 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVector Quantized Latent Concepts: A Scalable Alternative to Clustering-Based Concept Discovery
Feb 02, 2026Deep Learning models encode rich semantic information in their hidden representations. However, it remains challenging to understand which parts of this information models actually rely on when making predictions. A promising line of post-hoc concept-based explanation methods relies on clustering token representations. However, commonly used approaches such as hierarchical clustering are computationally infeasible for large-scale datasets, and K-Means often yields shallow or frequency-dominated clusters. We propose the vector quantized latent concept (VQLC) method, a framework built upon the vector quantized-variational autoencoder (VQ-VAE) architecture that learns a discrete codebook mapping continuous representations to concept vectors. We perform thorough evaluations and show that VQLC improves scalability while maintaining comparable quality of human-understandable explanations.
Enhancing Image Resolution: A Simulation Study and Sensitivity Analysis of System Parameters for Resourcesat-3S/3SA
Oct 30, 2024



Resourcesat-3S/3SA, an upcoming Indian satellite, is designed with Aft and Fore payloads capturing stereo images at look angles of -5deg and 26deg, respectively. Operating at 632.6 km altitude, it features a panchromatic (PAN) band offering a Ground Sampling Distance (GSD) of 1.25 meters and a 60 km swath. To balance swath width and resolution, an Instantaneous Geometric Field of View (IGFOV) of 2.5 meters is maintained while ensuring a 1.25-meter GSD both along and across track. Along-track sampling is achieved through precise timing, while across-track accuracy is ensured by using two staggered pixel arrays. Signal-to-Noise Ratio (SNR) is enhanced through Time Delay and Integration (TDI), employing two five-stage subarrays spaced 80 {\mu}m apart along the track, with a 4 {\mu}m (0.5 pixel) stagger in the across-track direction to achieve 1.25-meter resolution. To further boost resolution, the satellite employs super-resolution (SR), combining multiple low-resolution captures using sub-pixel shifts to produce high-resolution images. This technique, effective when images contain aliased high-frequency details, reconstructs full-resolution imagery using phase information from multiple observations, and has been successfully applied in remote sensing missions like SPOT-5, SkySat, and DubaiSat-1. A Monte Carlo simulation explores the factors influencing the resolution in Resourcesat-3S/3SA, with sensitivity analysis highlighting key impacts. The simulation methodology is broadly applicable to other remote sensing missions, optimizing SR for enhanced image clarity and resolution in future satellite systems.
Geometric Correction and Mosaic Generation of Geo High Resolution Camera Images
Oct 25, 2024



The Geo High Resolution Camera (GHRC) aboard ISRO GSAT-29 satellite is a state-of-the-art 6-band Visible and Near Infrared (VNIR) imager in geostationary orbit at 55degE longitude. It provides a ground sampling distance of 55 meters at nadir, covering 110x110 km at a time, and can image the entire Earth disk using a scan mirror mechanism. To cover India, GHRC uses a two-dimensional raster scanning technique, resulting in over 1,000 scenes that must be stitched into a seamless mosaic. This paper presents the geolocation model and examines potential sources of targeting error, with an assessment of location accuracy. Challenges in inter-band registration and inter-frame mosaicing are addressed through algorithms for geometric correction, band-to-band registration, and seamless mosaic generation. In-flight geometric calibration, including adjustments to the instrument interior alignment angles using ground reference images, has improved pointing and location accuracy. A backtracking algorithm has been developed to correct frame-to-frame mosaicing errors for large-scale mosaics, leveraging geometric models, image processing, and space resection techniques. These advancements now enable the operational generation of full India mosaics with 100-meter resolution and high geometric fidelity, enhancing the GHRC capabilities for Earth observation and monitoring applications.
