 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Odia Braille Literacy: The Influence of Speed on Error Reduction and Enhanced Comprehension
Oct 12, 2023


This study aims to conduct an extensive detailed analysis of the Odia Braille reading comprehension among students with visual disability. Specifically, the study explores their reading speed and hand or finger movements. The study also aims to investigate any comprehension difficulties and reading errors they may encounter. Six students from the 9th and 10th grades, aged between 14 and 16, participated in the study. We observed participants hand movements to understand how reading errors were connected to hand movement and identify the students reading difficulties. We also evaluated the participants Odia Braille reading skills, including their reading speed (in words per minute), errors, and comprehension. The average speed of Odia Braille reader is 17.64wpm. According to the study, there was a noticeable correlation between reading speed and reading errors. As reading speed decreased, the number of reading errors tended to increase. Moreover, the study established a link between reduced Braille reading errors and improved reading comprehension. In contrast, the study found that better comprehension was associated with increased reading speed. The researchers concluded with some interesting findings about preferred Braille reading patterns. These findings have important theoretical, developmental, and methodological implications for instruction.
On the Evaluation of User Privacy in Deep Neural Networks using Timing Side Channel
Aug 03, 2022
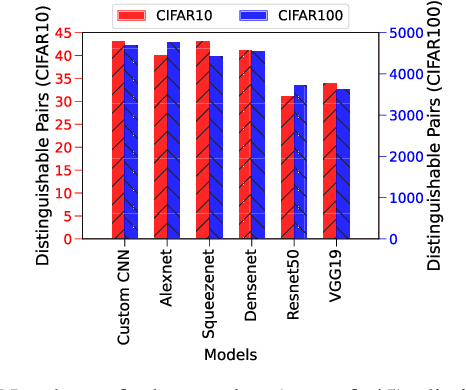
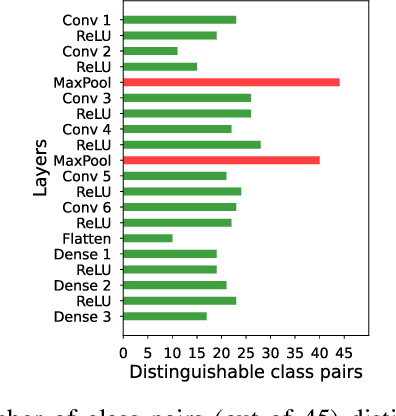

Recent Deep Learning (DL) advancements in solving complex real-world tasks have led to its widespread adoption in practical applications. However, this opportunity comes with significant underlying risks, as many of these models rely on privacy-sensitive data for training in a variety of applications, making them an overly-exposed threat surface for privacy violations. Furthermore, the widespread use of cloud-based Machine-Learning-as-a-Service (MLaaS) for its robust infrastructure support has broadened the threat surface to include a variety of remote side-channel attacks. In this paper, we first identify and report a novel data-dependent timing side-channel leakage (termed Class Leakage) in DL implementations originating from non-constant time branching operation in a widely used DL framework PyTorch. We further demonstrate a practical inference-time attack where an adversary with user privilege and hard-label black-box access to an MLaaS can exploit Class Leakage to compromise the privacy of MLaaS users. DL models are vulnerable to Membership Inference Attack (MIA), where an adversary's objective is to deduce whether any particular data has been used while training the model. In this paper, as a separate case study, we demonstrate that a DL model secured with differential privacy (a popular countermeasure against MIA) is still vulnerable to MIA against an adversary exploiting Class Leakage. We develop an easy-to-implement countermeasure by making a constant-time branching operation that alleviates the Class Leakage and also aids in mitigating MIA. We have chosen two standard benchmarking image classification datasets, CIFAR-10 and CIFAR-100 to train five state-of-the-art pre-trained DL models, over two different computing environments having Intel Xeon and Intel i7 processors to validate our approach.
