 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Compositional Generalization with Latent Structure and Data Augmentation
Dec 14, 2021
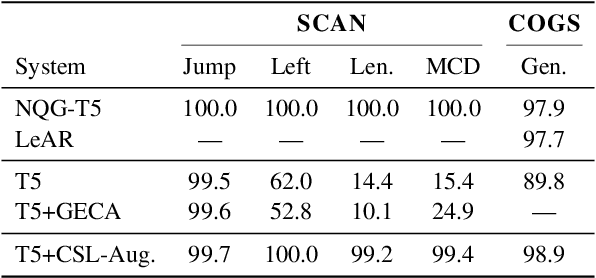
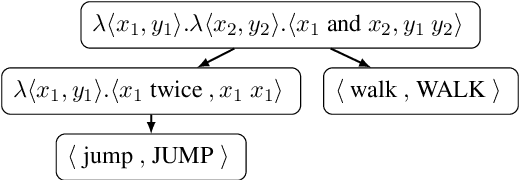
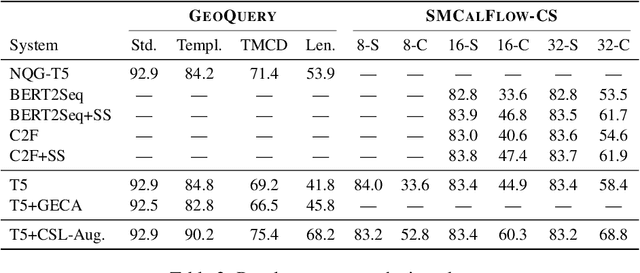
Generic unstructured neural networks have been shown to struggle on out-of-distribution compositional generalization. Compositional data augmentation via example recombination has transferred some prior knowledge about compositionality to such black-box neural models for several semantic parsing tasks, but this often required task-specific engineering or provided limited gains. We present a more powerful data recombination method using a model called Compositional Structure Learner (CSL). CSL is a generative model with a quasi-synchronous context-free grammar backbone, which we induce from the training data. We sample recombined examples from CSL and add them to the fine-tuning data of a pre-trained sequence-to-sequence model (T5). This procedure effectively transfers most of CSL's compositional bias to T5 for diagnostic tasks, and results in a model even stronger than a T5-CSL ensemble on two real world compositional generalization tasks. This results in new state-of-the-art performance for these challenging semantic parsing tasks requiring generalization to both natural language variation and novel compositions of elements.
Controllable Semantic Parsing via Retrieval Augmentation
Oct 16, 2021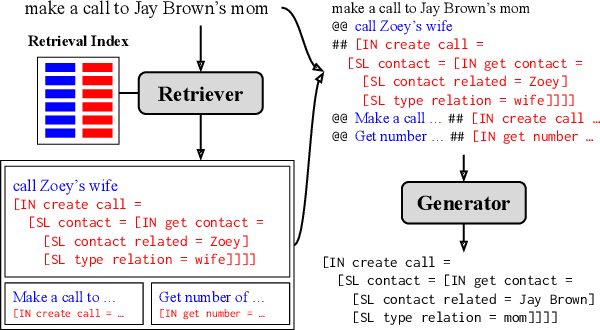
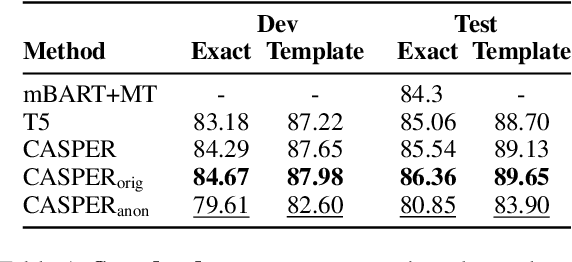

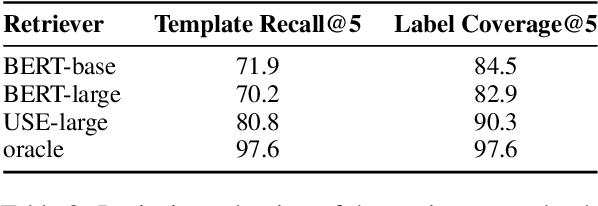
In practical applications of semantic parsing, we often want to rapidly change the behavior of the parser, such as enabling it to handle queries in a new domain, or changing its predictions on certain targeted queries. While we can introduce new training examples exhibiting the target behavior, a mechanism for enacting such behavior changes without expensive model re-training would be preferable. To this end, we propose ControllAble Semantic Parser via Exemplar Retrieval (CASPER). Given an input query, the parser retrieves related exemplars from a retrieval index, augments them to the query, and then applies a generative seq2seq model to produce an output parse. The exemplars act as a control mechanism over the generic generative model: by manipulating the retrieval index or how the augmented query is constructed, we can manipulate the behavior of the parser. On the MTOP dataset, in addition to achieving state-of-the-art on the standard setup, we show that CASPER can parse queries in a new domain, adapt the prediction toward the specified patterns, or adapt to new semantic schemas without having to further re-train the model.
