 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning Training on a Real Processing-in-Memory System
Jun 13, 2022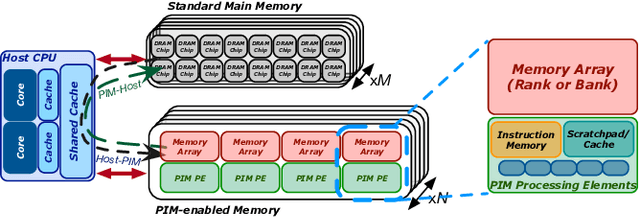
Training machine learning algorithms is a computationally intensive process, which is frequently memory-bound due to repeatedly accessing large training datasets. As a result, processor-centric systems (e.g., CPU, GPU) suffer from costly data movement between memory units and processing units, which consumes large amounts of energy and execution cycles. Memory-centric computing systems, i.e., computing systems with processing-in-memory (PIM) capabilities, can alleviate this data movement bottleneck. Our goal is to understand the potential of modern general-purpose PIM architectures to accelerate machine learning training. To do so, we (1) implement several representative classic machine learning algorithms (namely, linear regression, logistic regression, decision tree, K-means clustering) on a real-world general-purpose PIM architecture, (2) characterize them in terms of accuracy, performance and scaling, and (3) compare to their counterpart implementations on CPU and GPU. Our experimental evaluation on a memory-centric computing system with more than 2500 PIM cores shows that general-purpose PIM architectures can greatly accelerate memory-bound machine learning workloads, when the necessary operations and datatypes are natively supported by PIM hardware. To our knowledge, our work is the first one to evaluate training of machine learning algorithms on a real-world general-purpose PIM architecture.
Heterogeneous Data-Centric Architectures for Modern Data-Intensive Applications: Case Studies in Machine Learning and Databases
May 29, 2022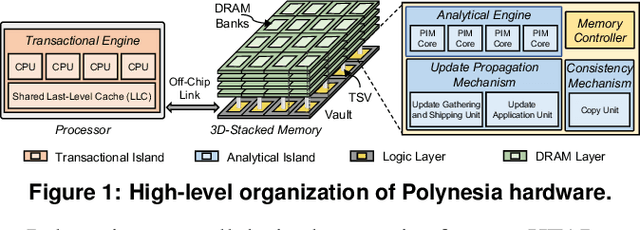
Today's computing systems require moving data back-and-forth between computing resources (e.g., CPUs, GPUs, accelerators) and off-chip main memory so that computation can take place on the data. Unfortunately, this data movement is a major bottleneck for system performance and energy consumption. One promising execution paradigm that alleviates the data movement bottleneck in modern and emerging applications is processing-in-memory (PIM), where the cost of data movement to/from main memory is reduced by placing computation capabilities close to memory. Naively employing PIM to accelerate data-intensive workloads can lead to sub-optimal performance due to the many design constraints PIM substrates impose. Therefore, many recent works co-design specialized PIM accelerators and algorithms to improve performance and reduce the energy consumption of (i) applications from various application domains; and (ii) various computing environments, including cloud systems, mobile systems, and edge devices. We showcase the benefits of co-designing algorithms and hardware in a way that efficiently takes advantage of the PIM paradigm for two modern data-intensive applications: (1) machine learning inference models for edge devices and (2) hybrid transactional/analytical processing databases for cloud systems. We follow a two-step approach in our system design. In the first step, we extensively analyze the computation and memory access patterns of each application to gain insights into its hardware/software requirements and major sources of performance and energy bottlenecks in processor-centric systems. In the second step, we leverage the insights from the first step to co-design algorithms and hardware accelerators to enable high-performance and energy-efficient data-centric architectures for each application.
