 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgenBIIG: A Neural BI Insights Generation System for Table Reporting
Nov 08, 2022


We present nBIIG, a neural Business Intelligence (BI) Insights Generation system. Given a table, our system applies various analyses to create corresponding RDF representations, and then uses a neural model to generate fluent textual insights out of these representations. The generated insights can be used by an analyst, via a human-in-the-loop paradigm, to enhance the task of creating compelling table reports. The underlying generative neural model is trained over large and carefully distilled data, curated from multiple BI domains. Thus, the system can generate faithful and fluent insights over open-domain tables, making it practical and useful.
Zero-Shot Text Classification with Self-Training
Oct 31, 2022



Recent advances in large pretrained language models have increased attention to zero-shot text classification. In particular, models finetuned on natural language inference datasets have been widely adopted as zero-shot classifiers due to their promising results and off-the-shelf availability. However, the fact that such models are unfamiliar with the target task can lead to instability and performance issues. We propose a plug-and-play method to bridge this gap using a simple self-training approach, requiring only the class names along with an unlabeled dataset, and without the need for domain expertise or trial and error. We show that fine-tuning the zero-shot classifier on its most confident predictions leads to significant performance gains across a wide range of text classification tasks, presumably since self-training adapts the zero-shot model to the task at hand.
Label Sleuth: From Unlabeled Text to a Classifier in a Few Hours
Aug 02, 2022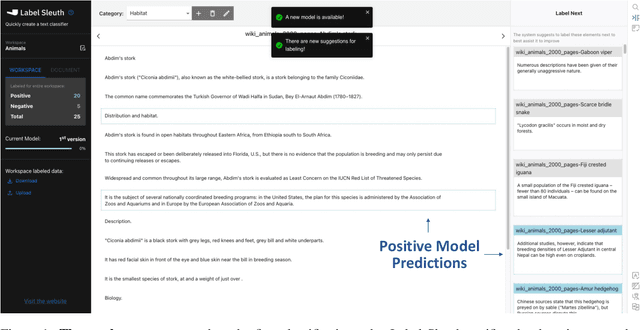

