 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpected Validation Performance and Estimation of a Random Variable's Maximum
Oct 01, 2021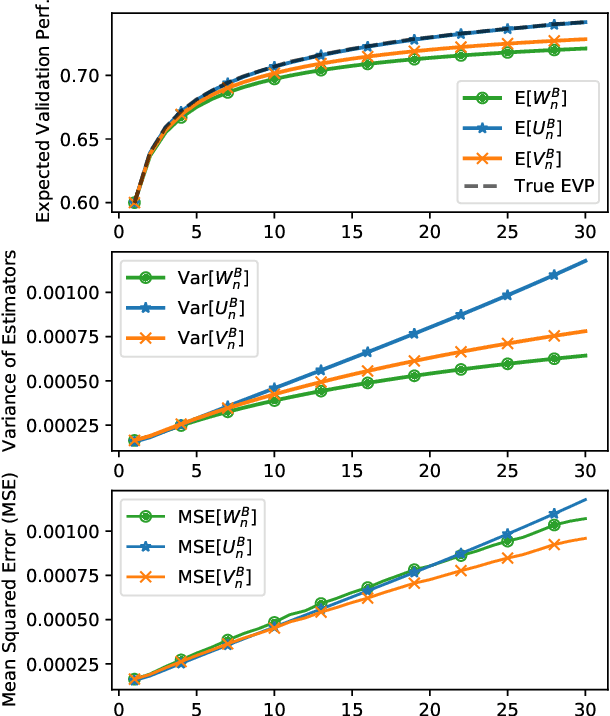
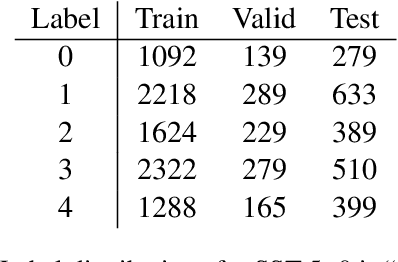
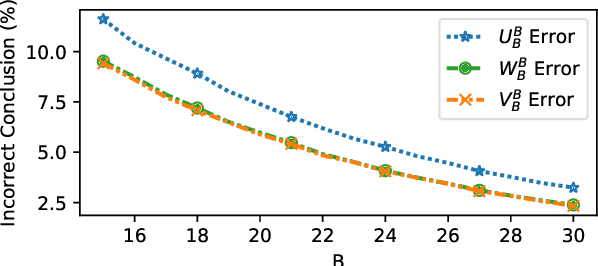
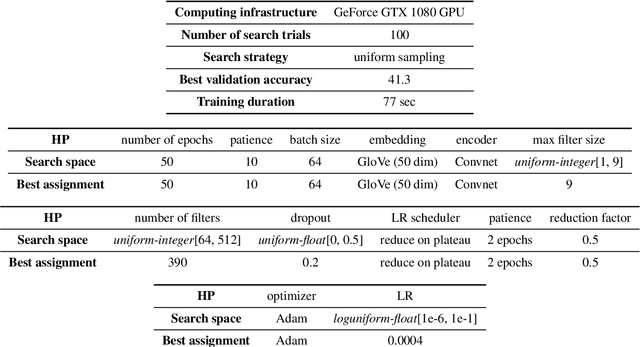
Research in NLP is often supported by experimental results, and improved reporting of such results can lead to better understanding and more reproducible science. In this paper we analyze three statistical estimators for expected validation performance, a tool used for reporting performance (e.g., accuracy) as a function of computational budget (e.g., number of hyperparameter tuning experiments). Where previous work analyzing such estimators focused on the bias, we also examine the variance and mean squared error (MSE). In both synthetic and realistic scenarios, we evaluate three estimators and find the unbiased estimator has the highest variance, and the estimator with the smallest variance has the largest bias; the estimator with the smallest MSE strikes a balance between bias and variance, displaying a classic bias-variance tradeoff. We use expected validation performance to compare between different models, and analyze how frequently each estimator leads to drawing incorrect conclusions about which of two models performs best. We find that the two biased estimators lead to the fewest incorrect conclusions, which hints at the importance of minimizing variance and MSE.
