 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePBFormer: Capturing Complex Scene Text Shape with Polynomial Band Transformer
Aug 29, 2023



We present PBFormer, an efficient yet powerful scene text detector that unifies the transformer with a novel text shape representation Polynomial Band (PB). The representation has four polynomial curves to fit a text's top, bottom, left, and right sides, which can capture a text with a complex shape by varying polynomial coefficients. PB has appealing features compared with conventional representations: 1) It can model different curvatures with a fixed number of parameters, while polygon-points-based methods need to utilize a different number of points. 2) It can distinguish adjacent or overlapping texts as they have apparent different curve coefficients, while segmentation-based or points-based methods suffer from adhesive spatial positions. PBFormer combines the PB with the transformer, which can directly generate smooth text contours sampled from predicted curves without interpolation. A parameter-free cross-scale pixel attention (CPA) module is employed to highlight the feature map of a suitable scale while suppressing the other feature maps. The simple operation can help detect small-scale texts and is compatible with the one-stage DETR framework, where no postprocessing exists for NMS. Furthermore, PBFormer is trained with a shape-contained loss, which not only enforces the piecewise alignment between the ground truth and the predicted curves but also makes curves' positions and shapes consistent with each other. Without bells and whistles about text pre-training, our method is superior to the previous state-of-the-art text detectors on the arbitrary-shaped text datasets.
Self-distillation Regularized Connectionist Temporal Classification Loss for Text Recognition: A Simple Yet Effective Approach
Aug 21, 2023Text recognition methods are gaining rapid development. Some advanced techniques, e.g., powerful modules, language models, and un- and semi-supervised learning schemes, consecutively push the performance on public benchmarks forward. However, the problem of how to better optimize a text recognition model from the perspective of loss functions is largely overlooked. CTC-based methods, widely used in practice due to their good balance between performance and inference speed, still grapple with accuracy degradation. This is because CTC loss emphasizes the optimization of the entire sequence target while neglecting to learn individual characters. We propose a self-distillation scheme for CTC-based model to address this issue. It incorporates a framewise regularization term in CTC loss to emphasize individual supervision, and leverages the maximizing-a-posteriori of latent alignment to solve the inconsistency problem that arises in distillation between CTC-based models. We refer to the regularized CTC loss as Distillation Connectionist Temporal Classification (DCTC) loss. DCTC loss is module-free, requiring no extra parameters, longer inference lag, or additional training data or phases. Extensive experiments on public benchmarks demonstrate that DCTC can boost text recognition model accuracy by up to 2.6%, without any of these drawbacks.
Large Language Models can be Guided to Evade AI-Generated Text Detection
May 19, 2023



Large Language Models (LLMs) have demonstrated exceptional performance in a variety of tasks, including essay writing and question answering. However, it is crucial to address the potential misuse of these models, which can lead to detrimental outcomes such as plagiarism and spamming. Recently, several detectors have been proposed, including fine-tuned classifiers and various statistical methods. In this study, we reveal that with the aid of carefully crafted prompts, LLMs can effectively evade these detection systems. We propose a novel Substitution-based In-Context example Optimization method (SICO) to automatically generate such prompts. On three real-world tasks where LLMs can be misused, SICO successfully enables ChatGPT to evade six existing detectors, causing a significant 0.54 AUC drop on average. Surprisingly, in most cases these detectors perform even worse than random classifiers. These results firmly reveal the vulnerability of existing detectors. Finally, the strong performance of SICO suggests itself as a reliable evaluation protocol for any new detector in this field.
ICDAR 2023 Competition on Reading the Seal Title
Apr 24, 2023Reading seal title text is a challenging task due to the variable shapes of seals, curved text, background noise, and overlapped text. However, this important element is commonly found in official and financial scenarios, and has not received the attention it deserves in the field of OCR technology. To promote research in this area, we organized ICDAR 2023 competition on reading the seal title (ReST), which included two tasks: seal title text detection (Task 1) and end-to-end seal title recognition (Task 2). We constructed a dataset of 10,000 real seal data, covering the most common classes of seals, and labeled all seal title texts with text polygons and text contents. The competition opened on 30th December, 2022 and closed on 20th March, 2023. The competition attracted 53 participants from academia and industry including 28 submissions for Task 1 and 25 submissions for Task 2, which demonstrated significant interest in this challenging task. In this report, we present an overview of the competition, including the organization, challenges, and results. We describe the dataset and tasks, and summarize the submissions and evaluation results. The results show that significant progress has been made in the field of seal title text reading, and we hope that this competition will inspire further research and development in this important area of OCR technology.
Improving Table Structure Recognition with Visual-Alignment Sequential Coordinate Modeling
Mar 20, 2023