Graph-Based Decoding for Task Oriented Semantic Parsing
Sep 09, 2021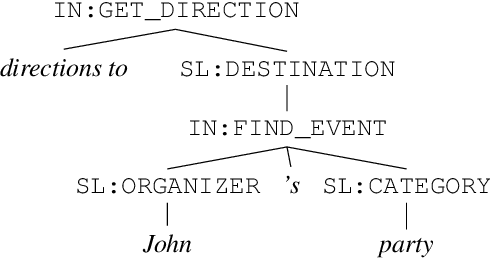
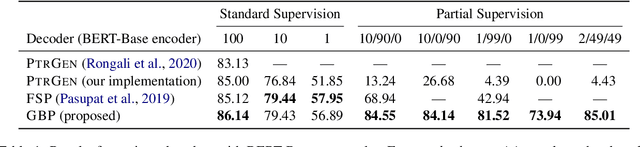

The dominant paradigm for semantic parsing in recent years is to formulate parsing as a sequence-to-sequence task, generating predictions with auto-regressive sequence decoders. In this work, we explore an alternative paradigm. We formulate semantic parsing as a dependency parsing task, applying graph-based decoding techniques developed for syntactic parsing. We compare various decoding techniques given the same pre-trained Transformer encoder on the TOP dataset, including settings where training data is limited or contains only partially-annotated examples. We find that our graph-based approach is competitive with sequence decoders on the standard setting, and offers significant improvements in data efficiency and settings where partially-annotated data is available.
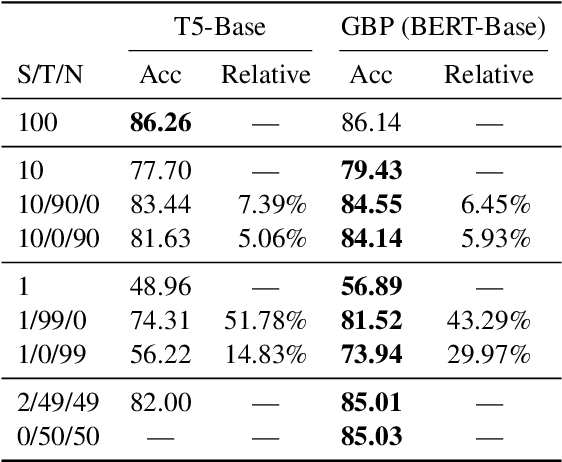
Unlocking Compositional Generalization in Pre-trained Models Using Intermediate Representations
Apr 15, 2021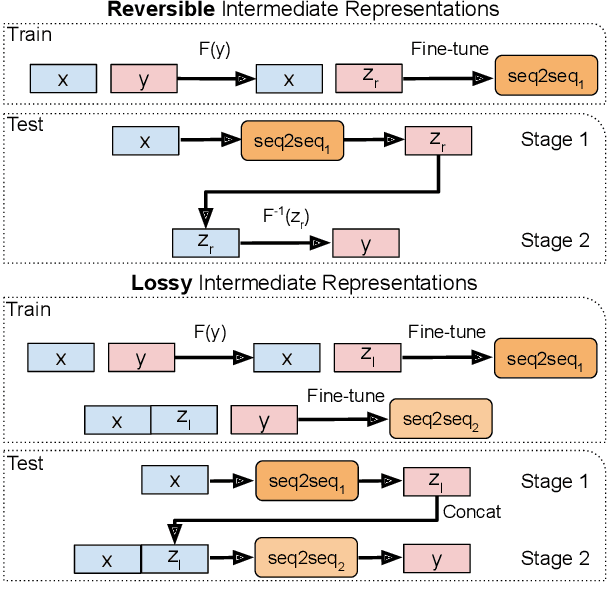
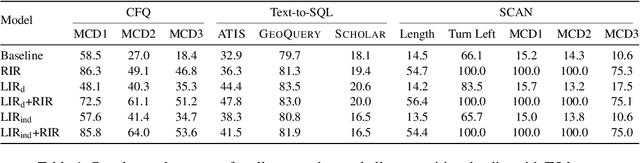
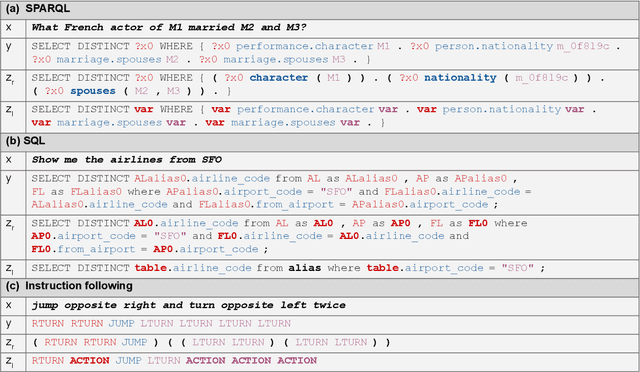
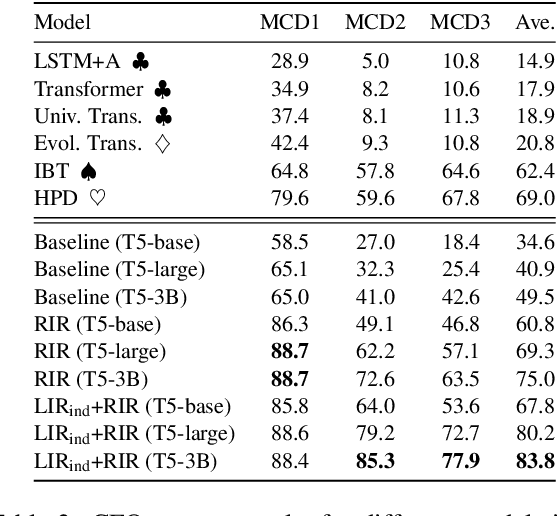
Sequence-to-sequence (seq2seq) models are prevalent in semantic parsing, but have been found to struggle at out-of-distribution compositional generalization. While specialized model architectures and pre-training of seq2seq models have been proposed to address this issue, the former often comes at the cost of generality and the latter only shows limited success. In this paper, we study the impact of intermediate representations on compositional generalization in pre-trained seq2seq models, without changing the model architecture at all, and identify key aspects for designing effective representations. Instead of training to directly map natural language to an executable form, we map to a reversible or lossy intermediate representation that has stronger structural correspondence with natural language. The combination of our proposed intermediate representations and pre-trained models is surprisingly effective, where the best combinations obtain a new state-of-the-art on CFQ (+14.8 accuracy points) and on the template-splits of three text-to-SQL datasets (+15.0 to +19.4 accuracy points). This work highlights that intermediate representations provide an important and potentially overlooked degree of freedom for improving the compositional generalization abilities of pre-trained seq2seq models.