Sentence Bottleneck Autoencoders from Transformer Language Models
Aug 31, 2021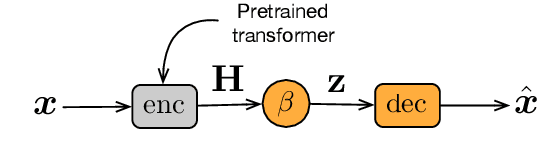
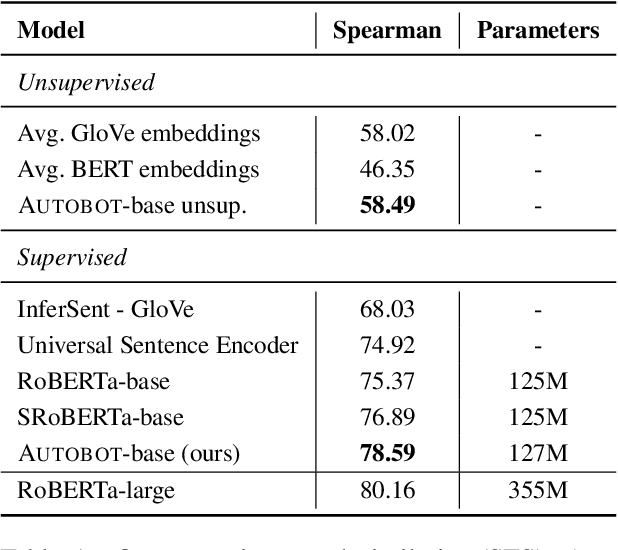
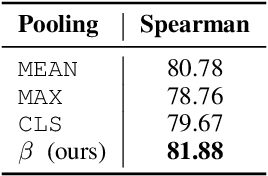
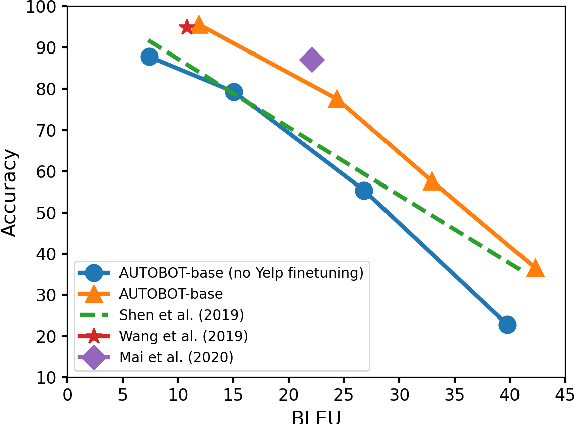
Representation learning for text via pretraining a language model on a large corpus has become a standard starting point for building NLP systems. This approach stands in contrast to autoencoders, also trained on raw text, but with the objective of learning to encode each input as a vector that allows full reconstruction. Autoencoders are attractive because of their latent space structure and generative properties. We therefore explore the construction of a sentence-level autoencoder from a pretrained, frozen transformer language model. We adapt the masked language modeling objective as a generative, denoising one, while only training a sentence bottleneck and a single-layer modified transformer decoder. We demonstrate that the sentence representations discovered by our model achieve better quality than previous methods that extract representations from pretrained transformers on text similarity tasks, style transfer (an example of controlled generation), and single-sentence classification tasks in the GLUE benchmark, while using fewer parameters than large pretrained models.
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
Aug 27, 2021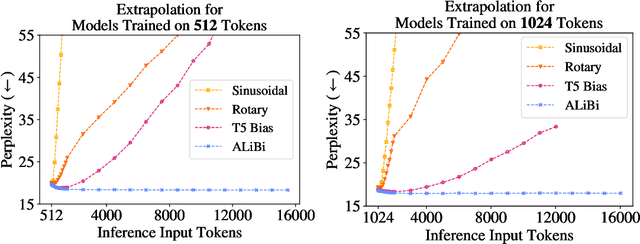
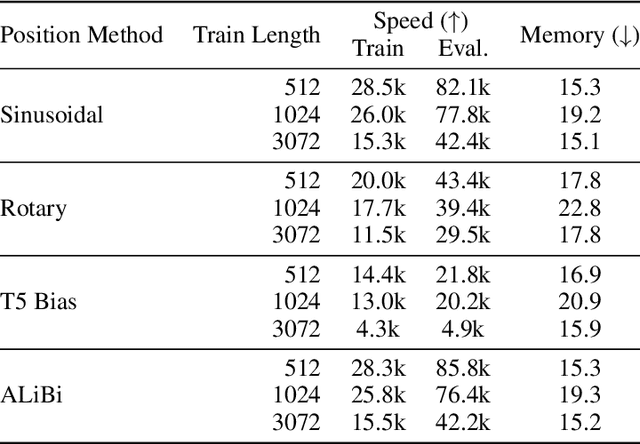

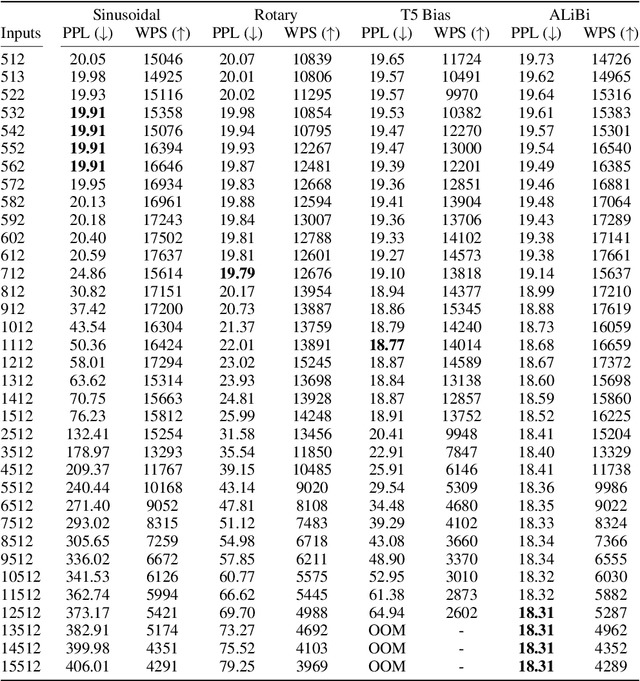
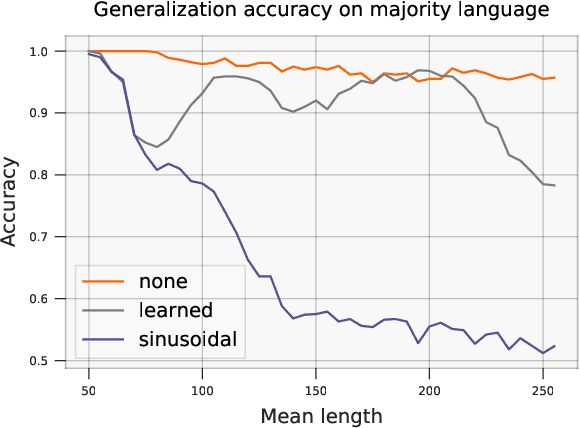