Sibyl: Adaptive and Extensible Data Placement in Hybrid Storage Systems Using Online Reinforcement Learning
May 15, 2022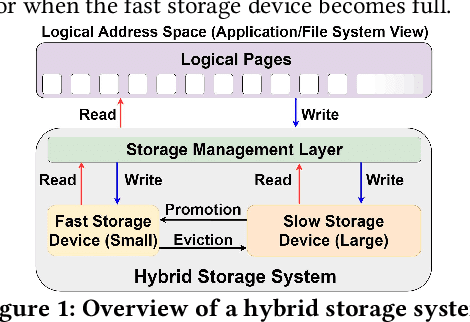

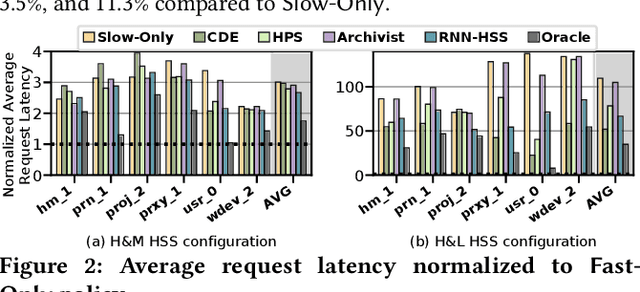
Hybrid storage systems (HSS) use multiple different storage devices to provide high and scalable storage capacity at high performance. Recent research proposes various techniques that aim to accurately identify performance-critical data to place it in a "best-fit" storage device. Unfortunately, most of these techniques are rigid, which (1) limits their adaptivity to perform well for a wide range of workloads and storage device configurations, and (2) makes it difficult for designers to extend these techniques to different storage system configurations (e.g., with a different number or different types of storage devices) than the configuration they are designed for. We introduce Sibyl, the first technique that uses reinforcement learning for data placement in hybrid storage systems. Sibyl observes different features of the running workload as well as the storage devices to make system-aware data placement decisions. For every decision it makes, Sibyl receives a reward from the system that it uses to evaluate the long-term performance impact of its decision and continuously optimizes its data placement policy online. We implement Sibyl on real systems with various HSS configurations. Our results show that Sibyl provides 21.6%/19.9% performance improvement in a performance-oriented/cost-oriented HSS configuration compared to the best previous data placement technique. Our evaluation using an HSS configuration with three different storage devices shows that Sibyl outperforms the state-of-the-art data placement policy by 23.9%-48.2%, while significantly reducing the system architect's burden in designing a data placement mechanism that can simultaneously incorporate three storage devices. We show that Sibyl achieves 80% of the performance of an oracle policy that has complete knowledge of future access patterns while incurring a very modest storage overhead of only 124.4 KiB.
DeepSketch: A New Machine Learning-Based Reference Search Technique for Post-Deduplication Delta Compression
Feb 17, 2022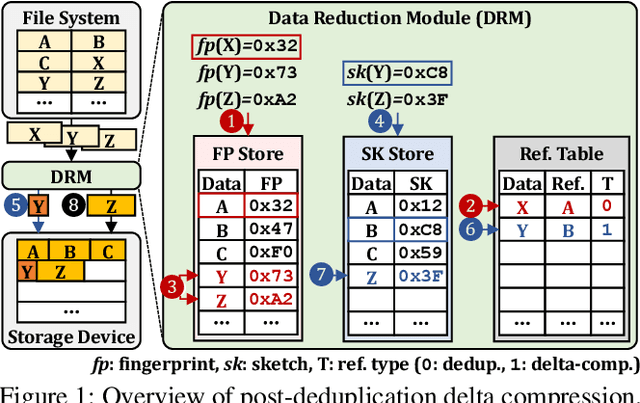
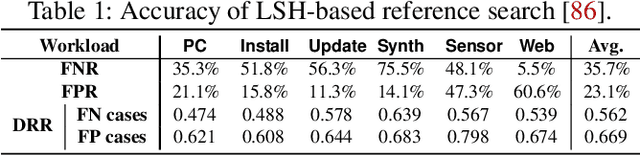
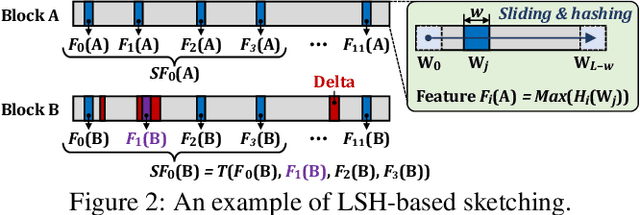
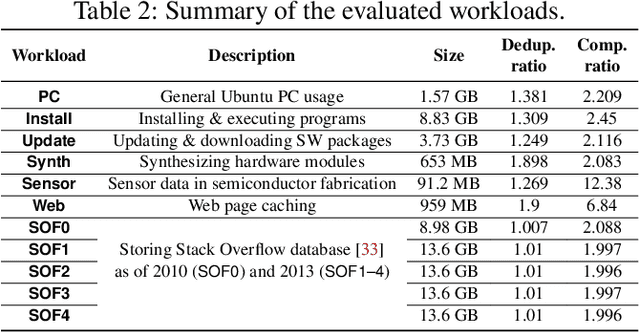
Data reduction in storage systems is becoming increasingly important as an effective solution to minimize the management cost of a data center. To maximize data-reduction efficiency, existing post-deduplication delta-compression techniques perform delta compression along with traditional data deduplication and lossless compression. Unfortunately, we observe that existing techniques achieve significantly lower data-reduction ratios than the optimal due to their limited accuracy in identifying similar data blocks. In this paper, we propose DeepSketch, a new reference search technique for post-deduplication delta compression that leverages the learning-to-hash method to achieve higher accuracy in reference search for delta compression, thereby improving data-reduction efficiency. DeepSketch uses a deep neural network to extract a data block's sketch, i.e., to create an approximate data signature of the block that can preserve similarity with other blocks. Our evaluation using eleven real-world workloads shows that DeepSketch improves the data-reduction ratio by up to 33% (21% on average) over a state-of-the-art post-deduplication delta-compression technique.