Texture Aware Autoencoder Pre-training And Pairwise Learning Refinement For Improved Iris Recognition
Feb 15, 2022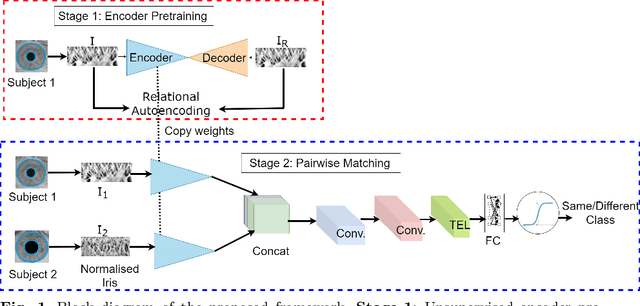
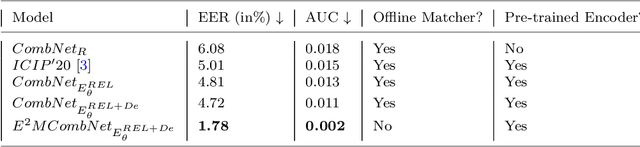
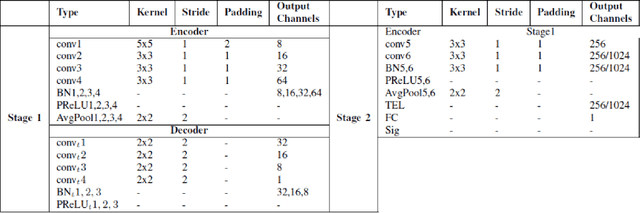
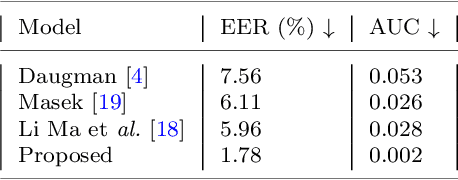
This paper presents a texture aware end-to-end trainable iris recognition system, specifically designed for datasets like iris having limited training data. We build upon our previous stagewise learning framework with certain key optimization and architectural innovations. First, we pretrain a Stage-1 encoder network with an unsupervised autoencoder learning optimized with an additional data relation loss on top of usual reconstruction loss. The data relation loss enables learning better texture representation which is pivotal for a texture rich dataset such as iris. Robustness of Stage-1 feature representation is further enhanced with an auxiliary denoising task. Such pre-training proves beneficial for effectively training deep networks on data constrained iris datasets. Next, in Stage-2 supervised refinement, we design a pairwise learning architecture for an end-to-end trainable iris recognition system. The pairwise learning includes the task of iris matching inside the training pipeline itself and results in significant improvement in recognition performance compared to usual offline matching. We validate our model across three publicly available iris datasets and the proposed model consistently outperforms both traditional and deep learning baselines for both Within-Dataset and Cross-Dataset configurations
Multilingual Audio-Visual Smartphone Dataset And Evaluation
Sep 09, 2021
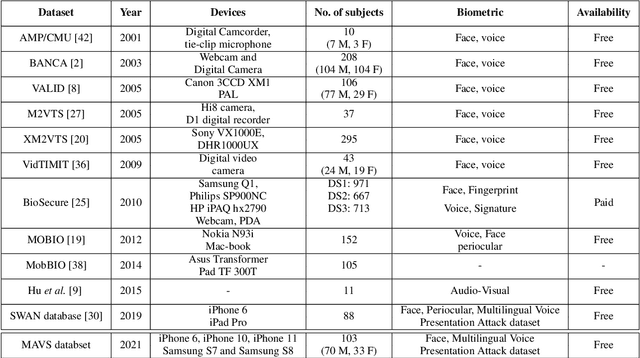


Smartphones have been employed with biometric-based verification systems to provide security in highly sensitive applications. Audio-visual biometrics are getting popular due to the usability and also it will be challenging to spoof because of multi-modal nature. In this work, we present an audio-visual smartphone dataset captured in five different recent smartphones. This new dataset contains 103 subjects captured in three different sessions considering the different real-world scenarios. Three different languages are acquired in this dataset to include the problem of language dependency of the speaker recognition systems. These unique characteristics of this dataset will pave the way to implement novel state-of-the-art unimodal or audio-visual speaker recognition systems. We also report the performance of the bench-marked biometric verification systems on our dataset. The robustness of biometric algorithms is evaluated towards multiple dependencies like signal noise, device, language and presentation attacks like replay and synthesized signals with extensive experiments. The obtained results raised many concerns about the generalization properties of state-of-the-art biometrics methods in smartphones.
