 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the limits of Concurrency in ML Training on Google TPUs
Nov 07, 2020
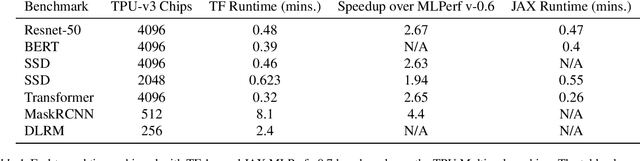
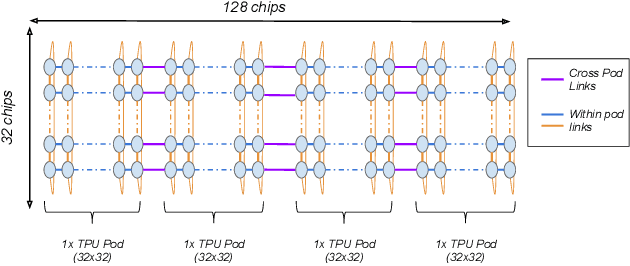
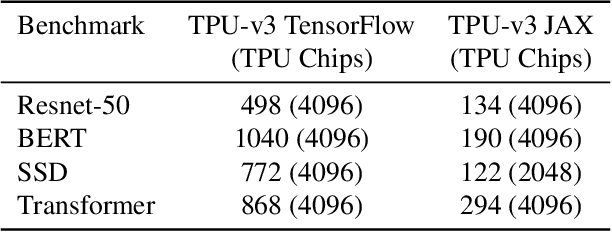
Recent results in language understanding using neural networks have required training hardware of unprecedentedscale, with thousands of chips cooperating on a single training run. This paper presents techniques to scaleML models on the Google TPU Multipod, a mesh with 4096 TPU-v3 chips. We discuss model parallelism toovercome scaling limitations from the fixed batch size in data parallelism, communication/collective optimizations,distributed evaluation of training metrics, and host input processing scaling optimizations. These techniques aredemonstrated in both the TensorFlow and JAX programming frameworks. We also present performance resultsfrom the recent Google submission to the MLPerf-v0.7 benchmark contest, achieving record training times from16 to 28 seconds in four MLPerf models on the Google TPU-v3 Multipod machine.
MLPerf Inference Benchmark
Nov 06, 2019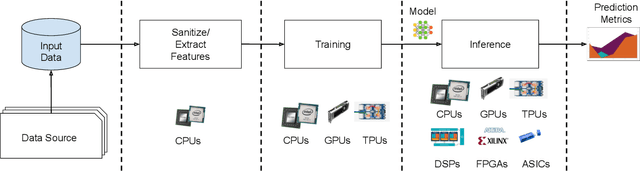
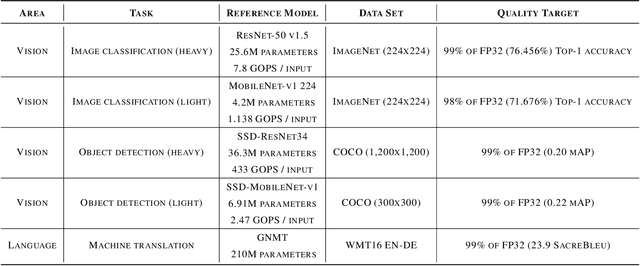
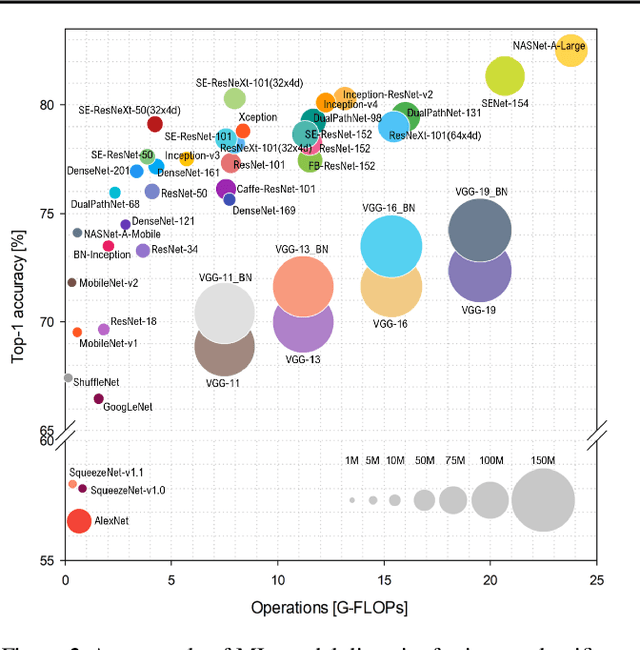
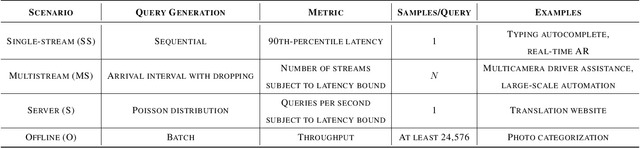
Machine-learning (ML) hardware and software system demand is burgeoning. Driven by ML applications, the number of different ML inference systems has exploded. Over 100 organizations are building ML inference chips, and the systems that incorporate existing models span at least three orders of magnitude in power consumption and four orders of magnitude in performance; they range from embedded devices to data-center solutions. Fueling the hardware are a dozen or more software frameworks and libraries. The myriad combinations of ML hardware and ML software make assessing ML-system performance in an architecture-neutral, representative, and reproducible manner challenging. There is a clear need for industry-wide standard ML benchmarking and evaluation criteria. MLPerf Inference answers that call. Driven by more than 30 organizations as well as more than 200 ML engineers and practitioners, MLPerf implements a set of rules and practices to ensure comparability across systems with wildly differing architectures. In this paper, we present the method and design principles of the initial MLPerf Inference release. The first call for submissions garnered more than 600 inference-performance measurements from 14 organizations, representing over 30 systems that show a range of capabilities.