 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Video Classification Using Fewer Frames
Feb 27, 2019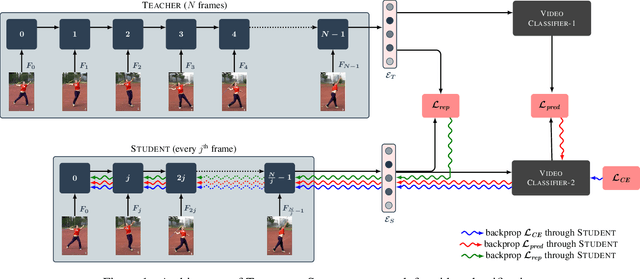
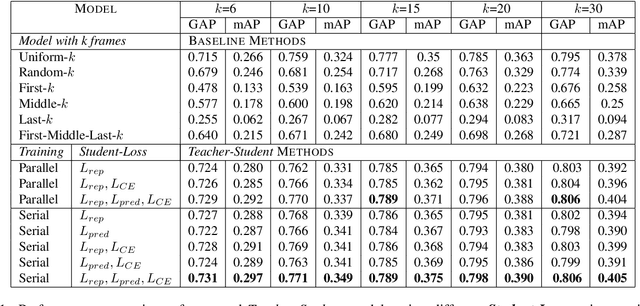
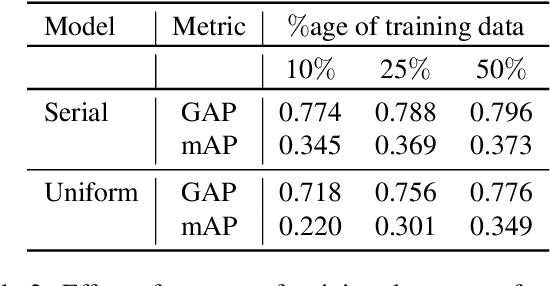
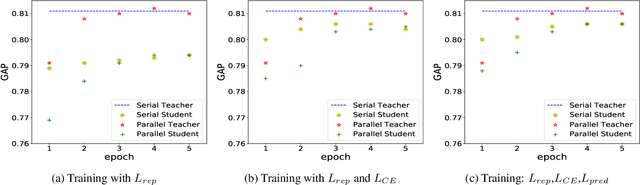
Recently,there has been a lot of interest in building compact models for video classification which have a small memory footprint (<1 GB). While these models are compact, they typically operate by repeated application of a small weight matrix to all the frames in a video. E.g. recurrent neural network based methods compute a hidden state for every frame of the video using a recurrent weight matrix. Similarly, cluster-and-aggregate based methods such as NetVLAD, have a learnable clustering matrix which is used to assign soft-clusters to every frame in the video. Since these models look at every frame in the video, the number of floating point operations (FLOPs) is still large even though the memory footprint is small. We focus on building compute-efficient video classification models which process fewer frames and hence have less number of FLOPs. Similar to memory efficient models, we use the idea of distillation albeit in a different setting. Specifically, in our case, a compute-heavy teacher which looks at all the frames in the video is used to train a compute-efficient student which looks at only a small fraction of frames in the video. This is in contrast to a typical memory efficient Teacher-Student setting, wherein both the teacher and the student look at all the frames in the video but the student has fewer parameters. Our work thus complements the research on memory efficient video classification. We do an extensive evaluation with three types of models for video classification,viz.(i) recurrent models (ii) cluster-and-aggregate models and (iii) memory-efficient cluster-and-aggregate models and show that in each of these cases, a see-it-all teacher can be used to train a compute efficient see-very-little student. We show that the proposed student network can reduce the inference time by 30% and the number of FLOPs by approximately 90% with a negligible drop in the performance.
