 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo SSL Models Have Déjà Vu? A Case of Unintended Memorization in Self-supervised Learning
Apr 28, 2023



Self-supervised learning (SSL) algorithms can produce useful image representations by learning to associate different parts of natural images with one another. However, when taken to the extreme, SSL models can unintendedly memorize specific parts in individual training samples rather than learning semantically meaningful associations. In this work, we perform a systematic study of the unintended memorization of image-specific information in SSL models -- which we refer to as d\'ej\`a vu memorization. Concretely, we show that given the trained model and a crop of a training image containing only the background (e.g., water, sky, grass), it is possible to infer the foreground object with high accuracy or even visually reconstruct it. Furthermore, we show that d\'ej\`a vu memorization is common to different SSL algorithms, is exacerbated by certain design choices, and cannot be detected by conventional techniques for evaluating representation quality. Our study of d\'ej\`a vu memorization reveals previously unknown privacy risks in SSL models, as well as suggests potential practical mitigation strategies. Code is available at https://github.com/facebookresearch/DejaVu.
Objectives Matter: Understanding the Impact of Self-Supervised Objectives on Vision Transformer Representations
Apr 25, 2023Joint-embedding based learning (e.g., SimCLR, MoCo, DINO) and reconstruction-based learning (e.g., BEiT, SimMIM, MAE) are the two leading paradigms for self-supervised learning of vision transformers, but they differ substantially in their transfer performance. Here, we aim to explain these differences by analyzing the impact of these objectives on the structure and transferability of the learned representations. Our analysis reveals that reconstruction-based learning features are significantly dissimilar to joint-embedding based learning features and that models trained with similar objectives learn similar features even across architectures. These differences arise early in the network and are primarily driven by attention and normalization layers. We find that joint-embedding features yield better linear probe transfer for classification because the different objectives drive different distributions of information and invariances in the learned representation. These differences explain opposite trends in transfer performance for downstream tasks that require spatial specificity in features. Finally, we address how fine-tuning changes reconstructive representations to enable better transfer, showing that fine-tuning re-organizes the information to be more similar to pre-trained joint embedding models.
A surprisingly simple technique to control the pretraining bias for better transfer: Expand or Narrow your representation
Apr 11, 2023



Self-Supervised Learning (SSL) models rely on a pretext task to learn representations. Because this pretext task differs from the downstream tasks used to evaluate the performance of these models, there is an inherent misalignment or pretraining bias. A commonly used trick in SSL, shown to make deep networks more robust to such bias, is the addition of a small projector (usually a 2 or 3 layer multi-layer perceptron) on top of a backbone network during training. In contrast to previous work that studied the impact of the projector architecture, we here focus on a simpler, yet overlooked lever to control the information in the backbone representation. We show that merely changing its dimensionality -- by changing only the size of the backbone's very last block -- is a remarkably effective technique to mitigate the pretraining bias. It significantly improves downstream transfer performance for both Self-Supervised and Supervised pretrained models.
Instance-Conditioned GAN Data Augmentation for Representation Learning
Mar 16, 2023



Data augmentation has become a crucial component to train state-of-the-art visual representation models. However, handcrafting combinations of transformations that lead to improved performances is a laborious task, which can result in visually unrealistic samples. To overcome these limitations, recent works have explored the use of generative models as learnable data augmentation tools, showing promising results in narrow application domains, e.g., few-shot learning and low-data medical imaging. In this paper, we introduce a data augmentation module, called DA_IC-GAN, which leverages instance-conditioned GAN generations and can be used off-the-shelf in conjunction with most state-of-the-art training recipes. We showcase the benefits of DA_IC-GAN by plugging it out-of-the-box into the supervised training of ResNets and DeiT models on the ImageNet dataset, and achieving accuracy boosts up to between 1%p and 2%p with the highest capacity models. Moreover, the learnt representations are shown to be more robust than the baselines when transferred to a handful of out-of-distribution datasets, and exhibit increased invariance to variations of instance and viewpoints. We additionally couple DA_IC-GAN with a self-supervised training recipe and show that we can also achieve an improvement of 1%p in accuracy in some settings. With this work, we strengthen the evidence on the potential of learnable data augmentations to improve visual representation learning, paving the road towards non-handcrafted augmentations in model training.