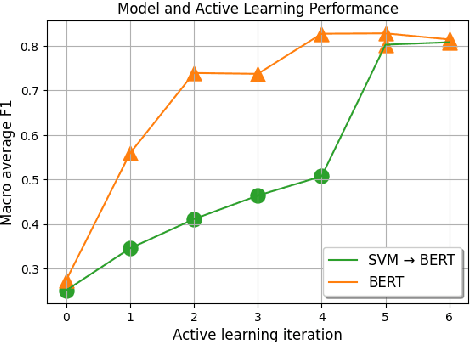

Text classification can be useful in many real-world scenarios, saving a lot of time for end users. However, building a custom classifier typically requires coding skills and ML knowledge, which poses a significant barrier for many potential users. To lift this barrier, we introduce Label Sleuth, a free open source system for labeling and creating text classifiers. This system is unique for (a) being a no-code system, making NLP accessible to non-experts, (b) guiding users through the entire labeling process until they obtain a custom classifier, making the process efficient -- from cold start to classifier in a few hours, and (c) being open for configuration and extension by developers. By open sourcing Label Sleuth we hope to build a community of users and developers that will broaden the utilization of NLP models.
VIRATrustData: A Trust-Annotated Corpus of Human-Chatbot Conversations About COVID-19 Vaccines
May 24, 2022
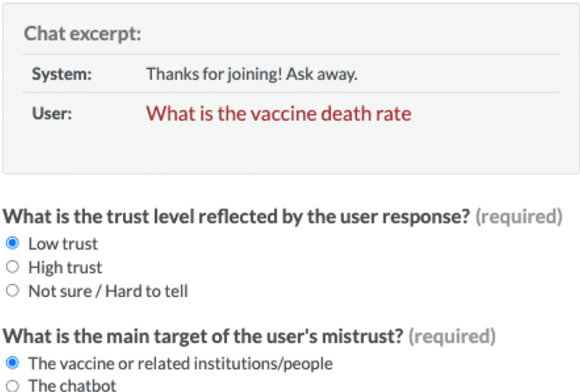
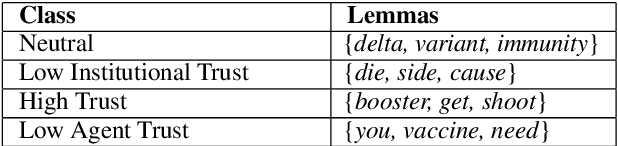
Public trust in medical information is crucial for successful application of public health policies such as vaccine uptake. This is especially true when the information is offered remotely, by chatbots, which have become increasingly popular in recent years. Here, we explore the challenging task of human-bot turn-level trust classification. We rely on a recently released data of observationally-collected (rather than crowdsourced) dialogs with VIRA chatbot, a COVID-19 Vaccine Information Resource Assistant. These dialogs are centered around questions and concerns about COVID-19 vaccines, where trust is particularly acute. We annotated $3k$ VIRA system-user conversational turns for Low Institutional Trust or Low Agent Trust vs. Neutral or High Trust. We release the labeled dataset, VIRATrustData, the first of its kind to the best of our knowledge. We demonstrate how this task is non-trivial and compare several models that predict the different levels of trust.
Benchmark Data and Evaluation Framework for Intent Discovery Around COVID-19 Vaccine Hesitancy
May 24, 2022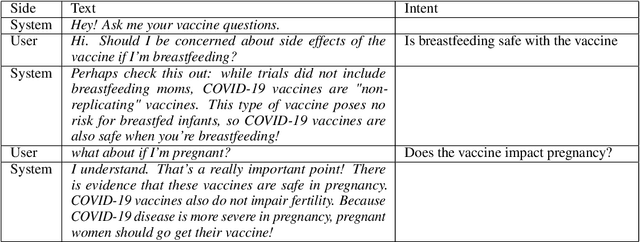
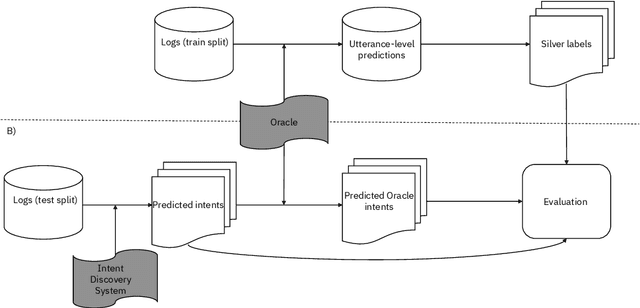

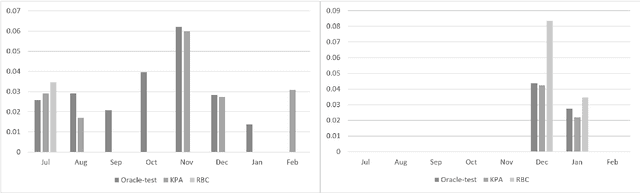
The COVID-19 pandemic has made a huge global impact and cost millions of lives. As COVID-19 vaccines were rolled out, they were quickly met with widespread hesitancy. To address the concerns of hesitant people, we launched VIRA, a public dialogue system aimed at addressing questions and concerns surrounding the COVID-19 vaccines. Here, we release VIRADialogs, a dataset of over 8k dialogues conducted by actual users with VIRA, providing a unique real-world conversational dataset. In light of rapid changes in users' intents, due to updates in guidelines or as a response to new information, we highlight the important task of intent discovery in this use-case. We introduce a novel automatic evaluation framework for intent discovery, leveraging the existing intent classifier of a given dialogue system. We use this framework to report baseline intent-discovery results over VIRADialogs, that highlight the difficulty of this task.
Diversity Enhanced Table-to-Text Generation via Type Control
May 22, 2022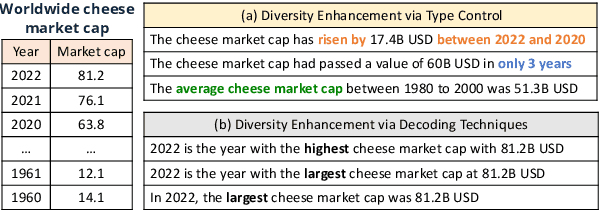