Re-evaluating ADEM: A Deeper Look at Scoring Dialogue Responses
Feb 23, 2019
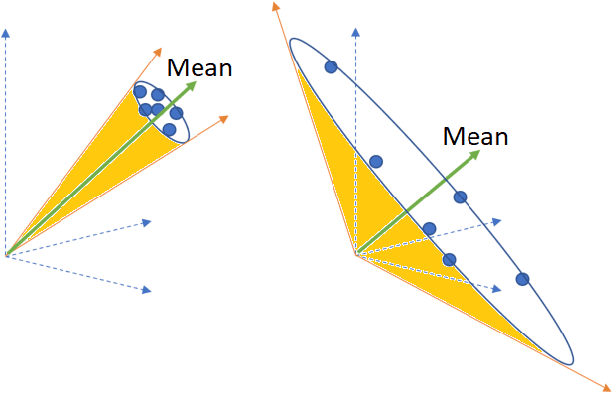

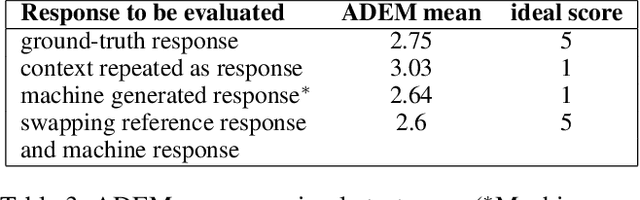
Automatically evaluating the quality of dialogue responses for unstructured domains is a challenging problem. ADEM(Lowe et al. 2017) formulated the automatic evaluation of dialogue systems as a learning problem and showed that such a model was able to predict responses which correlate significantly with human judgements, both at utterance and system level. Their system was shown to have beaten word-overlap metrics such as BLEU with large margins. We start with the question of whether an adversary can game the ADEM model. We design a battery of targeted attacks at the neural network based ADEM evaluation system and show that automatic evaluation of dialogue systems still has a long way to go. ADEM can get confused with a variation as simple as reversing the word order in the text! We report experiments on several such adversarial scenarios that draw out counterintuitive scores on the dialogue responses. We take a systematic look at the scoring function proposed by ADEM and connect it to linear system theory to predict the shortcomings evident in the system. We also devise an attack that can fool such a system to rate a response generation system as favorable. Finally, we allude to future research directions of using the adversarial attacks to design a truly automated dialogue evaluation system.
UltraCompression: Framework for High Density Compression of Ultrasound Volumes using Physics Modeling Deep Neural Networks
Jan 17, 2019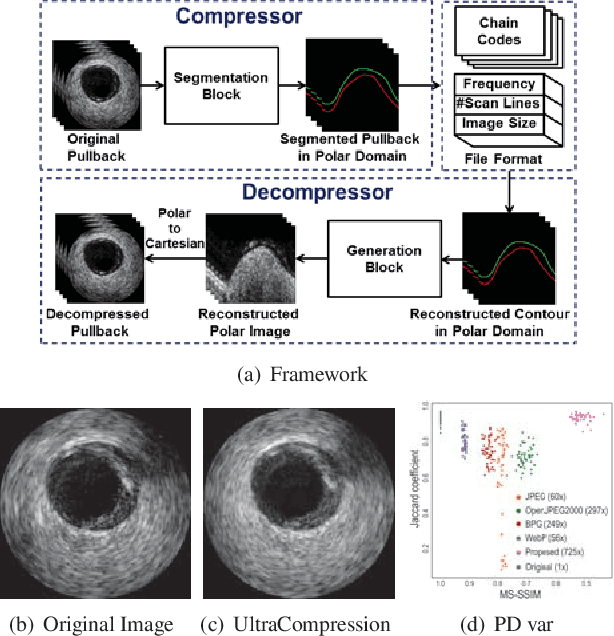
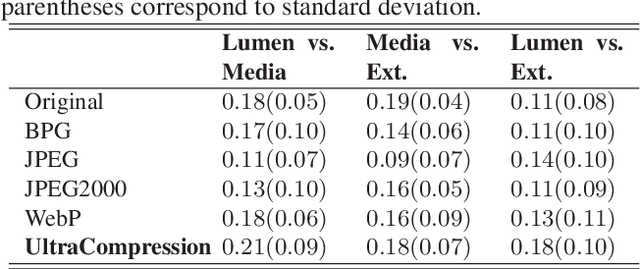
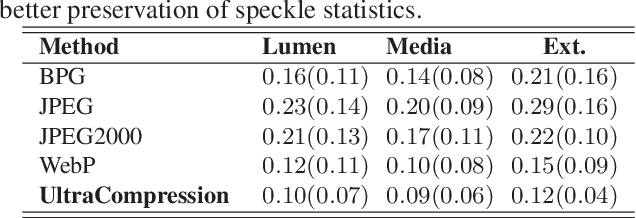

Ultrasound image compression by preserving speckle-based key information is a challenging task. In this paper, we introduce an ultrasound image compression framework with the ability to retain realism of speckle appearance despite achieving very high-density compression factors. The compressor employs a tissue segmentation method, transmitting segments along with transducer frequency, number of samples and image size as essential information required for decompression. The decompressor is based on a convolutional network trained to generate patho-realistic ultrasound images which convey essential information pertinent to tissue pathology visible in the images. We demonstrate generalizability of the building blocks using two variants to build the compressor. We have evaluated the quality of decompressed images using distortion losses as well as perception loss and compared it with other off the shelf solutions. The proposed method achieves a compression ratio of $725:1$ while preserving the statistical distribution of speckles. This enables image segmentation on decompressed images to achieve dice score of $0.89 \pm 0.11$, which evidently is not so accurately achievable when images are compressed with current standards like JPEG, JPEG 2000, WebP and BPG. We envision this frame work to serve as a roadmap for speckle image compression standards.