EcoFlow: Efficient Convolutional Dataflows for Low-Power Neural Network Accelerators
Feb 04, 2022

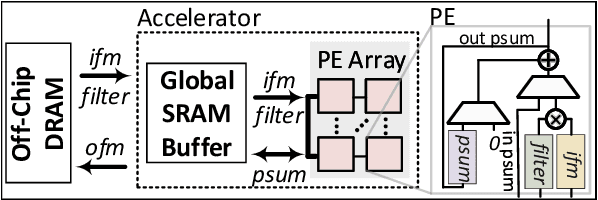
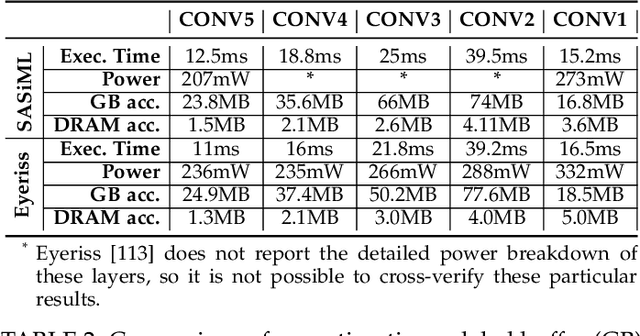
Dilated and transposed convolutions are widely used in modern convolutional neural networks (CNNs). These kernels are used extensively during CNN training and inference of applications such as image segmentation and high-resolution image generation. Although these kernels have grown in popularity, they stress current compute systems due to their high memory intensity, exascale compute demands, and large energy consumption. We find that commonly-used low-power CNN inference accelerators based on spatial architectures are not optimized for both of these convolutional kernels. Dilated and transposed convolutions introduce significant zero padding when mapped to the underlying spatial architecture, significantly degrading performance and energy efficiency. Existing approaches that address this issue require significant design changes to the otherwise simple, efficient, and well-adopted architectures used to compute direct convolutions. To address this challenge, we propose EcoFlow, a new set of dataflows and mapping algorithms for dilated and transposed convolutions. These algorithms are tailored to execute efficiently on existing low-cost, small-scale spatial architectures and requires minimal changes to the network-on-chip of existing accelerators. EcoFlow eliminates zero padding through careful dataflow orchestration and data mapping tailored to the spatial architecture. EcoFlow enables flexible and high-performance transpose and dilated convolutions on architectures that are otherwise optimized for CNN inference. We evaluate the efficiency of EcoFlow on CNN training workloads and Generative Adversarial Network (GAN) training workloads. Experiments in our new cycle-accurate simulator show that EcoFlow 1) reduces end-to-end CNN training time between 7-85%, and 2) improves end-to-end GAN training performance between 29-42%, compared to state-of-the-art CNN inference accelerators.