Towards Democratizing Joint-Embedding Self-Supervised Learning
Mar 03, 2023



Joint Embedding Self-Supervised Learning (JE-SSL) has seen rapid developments in recent years, due to its promise to effectively leverage large unlabeled data. The development of JE-SSL methods was driven primarily by the search for ever increasing downstream classification accuracies, using huge computational resources, and typically built upon insights and intuitions inherited from a close parent JE-SSL method. This has led unwittingly to numerous pre-conceived ideas that carried over across methods e.g. that SimCLR requires very large mini batches to yield competitive accuracies; that strong and computationally slow data augmentations are required. In this work, we debunk several such ill-formed a priori ideas in the hope to unleash the full potential of JE-SSL free of unnecessary limitations. In fact, when carefully evaluating performances across different downstream tasks and properly optimizing hyper-parameters of the methods, we most often -- if not always -- see that these widespread misconceptions do not hold. For example we show that it is possible to train SimCLR to learn useful representations, while using a single image patch as negative example, and simple Gaussian noise as the only data augmentation for the positive pair. Along these lines, in the hope to democratize JE-SSL and to allow researchers to easily make more extensive evaluations of their methods, we introduce an optimized PyTorch library for SSL.
Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
Jan 19, 2023



This paper demonstrates an approach for learning highly semantic image representations without relying on hand-crafted data-augmentations. We introduce the Image-based Joint-Embedding Predictive Architecture (I-JEPA), a non-generative approach for self-supervised learning from images. The idea behind I-JEPA is simple: from a single context block, predict the representations of various target blocks in the same image. A core design choice to guide I-JEPA towards producing semantic representations is the masking strategy; specifically, it is crucial to (a) predict several target blocks in the image, (b) sample target blocks with sufficiently large scale (occupying 15%-20% of the image), and (c) use a sufficiently informative (spatially distributed) context block. Empirically, when combined with Vision Transformers, we find I-JEPA to be highly scalable. For instance, we train a ViT-Huge/16 on ImageNet using 32 A100 GPUs in under 38 hours to achieve strong downstream performance across a wide range of tasks requiring various levels of abstraction, from linear classification to object counting and depth prediction.
ImageNet-X: Understanding Model Mistakes with Factor of Variation Annotations
Nov 03, 2022Deep learning vision systems are widely deployed across applications where reliability is critical. However, even today's best models can fail to recognize an object when its pose, lighting, or background varies. While existing benchmarks surface examples challenging for models, they do not explain why such mistakes arise. To address this need, we introduce ImageNet-X, a set of sixteen human annotations of factors such as pose, background, or lighting the entire ImageNet-1k validation set as well as a random subset of 12k training images. Equipped with ImageNet-X, we investigate 2,200 current recognition models and study the types of mistakes as a function of model's (1) architecture, e.g. transformer vs. convolutional, (2) learning paradigm, e.g. supervised vs. self-supervised, and (3) training procedures, e.g., data augmentation. Regardless of these choices, we find models have consistent failure modes across ImageNet-X categories. We also find that while data augmentation can improve robustness to certain factors, they induce spill-over effects to other factors. For example, strong random cropping hurts robustness on smaller objects. Together, these insights suggest to advance the robustness of modern vision models, future research should focus on collecting additional data and understanding data augmentation schemes. Along with these insights, we release a toolkit based on ImageNet-X to spur further study into the mistakes image recognition systems make.
