 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhases of Muon: When Muon Eclipses SignSGD
May 10, 2026Recently, Muon and related spectral optimizers have demonstrated strong empirical performance as scalable stochastic methods, often outperforming Adam. Yet their behaviour remains poorly understood. We analyze stochastic spectral optimizers, including Muon, on a high-dimensional matrix-valued least squares problem. We derive explicit deterministic dynamics that provide a tractable framework for studying learning behaviour with a focus on (stochastic) SignSVD, which Muon approximates, and (stochastic) SignSGD, the latter serving as a proxy for Adam. Our analysis shows that for large batch size, SignSVD performs a square-root preconditioning with respect to the data covariance spectrum, while for small batch size smaller eigenmodes behave like SGD, slowing down convergence. We contrast with SignSGD which for generic covariance performs no preconditioning and has no transition, leading to different optimal learning rates and convergence characteristics. The two methods match up to a constant factor with isotropic data, but behave differently with anisotropic data. An analysis of a power law covariance model with data exponent $α$ and target exponent $β$ shows there are three phases in the $(α,β)$ plane: one where SignSGD is uniformly favored, one where SignSVD is uniformly favored, and a third where the two methods exhibit a trade-off in performance.
Eigenvalue distribution of the Neural Tangent Kernel in the quadratic scaling
Aug 27, 2025We compute the asymptotic eigenvalue distribution of the neural tangent kernel of a two-layer neural network under a specific scaling of dimension. Namely, if $X\in\mathbb{R}^{n\times d}$ is an i.i.d random matrix, $W\in\mathbb{R}^{d\times p}$ is an i.i.d $\mathcal{N}(0,1)$ matrix and $D\in\mathbb{R}^{p\times p}$ is a diagonal matrix with i.i.d bounded entries, we consider the matrix \[ \mathrm{NTK} = \frac{1}{d}XX^\top \odot \frac{1}{p} \sigma'\left( \frac{1}{\sqrt{d}}XW \right)D^2 \sigma'\left( \frac{1}{\sqrt{d}}XW \right)^\top \] where $\sigma'$ is a pseudo-Lipschitz function applied entrywise and under the scaling $\frac{n}{dp}\to \gamma_1$ and $\frac{p}{d}\to \gamma_2$. We describe the asymptotic distribution as the free multiplicative convolution of the Marchenko--Pastur distribution with a deterministic distribution depending on $\sigma$ and $D$.
Largest Eigenvalues of the Conjugate Kernel of Single-Layered Neural Networks
Jan 13, 2022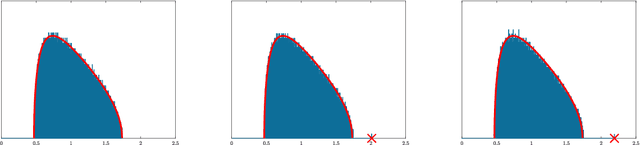
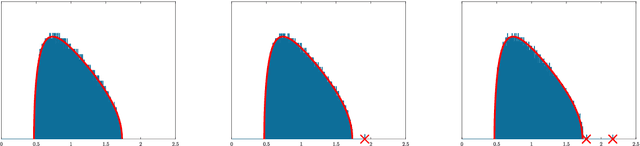
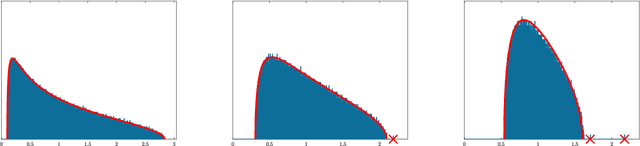
This paper is concerned with the asymptotic distribution of the largest eigenvalues for some nonlinear random matrix ensemble stemming from the study of neural networks. More precisely we consider $M= \frac{1}{m} YY^\top$ with $Y=f(WX)$ where $W$ and $X$ are random rectangular matrices with i.i.d. centered entries. This models the data covariance matrix or the Conjugate Kernel of a single layered random Feed-Forward Neural Network. The function $f$ is applied entrywise and can be seen as the activation function of the neural network. We show that the largest eigenvalue has the same limit (in probability) as that of some well-known linear random matrix ensembles. In particular, we relate the asymptotic limit of the largest eigenvalue for the nonlinear model to that of an information-plus-noise random matrix, establishing a possible phase transition depending on the function $f$ and the distribution of $W$ and $X$. This may be of interest for applications to machine learning.
Eigenvalue distribution of nonlinear models of random matrices
Apr 25, 2019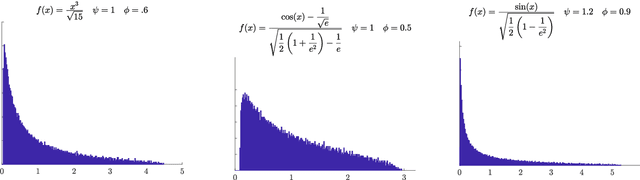
This paper is concerned with the asymptotic empirical eigenvalue distribution of a non linear random matrix ensemble. More precisely we consider $M= \frac{1}{m} YY^*$ with $Y=f(WX)$ where $W$ and $X$ are random rectangular matrices with i.i.d. centered entries. The function $f$ is applied pointwise and can be seen as an activation function in (random) neural networks. We compute the asymptotic empirical distribution of this ensemble in the case where $W$ and $X$ have sub-Gaussian tails and $f$ is real analytic. This extends a previous result where the case of Gaussian matrices $W$ and $X$ is considered. We also investigate the same questions in the multi-layer case, regarding neural network applications.