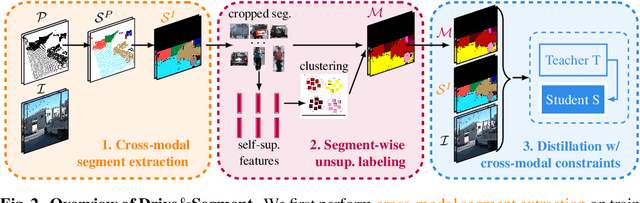
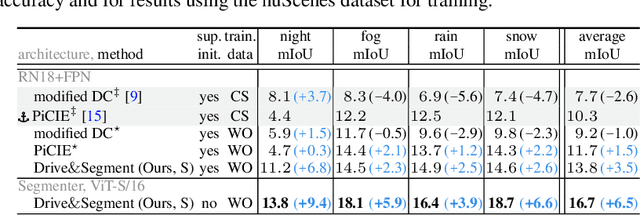
This work investigates learning pixel-wise semantic image segmentation in urban scenes without any manual annotation, just from the raw non-curated data collected by cars which, equipped with cameras and LiDAR sensors, drive around a city. Our contributions are threefold. First, we propose a novel method for cross-modal unsupervised learning of semantic image segmentation by leveraging synchronized LiDAR and image data. The key ingredient of our method is the use of an object proposal module that analyzes the LiDAR point cloud to obtain proposals for spatially consistent objects. Second, we show that these 3D object proposals can be aligned with the input images and reliably clustered into semantically meaningful pseudo-classes. Finally, we develop a cross-modal distillation approach that leverages image data partially annotated with the resulting pseudo-classes to train a transformer-based model for image semantic segmentation. We show the generalization capabilities of our method by testing on four different testing datasets (Cityscapes, Dark Zurich, Nighttime Driving and ACDC) without any finetuning, and demonstrate significant improvements compared to the current state of the art on this problem. See project webpage https://vobecant.github.io/DriveAndSegment/ for the code and more.
Raw High-Definition Radar for Multi-Task Learning
Dec 20, 2021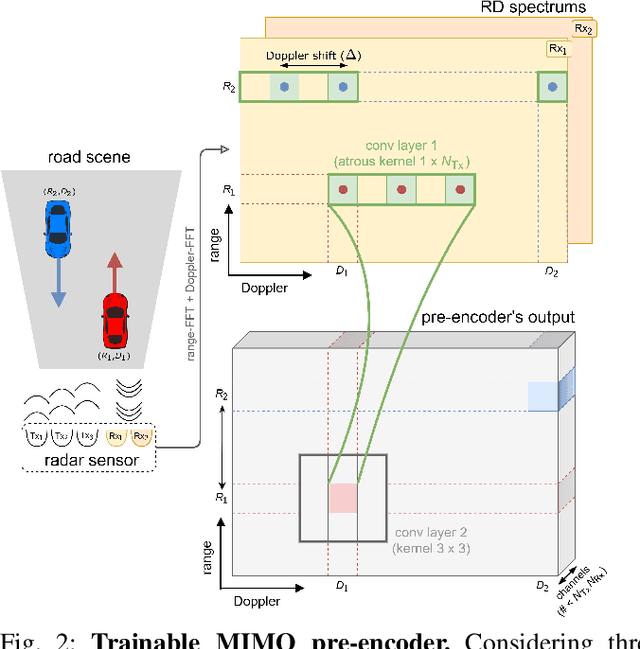
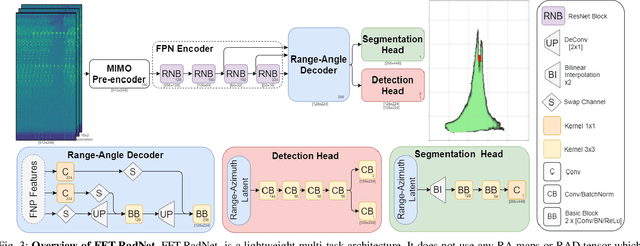
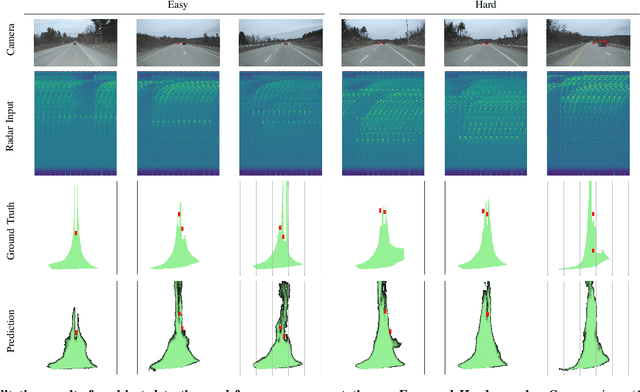
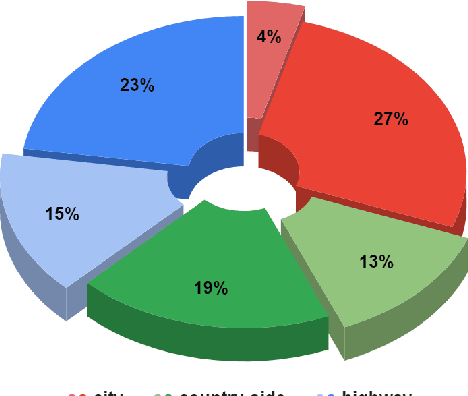
With their robustness to adverse weather conditions and ability to measure speeds, radar sensors have been part of the automotive landscape for more than two decades. Recent progress toward High Definition (HD) Imaging radar has driven the angular resolution below the degree, thus approaching laser scanning performance. However, the amount of data a HD radar delivers and the computational cost to estimate the angular positions remain a challenge. In this paper, we propose a novel HD radar sensing