Explaining Outcomes of Multi-Party Dialogues using Causal Learning
May 03, 2021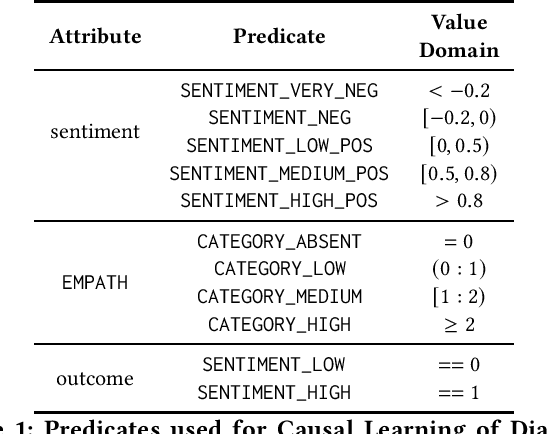


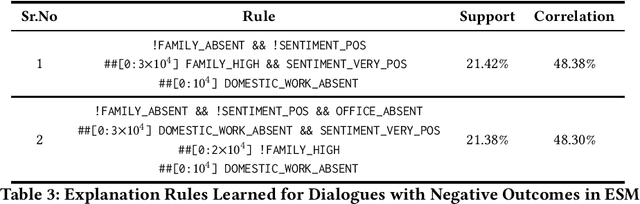
Multi-party dialogues are common in enterprise social media on technical as well as non-technical topics. The outcome of a conversation may be positive or negative. It is important to analyze why a dialogue ends with a particular sentiment from the point of view of conflict analysis as well as future collaboration design. We propose an explainable time series mining algorithm for such analysis. A dialogue is represented as an attributed time series of occurrences of keywords, EMPATH categories, and inferred sentiments at various points in its progress. A special decision tree, with decision metrics that take into account temporal relationships between dialogue events, is used for predicting the cause of the outcome sentiment. Interpretable rules mined from the classifier are used to explain the prediction. Experimental results are presented for the enterprise social media posts in a large company.
Alternating Direction Method of Multipliers for Quantization
Sep 08, 2020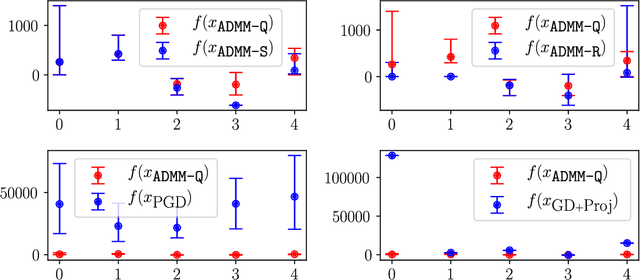

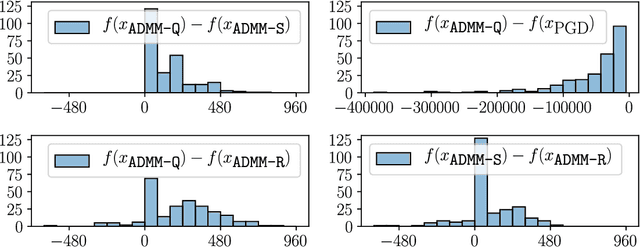

Quantization of the parameters of machine learning models, such as deep neural networks, requires solving constrained optimization problems, where the constraint set is formed by the Cartesian product of many simple discrete sets. For such optimization problems, we study the performance of the Alternating Direction Method of Multipliers for Quantization ($\texttt{ADMM-Q}$) algorithm, which is a variant of the widely-used ADMM method applied to our discrete optimization problem. We establish the convergence of the iterates of $\texttt{ADMM-Q}$ to certain $\textit{stationary points}$. To the best of our knowledge, this is the first analysis of an ADMM-type method for problems with discrete variables/constraints. Based on our theoretical insights, we develop a few variants of $\texttt{ADMM-Q}$ that can handle inexact update rules, and have improved performance via the use of "soft projection" and "injecting randomness to the algorithm". We empirically evaluate the efficacy of our proposed approaches.