Advancements in Image Resolution: Super-Resolution Algorithm for Enhanced EOS-06 OCM-3 Data
Oct 24, 2024The Ocean Color Monitor-3 (OCM-3) sensor is instrumental in Earth observation, achieving a critical balance between high-resolution imaging and broad coverage. This paper explores innovative imaging methods employed in OCM-3 and the transformative potential of super-resolution techniques to enhance image quality. The super-resolution model for OCM-3 (SOCM-3) addresses the challenges of contemporary satellite imaging by effectively navigating the trade-off between image clarity and swath width. With resolutions below 240 meters in Local Area Coverage (LAC) mode and below 750 meters in Global Area Coverage (GAC) mode, coupled with a wide 1550-kilometer swath and a 2-day revisit time, SOCM-3 emerges as a leading asset in remote sensing. The paper details the intricate interplay of atmospheric, motion, optical, and detector effects that impact image quality, emphasizing the necessity for advanced computational techniques and sophisticated algorithms for effective image reconstruction. Evaluation methods are thoroughly discussed, incorporating visual assessments using the Blind/Referenceless Image Spatial Quality Evaluator (BRISQUE) metric and computational metrics such as Line Spread Function (LSF), Full Width at Half Maximum (FWHM), and Super-Resolution (SR) ratio. Additionally, statistical analyses, including power spectrum evaluations and target-wise spectral signatures, are employed to gauge the efficacy of super-resolution techniques. By enhancing both spatial resolution and revisit frequency, this study highlights significant advancements in remote sensing capabilities, providing valuable insights for applications across cryospheric, vegetation, oceanic, coastal, and domains. Ultimately, the findings underscore the potential of SOCM-3 to contribute meaningfully to our understanding of finescale oceanic phenomena and environmental monitoring.
Hyperspectral Spatial Super-Resolution using Keystone Error
Oct 24, 2024



Hyperspectral images enable precise identification of ground objects by capturing their spectral signatures with fine spectral resolution.While high spatial resolution further enhances this capability, increasing spatial resolution through hardware like larger telescopes is costly and inefficient. A more optimal solution is using ground processing techniques, such as hypersharpening, to merge high spectral and spatial resolution data. However, this method works best when datasets are captured under similar conditions, which is difficult when using data from different times. In this work, we propose a superresolution approach to enhance hyperspectral data's spatial resolution without auxiliary input. Our method estimates the high-resolution point spread function (PSF) using blind deconvolution and corrects for sampling-related blur using a model-based superresolution framework. This differs from previous approaches by not assuming a known highresolution blur. We also introduce an adaptive prior that improves performance compared to existing methods. Applied to the visible and near-infrared (VNIR) spectrometer of HySIS, ISRO hyperspectral sensor, our algorithm removes aliasing and boosts resolution by approximately 1.3 times. It is versatile and can be applied to similar systems.
Data Processing Chain and Products of EOS-06 OCM-3 Payload From Signal Processing to Geometric Precision
Oct 22, 2024The Ocean Color Monitor-3, launched aboard Oceansat-3, represents a significant advancement in ocean observation technology, building upon the capabilities of its predecessors. With thirteen spectral bands, OCM-3 enhances feature identification and atmospheric correction, enabling precise data collection from a sun-synchronous orbit. With thirteen spectral bands, OCM-3 enhances feature identification and atmospheric correction, enabling precise data collection from a sunsynchronous orbit. Operating at an altitude of 732.5 km, the satellite achieves high signal-to-noise ratios (SNR) through sophisticated onboard and ground processing techniques, including advanced geometric modeling for pixel registration.The OCM-3 processing pipeline, consisting of multiple levels, ensures rigorous calibration and correction of radiometric and geometric data. This paper presents key methodologies such as dark data modeling, photo response non-uniformity correction, and smear correction, are employed to enhance data quality. The effective implementation of ground time delay integration (TDI) allows for the refinement of SNR, with evaluations demonstrating that performance specifications were exceeded. Geometric calibration procedures, including band-to-band registration and geolocation accuracy assessments, which further optimize data reliability are presented in the paper. Advanced image registration techniques leveraging Ground Control Points (GCPs) and residual error analysis significantly reduce geolocation errors, achieving precision within specified thresholds. Overall, OCM-3 comprehensive calibration and processing strategies ensure high-quality, reliable data crucial for ocean monitoring and change detection applications, facilitating improved understanding of ocean dynamics and environmental changes.
