 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Instruct: Aligning Language Model with Self Generated Instructions
Dec 20, 2022



Large "instruction-tuned" language models (finetuned to respond to instructions) have demonstrated a remarkable ability to generalize zero-shot to new tasks. Nevertheless, they depend heavily on human-written instruction data that is limited in quantity, diversity, and creativity, therefore hindering the generality of the tuned model. We introduce Self-Instruct, a framework for improving the instruction-following capabilities of pretrained language models by bootstrapping off its own generations. Our pipeline generates instruction, input, and output samples from a language model, then prunes them before using them to finetune the original model. Applying our method to vanilla GPT3, we demonstrate a 33% absolute improvement over the original model on Super-NaturalInstructions, on par with the performance of InstructGPT_001, which is trained with private user data and human annotations. For further evaluation, we curate a set of expert-written instructions for novel tasks, and show through human evaluation that tuning GPT3 with Self-Instruct outperforms using existing public instruction datasets by a large margin, leaving only a 5% absolute gap behind InstructGPT_001. Self-Instruct provides an almost annotation-free method for aligning pre-trained language models with instructions, and we release our large synthetic dataset to facilitate future studies on instruction tuning.
Demystifying Prompts in Language Models via Perplexity Estimation
Dec 08, 2022



Language models can be prompted to perform a wide variety of zero- and few-shot learning problems. However, performance varies significantly with the choice of prompt, and we do not yet understand why this happens or how to pick the best prompts. In this work, we analyze the factors that contribute to this variance and establish a new empirical hypothesis: the performance of a prompt is coupled with the extent to which the model is familiar with the language it contains. Over a wide range of tasks, we show that the lower the perplexity of the prompt is, the better the prompt is able to perform the task. As a result, we devise a method for creating prompts: (1) automatically extend a small seed set of manually written prompts by paraphrasing using GPT3 and backtranslation and (2) choose the lowest perplexity prompts to get significant gains in performance.
Data-Efficient Finetuning Using Cross-Task Nearest Neighbors
Dec 01, 2022



Language models trained on massive prompted multitask datasets like T0 (Sanh et al., 2021) or FLAN (Wei et al., 2021a) can generalize to tasks unseen during training. We show that training on a carefully chosen subset of instances can outperform training on all available data on a variety of datasets. We assume access to a small number (250--1000) of unlabeled target task instances, select their nearest neighbors from a pool of multitask data, and use the retrieved data to train target task-specific models. Our method is more data-efficient than training a single multitask model, while still outperforming it by large margins. We evaluate across a diverse set of tasks not in the multitask pool we retrieve from, including those used to evaluate T0 and additional complex tasks including legal and scientific document QA. We retrieve small subsets of P3 (the collection of prompted datasets from which T0's training data was sampled) and finetune T5 models that outperform the 3-billion parameter variant of T0 (T0-3B) by 3--30% on 12 out of 14 evaluation datasets while using at most 2% of the data used to train T0-3B. These models also provide a better initialization than T0-3B for few-shot finetuning on target-task data, as shown by a 2--23% relative improvement over few-shot finetuned T0-3B models on 8 datasets. Our code is available at https://github.com/allenai/data-efficient-finetuning.
Domain Mismatch Doesn't Always Prevent Cross-Lingual Transfer Learning
Nov 30, 2022



Cross-lingual transfer learning without labeled target language data or parallel text has been surprisingly effective in zero-shot cross-lingual classification, question answering, unsupervised machine translation, etc. However, some recent publications have claimed that domain mismatch prevents cross-lingual transfer, and their results show that unsupervised bilingual lexicon induction (UBLI) and unsupervised neural machine translation (UNMT) do not work well when the underlying monolingual corpora come from different domains (e.g., French text from Wikipedia but English text from UN proceedings). In this work, we show that a simple initialization regimen can overcome much of the effect of domain mismatch in cross-lingual transfer. We pre-train word and contextual embeddings on the concatenated domain-mismatched corpora, and use these as initializations for three tasks: MUSE UBLI, UN Parallel UNMT, and the SemEval 2017 cross-lingual word similarity task. In all cases, our results challenge the conclusions of prior work by showing that proper initialization can recover a large portion of the losses incurred by domain mismatch.
* 8 pages, 1 figure. Published/presented at LREC (2022)
PromptCap: Prompt-Guided Task-Aware Image Captioning
Nov 15, 2022