model, FFT-RadNet, that eliminates the overhead of computing the Range-Azimuth-Doppler 3D tensor, learning instead to recover angles from a Range-Doppler spectrum. FFT-RadNet is trained both to detect vehicles and to segment free driving space. On both tasks, it competes with the most recent radar-based models while requiring less compute and memory. Also, we collected and annotated 2-hour worth of raw data from synchronized automotive-grade sensors (camera, laser, HD radar) in various environments (city street, highway, countryside road). This unique dataset, nick-named RADIal for "Radar, Lidar et al.", is available at https://github.com/valeoai/RADIal.
CSG0: Continual Urban Scene Generation with Zero Forgetting
Dec 06, 2021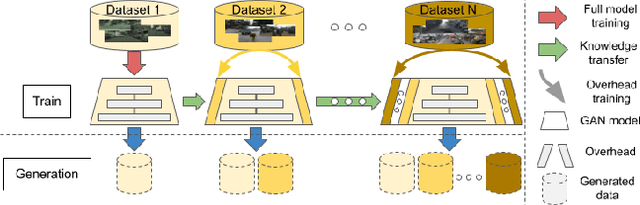
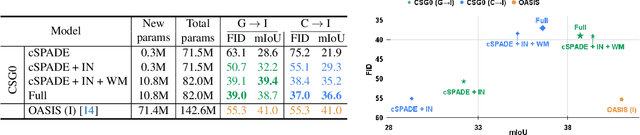
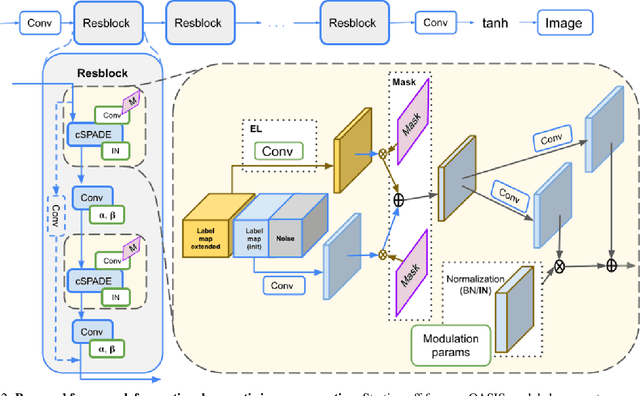
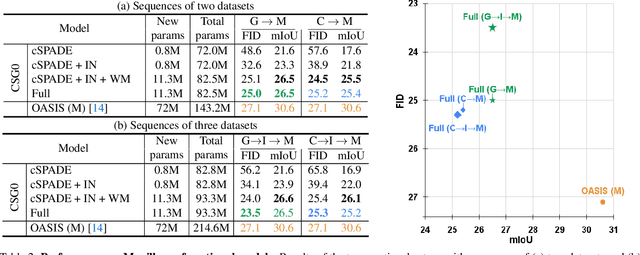
With the rapid advances in generative adversarial networks (GANs), the visual quality of synthesised scenes keeps improving, including for complex urban scenes with applications to automated driving. We address in this work a continual scene generation setup in which GANs are trained on a stream of distinct domains; ideally, the learned models should eventually be able to generate new scenes in all seen domains. This setup reflects the real-life scenario where data are continuously acquired in different places at different times. In such a continual setup, we aim for learning with zero forgetting, i.e., with no degradation in synthesis quality over earlier domains due to catastrophic forgetting. To this end, we introduce a novel framework that not only (i) enables seamless knowledge transfer in continual training but also (ii) guarantees zero forgetting with a small overhead cost. While being more memory efficient, thanks to continual learning, our model obtains better synthesis quality as compared against the brute-force solution that trains one full model for each domain. Especially, under extreme low-data regimes, our approach significantly outperforms the brute-force one by a large margin.