Since the introduction of the transformer model by Vaswani et al. (2017), a fundamental question remains open: how to achieve extrapolation at inference time to longer sequences than seen during training? We first show that extrapolation can be improved by changing the position representation method, though we find that existing proposals do not allow efficient extrapolation. We introduce a simple and efficient method, Attention with Linear Biases (ALiBi), that allows for extrapolation. ALiBi does not add positional embeddings to the word embeddings; instead, it biases the query-key attention scores with a term that is proportional to their distance. We show that this method allows training a 1.3 billion parameter model on input sequences of length 1024 that extrapolates to input sequences of length 2048, achieving the same perplexity as a sinusoidal position embedding model trained on inputs of length 2048, 11% faster and using 11% less memory. ALiBi's inductive bias towards recency allows it to outperform multiple strong position methods on the WikiText-103 benchmark. Finally, we provide analysis of ALiBi to understand why it leads to better performance.
DEMix Layers: Disentangling Domains for Modular Language Modeling
Aug 20, 2021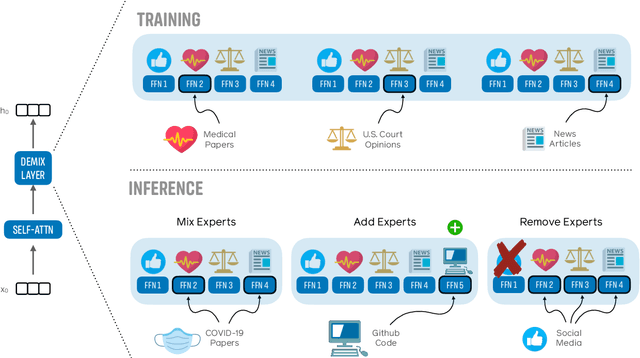
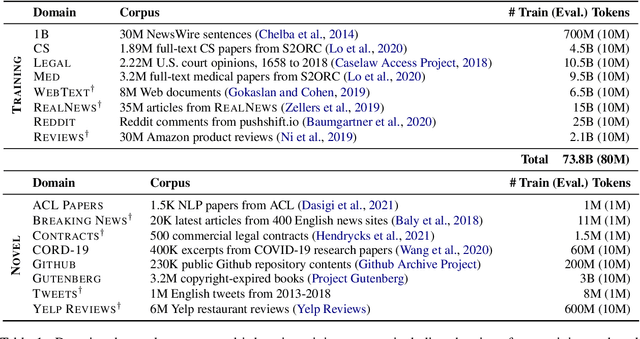
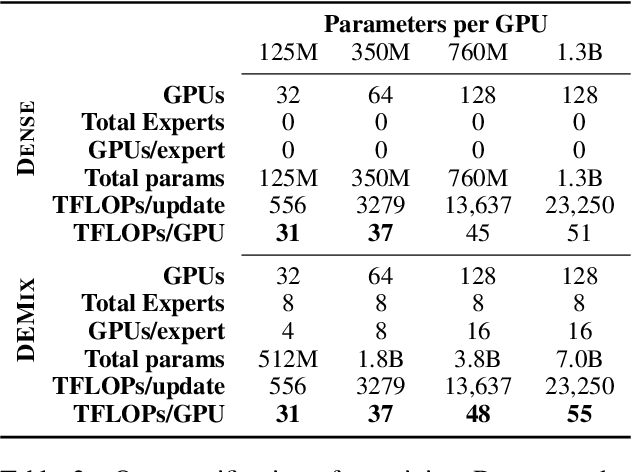
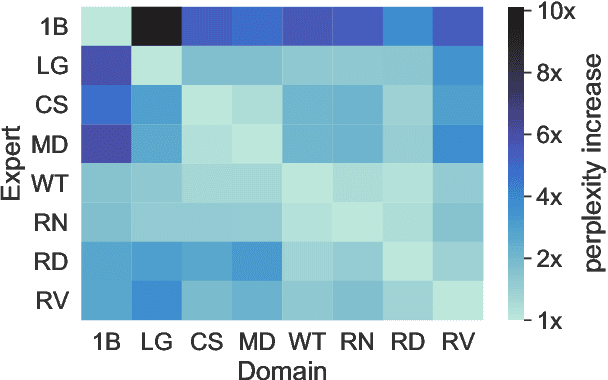
We introduce a new domain expert mixture (DEMix) layer that enables conditioning a language model (LM) on the domain of the input text. A DEMix layer is a collection of expert feedforward networks, each specialized to a domain, that makes the LM modular: experts can be mixed, added or removed after initial training. Extensive experiments with autoregressive transformer LMs (up to 1.3B parameters) show that DEMix layers reduce test-time perplexity, increase training efficiency, and enable rapid adaptation with little overhead. We show that mixing