Unsupervised Pre-trained, Texture Aware And Lightweight Model for Deep Learning-Based Iris Recognition Under Limited Annotated Data
Feb 20, 2020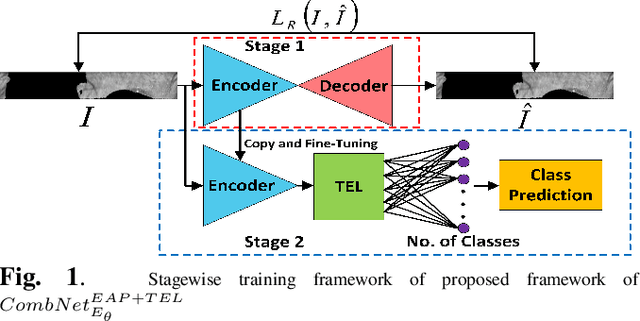
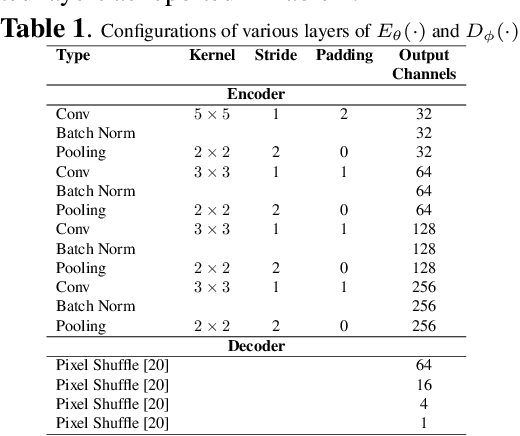

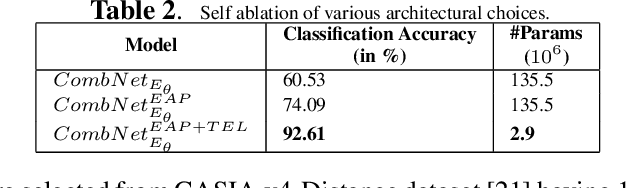
In this paper, we present a texture aware lightweight deep learning framework for iris recognition. Our contributions are primarily three fold. Firstly, to address the dearth of labelled iris data, we propose a reconstruction loss guided unsupervised pre-training stage followed by supervised refinement. This drives the network weights to focus on discriminative iris texture patterns. Next, we propose several texture aware improvisations inside a Convolution Neural Net to better leverage iris textures. Finally, we show that our systematic training and architectural choices enable us to design an efficient framework with upto 100X fewer parameters than contemporary deep learning baselines yet achieve better recognition performance for within and cross dataset evaluations.
ExTra: Transfer-guided Exploration
Jun 27, 2019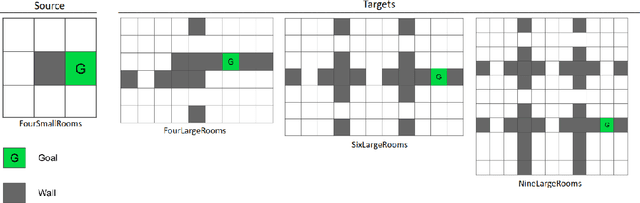
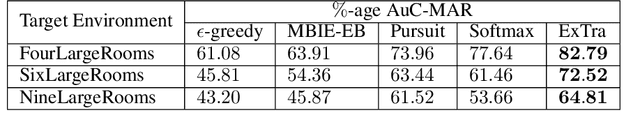
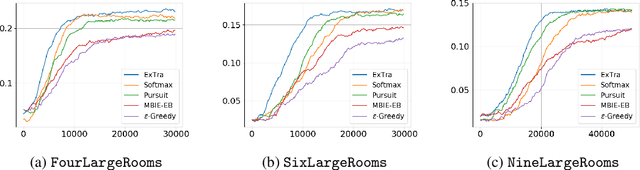

In this work we present a novel approach for transfer-guided exploration in reinforcement learning that is inspired by the human tendency to leverage experiences from similar encounters in the past while navigating a new task. Given an optimal policy in a related task-environment, we show that its bisimulation distance from the current task-environment gives a lower bound on the optimal advantage of state-action pairs in the current task-environment. Transfer-guided Exploration (ExTra) samples actions from a Softmax distribution over these lower bounds. In this way, actions with potentially higher optimum advantage are sampled more frequently. In our experiments on gridworld environments, we demonstrate that given access to an optimal policy in a related task-environment, ExTra can outperform popular domain-specific exploration strategies viz. epsilon greedy, Model-Based Interval Estimation - Exploration Based (MBIE-EB), Pursuit and Boltzmann in terms of sample complexity and rate of convergence. We further show that ExTra is robust to choices of source task and shows a graceful degradation of performance as the dissimilarity of the source task increases. We also demonstrate that ExTra, when used alongside traditional exploration algorithms, improves their rate of convergence. Thus it is capable of complimenting the efficacy of traditional exploration algorithms.
