 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest Time Learning for Time Series Forecasting
Sep 21, 2024Time-series forecasting has seen significant advancements with the introduction of token prediction mechanisms such as multi-head attention. However, these methods often struggle to achieve the same performance as in language modeling, primarily due to the quadratic computational cost and the complexity of capturing long-range dependencies in time-series data. State-space models (SSMs), such as Mamba, have shown promise in addressing these challenges by offering efficient solutions with linear RNNs capable of modeling long sequences with larger context windows. However, there remains room for improvement in accuracy and scalability. We propose the use of Test-Time Training (TTT) modules in a parallel architecture to enhance performance in long-term time series forecasting. Through extensive experiments on standard benchmark datasets, we demonstrate that TTT modules consistently outperform state-of-the-art models, including the Mamba-based TimeMachine, particularly in scenarios involving extended sequence and prediction lengths. Our results show significant improvements in Mean Squared Error (MSE) and Mean Absolute Error (MAE), especially on larger datasets such as Electricity, Traffic, and Weather, underscoring the effectiveness of TTT in capturing long-range dependencies. Additionally, we explore various convolutional architectures within the TTT framework, showing that even simple configurations like 1D convolution with small filters can achieve competitive results. This work sets a new benchmark for time-series forecasting and lays the groundwork for future research in scalable, high-performance forecasting models.
OnlySportsLM: Optimizing Sports-Domain Language Models with SOTA Performance under Billion Parameters
Aug 30, 2024



This paper explores the potential of a small, domain-specific language model trained exclusively on sports-related data. We investigate whether extensive training data with specially designed small model structures can overcome model size constraints. The study introduces the OnlySports collection, comprising OnlySportsLM, OnlySports Dataset, and OnlySports Benchmark. Our approach involves: 1) creating a massive 600 billion tokens OnlySports Dataset from FineWeb, 2) optimizing the RWKV architecture for sports-related tasks, resulting in a 196M parameters model with 20-layer, 640-dimension structure, 3) training the OnlySportsLM on part of OnlySports Dataset, and 4) testing the resultant model on OnlySports Benchmark. OnlySportsLM achieves a 37.62%/34.08% accuracy improvement over previous 135M/360M state-of-the-art models and matches the performance of larger models such as SomlLM 1.7B and Qwen 1.5B in the sports domain. Additionally, the OnlySports collection presents a comprehensive workflow for building high-quality, domain-specific language models, providing a replicable blueprint for efficient AI development across various specialized fields.
ConvNLP: Image-based AI Text Detection
Jul 09, 2024



The potentials of Generative-AI technologies like Large Language models (LLMs) to revolutionize education are undermined by ethical considerations around their misuse which worsens the problem of academic dishonesty. LLMs like GPT-4 and Llama 2 are becoming increasingly powerful in generating sophisticated content and answering questions, from writing academic essays to solving complex math problems. Students are relying on these LLMs to complete their assignments and thus compromising academic integrity. Solutions to detect LLM-generated text are compute-intensive and often lack generalization. This paper presents a novel approach for detecting LLM-generated AI-text using a visual representation of word embedding. We have formulated a novel Convolutional Neural Network called ZigZag ResNet, as well as a scheduler for improving generalization, named ZigZag Scheduler. Through extensive evaluation using datasets of text generated by six different state-of-the-art LLMs, our model demonstrates strong intra-domain and inter-domain generalization capabilities. Our best model detects AI-generated text with an impressive average detection rate (over inter- and intra-domain test data) of 88.35%. Through an exhaustive ablation study, our ZigZag ResNet and ZigZag Scheduler provide a performance improvement of nearly 4% over the vanilla ResNet. The end-to-end inference latency of our model is below 2.5ms per sentence. Our solution offers a lightweight, computationally efficient, and faster alternative to existing tools for AI-generated text detection, with better generalization performance. It can help academic institutions in their fight against the misuse of LLMs in academic settings. Through this work, we aim to contribute to safeguarding the principles of academic integrity and ensuring the trustworthiness of student work in the era of advanced LLMs.
