 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy-Conditioned Policies for Multi-Agent Task Solving
Dec 24, 2025


In multi-agent tasks, the central challenge lies in the dynamic adaptation of strategies. However, directly conditioning on opponents' strategies is intractable in the prevalent deep reinforcement learning paradigm due to a fundamental ``representational bottleneck'': neural policies are opaque, high-dimensional parameter vectors that are incomprehensible to other agents. In this work, we propose a paradigm shift that bridges this gap by representing policies as human-interpretable source code and utilizing Large Language Models (LLMs) as approximate interpreters. This programmatic representation allows us to operationalize the game-theoretic concept of \textit{Program Equilibrium}. We reformulate the learning problem by utilizing LLMs to perform optimization directly in the space of programmatic policies. The LLM functions as a point-wise best-response operator that iteratively synthesizes and refines the ego agent's policy code to respond to the opponent's strategy. We formalize this process as \textit{Programmatic Iterated Best Response (PIBR)}, an algorithm where the policy code is optimized by textual gradients, using structured feedback derived from game utility and runtime unit tests. We demonstrate that this approach effectively solves several standard coordination matrix games and a cooperative Level-Based Foraging environment.
Image-POSER: Reflective RL for Multi-Expert Image Generation and Editing
Nov 15, 2025
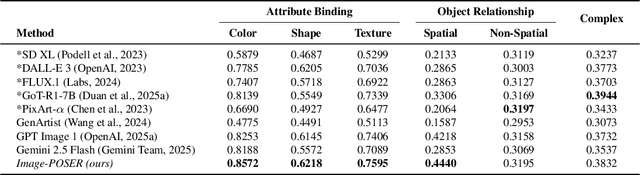
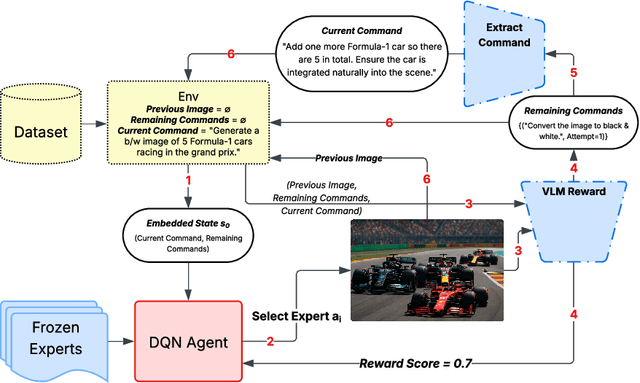
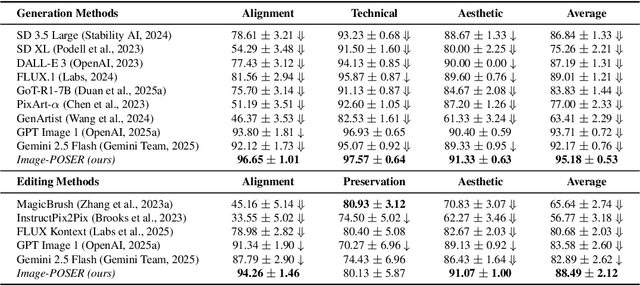
Recent advances in text-to-image generation have produced strong single-shot models, yet no individual system reliably executes the long, compositional prompts typical of creative workflows. We introduce Image-POSER, a reflective reinforcement learning framework that (i) orchestrates a diverse registry of pretrained text-to-image and image-to-image experts, (ii) handles long-form prompts end-to-end through dynamic task decomposition, and (iii) supervises alignment at each step via structured feedback from a vision-language model critic. By casting image synthesis and editing as a Markov Decision Process, we learn non-trivial expert pipelines that adaptively combine strengths across models. Experiments show that Image-POSER outperforms baselines, including frontier models, across industry-standard and custom benchmarks in alignment, fidelity, and aesthetics, and is consistently preferred in human evaluations. These results highlight that reinforcement learning can endow AI systems with the capacity to autonomously decompose, reorder, and combine visual models, moving towards general-purpose visual assistants.