Data-Driven Compression of Convolutional Neural Networks
Nov 28, 2019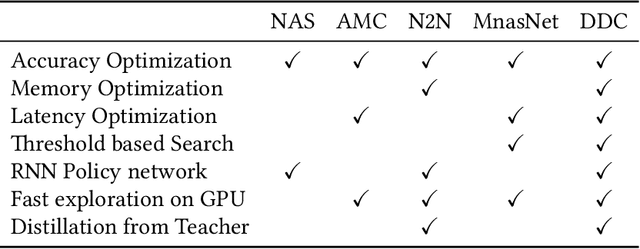
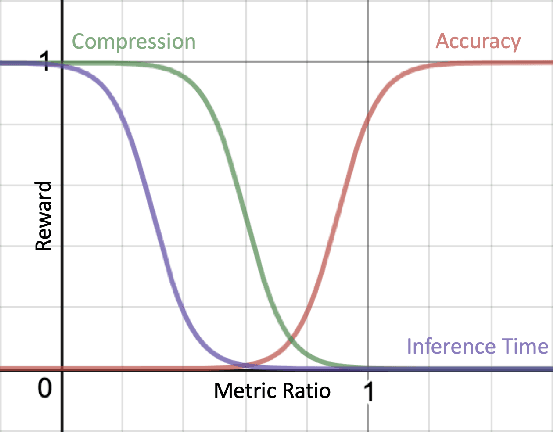
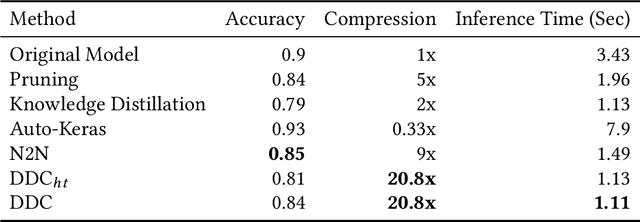
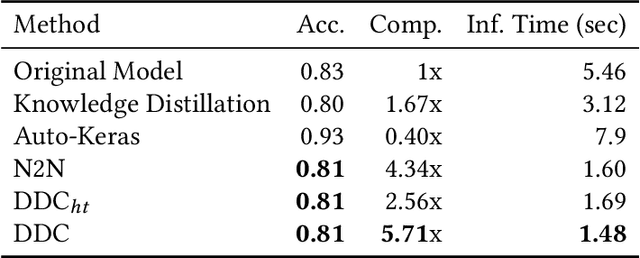
Deploying trained convolutional neural networks (CNNs) to mobile devices is a challenging task because of the simultaneous requirements of the deployed model to be fast, lightweight and accurate. Designing and training a CNN architecture that does well on all three metrics is highly non-trivial and can be very time-consuming if done by hand. One way to solve this problem is to compress the trained CNN models before deploying to mobile devices. This work asks and answers three questions on compressing CNN models automatically: a) How to control the trade-off between speed, memory and accuracy during model compression? b) In practice, a deployed model may not see all classes and/or may not need to produce all class labels. Can this fact be used to improve the trade-off? c) How to scale the compression algorithm to execute within a reasonable amount of time for many deployments? The paper demonstrates that a model compression algorithm utilizing reinforcement learning with architecture search and knowledge distillation can answer these questions in the affirmative. Experimental results are provided for current state-of-the-art CNN model families for image feature extraction like VGG and ResNet with CIFAR datasets.