STEEX: Steering Counterfactual Explanations with Semantics
Nov 26, 2021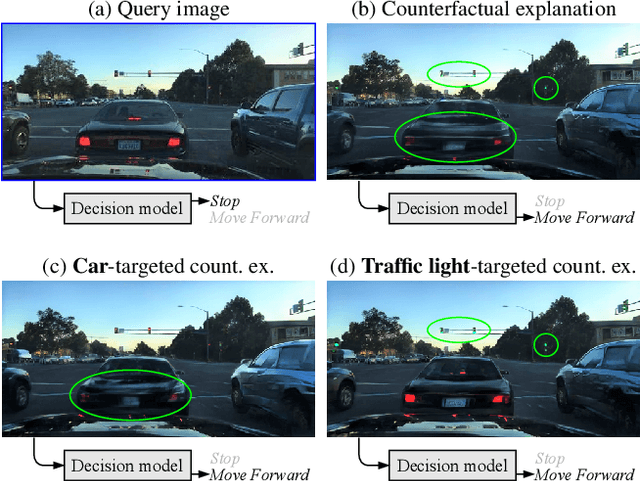
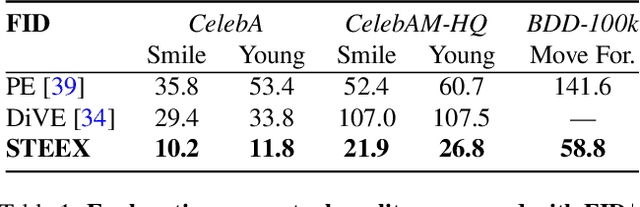
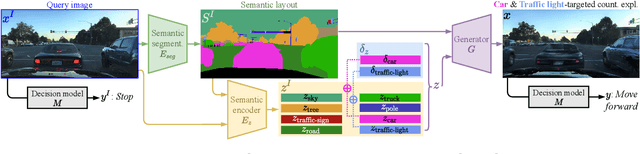
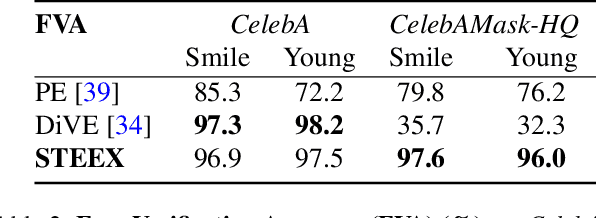
As deep learning models are increasingly used in safety-critical applications, explainability and trustworthiness become major concerns. For simple images, such as low-resolution face portraits, synthesizing visual counterfactual explanations has recently been proposed as a way to uncover the decision mechanisms of a trained classification model. In this work, we address the problem of producing counterfactual explanations for high-quality images and complex scenes. Leveraging recent semantic-to-image models, we propose a new generative counterfactual explanation framework that produces plausible and sparse modifications which preserve the overall scene structure. Furthermore, we introduce the concept of "region-targeted counterfactual explanations", and a corresponding framework, where users can guide the generation of counterfactuals by specifying a set of semantic regions of the query image the explanation must be about. Extensive experiments are conducted on challenging datasets including high-quality portraits (CelebAMask-HQ) and driving scenes (BDD100k).