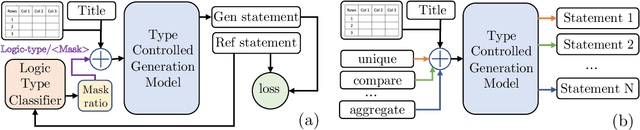

Generating natural language statements to convey information from tabular data (i.e., Table-to-text) is a process with one input and a variety of valid outputs. This characteristic underscores the abilities to control the generation and produce a diverse set of outputs as two key assets. Thus, we propose a diversity enhancing scheme that builds upon an inherent property of the statements, namely, their logic-types, by using a type-controlled Table-to-text generation model. Employing automatic and manual tests, we prove its twofold advantage: users can effectively tune the generated statement type, and, by sampling different types, can obtain a diverse set of statements for a given table.
Multi-Domain Targeted Sentiment Analysis
May 08, 2022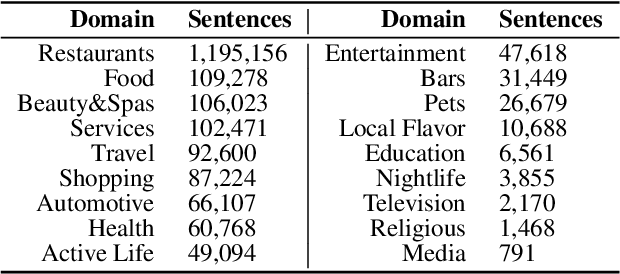
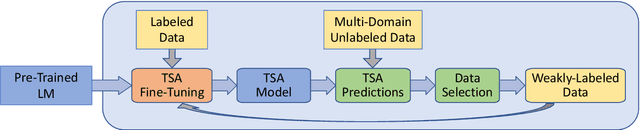
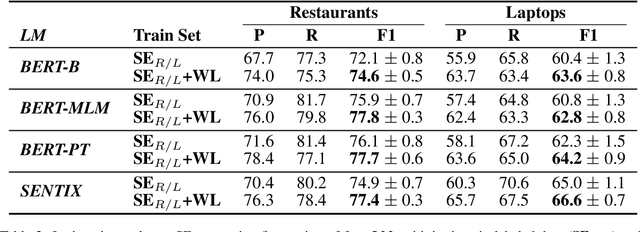
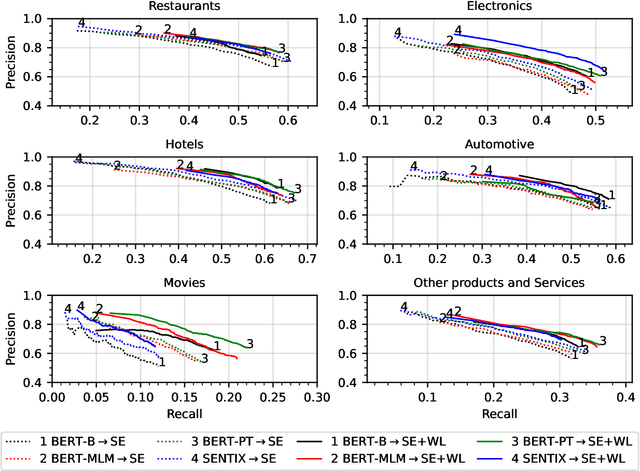
Targeted Sentiment Analysis (TSA) is a central task for generating insights from consumer reviews. Such content is extremely diverse, with sites like Amazon or Yelp containing reviews on products and businesses from many different domains. A real-world TSA system should gracefully handle that diversity. This can be achieved by a multi-domain model -- one that is robust to the domain of the analyzed texts, and performs well on various domains. To address this scenario, we present a multi-domain TSA system based on augmenting a given training set with diverse weak labels from assorted domains. These are obtained through self-training on the Yelp reviews corpus. Extensive experiments with our approach on three evaluation datasets across different domains demonstrate the effectiveness of our solution. We further analyze how restrictions imposed on the available labeled data affect the performance, and compare the proposed method to the costly alternative of manually gathering diverse TSA labeled data. Our results and analysis show that our approach is a promising step towards a practical domain-robust TSA system.
Fusing finetuned models for better pretraining
Apr 06, 2022
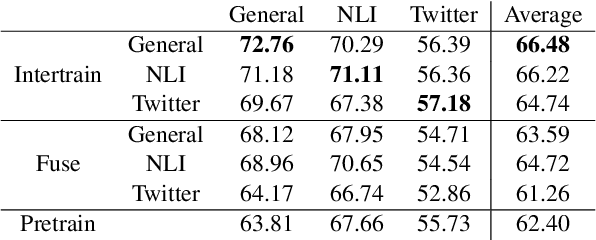
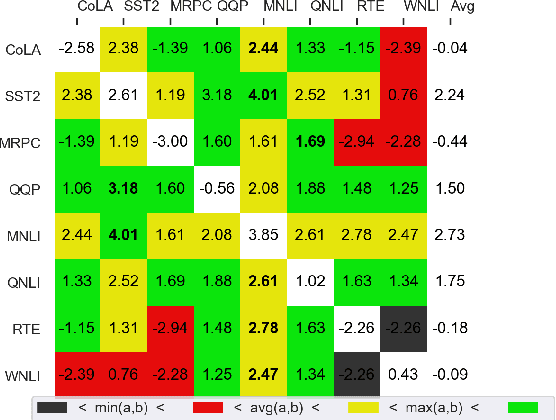