experts during inference, using a parameter-free weighted ensemble, allows the model to better generalize to heterogeneous or unseen domains. We also show that experts can be added to iteratively incorporate new domains without forgetting older ones, and that experts can be removed to restrict access to unwanted domains, without additional training. Overall, these results demonstrate benefits of explicitly conditioning on textual domains during language modeling.
All That's 'Human' Is Not Gold: Evaluating Human Evaluation of Generated Text
Jul 07, 2021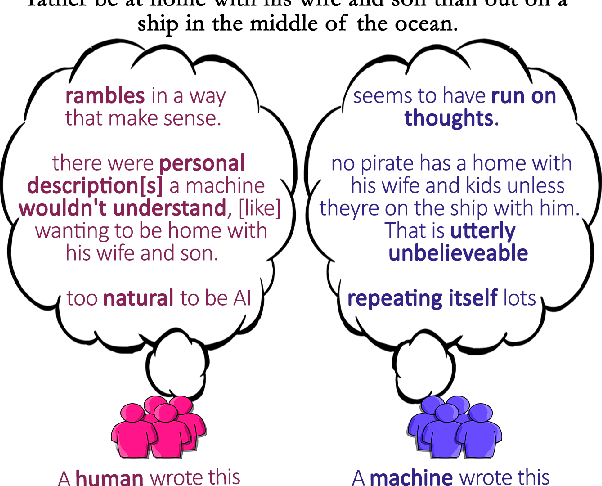
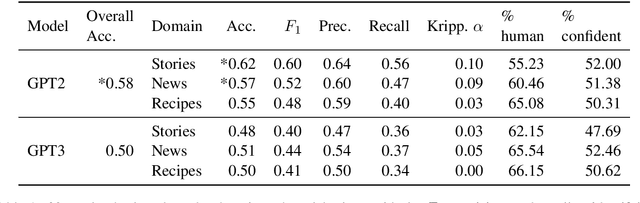

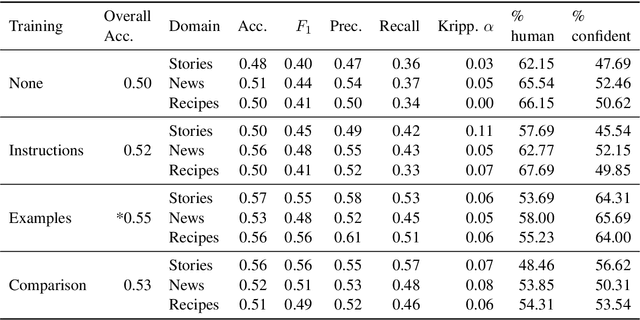
Human evaluations are typically considered the gold standard in natural language generation, but as models' fluency improves, how well can evaluators detect and judge machine-generated text? We run a study assessing non-experts' ability to distinguish between human- and machine-authored text (GPT2 and GPT3) in three domains (stories, news articles, and recipes). We find that, without training, evaluators distinguished between GPT3- and human-authored text at random chance level. We explore three approaches for quickly training evaluators to better identify GPT3-authored text (detailed instructions, annotated examples, and paired examples) and find that while evaluators' accuracy improved up to 55%, it did not significantly improve across the three domains. Given the inconsistent results across text domains and the often contradictory reasons evaluators gave for their judgments, we examine the role untrained human evaluations play in NLG evaluation and provide recommendations to NLG researchers for improving human evaluations of text generated from state-of-the-art models.