Pythia: A Customizable Hardware Prefetching Framework Using Online Reinforcement Learning
Oct 19, 2021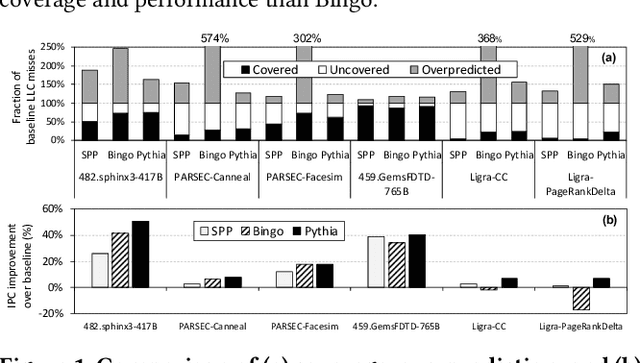
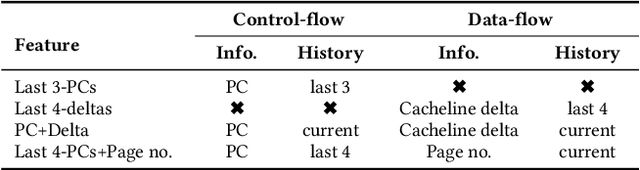

Past research has proposed numerous hardware prefetching techniques, most of which rely on exploiting one specific type of program context information (e.g., program counter, cacheline address) to predict future memory accesses. These techniques either completely neglect a prefetcher's undesirable effects (e.g., memory bandwidth usage) on the overall system, or incorporate system-level feedback as an afterthought to a system-unaware prefetch algorithm. We show that prior prefetchers often lose their performance benefit over a wide range of workloads and system configurations due to their inherent inability to take multiple different types of program context and system-level feedback information into account while prefetching. In this paper, we make a case for designing a holistic prefetch algorithm that learns to prefetch using multiple different types of program context and system-level feedback information inherent to its design. To this end, we propose Pythia, which formulates the prefetcher as a reinforcement learning agent. For every demand request, Pythia observes multiple different types of program context information to make a prefetch decision. For every prefetch decision, Pythia receives a numerical reward that evaluates prefetch quality under the current memory bandwidth usage. Pythia uses this reward to reinforce the correlation between program context information and prefetch decision to generate highly accurate, timely, and system-aware prefetch requests in the future. Our extensive evaluations using simulation and hardware synthesis show that Pythia outperforms multiple state-of-the-art prefetchers over a wide range of workloads and system configurations, while incurring only 1.03% area overhead over a desktop-class processor and no software changes in workloads. The source code of Pythia can be freely downloaded from https://github.com/CMU-SAFARI/Pythia.
Google Neural Network Models for Edge Devices: Analyzing and Mitigating Machine Learning Inference Bottlenecks
Sep 29, 2021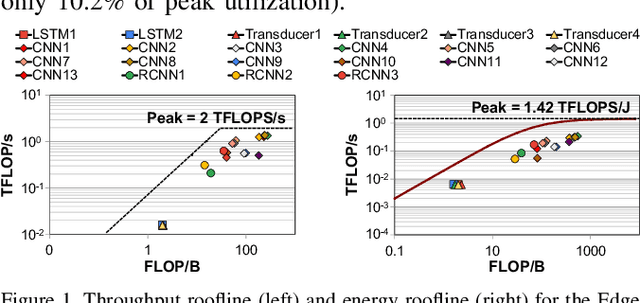
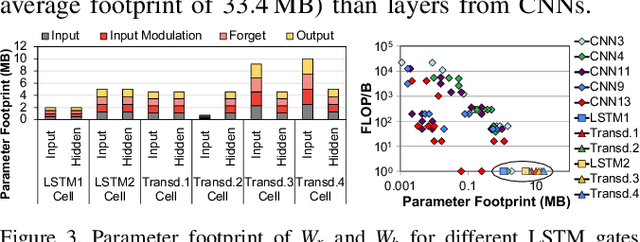
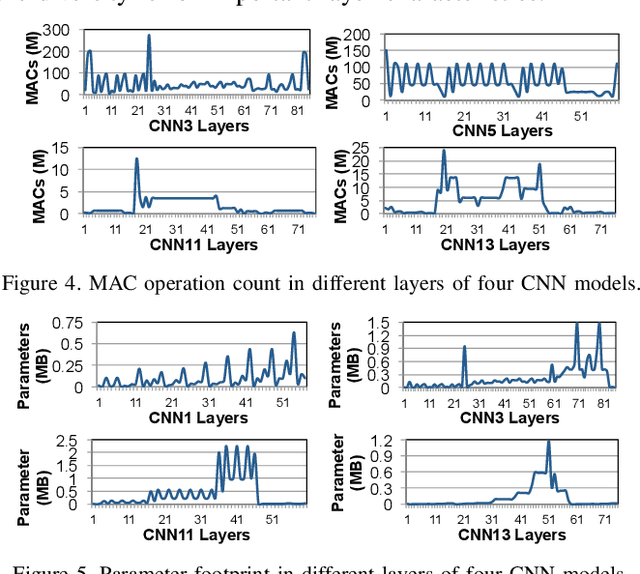
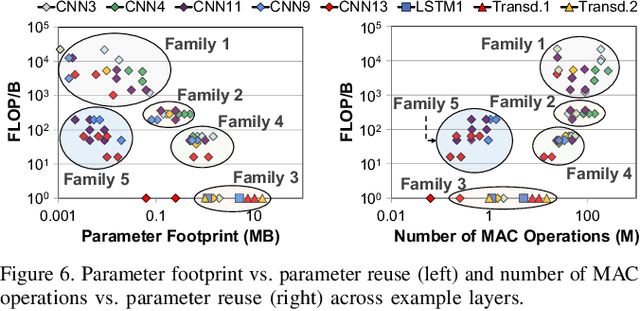
Emerging edge computing platforms often contain machine learning (ML) accelerators that can accelerate inference for a wide range of neural network (NN) models. These models are designed to fit within the limited area and energy constraints of the edge computing platforms, each targeting various applications (e.g., face detection, speech recognition, translation, image captioning, video analytics). To understand how edge ML accelerators perform, we characterize the