DeepSWIR: A Deep Learning Based Approach for the Synthesis of Short-Wave InfraRed Band using Multi-Sensor Concurrent Datasets
May 07, 2019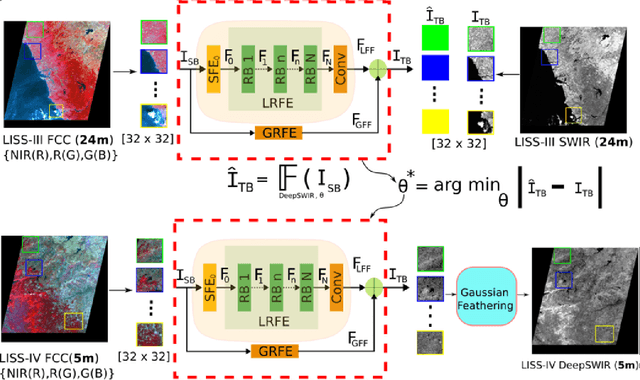
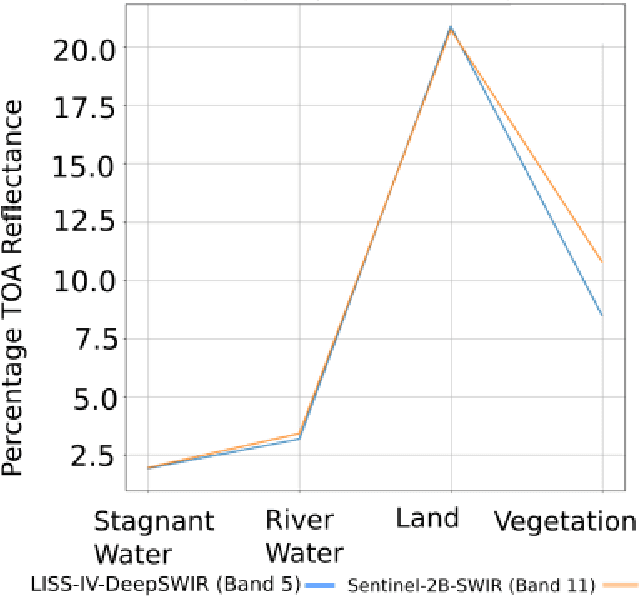


Convolutional Neural Network (CNN) is achieving remarkable progress in various computer vision tasks. In the past few years, the remote sensing community has observed Deep Neural Network (DNN) finally taking off in several challenging fields. In this study, we propose a DNN to generate a predefined High Resolution (HR) synthetic spectral band using an ensemble of concurrent Low Resolution (LR) bands and existing HR bands. Of particular interest, the proposed network, namely DeepSWIR, synthesizes Short-Wave InfraRed (SWIR) band at 5m Ground Sampling Distance (GSD) using Green (G), Red (R) and Near InfraRed (NIR) bands at both 24m and 5m GSD, and SWIR band at 24m GSD. To our knowledge, the highest spatial resolution of commercially deliverable SWIR band is at 7.5m GSD. Also, we propose a Gaussian feathering based image stitching approach in light of processing large satellite imagery. To experimentally validate the synthesized HR SWIR band, we critically analyse the qualitative and quantitative results produced by DeepSWIR using state-of-the-art evaluation metrics. Further, we convert the synthesized DN values to Top Of Atmosphere (TOA) reflectance and compare with the corresponding band of Sentinel-2B. Finally, we show one real world application of the synthesized band by using it to map wetland resources over our region of interest.
PUNCH: Positive UNlabelled Classification based information retrieval in Hyperspectral images
Apr 09, 2019
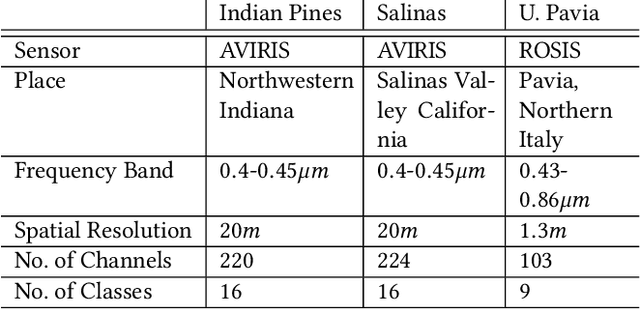

Hyperspectral images of land-cover captured by airborne or satellite-mounted sensors provide a rich source of information about the chemical composition of the materials present in a given place. This makes hyperspectral imaging an important tool for earth sciences, land-cover studies, and military and strategic applications. However, the scarcity of labeled training examples and spatial variability of spectral signature are two of the biggest challenges faced by hyperspectral image classification. In order to address these issues, we aim to develop a framework for material-agnostic information retrieval in hyperspectral images based on Positive-Unlabelled (PU) classification. Given a hyperspectral scene, the user labels some positive samples of a material he/she is looking for and our goal is to retrieve all the remaining instances of the query material in the scene. Additionally, we require the system to work equally well for any material in any scene without the user having to disclose the identity of the query material. This material-agnostic nature of the framework provides it with superior generalization abilities. We explore two alternative approaches to solve the hyperspectral image classification problem within this framework. The first approach is an adaptation of non-negative risk estimation based PU learning for hyperspectral data. The second approach is based on one-versus-all positive-negative classification where the negative class is approximately sampled using a novel spectral-spatial retrieval model. We propose two annotator models - uniform and blob - that represent the labelling patterns of a human annotator. We compare the performances of the proposed algorithms for each annotator model on three benchmark hyperspectral image datasets - Indian Pines, Pavia University and Salinas.