Image captioning aims to describe an image with a natural language sentence, allowing powerful language models to understand images. The framework of combining image captioning with language models has been successful on various vision-language tasks. However, an image contains much more information than a single sentence, leading to underspecification of which visual entities should be described in the caption sentence. For example, when performing visual questioning answering (VQA), generic image captions often miss visual details that are essential for the language model to answer correctly. To address this challenge, we propose PromptCap, a captioning model that takes a natural-language prompt to control the contents of the generated caption. The prompt contains a question that the caption should help to answer, and also supports taking auxiliary text inputs such as scene text within the image itself. To finetune a general image caption model for prompt-guided captioning, we propose a pipeline to synthesize and filter training examples with GPT-3 and existing VQA datasets. For evaluation, we start with an existing pipeline in which a language model is prompted with image captions to carry out VQA. With the same language model, a higher QA accuracy shows that our generated captions are more relevant to the question prompts. PromptCap outperforms generic captions by a large margin on a variety of VQA tasks and achieves the state-of-the-art accuracy of 58.8 % on OK-VQA and 58.0 % on A-OKVQA. Zero-shot experiments on WebQA show that PromptCap generalizes well to unseen domains.
How Much Does Attention Actually Attend? Questioning the Importance of Attention in Pretrained Transformers
Nov 07, 2022



The attention mechanism is considered the backbone of the widely-used Transformer architecture. It contextualizes the input by computing input-specific attention matrices. We find that this mechanism, while powerful and elegant, is not as important as typically thought for pretrained language models. We introduce PAPA, a new probing method that replaces the input-dependent attention matrices with constant ones -- the average attention weights over multiple inputs. We use PAPA to analyze several established pretrained Transformers on six downstream tasks. We find that without any input-dependent attention, all models achieve competitive performance -- an average relative drop of only 8% from the probing baseline. Further, little or no performance drop is observed when replacing half of the input-dependent attention matrices with constant (input-independent) ones. Interestingly, we show that better-performing models lose more from applying our method than weaker models, suggesting that the utilization of the input-dependent attention mechanism might be a factor in their success. Our results motivate research on simpler alternatives to input-dependent attention, as well as on methods for better utilization of this mechanism in the Transformer architecture.
Modeling Context With Linear Attention for Scalable Document-Level Translation
Oct 16, 2022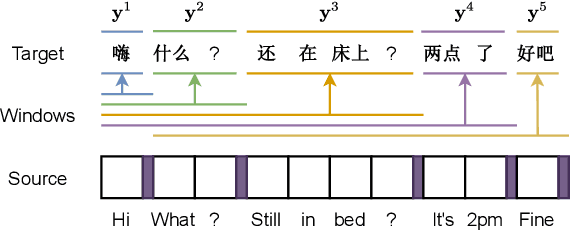
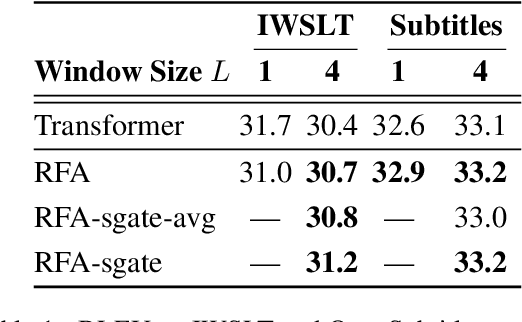
Document-level machine translation leverages inter-sentence dependencies to produce more coherent and consistent translations. However, these models, predominantly based on transformers, are difficult to scale to long documents as their attention layers have quadratic complexity in the sequence length. Recent efforts on efficient attention improve scalability, but their effect on document translation remains unexplored. In this work, we investigate the efficacy of a recent linear attention model by Peng et al. (2021) on document translation and augment it with a sentential gate to promote a recency inductive bias. We evaluate the model on IWSLT 2015 and OpenSubtitles 2018 against the transformer, demonstrating substantially increased decoding speed on long sequences with similar or better BLEU scores. We show that sentential gating further improves translation quality on IWSLT.
Transparency Helps Reveal When Language Models Learn Meaning
Oct 14, 2022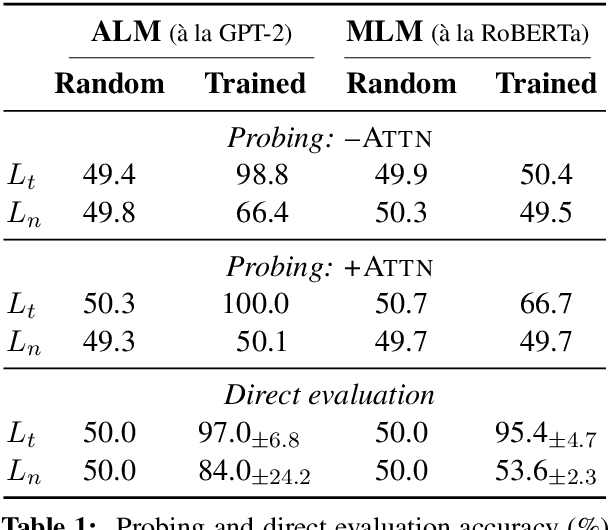
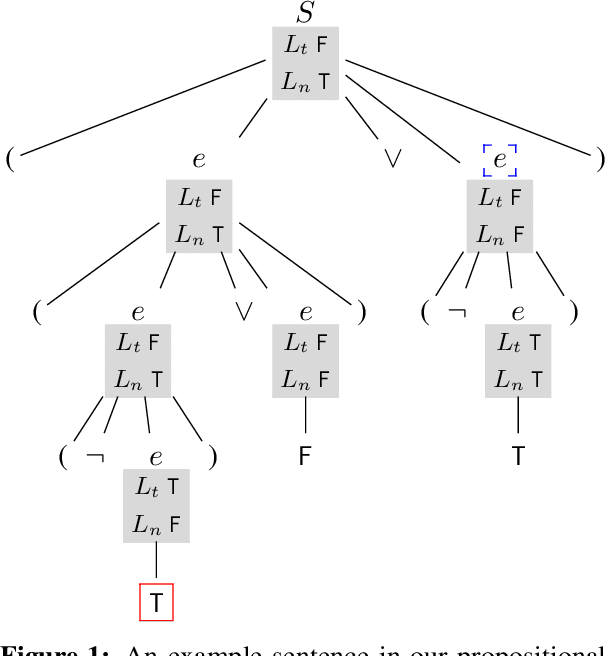

