 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD-REX: Differentiable Real-to-Sim-to-Real Engine for Learning Dexterous Grasping
Mar 01, 2026Simulation provides a cost-effective and flexible platform for data generation and policy learning to develop robotic systems. However, bridging the gap between simulation and real-world dynamics remains a significant challenge, especially in physical parameter identification. In this work, we introduce a real-to-sim-to-real engine that leverages the Gaussian Splat representations to build a differentiable engine, enabling object mass identification from real-world visual observations and robot control signals, while enabling grasping policy learning simultaneously. Through optimizing the mass of the manipulated object, our method automatically builds high-fidelity and physically plausible digital twins. Additionally, we propose a novel approach to train force-aware grasping policies from limited data by transferring feasible human demonstrations into simulated robot demonstrations. Through comprehensive experiments, we demonstrate that our engine achieves accurate and robust performance in mass identification across various object geometries and mass values. Those optimized mass values facilitate force-aware policy learning, achieving superior and high performance in object grasping, effectively reducing the sim-to-real gap.
CMPhysBench: A Benchmark for Evaluating Large Language Models in Condensed Matter Physics
Aug 25, 2025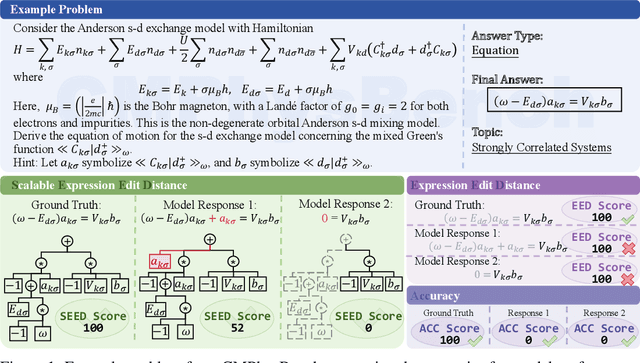
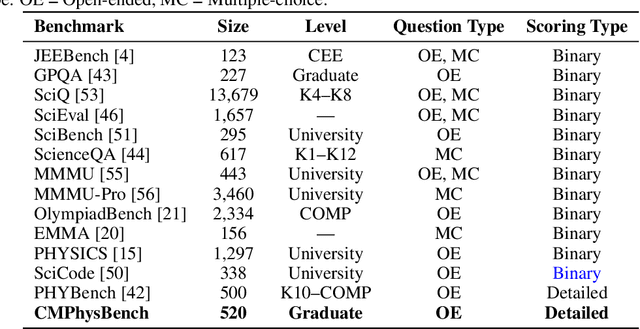
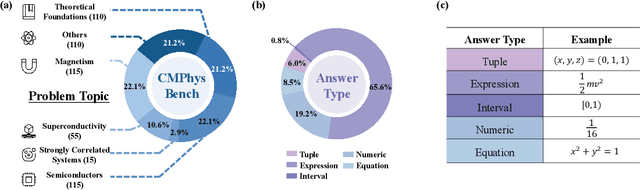

We introduce CMPhysBench, designed to assess the proficiency of Large Language Models (LLMs) in Condensed Matter Physics, as a novel Benchmark. CMPhysBench is composed of more than 520 graduate-level meticulously curated questions covering both representative subfields and foundational theoretical frameworks of condensed matter physics, such as magnetism, superconductivity, strongly correlated systems, etc. To ensure a deep understanding of the problem-solving process,we focus exclusively on calculation problems, requiring LLMs to independently generate comprehensive solutions. Meanwhile, leveraging tree-based representations of expressions, we introduce the Scalable Expression Edit Distance (SEED) score, which provides fine-grained (non-binary) partial credit and yields a more accurate assessment of similarity between prediction and ground-truth. Our results show that even the best models, Grok-4, reach only 36 average SEED score and 28% accuracy on CMPhysBench, underscoring a significant capability gap, especially for this practical and frontier domain relative to traditional physics. The code anddataset are publicly available at https://github.com/CMPhysBench/CMPhysBench.
Learning an Implicit Physics Model for Image-based Fluid Simulation
Aug 11, 2025Humans possess an exceptional ability to imagine 4D scenes, encompassing both motion and 3D geometry, from a single still image. This ability is rooted in our accumulated observations of similar scenes and an intuitive understanding of physics. In this paper, we aim to replicate this capacity in neural networks, specifically focusing on natural fluid imagery. Existing methods for this task typically employ simplistic 2D motion estimators to animate the image, leading to motion predictions that often defy physical principles, resulting in unrealistic animations. Our approach introduces a novel method for generating 4D scenes with physics-consistent animation from a single image. We propose the use of a physics-informed neural network that predicts motion for each surface point, guided by a loss term derived from fundamental physical principles, including the Navier-Stokes equations. To capture appearance, we predict feature-based 3D Gaussians from the input image and its estimated depth, which are then animated using the predicted motions and rendered from any desired camera perspective. Experimental results highlight the effectiveness of our method in producing physically plausible animations, showcasing significant performance improvements over existing methods. Our project page is https://physfluid.github.io/ .
Decision-based AI Visual Navigation for Cardiac Ultrasounds
Apr 16, 2025