performance of a commercial Google Edge TPU, using 24 Google edge NN models (which span a wide range of NN model types) and analyzing each NN layer within each model. We find that the Edge TPU suffers from three major shortcomings: (1) it operates significantly below peak computational throughput, (2) it operates significantly below its theoretical energy efficiency, and (3) its memory system is a large energy and performance bottleneck. Our characterization reveals that the one-size-fits-all, monolithic design of the Edge TPU ignores the high degree of heterogeneity both across different NN models and across different NN layers within the same NN model, leading to the shortcomings we observe. We propose a new acceleration framework called Mensa. Mensa incorporates multiple heterogeneous edge ML accelerators (including both on-chip and near-data accelerators), each of which caters to the characteristics of a particular subset of NN models and layers. During NN inference, for each NN layer, Mensa decides which accelerator to schedule the layer on, taking into account both the optimality of each accelerator for the layer and layer-to-layer communication costs. Averaged across all 24 Google edge NN models, Mensa improves energy efficiency and throughput by 3.0x and 3.1x over the Edge TPU, and by 2.4x and 4.3x over Eyeriss~v2, a state-of-the-art accelerator.
Energy-Efficient Mobile Robot Control via Run-time Monitoring of Environmental Complexity and Computing Workload
Sep 08, 2021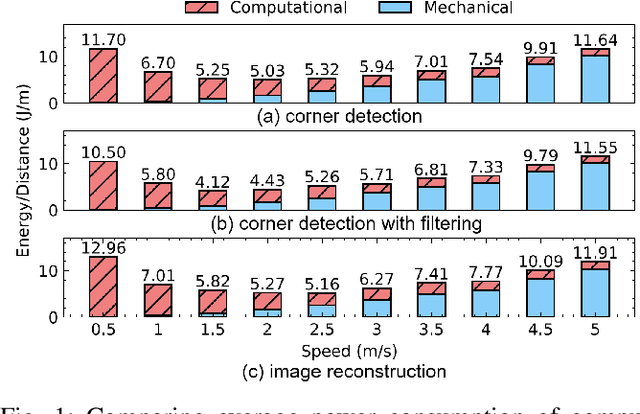

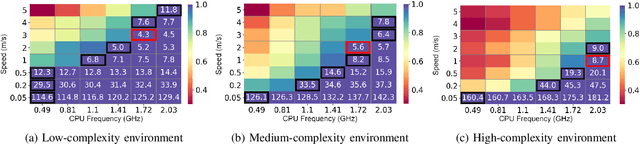
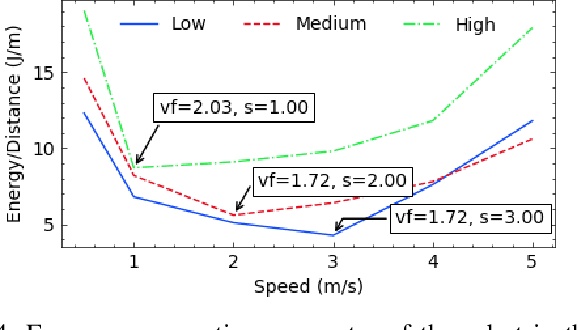
We propose an energy-efficient controller to minimize the energy consumption of a mobile robot by dynamically manipulating the mechanical and computational actuators of the robot. The mobile robot performs real-time vision-based applications based on an event-based camera. The actuators of the controller are CPU voltage/frequency for the computation part and motor voltage for the mechanical part. We show that independently considering speed control of the robot and voltage/frequency control of the CPU does not necessarily result in an energy-efficient solution. In fact, to obtain the highest efficiency, the computation and mechanical parts should be controlled together in synergy. We propose a fast hill-climbing optimization algorithm to allow the controller to find the best CPU/motor configuration at run-time and whenever the mobile robot is facing a new environment during its travel. Experimental results on a robot with Brushless DC Motors, Jetson TX2 board as the computing unit, and a DAVIS-346 event-based camera show that the proposed control algorithm can save battery energy by an average of 50.5%, 41%, and 30%, in low-complexity, medium-complexity, and high-complexity environments, over baselines.