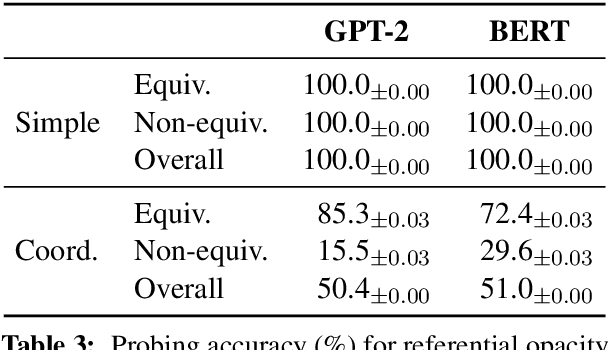
Many current NLP systems are built from language models trained to optimize unsupervised objectives on large amounts of raw text. Under what conditions might such a procedure acquire meaning? Our systematic experiments with synthetic data reveal that, with languages where all expressions have context-independent denotations (i.e., languages with strong transparency), both autoregressive and masked language models successfully learn to emulate semantic relations between expressions. However, when denotations are changed to be context-dependent with the language otherwise unmodified, this ability degrades. Turning to natural language, our experiments with a specific phenomenon -- referential opacity -- add to the growing body of evidence that current language models do not well-represent natural language semantics. We show this failure relates to the context-dependent nature of natural language form-meaning mappings.
Measuring and Narrowing the Compositionality Gap in Language Models
Oct 07, 2022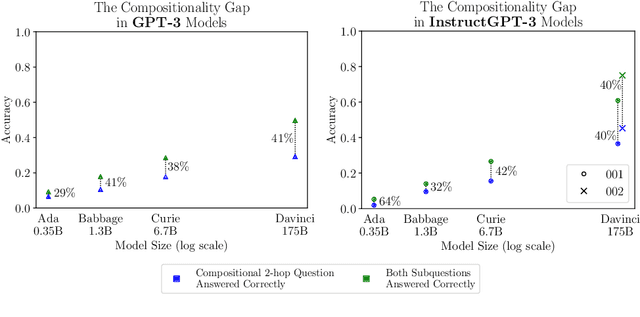
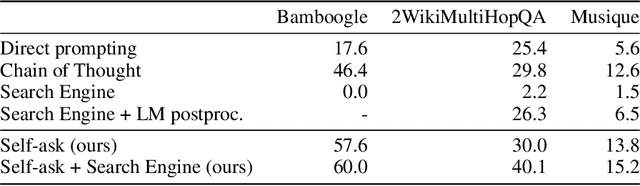
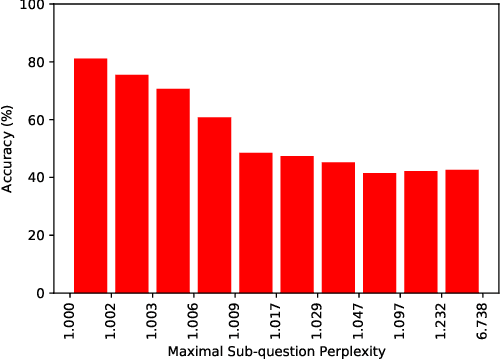