Beyond Black Box AI-Generated Plagiarism Detection: From Sentence to Document Level
Jun 13, 2023The increasing reliance on large language models (LLMs) in academic writing has led to a rise in plagiarism. Existing AI-generated text classifiers have limited accuracy and often produce false positives. We propose a novel approach using natural language processing (NLP) techniques, offering quantifiable metrics at both sentence and document levels for easier interpretation by human evaluators. Our method employs a multi-faceted approach, generating multiple paraphrased versions of a given question and inputting them into the LLM to generate answers. By using a contrastive loss function based on cosine similarity, we match generated sentences with those from the student's response. Our approach achieves up to 94% accuracy in classifying human and AI text, providing a robust and adaptable solution for plagiarism detection in academic settings. This method improves with LLM advancements, reducing the need for new model training or reconfiguration, and offers a more transparent way of evaluating and detecting AI-generated text.
Accelerating Parallel Stochastic Gradient Descent via Non-blocking Mini-batches
Nov 09, 2022SOTA decentralized SGD algorithms can overcome the bandwidth bottleneck at the parameter server by using communication collectives like Ring All-Reduce for synchronization. While the parameter updates in distributed SGD may happen asynchronously there is still a synchronization barrier to make sure that the local training epoch at every learner is complete before the learners can advance to the next epoch. The delays in waiting for the slowest learners(stragglers) remain to be a problem in the synchronization steps of these state-of-the-art decentralized frameworks. In this paper, we propose the (de)centralized Non-blocking SGD (Non-blocking SGD) which can address the straggler problem in a heterogeneous environment. The main idea of Non-blocking SGD is to split the original batch into mini-batches, then accumulate the gradients and update the model based on finished mini-batches. The Non-blocking idea can be implemented using decentralized algorithms including Ring All-reduce, D-PSGD, and MATCHA to solve the straggler problem. Moreover, using gradient accumulation to update the model also guarantees convergence and avoids gradient staleness. Run-time analysis with random straggler delays and computational efficiency/throughput of devices is also presented to show the advantage of Non-blocking SGD. Experiments on a suite of datasets and deep learning networks validate the theoretical analyses and demonstrate that Non-blocking SGD speeds up the training and fastens the convergence. Compared with the state-of-the-art decentralized asynchronous algorithms like D-PSGD and MACHA, Non-blocking SGD takes up to 2x fewer time to reach the same training loss in a heterogeneous environment.
RCD-SGD: Resource-Constrained Distributed SGD in Heterogeneous Environment via Submodular Partitioning
Nov 02, 2022The convergence of SGD based distributed training algorithms is tied to the data distribution across workers. Standard partitioning techniques try to achieve equal-sized partitions with per-class population distribution in proportion to the total dataset. Partitions having the same overall population size or even the same number of samples per class may still have Non-IID distribution in the feature space. In heterogeneous computing environments, when devices have different computing capabilities, even-sized partitions across devices can lead to the straggler problem in distributed SGD. We develop a framework for distributed SGD in heterogeneous environments based on a novel data partitioning algorithm involving submodular optimization. Our data partitioning algorithm explicitly accounts for resource heterogeneity across workers while achieving similar class-level feature distribution and maintaining class balance. Based on this algorithm, we develop a distributed SGD framework that can accelerate existing SOTA distributed training algorithms by up to 32%.