Scarecrow: A Framework for Scrutinizing Machine Text
Jul 06, 2021
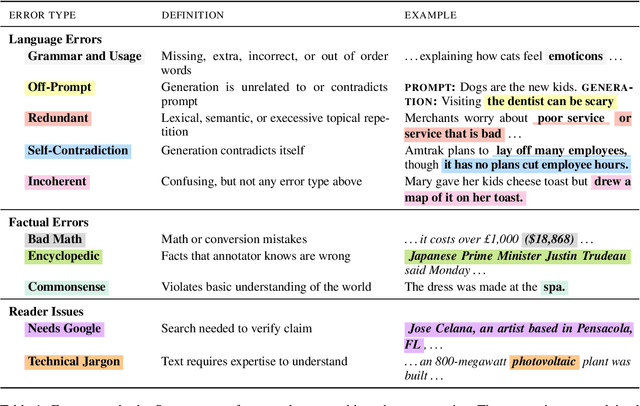
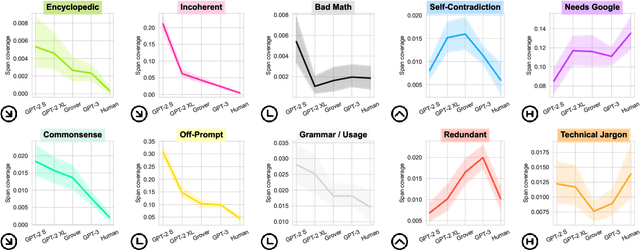
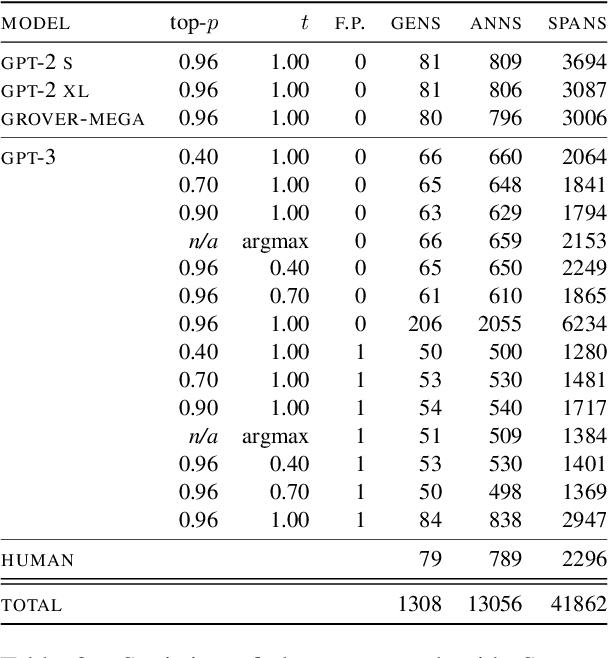
Modern neural text generation systems can produce remarkably fluent and grammatical texts. While earlier language models suffered from repetition and syntactic errors, the errors made by contemporary models are often semantic, narrative, or discourse failures. To facilitate research of these complex error types, we introduce a new structured, crowdsourced error annotation schema called Scarecrow. The error categories used in Scarecrow -- such as redundancy, commonsense errors, and incoherence -- were identified by combining expert analysis with several pilot rounds of ontology-free crowd annotation to arrive at a schema which covers the error phenomena found in real machine generated text. We use Scarecrow to collect 13k annotations of 1.3k human and machine generate paragraphs of English language news text, amounting to over 41k spans each labeled with its error category, severity, a natural language explanation, and antecedent span (where relevant). We collect annotations for text generated by state-of-the-art systems with varying known performance levels, from GPT-2 Small through the largest GPT-3. We isolate several factors for detailed analysis, including parameter count, training data, and decoding technique. Our results show both expected and surprising differences across these settings. These findings demonstrate the value of Scarecrow annotations in the assessment of current and future text generation systems. We release our complete annotation toolkit and dataset at https://yao-dou.github.io/scarecrow/.