We investigate the ability of language models to perform compositional reasoning tasks where the overall solution depends on correctly composing the answers to sub-problems. We measure how often models can correctly answer all sub-problems but not generate the overall solution, a ratio we call the compositionality gap. We evaluate this ratio by asking multi-hop questions with answers that require composing multiple facts unlikely to have been observed together during pretraining. In the GPT-3 family of models, as model size increases we show that the single-hop question answering performance improves faster than the multi-hop performance does, therefore the compositionality gap does not decrease. This surprising result suggests that while more powerful models memorize and recall more factual knowledge, they show no corresponding improvement in their ability to perform this kind of compositional reasoning. We then demonstrate how elicitive prompting (such as chain of thought) narrows the compositionality gap by reasoning explicitly instead of implicitly. We present a new method, self-ask, that further improves on chain of thought. In our method, the model explicitly asks itself (and then answers) follow-up questions before answering the initial question. We finally show that self-ask's structured prompting lets us easily plug in a search engine to answer the follow-up questions, which additionally improves accuracy.
Binding Language Models in Symbolic Languages
Oct 06, 2022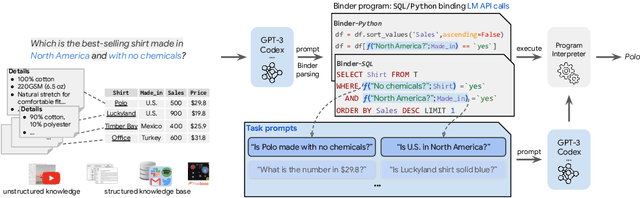
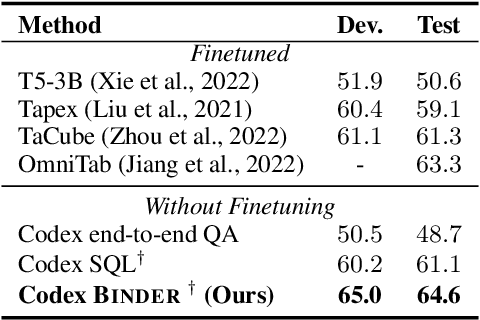

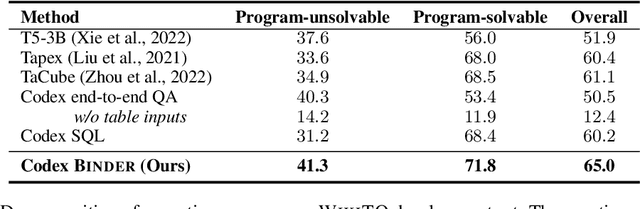
Though end-to-end neural approaches have recently been dominating NLP tasks in both performance and ease-of-use, they lack interpretability and robustness. We propose Binder, a training-free neural-symbolic framework that maps the task input to a program, which (1) allows binding a unified API of language model (LM) functionalities to a programming language (e.g., SQL, Python) to extend its grammar coverage and thus tackle more diverse questions, (2) adopts an LM as both the program parser and the underlying model called by the API during execution, and (3) requires only a few in-context exemplar annotations. Specifically, we employ GPT-3 Codex as the LM. In the parsing stage, with only a few in-context exemplars, Codex is able to identify the part of the task input that cannot be answerable by the original programming language, correctly generate API calls to prompt Codex to solve the unanswerable part, and identify where to place the API calls while being compatible with the original grammar. In the execution stage, Codex can perform versatile functionalities (e.g., commonsense QA, information extraction) given proper prompts in the API calls. Binder achieves state-of-the-art results on WikiTableQuestions and TabFact datasets, with explicit output programs that benefit human debugging. Note that previous best systems are all finetuned on tens of thousands of task-specific samples, while Binder only uses dozens of annotations as in-context exemplars without any training. Our code is available at https://github.com/HKUNLP/Binder .