G2L: A Geometric Approach for Generating Pseudo-labels that Improve Transfer Learning
Jul 07, 2022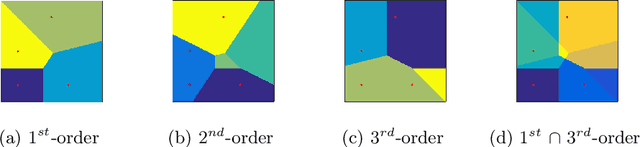
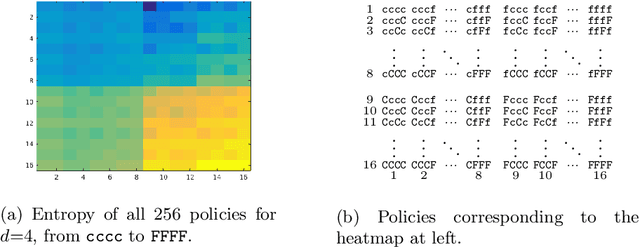
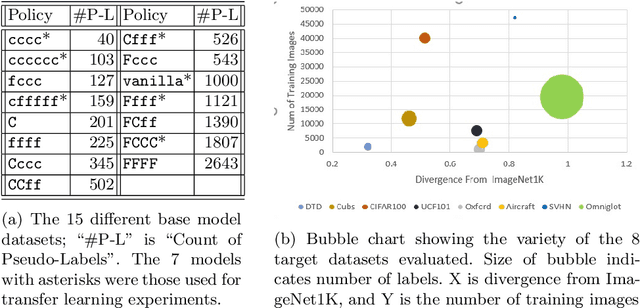
Transfer learning is a deep-learning technique that ameliorates the problem of learning when human-annotated labels are expensive and limited. In place of such labels, it uses instead the previously trained weights from a well-chosen source model as the initial weights for the training of a base model for a new target dataset. We demonstrate a novel but general technique for automatically creating such source models. We generate pseudo-labels according to an efficient and extensible algorithm that is based on a classical result from the geometry of high dimensions, the Cayley-Menger determinant. This G2L (``geometry to label'') method incrementally builds up pseudo-labels using a greedy computation of hypervolume content. We demonstrate that the method is tunable with respect to expected accuracy, which can be forecast by an information-theoretic measure of dataset similarity (divergence) between source and target. The results of 280 experiments show that this mechanical technique generates base models that have similar or better transferability compared to a baseline of models trained on extensively human-annotated ImageNet1K labels, yielding an overall error decrease of 0.43\%, and an error decrease in 4 out of 5 divergent datasets tested.