Few-shot Intent Classification and Slot Filling with Retrieved Examples
Apr 12, 2021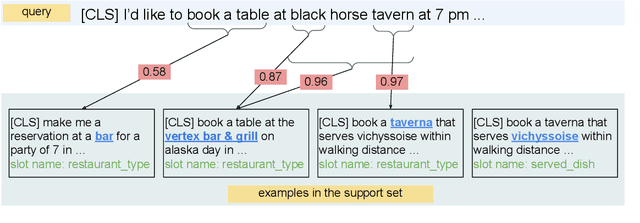
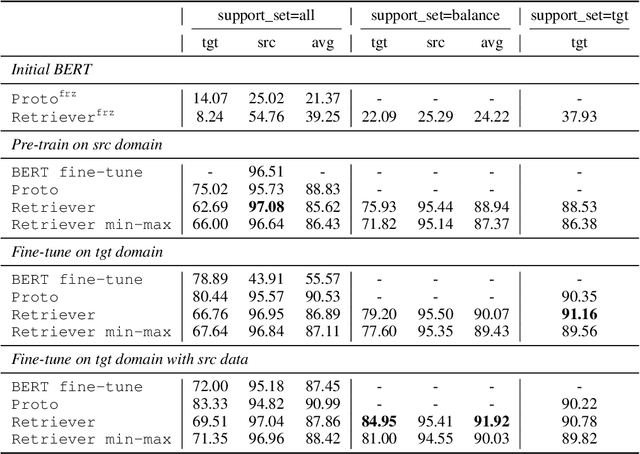
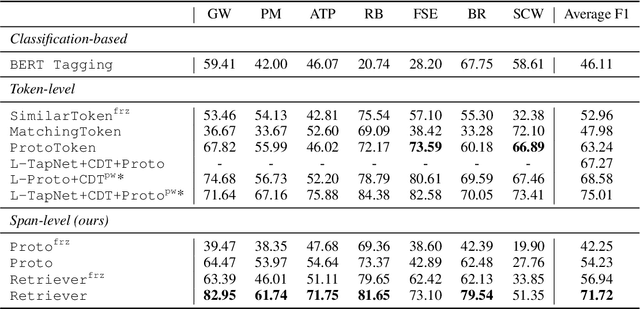

Few-shot learning arises in important practical scenarios, such as when a natural language understanding system needs to learn new semantic labels for an emerging, resource-scarce domain. In this paper, we explore retrieval-based methods for intent classification and slot filling tasks in few-shot settings. Retrieval-based methods make predictions based on labeled examples in the retrieval index that are similar to the input, and thus can adapt to new domains simply by changing the index without having to retrain the model. However, it is non-trivial to apply such methods on tasks with a complex label space like slot filling. To this end, we propose a span-level retrieval method that learns similar contextualized representations for spans with the same label via a novel batch-softmax objective. At inference time, we use the labels of the retrieved spans to construct the final structure with the highest aggregated score. Our method outperforms previous systems in various few-shot settings on the CLINC and SNIPS benchmarks.
Compositional Generalization and Natural Language Variation: Can a Semantic Parsing Approach Handle Both?