On the Power of Saturated Transformers: A View from Circuit Complexity
Jun 30, 2021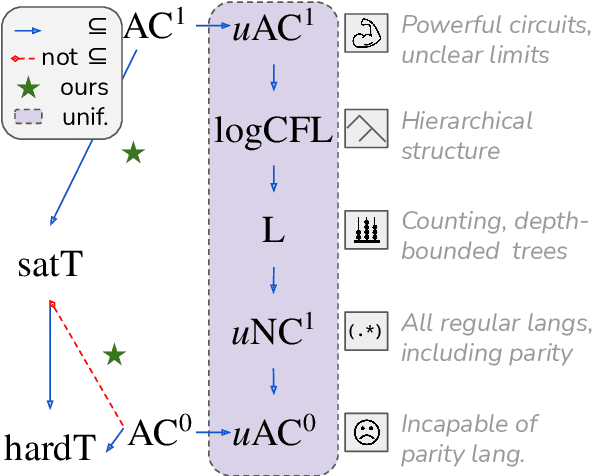
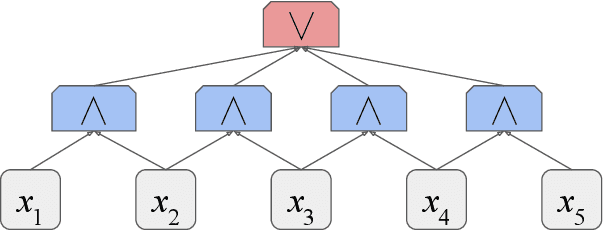

Transformers have become a standard architecture for many NLP problems. This has motivated theoretically analyzing their capabilities as models of language, in order to understand what makes them successful, and what their potential weaknesses might be. Recent work has shown that transformers with hard attention are quite limited in capacity, and in fact can be simulated by constant-depth circuits. However, hard attention is a restrictive assumption, which may complicate the relevance of these results for practical transformers. In this work, we analyze the circuit complexity of transformers with saturated attention: a generalization of hard attention that more closely captures the attention patterns learnable in practical transformers. We show that saturated transformers transcend the limitations of hard-attention transformers. With some minor assumptions, we prove that the number of bits needed to represent a saturated transformer memory vector is $O(\log n)$, which implies saturated transformers can be simulated by log-depth circuits. Thus, the jump from hard to saturated attention can be understood as increasing the transformer's effective circuit depth by a factor of $O(\log n)$.
Specializing Multilingual Language Models: An Empirical Study
Jun 22, 2021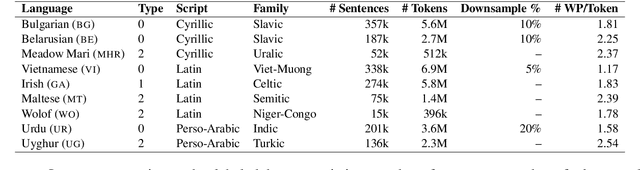
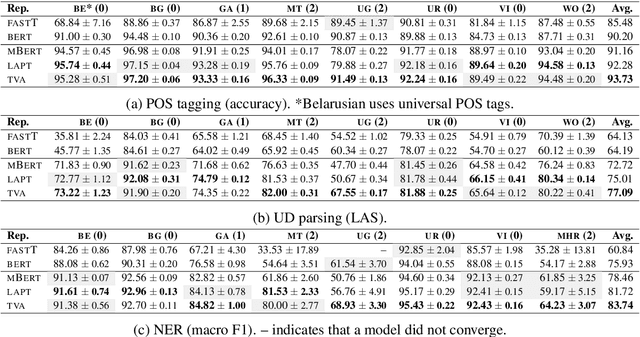
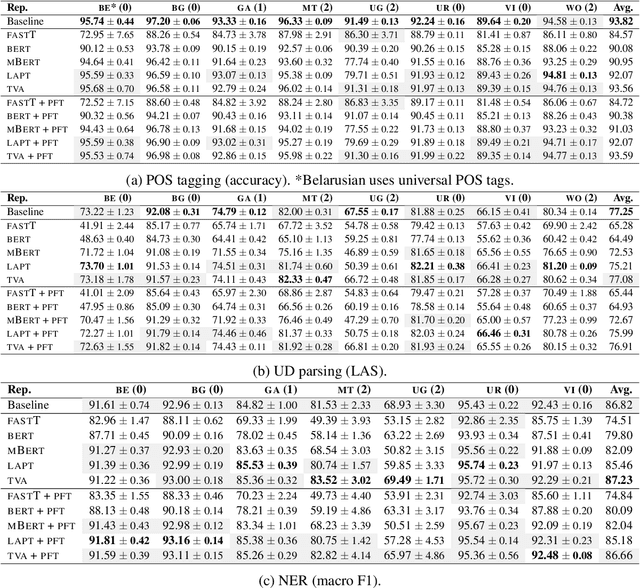

Contextualized word representations from pretrained multilingual language models have become the de facto standard for addressing natural language tasks in many different languages, but the success of this approach is far from universal. For languages rarely or never seen by these models, directly using such models