Using sequential drift detection to test the API economy
Nov 25, 2021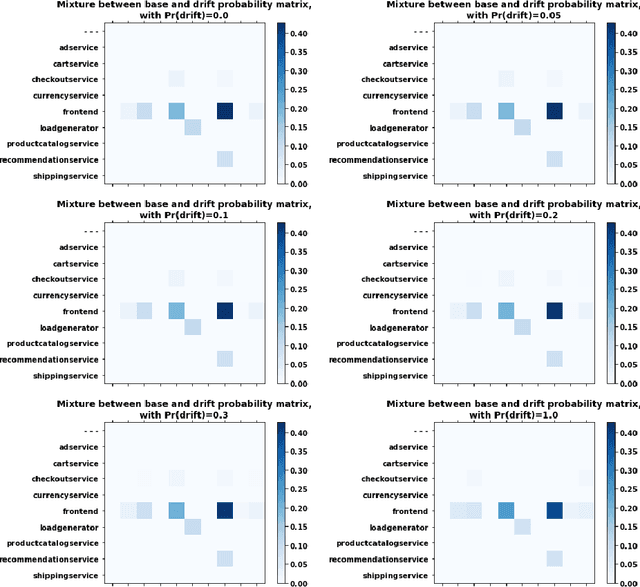
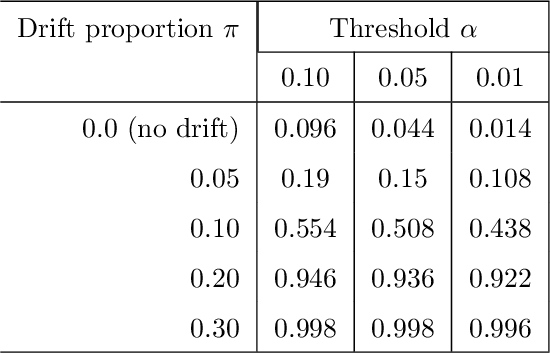
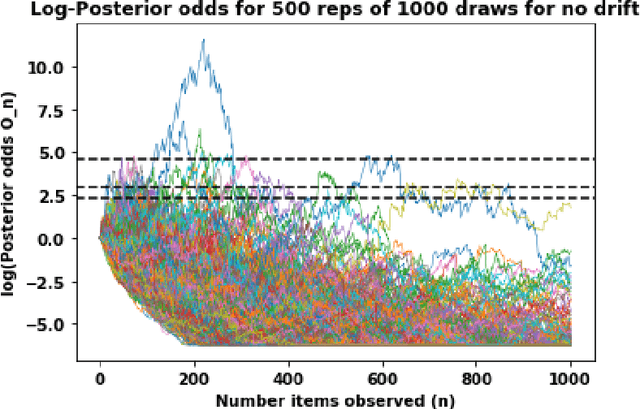
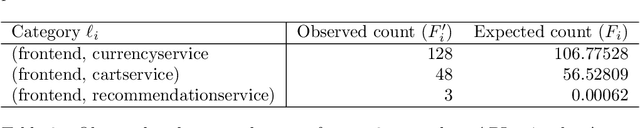
The API economy refers to the widespread integration of API (advanced programming interface) microservices, where software applications can communicate with each other, as a crucial element in business models and functions. The number of possible ways in which such a system could be used is huge. It is thus desirable to monitor the usage patterns and identify when the system is used in a way that was never used before. This provides a warning to the system analysts and they can ensure uninterrupted operation of the system. In this work we analyze both histograms and call graph of API usage to determine if the usage patterns of the system has shifted. We compare the application of nonparametric statistical and Bayesian sequential analysis to the problem. This is done in a way that overcomes the issue of repeated statistical tests and insures statistical