Oct 24, 2020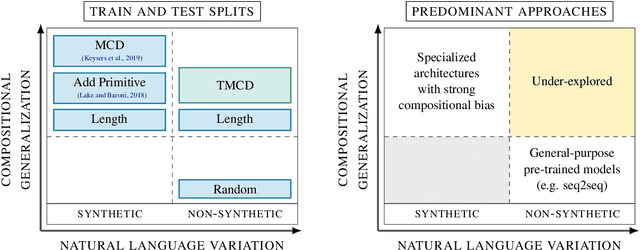

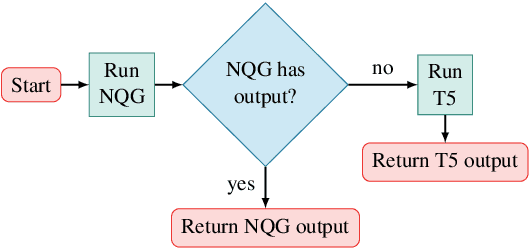
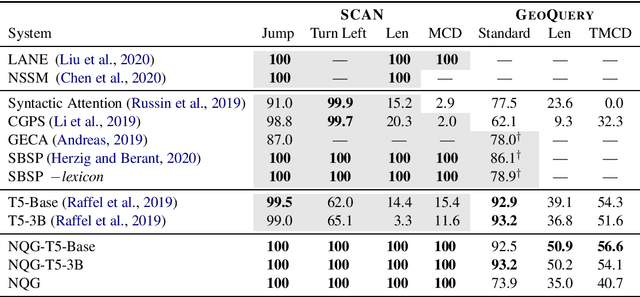
Sequence-to-sequence models excel at handling natural language variation, but have been shown to struggle with out-of-distribution compositional generalization. This has motivated new specialized architectures with stronger compositional biases, but most of these approaches have only been evaluated on synthetically-generated datasets, which are not representative of natural language variation. In this work we ask: can we develop a semantic parsing approach that handles both natural language variation and compositional generalization? To better assess this capability, we propose new train and test splits of non-synthetic datasets. We demonstrate that strong existing semantic parsing approaches do not yet perform well across a broad set of evaluations. We also propose NQG-T5, a hybrid model that combines a high-precision grammar-based approach with a pre-trained sequence-to-sequence model. It outperforms existing approaches across several compositional generalization challenges, while also being competitive with the state-of-the-art on standard evaluations. While still far from solving this problem, our study highlights the importance of diverse evaluations and the open challenge of handling both compositional generalization and natural language variation in semantic parsing.
Learning Abstract Models for Strategic Exploration and Fast Reward Transfer
Jul 12, 2020
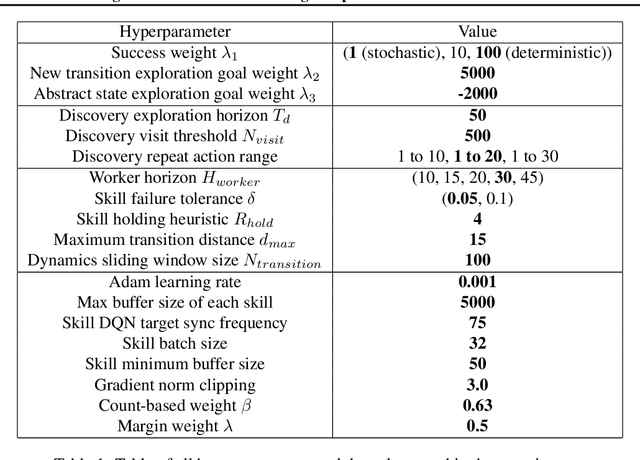
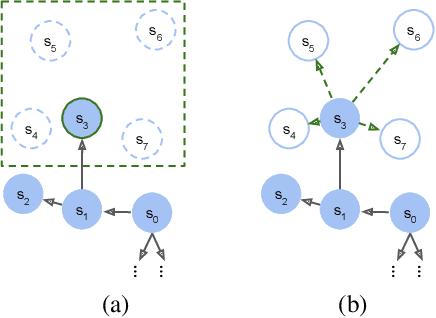

Model-based reinforcement learning (RL) is appealing because (i) it enables planning and thus more strategic exploration, and (ii) by decoupling dynamics from rewards, it enables fast transfer to new reward functions. However, learning an accurate Markov Decision Process (MDP) over high-dimensional states (e.g., raw pixels) is extremely challenging because it requires function approximation, which leads to compounding errors. Instead, to avoid compounding errors, we propose learning an abstract MDP over abstract states: low-dimensional coarse representations of the state (e.g., capturing agent position, ignoring other objects). We assume access to an abstraction function that maps the concrete states to abstract states. In our approach, we construct an abstract MDP, which grows through strategic exploration via planning. Similar to hierarchical RL approaches, the abstract actions of the abstract MDP are backed by learned subpolicies that navigate between abstract states. Our approach achieves strong results on three of the hardest Arcade Learning Environment games (Montezuma's Revenge, Pitfall!, and Private Eye), including superhuman performance on Pitfall! without demonstrations. After training on one task, we can reuse the learned abstract MDP for new reward functions, achieving higher reward in 1000x fewer samples than model-free methods trained from scratch.