Pretrained models are the standard starting point for training. This approach consistently outperforms the use of a random initialization. However, pretraining is a costly endeavour that few can undertake. In this paper, we create better base models at hardly any cost, by fusing multiple existing fine tuned models into one. Specifically, we fuse by averaging the weights of these models. We show that the fused model results surpass the pretrained model ones. We also show that fusing is often better than intertraining. We find that fusing is less dependent on the target task. Furthermore, weight decay nullifies intertraining effects but not those of fusing.
Quality Controlled Paraphrase Generation
Apr 01, 2022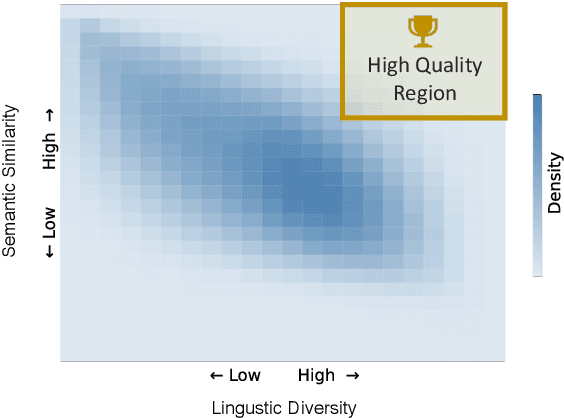