significance of the alerts. The technique was simulated and tested and proven effective in detecting the drift in various scenarios. We also mention modifications to the technique to decrease its memory so that it can respond more quickly when the distribution drift occurs at a delay from when monitoring begins.
Machine Learning Model Drift Detection Via Weak Data Slices
Aug 11, 2021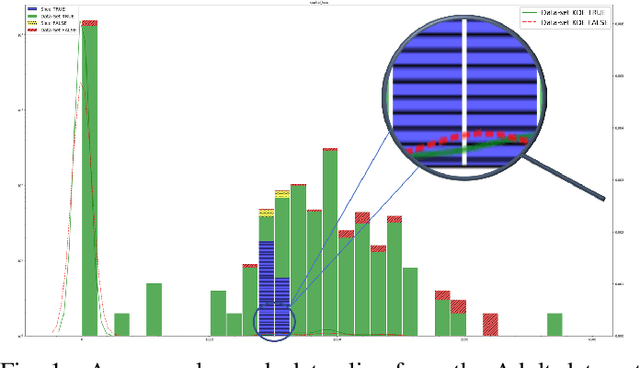
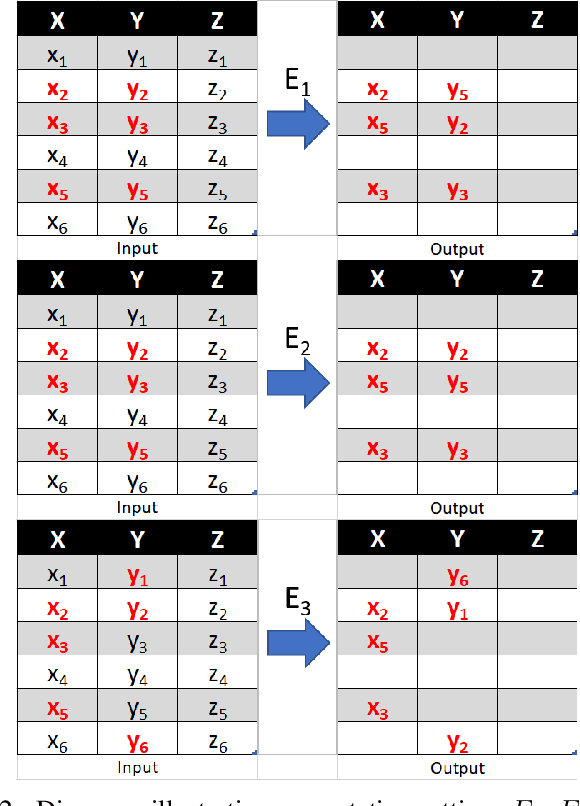
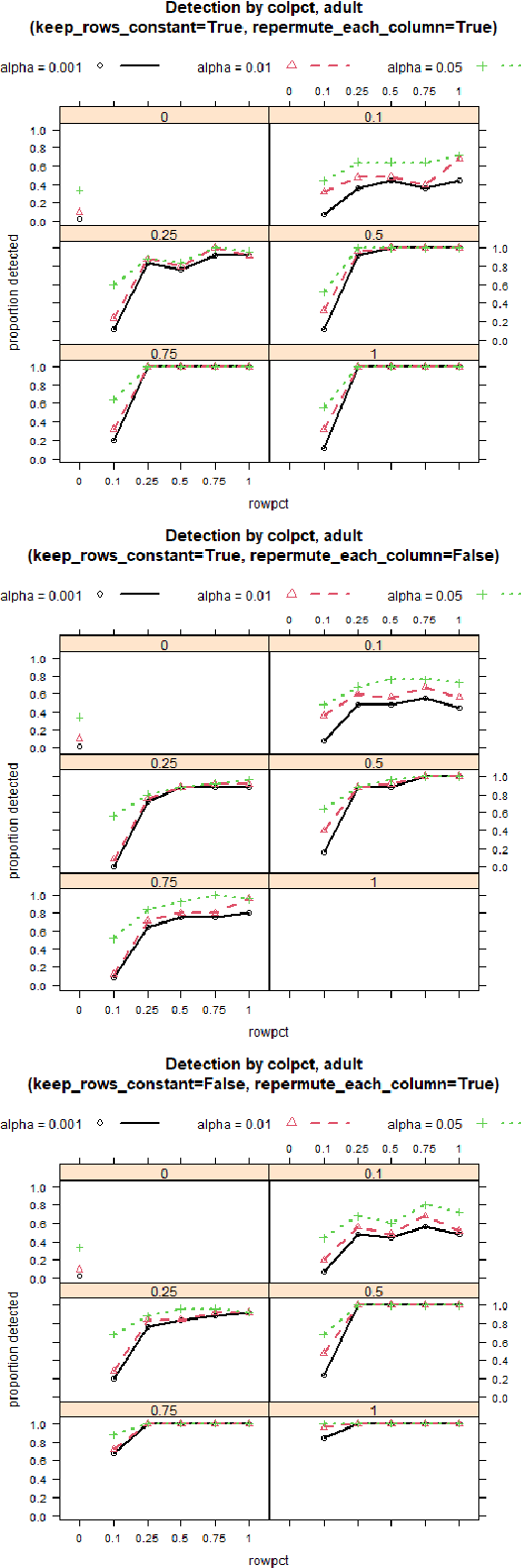
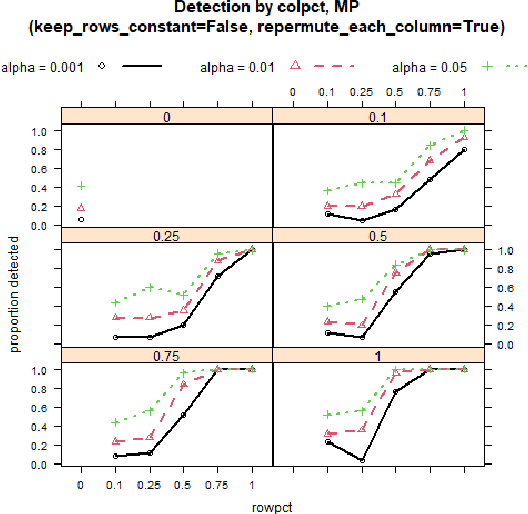
Detecting drift in performance of Machine Learning (ML) models is an acknowledged challenge. For ML models to become an integral part of business applications it is essential to detect when an ML model drifts away from acceptable operation. However, it is often the case that actual labels are difficult and expensive to get, for example, because they require expert judgment. Therefore, there is a need for methods that detect likely degradation in ML operation without labels. We propose a method that utilizes feature space rules, called data slices, for drift detection. We provide experimental indications that our method is likely to identify that the ML model will likely change in performance, based on changes in the underlying data.