Ultrasound imaging of the heart (echocardiography) is widely used to diagnose cardiac diseases. However, obtaining an echocardiogram requires an expert sonographer and a high-quality ultrasound imaging device, which are generally only available in hospitals. Recently, AI-based navigation models and algorithms have been used to aid novice sonographers in acquiring the standardized cardiac views necessary to visualize potential disease pathologies. These navigation systems typically rely on directional guidance to predict the necessary rotation of the ultrasound probe. This paper demonstrates a novel AI navigation system that builds on a decision model for identifying the inferior vena cava (IVC) of the heart. The decision model is trained offline using cardiac ultrasound videos and employs binary classification to determine whether the IVC is present in a given ultrasound video. The underlying model integrates a novel localization algorithm that leverages the learned feature representations to annotate the spatial location of the IVC in real-time. Our model demonstrates strong localization performance on traditional high-quality hospital ultrasound videos, as well as impressive zero-shot performance on lower-quality ultrasound videos from a more affordable Butterfly iQ handheld ultrasound machine. This capability facilitates the expansion of ultrasound diagnostics beyond hospital settings. Currently, the guidance system is undergoing clinical trials and is available on the Butterfly iQ app.
Skyeyes: Ground Roaming using Aerial View Images
Sep 25, 2024



Integrating aerial imagery-based scene generation into applications like autonomous driving and gaming enhances realism in 3D environments, but challenges remain in creating detailed content for occluded areas and ensuring real-time, consistent rendering. In this paper, we introduce Skyeyes, a novel framework that can generate photorealistic sequences of ground view images using only aerial view inputs, thereby creating a ground roaming experience. More specifically, we combine a 3D representation with a view consistent generation model, which ensures coherence between generated images. This method allows for the creation of geometrically consistent ground view images, even with large view gaps. The images maintain improved spatial-temporal coherence and realism, enhancing scene comprehension and visualization from aerial perspectives. To the best of our knowledge, there are no publicly available datasets that contain pairwise geo-aligned aerial and ground view imagery. Therefore, we build a large, synthetic, and geo-aligned dataset using Unreal Engine. Both qualitative and quantitative analyses on this synthetic dataset display superior results compared to other leading synthesis approaches. See the project page for more results: https://chaoren2357.github.io/website-skyeyes/.
Geometry-aware Feature Matching for Large-Scale Structure from Motion
Sep 03, 2024



Establishing consistent and dense correspondences across multiple images is crucial for Structure from Motion (SfM) systems. Significant view changes, such as air-to-ground with very sparse view overlap, pose an even greater challenge to the correspondence solvers. We present a novel optimization-based approach that significantly enhances existing feature matching methods by introducing geometry cues in addition to color cues. This helps fill gaps when there is less overlap in large-scale scenarios. Our method formulates geometric verification as an optimization problem, guiding feature matching within detector-free methods and using sparse correspondences from detector-based methods as anchor points. By enforcing geometric constraints via the Sampson Distance, our approach ensures that the denser correspondences from detector-free methods are geometrically consistent and more accurate. This hybrid strategy significantly improves correspondence density and accuracy, mitigates multi-view inconsistencies, and leads to notable advancements in camera pose accuracy and point cloud density. It outperforms state-of-the-art feature matching methods on benchmark datasets and enables feature matching in challenging extreme large-scale settings.