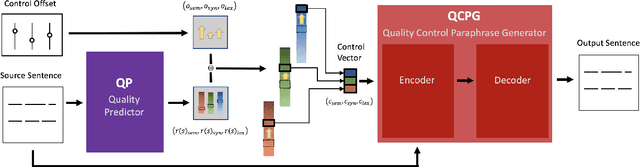
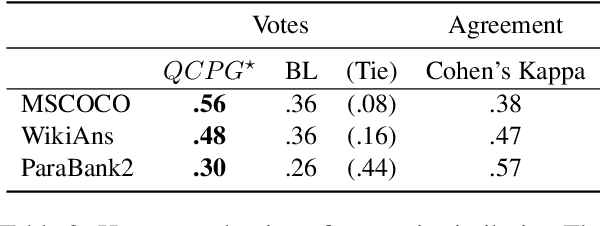
Paraphrase generation has been widely used in various downstream tasks. Most tasks benefit mainly from high quality paraphrases, namely those that are semantically similar to, yet linguistically diverse from, the original sentence. Generating high-quality paraphrases is challenging as it becomes increasingly hard to preserve meaning as linguistic diversity increases. Recent works achieve nice results by controlling specific aspects of the paraphrase, such as its syntactic tree. However, they do not allow to directly control the quality of the generated paraphrase, and suffer from low flexibility and scalability. Here we propose $QCPG$, a quality-guided controlled paraphrase generation model, that allows directly controlling the quality dimensions. Furthermore, we suggest a method that given a sentence, identifies points in the quality control space that are expected to yield optimal generated paraphrases. We show that our method is able to generate paraphrases which maintain the original meaning while achieving higher diversity than the uncontrolled baseline. The models, the code, and the data can be found in https://github.com/IBM/quality-controlled-paraphrase-generation.
Heuristic-based Inter-training to Improve Few-shot Multi-perspective Dialog Summarization
Mar 30, 2022
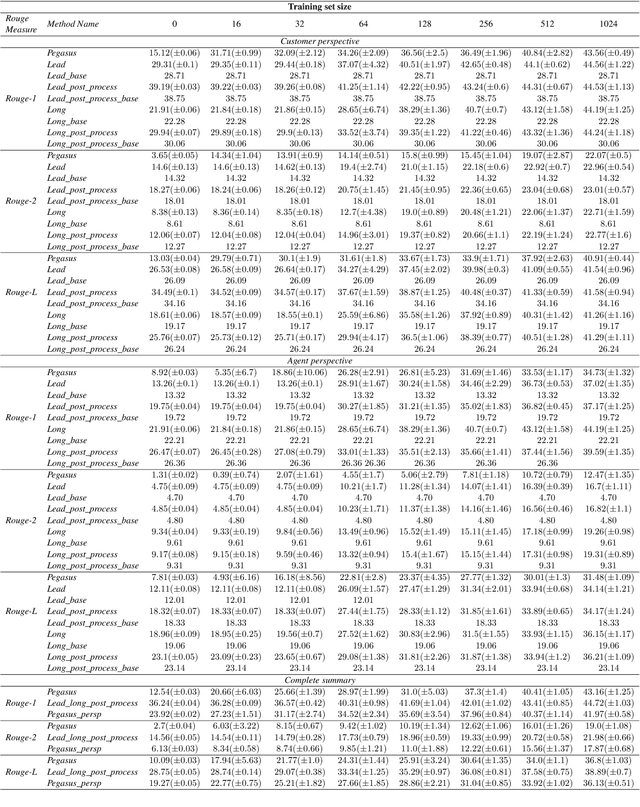
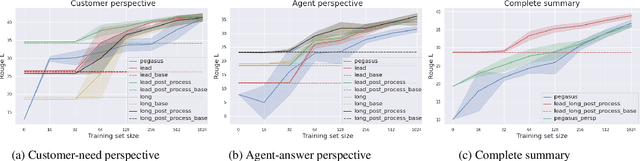
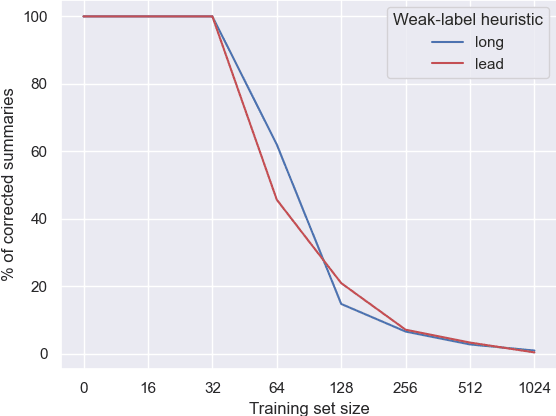
Many organizations require their customer-care agents to manually summarize their conversations with customers. These summaries are vital for decision making purposes of the organizations. The perspective of the summary that is required to be created depends on the application of the summaries. With this work, we study the multi-perspective summarization of customer-care conversations between support agents and customers. We observe that there are different heuristics that are associated with summaries of different perspectives, and explore these heuristics to create weak-labeled data for intermediate training of the models before fine-tuning with scarce human annotated summaries. Most importantly, we show that our approach supports models to generate multi-perspective summaries with a very small amount of annotated data. For example, our approach achieves 94\% of the performance (Rouge-2) of a model trained with the original data, by training only with 7\% of the original data.