Time Is Effort: Estimating Human Post-Editing Time for Grammar Error Correction Tool Evaluation
Oct 05, 2025Text editing can involve several iterations of revision. Incorporating an efficient Grammar Error Correction (GEC) tool in the initial correction round can significantly impact further human editing effort and final text quality. This raises an interesting question to quantify GEC Tool usability: How much effort can the GEC Tool save users? We present the first large-scale dataset of post-editing (PE) time annotations and corrections for two English GEC test datasets (BEA19 and CoNLL14). We introduce Post-Editing Effort in Time (PEET) for GEC Tools as a human-focused evaluation scorer to rank any GEC Tool by estimating PE time-to-correct. Using our dataset, we quantify the amount of time saved by GEC Tools in text editing. Analyzing the edit type indicated that determining whether a sentence needs correction and edits like paraphrasing and punctuation changes had the greatest impact on PE time. Finally, comparison with human rankings shows that PEET correlates well with technical effort judgment, providing a new human-centric direction for evaluating GEC tool usability. We release our dataset and code at: https://github.com/ankitvad/PEET_Scorer.
Information Bargaining: Bilateral Commitment in Bayesian Persuasion
Jun 09, 2025Bayesian persuasion, an extension of cheap-talk communication, involves an informed sender committing to a signaling scheme to influence a receiver's actions. Compared to cheap talk, this sender's commitment enables the receiver to verify the incentive compatibility of signals beforehand, facilitating cooperation. While effective in one-shot scenarios, Bayesian persuasion faces computational complexity (NP-hardness) when extended to long-term interactions, where the receiver may adopt dynamic strategies conditional on past outcomes and future expectations. To address this complexity, we introduce the bargaining perspective, which allows: (1) a unified framework and well-structured solution concept for long-term persuasion, with desirable properties such as fairness and Pareto efficiency; (2) a clear distinction between two previously conflated advantages: the sender's informational advantage and first-proposer advantage. With only modest modifications to the standard setting, this perspective makes explicit the common knowledge of the game structure and grants the receiver comparable commitment capabilities, thereby reinterpreting classic one-sided persuasion as a balanced information bargaining framework. The framework is validated through a two-stage validation-and-inference paradigm: We first demonstrate that GPT-o3 and DeepSeek-R1, out of publicly available LLMs, reliably handle standard tasks; We then apply them to persuasion scenarios to test that the outcomes align with what our information-bargaining framework suggests. All code, results, and terminal logs are publicly available at github.com/YueLin301/InformationBargaining.
Basis Transformers for Multi-Task Tabular Regression
Jun 07, 2025Dealing with tabular data is challenging due to partial information, noise, and heterogeneous structure. Existing techniques often struggle to simultaneously address key aspects of tabular data such as textual information, a variable number of columns, and unseen data without metadata besides column names. We propose a novel architecture, \textit{basis transformers}, specifically designed to tackle these challenges while respecting inherent invariances in tabular data, including hierarchical structure and the representation of numeric values. We evaluate our design on a multi-task tabular regression benchmark, achieving an improvement of 0.338 in the median $R^2$ score and the lowest standard deviation across 34 tasks from the OpenML-CTR23 benchmark. Furthermore, our model has five times fewer parameters than the best-performing baseline and surpasses pretrained large language model baselines -- even when initialized from randomized weights.
Reflect-then-Plan: Offline Model-Based Planning through a Doubly Bayesian Lens
Jun 06, 2025Offline reinforcement learning (RL) is crucial when online exploration is costly or unsafe but often struggles with high epistemic uncertainty due to limited data. Existing methods rely on fixed conservative policies, restricting adaptivity and generalization. To address this, we propose Reflect-then-Plan (RefPlan), a novel doubly Bayesian offline model-based (MB) planning approach. RefPlan unifies uncertainty modeling and MB planning by recasting planning as Bayesian posterior estimation. At deployment, it updates a belief over environment dynamics using real-time observations, incorporating uncertainty into MB planning via marginalization. Empirical results on standard benchmarks show that RefPlan significantly improves the performance of conservative offline RL policies. In particular, RefPlan maintains robust performance under high epistemic uncertainty and limited data, while demonstrating resilience to changing environment dynamics, improving the flexibility, generalizability, and robustness of offline-learned policies.