REALM: Retrieval-Augmented Language Model Pre-Training
Feb 10, 2020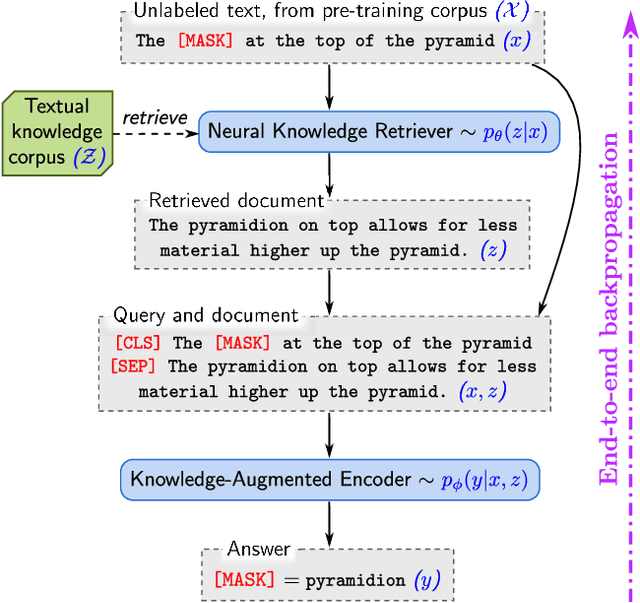
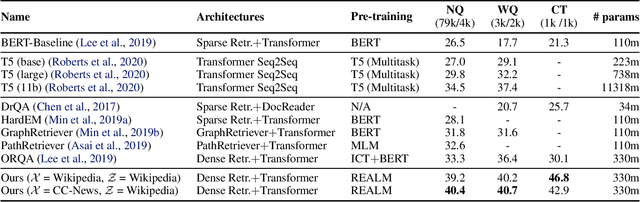

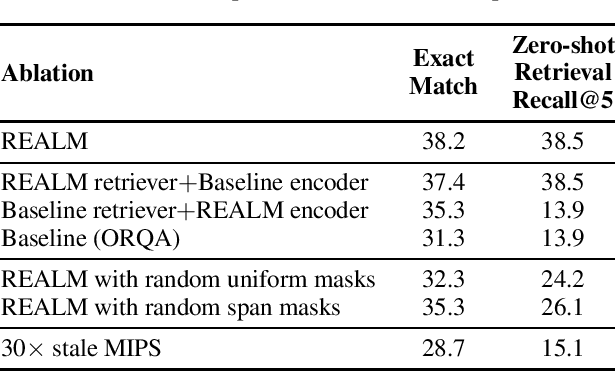
Language model pre-training has been shown to capture a surprising amount of world knowledge, crucial for NLP tasks such as question answering. However, this knowledge is stored implicitly in the parameters of a neural network, requiring ever-larger networks to cover more facts. To capture knowledge in a more modular and interpretable way, we augment language model pre-training with a latent knowledge retriever, which allows the model to retrieve and attend over documents from a large corpus such as Wikipedia, used during pre-training, fine-tuning and inference. For the first time, we show how to pre-train such a knowledge retriever in an unsupervised manner, using masked language modeling as the learning signal and backpropagating through a retrieval step that considers millions of documents. We demonstrate the effectiveness of Retrieval-Augmented Language Model pre-training (REALM) by fine-tuning on the challenging task of Open-domain Question Answering (Open-QA). We compare against state-of-the-art models for both explicit and implicit knowledge storage on three popular Open-QA benchmarks, and find that we outperform all previous methods by a significant margin (4-16% absolute accuracy), while also providing qualitative benefits such as interpretability and modularity.