Localizing Objects with Self-Supervised Transformers and no Labels
Sep 29, 2021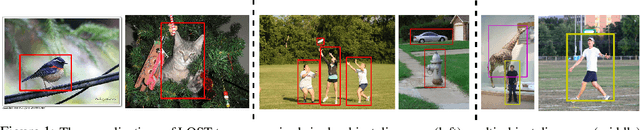
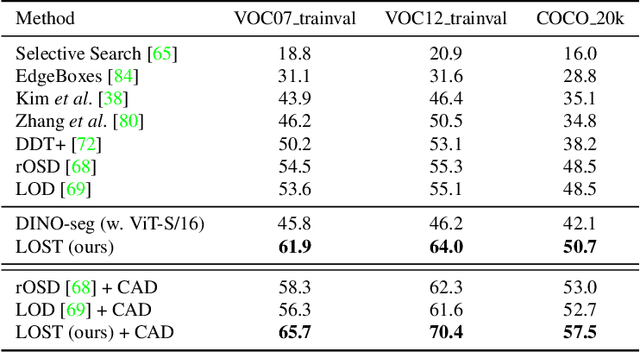

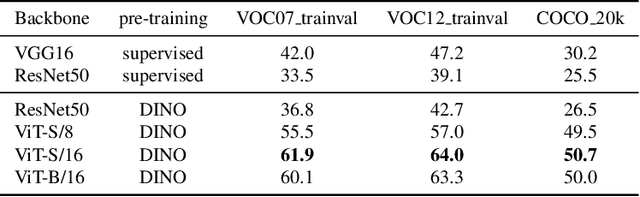
Localizing objects in image collections without supervision can help to avoid expensive annotation campaigns. We propose a simple approach to this problem, that leverages the activation features of a vision transformer pre-trained in a self-supervised manner. Our method, LOST, does not require any external object proposal nor any exploration of the image collection; it operates on a single image. Yet, we outperform state-of-the-art object discovery methods by up to 8 CorLoc points on PASCAL VOC 2012. We also show that training a class-agnostic detector on the discovered objects boosts results by another 7 points. Moreover, we show promising results on the unsupervised object discovery task. The code to reproduce our results can be found at https://github.com/valeoai/LOST.
Raising context awareness in motion forecasting
Sep 16, 2021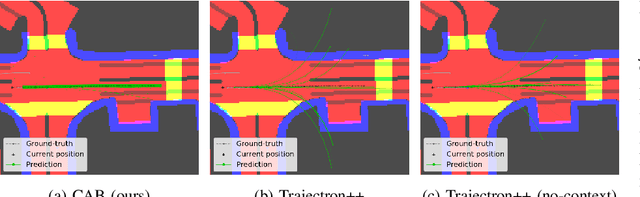
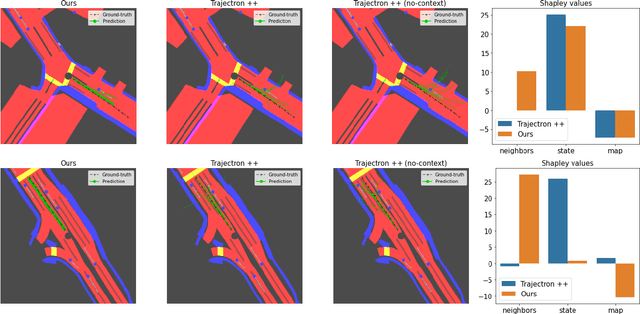
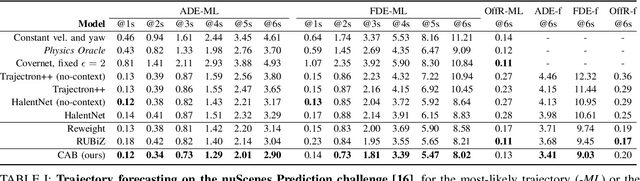
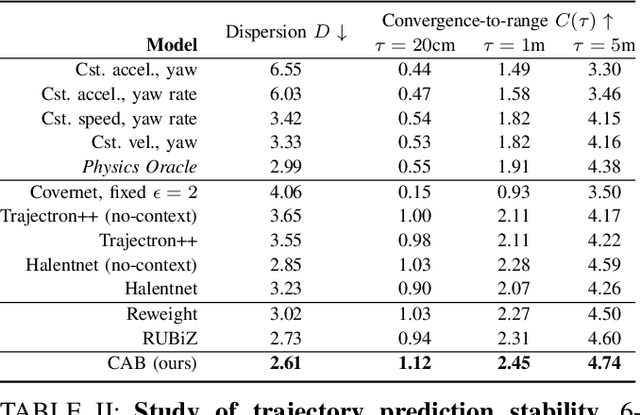
Learning-based trajectory prediction models have encountered great success, with the promise of leveraging contextual information in addition to motion history. Yet, we find that state-of-the-art forecasting methods tend to overly rely on the agent's dynamics, failing to exploit the semantic cues provided at its input. To alleviate this issue, we introduce CAB, a motion forecasting model equipped with a training procedure designed to promote the use of semantic contextual information. We also introduce two novel metrics -- dispersion and convergence-to-range -- to measure the temporal consistency of successive forecasts, which we found missing in standard metrics. Our method is evaluated on the widely adopted nuScenes Prediction benchmark.