Disentanglement of Correlated Factors via Hausdorff Factorized Support
Oct 13, 2022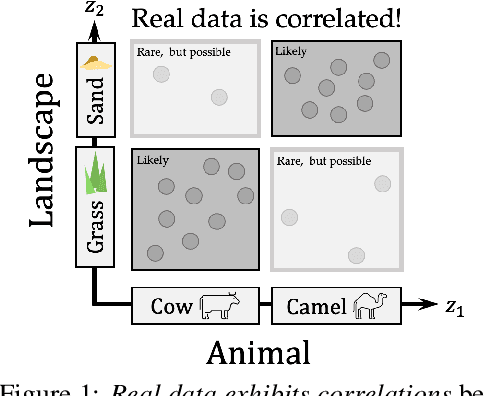
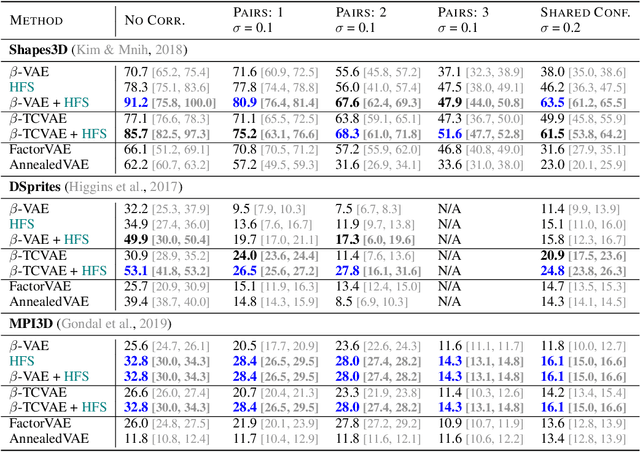
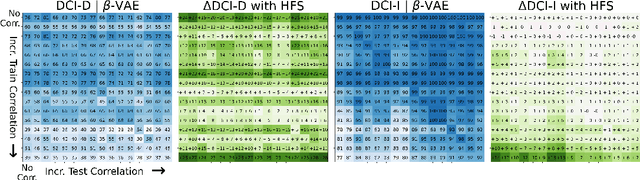
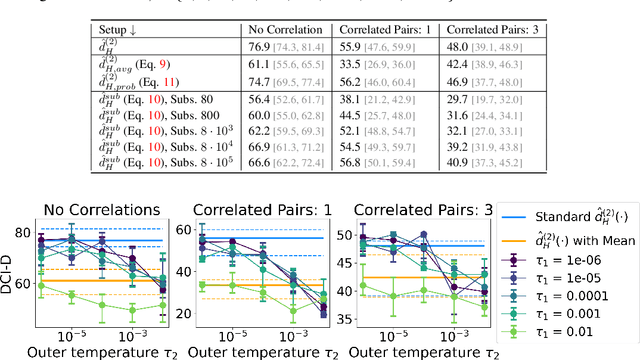
A grand goal in deep learning research is to learn representations capable of generalizing across distribution shifts. Disentanglement is one promising direction aimed at aligning a models representations with the underlying factors generating the data (e.g. color or background). Existing disentanglement methods, however, rely on an often unrealistic assumption: that factors are statistically independent. In reality, factors (like object color and shape) are correlated. To address this limitation, we propose a relaxed disentanglement criterion - the Hausdorff Factorized Support (HFS) criterion - that encourages a factorized support, rather than a factorial distribution, by minimizing a Hausdorff distance. This allows for arbitrary distributions of the factors over their support, including correlations between them. We show that the use of HFS consistently facilitates disentanglement and recovery of ground-truth factors across a variety of correlation settings and benchmarks, even under severe training correlations and correlation shifts, with in parts over +60% in relative improvement over existing disentanglement methods. In addition, we find that leveraging HFS for representation learning can even facilitate transfer to downstream tasks such as classification under distribution shifts. We hope our original approach and positive empirical results inspire further progress on the open problem of robust generalization.