Adversarial training in communication constrained federated learning
Mar 01, 2021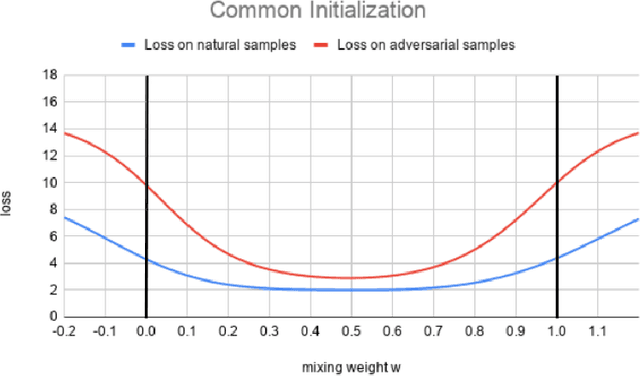
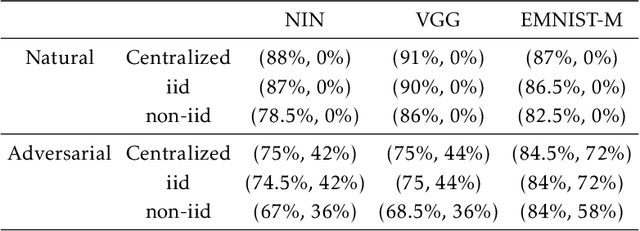
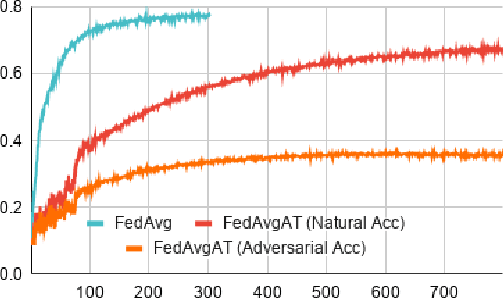
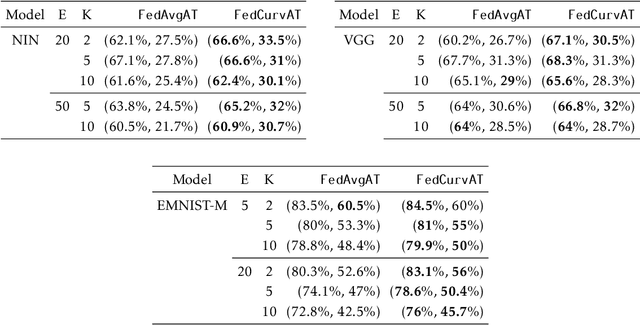
Federated learning enables model training over a distributed corpus of agent data. However, the trained model is vulnerable to adversarial examples, designed to elicit misclassification. We study the feasibility of using adversarial training (AT) in the federated learning setting. Furthermore, we do so assuming a fixed communication budget and non-iid data distribution between participating agents. We observe a significant drop in both natural and adversarial accuracies when AT is used in the federated setting as opposed to centralized training. We attribute this to the number of epochs of AT performed locally at the agents, which in turn effects (i) drift between local models; and (ii) convergence time (measured in number of communication rounds). Towards this end, we propose FedDynAT, a novel algorithm for performing AT in federated setting. Through extensive experimentation we show that FedDynAT significantly improves both natural and adversarial accuracy, as well as model convergence time by reducing the model drift.