BASS Net: Band-Adaptive Spectral-Spatial Feature Learning Neural Network for Hyperspectral Image Classification
Dec 02, 2016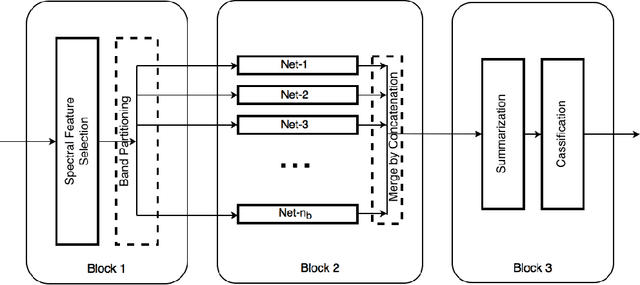
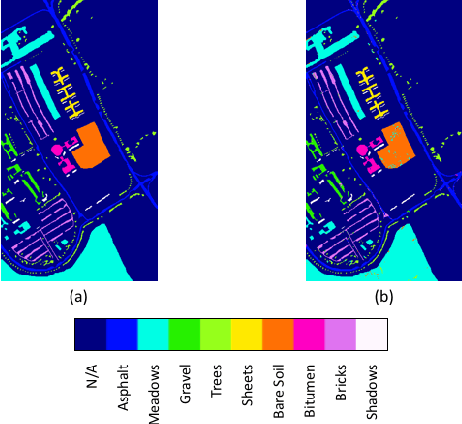
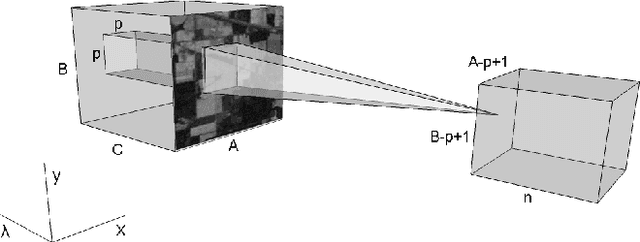
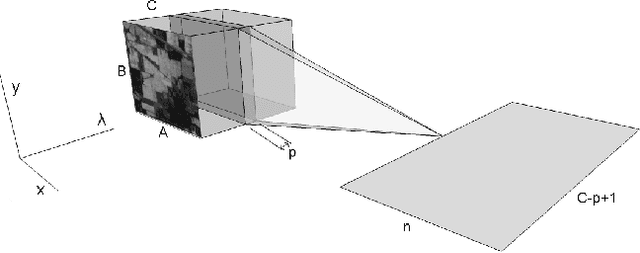
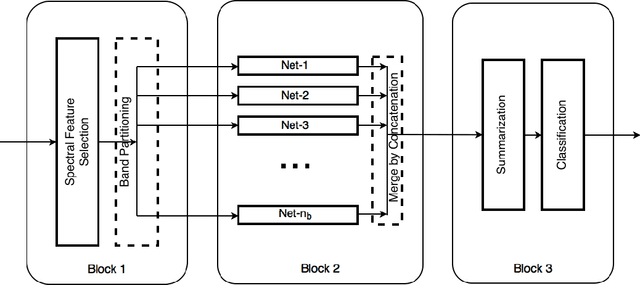
Deep learning based landcover classification algorithms have recently been proposed in literature. In hyperspectral images (HSI) they face the challenges of large dimensionality, spatial variability of spectral signatures and scarcity of labeled data. In this article we propose an end-to-end deep learning architecture that extracts band specific spectral-spatial features and performs landcover classification. The architecture has fewer independent connection weights and thus requires lesser number of training data. The method is found to outperform the highest reported accuracies on popular hyperspectral image data sets.