LiDARTouch: Monocular metric depth estimation with a few-beam LiDAR
Sep 08, 2021
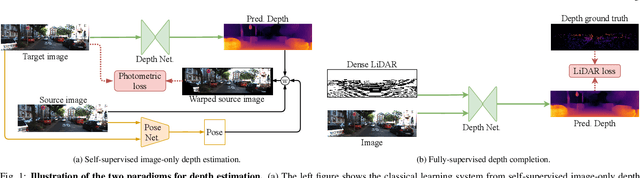
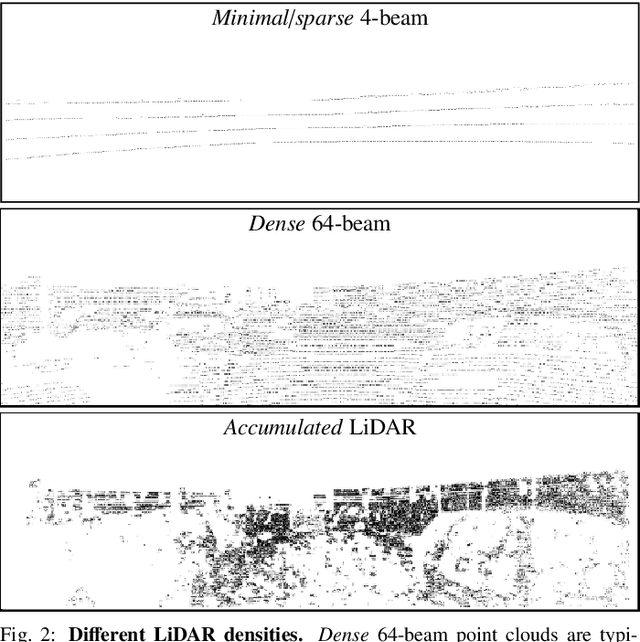
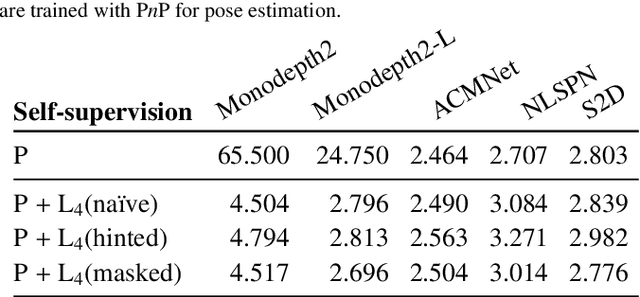
Vision-based depth estimation is a key feature in autonomous systems, which often relies on a single camera or several independent ones. In such a monocular setup, dense depth is obtained with either additional input from one or several expensive LiDARs, e.g., with 64 beams, or camera-only methods, which suffer from scale-ambiguity and infinite-depth problems. In this paper, we propose a new alternative of densely estimating metric depth by combining a monocular camera with a light-weight LiDAR, e.g., with 4 beams, typical of today's automotive-grade mass-produced laser scanners. Inspired by recent self-supervised methods, we introduce a novel framework, called LiDARTouch, to estimate dense depth maps from monocular images with the help of ``touches'' of LiDAR, i.e., without the need for dense ground-truth depth. In our setup, the minimal LiDAR input contributes on three different levels: as an additional model's input, in a self-supervised LiDAR reconstruction objective function, and to estimate changes of pose (a key component of self-supervised depth estimation architectures). Our LiDARTouch framework achieves new state of the art in self-supervised depth estimation on the KITTI dataset, thus supporting our choices of integrating the very sparse LiDAR signal with other visual features. Moreover, we show that the use of a few-beam LiDAR alleviates scale ambiguity and infinite-depth issues that camera-only methods suffer from. We also demonstrate that methods from the fully-supervised depth-completion literature can be adapted to a self-supervised regime with a minimal LiDAR signal.