often results in suboptimal representation or use of data, motivating additional model adaptations to achieve reasonably strong performance. In this work, we study the performance, extensibility, and interaction of two such adaptations for this low-resource setting: vocabulary augmentation and script transliteration. Our evaluations on a set of three tasks in nine diverse low-resource languages yield a mixed result, upholding the viability of these approaches while raising new questions around how to optimally adapt multilingual models to low-resource settings.
Scientific Language Models for Biomedical Knowledge Base Completion: An Empirical Study
Jun 17, 2021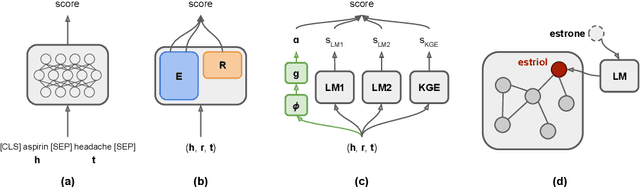
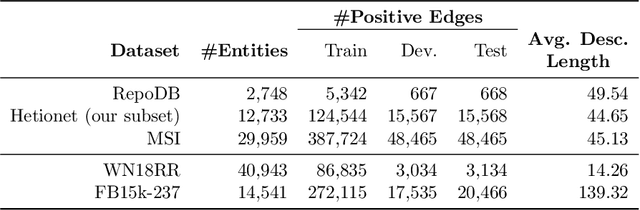
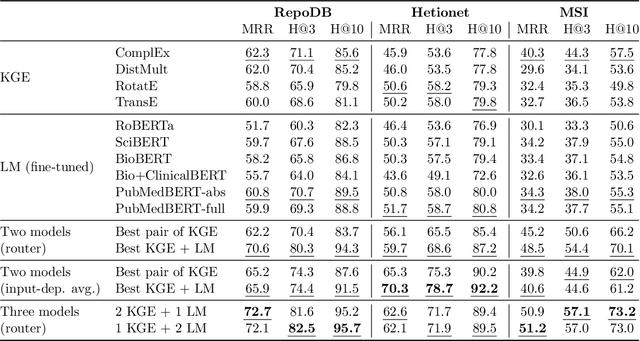
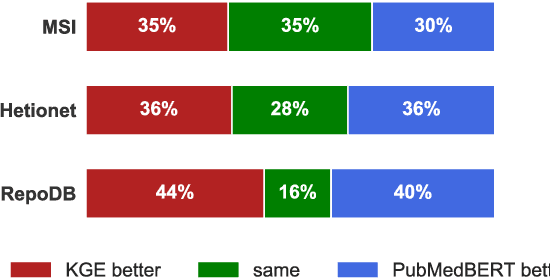
Biomedical knowledge graphs (KGs) hold rich information on entities such as diseases, drugs, and genes. Predicting missing links in these graphs can boost many important applications, such as drug design and repurposing. Recent work has shown that general-domain language models (LMs) can serve as "soft" KGs, and that they can be fine-tuned for the task of KG completion. In this work, we study scientific LMs for KG completion, exploring whether we can tap into their latent knowledge to enhance biomedical link prediction. We evaluate several domain-specific LMs, fine-tuning them on datasets centered on drugs and diseases that we represent as KGs and enrich with textual entity descriptions. We integrate the LM-based models with KG embedding models, using a router method that learns to assign each input example to either type of model and provides a substantial boost in performance. Finally, we demonstrate the advantage of LM models in the inductive setting with novel scientific entities. Our datasets and code are made publicly available.