The Hidden Uniform Cluster Prior in Self-Supervised Learning
Oct 13, 2022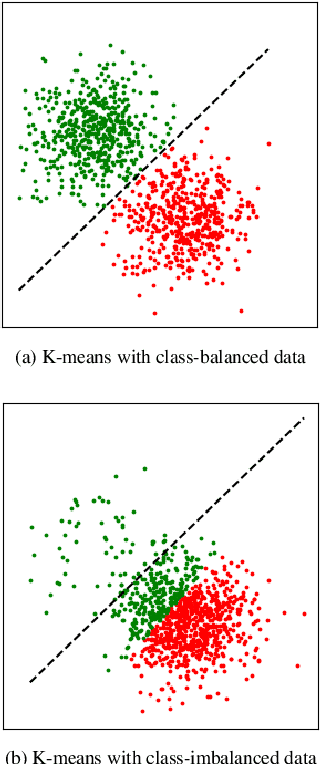


A successful paradigm in representation learning is to perform self-supervised pretraining using tasks based on mini-batch statistics (e.g., SimCLR, VICReg, SwAV, MSN). We show that in the formulation of all these methods is an overlooked prior to learn features that enable uniform clustering of the data. While this prior has led to remarkably semantic representations when pretraining on class-balanced data, such as ImageNet, we demonstrate that it can hamper performance when pretraining on class-imbalanced data. By moving away from conventional uniformity priors and instead preferring power-law distributed feature clusters, we show that one can improve the quality of the learned representations on real-world class-imbalanced datasets. To demonstrate this, we develop an extension of the Masked Siamese Networks (MSN) method to support the use of arbitrary features priors.
Guillotine Regularization: Improving Deep Networks Generalization by Removing their Head
Jun 27, 2022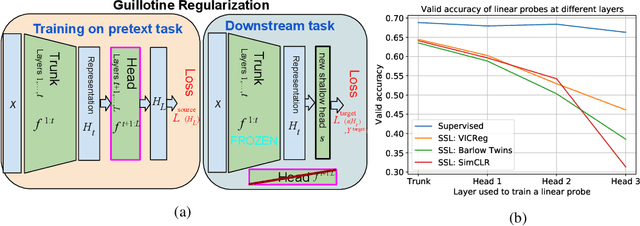
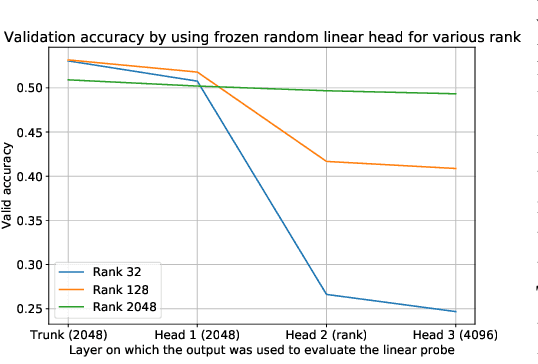
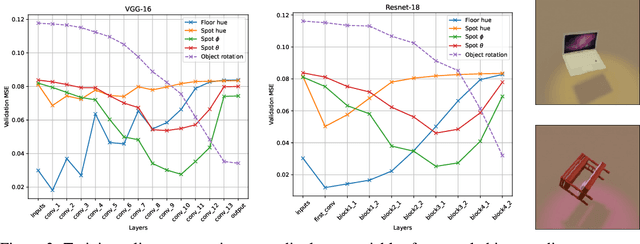
One unexpected technique that emerged in recent years consists in training a Deep Network (DN) with a Self-Supervised Learning (SSL) method, and using this network on downstream tasks but with its last few layers entirely removed. This usually skimmed-over trick is actually critical for SSL methods to display competitive performances. For example, on ImageNet classification, more than 30 points of percentage can be gained that way. This is a little vexing, as one would hope that the network layer at which invariance is explicitly enforced by the SSL criterion during training (the last layer) should be the one to use for best generalization performance downstream. But it seems not to be, and this study sheds some light on why. This trick, which we name Guillotine Regularization (GR), is in fact a generically applicable form of regularization that has also been used to improve generalization performance in transfer learning scenarios. In this work, through theory and experiments, we formalize GR and identify the underlying reasons behind its success in SSL methods. Our study shows that the use of this trick is essential to SSL performance for two main reasons: (i) improper data-augmentations to define the positive pairs used during training, and/or (ii) suboptimal selection of the hyper-parameters of the SSL loss.