PUNCH: Positive UNlabelled Classification based information retrieval in Hyperspectral images
Apr 09, 2019
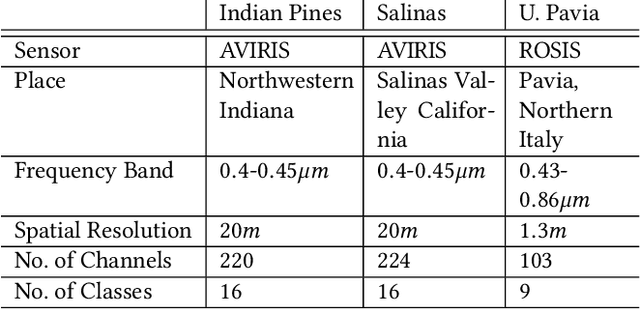
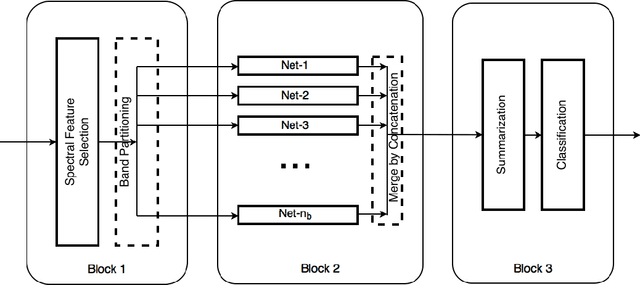

Hyperspectral images of land-cover captured by airborne or satellite-mounted sensors provide a rich source of information about the chemical composition of the materials present in a given place. This makes hyperspectral imaging an important tool for earth sciences, land-cover studies, and military and strategic applications. However, the scarcity of labeled training examples and spatial variability of spectral signature are two of the biggest challenges faced by hyperspectral image classification. In order to address these issues, we aim to develop a framework for material-agnostic information retrieval in hyperspectral images based on Positive-Unlabelled (PU) classification. Given a hyperspectral scene, the user labels some positive samples of a material he/she is looking for and our goal is to retrieve all the remaining instances of the query material in the scene. Additionally, we require the system to work equally well for any material in any scene without the user having to disclose the identity of the query material. This material-agnostic nature of the framework provides it with superior generalization abilities. We explore two alternative approaches to solve the hyperspectral image classification problem within this framework. The first approach is an adaptation of non-negative risk estimation based PU learning for hyperspectral data. The second approach is based on one-versus-all positive-negative classification where the negative class is approximately sampled using a novel spectral-spatial retrieval model. We propose two annotator models - uniform and blob - that represent the labelling patterns of a human annotator. We compare the performances of the proposed algorithms for each annotator model on three benchmark hyperspectral image datasets - Indian Pines, Pavia University and Salinas.