DExperts: Decoding-Time Controlled Text Generation with Experts and Anti-Experts
Jun 03, 2021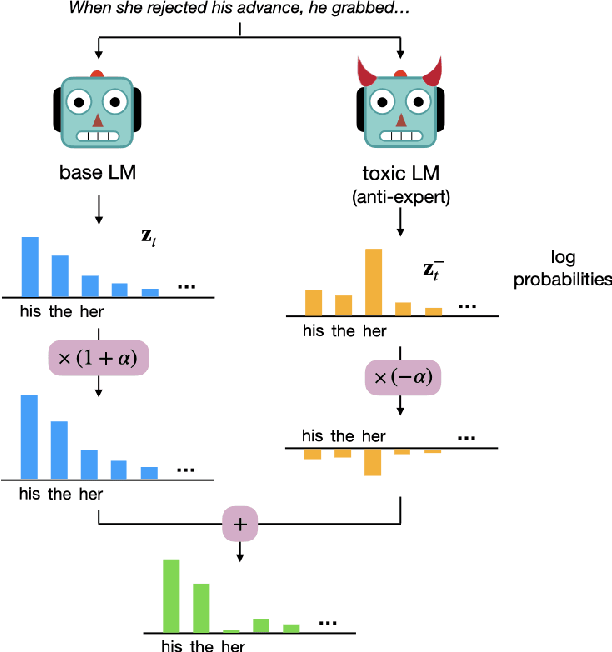
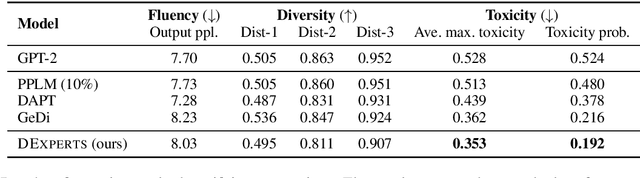
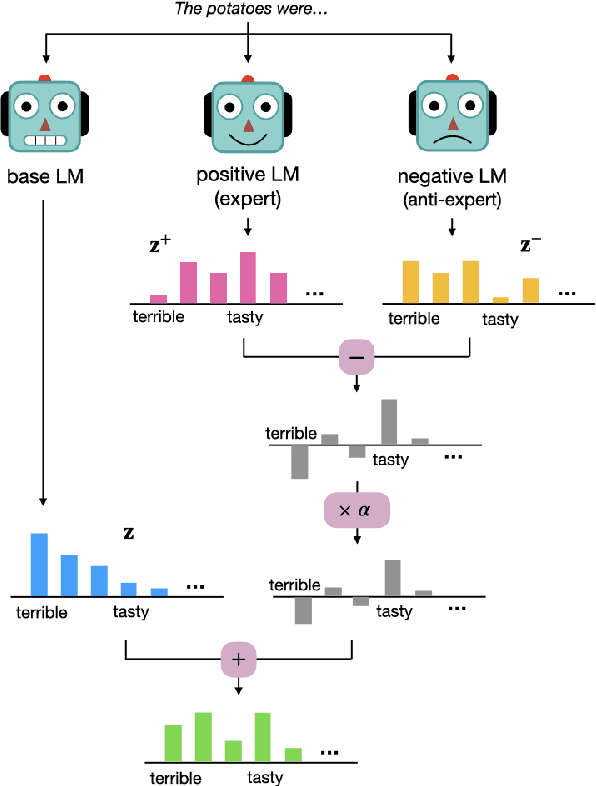
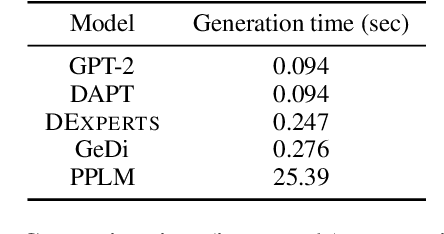
Despite recent advances in natural language generation, it remains challenging to control attributes of generated text. We propose DExperts: Decoding-time Experts, a decoding-time method for controlled text generation that combines a pretrained language model with "expert" LMs and/or "anti-expert" LMs in a product of experts. Intuitively, under the ensemble, tokens only get high probability if they are considered likely by the experts, and unlikely by the anti-experts. We apply DExperts to language detoxification and sentiment-controlled generation, where we outperform existing controllable generation methods on both automatic and human evaluations. Moreover, because DExperts operates only on the output of the pretrained LM, it is effective with (anti-)experts of smaller size, including when operating on GPT-3. Our work highlights the promise of tuning small LMs on text with (un)desirable attributes for efficient decoding-time steering.