GateKeeper-GPU: Fast and Accurate Pre-Alignment Filtering in Short Read Mapping
Mar 31, 2021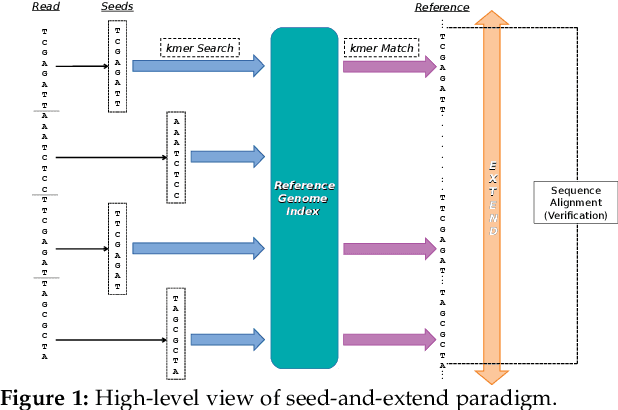
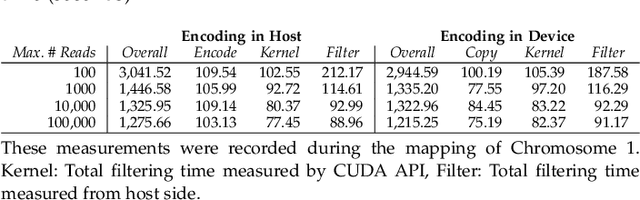

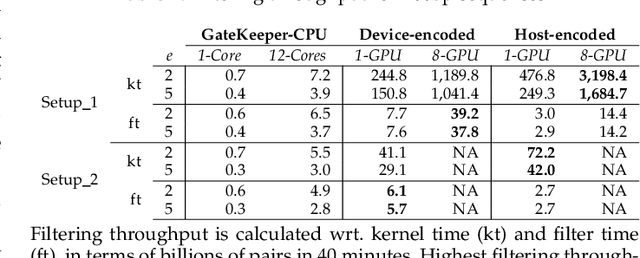
At the last step of short read mapping, the candidate locations of the reads on the reference genome are verified to compute their differences from the corresponding reference segments using sequence alignment algorithms. Calculating the similarities and differences between two sequences is still computationally expensive since approximate string matching techniques traditionally inherit dynamic programming algorithms with quadratic time and space complexity. We introduce GateKeeper-GPU, a fast and accurate pre-alignment filter that efficiently reduces the need for expensive sequence alignment. GateKeeper-GPU provides two main contributions: first, improving the filtering accuracy of GateKeeper(state-of-the-art lightweight pre-alignment filter), second, exploiting the massive parallelism provided by the large number of GPU threads of modern GPUs to examine numerous sequence pairs rapidly and concurrently. GateKeeper-GPU accelerates the sequence alignment by up to 2.9x and provides up to 1.4x speedup to the end-to-end execution time of a comprehensive read mapper (mrFAST). GateKeeper-GPU is available at https://github.com/BilkentCompGen/GateKeeper-GPU
GraphMineSuite: Enabling High-Performance and Programmable Graph Mining Algorithms with Set Algebra
Mar 05, 2021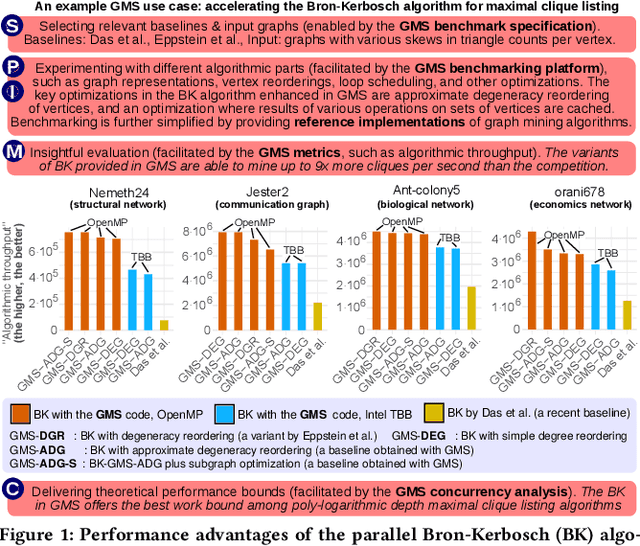