Segmentation of Lumen and External Elastic Laminae in Intravascular Ultrasound Images using Ultrasonic Backscattering Physics Initialized Multiscale Random Walks
Jan 21, 2019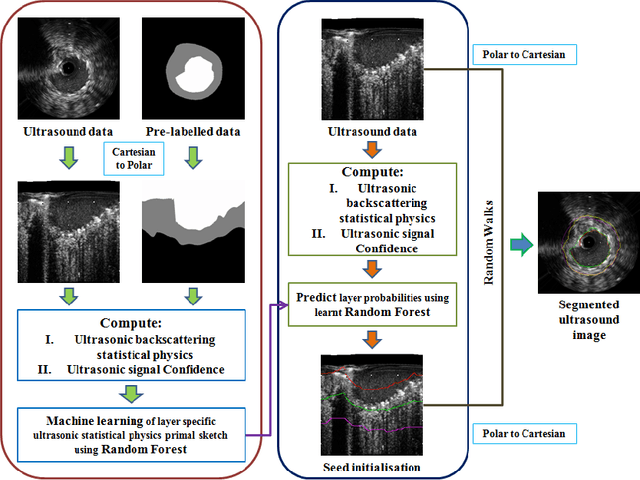
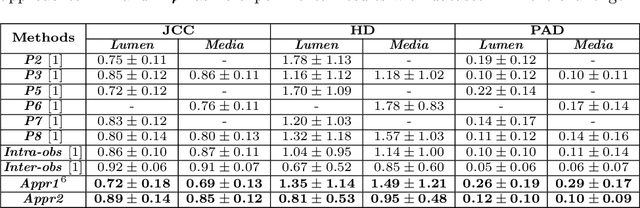
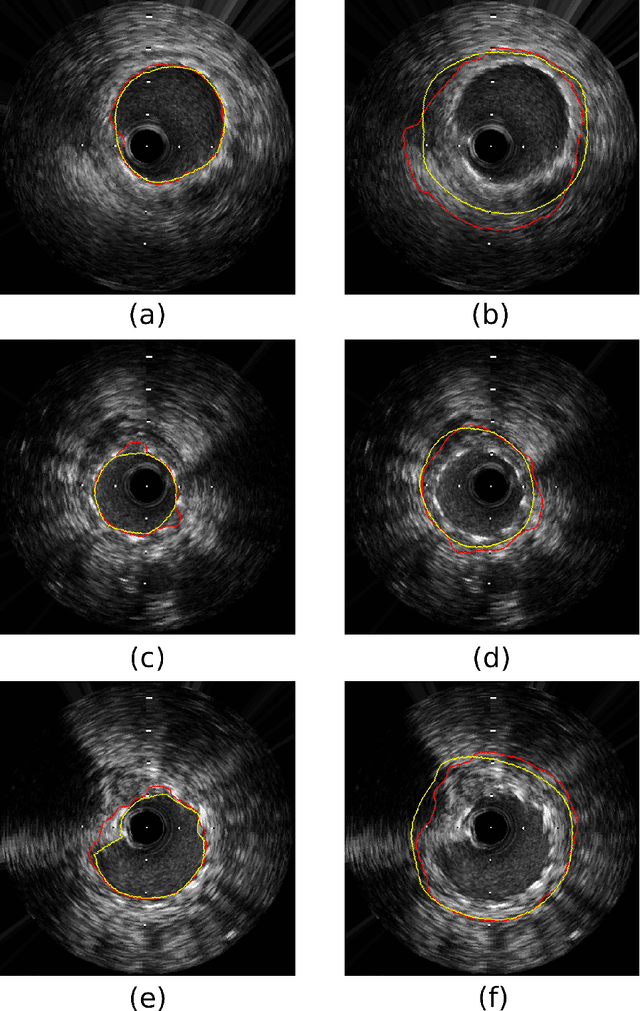
Coronary artery disease accounts for a large number of deaths across the world and clinicians generally prefer using x-ray computed tomography or magnetic resonance imaging for localizing vascular pathologies. Interventional imaging modalities like intravascular ultrasound (IVUS) are used to adjunct diagnosis of atherosclerotic plaques in vessels, and help assess morphological state of the vessel and plaque, which play a significant role for treatment planning. Since speckle intensity in IVUS images are inherently stochastic in nature and challenge clinicians with accurate visibility of the vessel wall boundaries, it requires automation. In this paper we present a method for segmenting the lumen and external elastic laminae of the artery wall in IVUS images using random walks over a multiscale pyramid of Gaussian decomposed frames. The seeds for the random walker are initialized by supervised learning of ultrasonic backscattering and attenuation statistical mechanics from labelled training samples. We have experimentally evaluated the performance using $77$ IVUS images acquired at $40$ MHz that are available in the IVUS segmentation challenge dataset\footnote{http://www.cvc.uab.es/IVUSchallenge2011/dataset.html} to obtain a Jaccard score of $0.89 \pm 0.14$ for lumen and $0.85 \pm 0.12$ for external elastic laminae segmentation over a $10$-fold cross-validation study.