SPoC: Search-based Pseudocode to Code
Jun 12, 2019
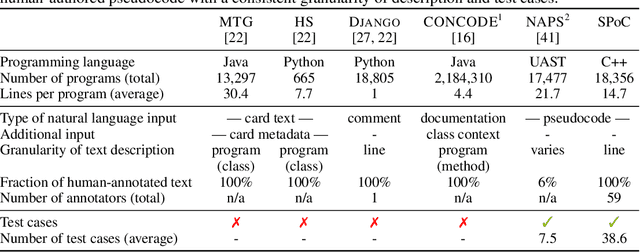
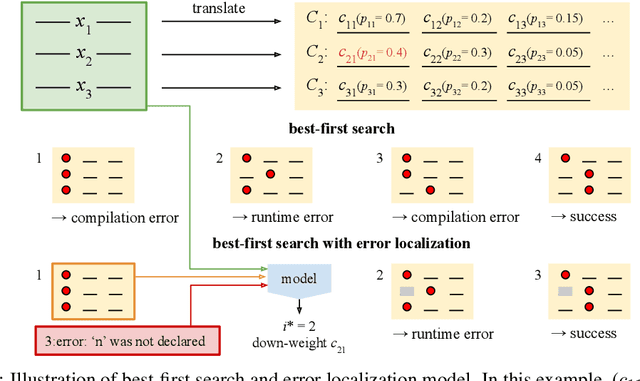
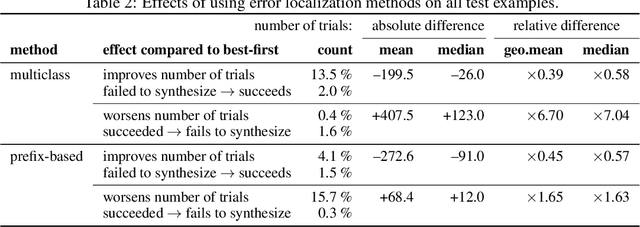
We consider the task of mapping pseudocode to long programs that are functionally correct. Given test cases as a mechanism to validate programs, we search over the space of possible translations of the pseudocode to find a program that passes the validation. However, without proper credit assignment to localize the sources of program failures, it is difficult to guide search toward more promising programs. We propose to perform credit assignment based on signals from compilation errors, which constitute 88.7% of program failures. Concretely, we treat the translation of each pseudocode line as a discrete portion of the program, and whenever a synthesized program fails to compile, an error localization method tries to identify the portion of the program responsible for the failure. We then focus search over alternative translations of the pseudocode for those portions. For evaluation, we collected the SPoC dataset (Search-based Pseudocode to Code) containing 18,356 programs with human-authored pseudocode and test cases. Under a budget of 100 program compilations, performing search improves the synthesis success rate over using the top-one translation of the pseudocode from 25.6% to 44.7%.
Improving Semantic Parsing for Task Oriented Dialog
Feb 15, 2019

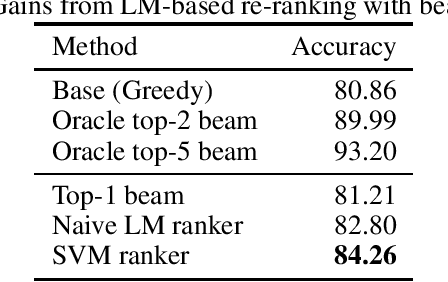
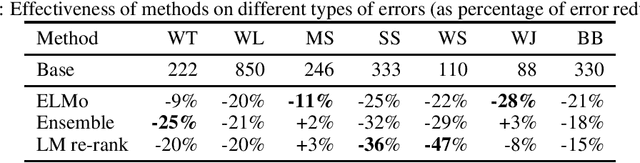
Semantic parsing using hierarchical representations has recently been proposed for task oriented dialog with promising results [Gupta et al 2018]. In this paper, we present three different improvements to the model: contextualized embeddings, ensembling, and pairwise re-ranking based on a language model. We taxonomize the errors possible for the hierarchical representation, such as wrong top intent, missing spans or split spans, and show that the three approaches correct different kinds of errors. The best model combines the three techniques and gives 6.4% better exact match accuracy than the state-of-the-art, with an error reduction of 33%, resulting in a new state-of-the-art result on the Task Oriented Parsing (TOP) dataset.