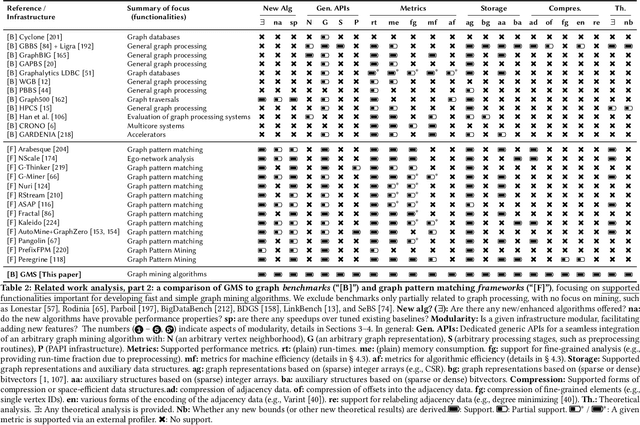
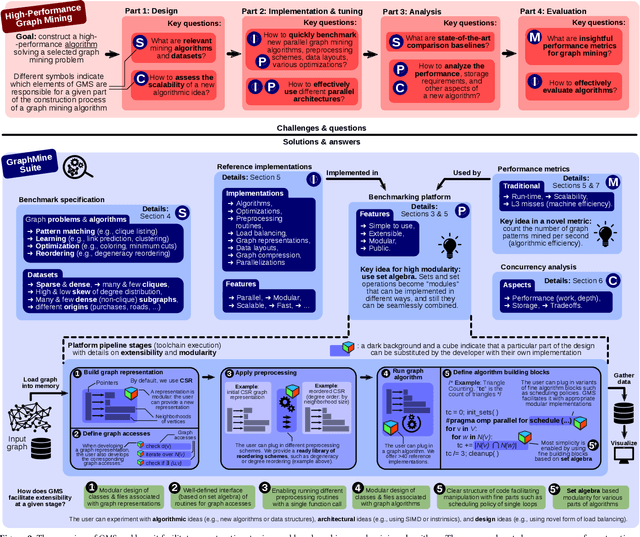
We propose GraphMineSuite (GMS): the first benchmarking suite for graph mining that facilitates evaluating and constructing high-performance graph mining algorithms. First, GMS comes with a benchmark specification based on extensive literature review, prescribing representative problems, algorithms, and datasets. Second, GMS offers a carefully designed software platform for seamless testing of different fine-grained elements of graph mining algorithms, such as graph representations or algorithm subroutines. The platform includes parallel implementations of more than 40 considered baselines, and it facilitates developing complex and fast mining algorithms. High modularity is possible by harnessing set algebra operations such as set intersection and difference, which enables breaking complex graph mining algorithms into simple building blocks that can be separately experimented with. GMS is supported with a broad concurrency analysis for portability in performance insights, and a novel performance metric to assess the throughput of graph mining algorithms, enabling more insightful evaluation. As use cases, we harness GMS to rapidly redesign and accelerate state-of-the-art baselines of core graph mining problems: degeneracy reordering (by up to >2x), maximal clique listing (by up to >9x), k-clique listing (by 1.1x), and subgraph isomorphism (by up to 2.5x), also obtaining better theoretical performance bounds.