Bayesian Persuasion as a Bargaining Game
Jun 06, 2025Bayesian persuasion, an extension of cheap-talk communication, involves an informed sender committing to a signaling scheme to influence a receiver's actions. Compared to cheap talk, this sender's commitment enables the receiver to verify the incentive compatibility of signals beforehand, facilitating cooperation. While effective in one-shot scenarios, Bayesian persuasion faces computational complexity (NP-hardness) when extended to long-term interactions, where the receiver may adopt dynamic strategies conditional on past outcomes and future expectations. To address this complexity, we introduce the bargaining perspective, which allows: (1) a unified framework and well-structured solution concept for long-term persuasion, with desirable properties such as fairness and Pareto efficiency; (2) a clear distinction between two previously conflated advantages: the sender's informational advantage and first-proposer advantage. With only modest modifications to the standard setting, this perspective makes explicit the common knowledge of the game structure and grants the receiver comparable commitment capabilities, thereby reinterpreting classic one-sided persuasion as a balanced information bargaining framework. The framework is validated through a two-stage validation-and-inference paradigm: We first demonstrate that GPT-o3 and DeepSeek-R1, out of publicly available LLMs, reliably handle standard tasks; We then apply them to persuasion scenarios to test that the outcomes align with what our information-bargaining framework suggests. All code, results, and terminal logs are publicly available at github.com/YueLin301/InformationBargaining.
Simplifying Bayesian Optimization Via In-Context Direct Optimum Sampling
May 29, 2025The optimization of expensive black-box functions is ubiquitous in science and engineering. A common solution to this problem is Bayesian optimization (BO), which is generally comprised of two components: (i) a surrogate model and (ii) an acquisition function, which generally require expensive re-training and optimization steps at each iteration, respectively. Although recent work enabled in-context surrogate models that do not require re-training, virtually all existing BO methods still require acquisition function maximization to select the next observation, which introduces many knobs to tune, such as Monte Carlo samplers and multi-start optimizers. In this work, we propose a completely in-context, zero-shot solution for BO that does not require surrogate fitting or acquisition function optimization. This is done by using a pre-trained deep generative model to directly sample from the posterior over the optimum point. We show that this process is equivalent to Thompson sampling and demonstrate the capabilities and cost-effectiveness of our foundation model on a suite of real-world benchmarks. We achieve an efficiency gain of more than 35x in terms of wall-clock time when compared with Gaussian process-based BO, enabling efficient parallel and distributed BO, e.g., for high-throughput optimization.
Measures of Variability for Risk-averse Policy Gradient
Apr 15, 2025Risk-averse reinforcement learning (RARL) is critical for decision-making under uncertainty, which is especially valuable in high-stake applications. However, most existing works focus on risk measures, e.g., conditional value-at-risk (CVaR), while measures of variability remain underexplored. In this paper, we comprehensively study nine common measures of variability, namely Variance, Gini Deviation, Mean Deviation, Mean-Median Deviation, Standard Deviation, Inter-Quantile Range, CVaR Deviation, Semi_Variance, and Semi_Standard Deviation. Among them, four metrics have not been previously studied in RARL. We derive policy gradient formulas for these unstudied metrics, improve gradient estimation for Gini Deviation, analyze their gradient properties, and incorporate them with the REINFORCE and PPO frameworks to penalize the dispersion of returns. Our empirical study reveals that variance-based metrics lead to unstable policy updates. In contrast, CVaR Deviation and Gini Deviation show consistent performance across different randomness and evaluation domains, achieving high returns while effectively learning risk-averse policies. Mean Deviation and Semi_Standard Deviation are also competitive across different scenarios. This work provides a comprehensive overview of variability measures in RARL, offering practical insights for risk-aware decision-making and guiding future research on risk metrics and RARL algorithms.
Learning to Negotiate via Voluntary Commitment
Mar 05, 2025



The partial alignment and conflict of autonomous agents lead to mixed-motive scenarios in many real-world applications. However, agents may fail to cooperate in practice even when cooperation yields a better outcome. One well known reason for this failure comes from non-credible commitments. To facilitate commitments among agents for better cooperation, we define Markov Commitment Games (MCGs), a variant of commitment games, where agents can voluntarily commit to their proposed future plans. Based on MCGs, we propose a learnable commitment protocol via policy gradients. We further propose incentive-compatible learning to accelerate convergence to equilibria with better social welfare. Experimental results in challenging mixed-motive tasks demonstrate faster empirical convergence and higher returns for our method compared with its counterparts. Our code is available at https://github.com/shuhui-zhu/DCL.