Table structure recognition aims to extract the logical and physical structure of unstructured table images into a machine-readable format. The latest end-to-end image-to-text approaches simultaneously predict the two structures by two decoders, where the prediction of the physical structure (the bounding boxes of the cells) is based on the representation of the logical structure. However, the previous methods struggle with imprecise bounding boxes as the logical representation lacks local visual information. To address this issue, we propose an end-to-end sequential modeling framework for table structure recognition called VAST. It contains a novel coordinate sequence decoder triggered by the representation of the non-empty cell from the logical structure decoder. In the coordinate sequence decoder, we model the bounding box coordinates as a language sequence, where the left, top, right and bottom coordinates are decoded sequentially to leverage the inter-coordinate dependency. Furthermore, we propose an auxiliary visual-alignment loss to enforce the logical representation of the non-empty cells to contain more local visual details, which helps produce better cell bounding boxes. Extensive experiments demonstrate that our proposed method can achieve state-of-the-art results in both logical and physical structure recognition. The ablation study also validates that the proposed coordinate sequence decoder and the visual-alignment loss are the keys to the success of our method.
Digital Twin-Assisted Knowledge Distillation Framework for Heterogeneous Federated Learning
Mar 10, 2023



In this paper, to deal with the heterogeneity in federated learning (FL) systems, a knowledge distillation (KD) driven training framework for FL is proposed, where each user can select its neural network model on demand and distill knowledge from a big teacher model using its own private dataset. To overcome the challenge of train the big teacher model in resource limited user devices, the digital twin (DT) is exploit in the way that the teacher model can be trained at DT located in the server with enough computing resources. Then, during model distillation, each user can update the parameters of its model at either the physical entity or the digital agent. The joint problem of model selection and training offloading and resource allocation for users is formulated as a mixed integer programming (MIP) problem. To solve the problem, Q-learning and optimization are jointly used, where Q-learning selects models for users and determines whether to train locally or on the server, and optimization is used to allocate resources for users based on the output of Q-learning. Simulation results show the proposed DT-assisted KD framework and joint optimization method can significantly improve the average accuracy of users while reducing the total delay.
Less is More: Understanding Word-level Textual Adversarial Attack via n-gram Frequency Descend
Feb 07, 2023



Word-level textual adversarial attacks have achieved striking performance in fooling natural language processing models. However, the fundamental questions of why these attacks are effective, and the intrinsic properties of the adversarial examples (AEs), are still not well understood. This work attempts to interpret textual attacks through the lens of $n$-gram frequency. Specifically, it is revealed that existing word-level attacks exhibit a strong tendency toward generation of examples with $n$-gram frequency descend ($n$-FD). Intuitively, this finding suggests a natural way to improve model robustness by training the model on the $n$-FD examples. To verify this idea, we devise a model-agnostic and gradient-free AE generation approach that relies solely on the $n$-gram frequency information, and further integrate it into the recently proposed convex hull framework for adversarial training. Surprisingly, the resultant method performs quite similarly to the original gradient-based method in terms of model robustness. These findings provide a human-understandable perspective for interpreting word-level textual adversarial attacks, and a new direction to improve model robustness.
Load Profile Inpainting for Missing Load Data Restoration and Baseline Estimation
Nov 29, 2022



This paper introduces a Generative Adversarial Nets (GAN) based, Load Profile Inpainting Network (Load-PIN) for restoring missing load data segments and estimating the baseline for a demand response event. The inputs are time series load data before and after the inpainting period together with explanatory variables (e.g., weather data). We propose a Generator structure consisting of a coarse network and a fine-tuning network. The coarse network provides an initial estimation of the data segment in the inpainting period. The fine-tuning network consists of self-attention blocks and gated convolution layers for adjusting the initial estimations. Loss functions are specially designed for the fine-tuning and the discriminator networks to enhance both the point-to-point accuracy and realisticness of the results. We test the Load-PIN on three real-world data sets for two applications: patching missing data and deriving baselines of conservation voltage reduction (CVR) events. We benchmark the performance of Load-PIN with five existing deep-learning methods. Our simulation results show that, compared with the state-of-the-art methods, Load-PIN can handle varying-length missing data events and achieve 15-30% accuracy improvement.
SigT: An Efficient End-to-End MIMO-OFDM Receiver Framework Based on Transformer
Nov 02, 2022Multiple-input multiple-output and orthogonal frequency-division multiplexing (MIMO-OFDM) are the key technologies in 4G and subsequent wireless communication systems. Conventionally, the MIMO-OFDM receiver is performed by multiple cascaded blocks with different functions and the algorithm in each block is designed based on ideal assumptions of wireless channel distributions. However, these assumptions may fail in practical complex wireless environments. The deep learning (DL) method has the ability to capture key features from complex and huge data. In this paper, a novel end-to-end MIMO-OFDM receiver framework based on \textit{transformer}, named SigT, is proposed. By regarding the signal received from each antenna as a token of the transformer, the spatial correlation of different antennas can be learned and the critical zero-shot problem can be mitigated. Furthermore, the proposed SigT framework can work well without the inserted pilots, which improves the useful data transmission efficiency. Experiment results show that SigT achieves much higher performance in terms of signal recovery accuracy than benchmark methods, even in a low SNR environment or with a small number of training samples. Code is available at https://github.com/SigTransformer/SigT.
MultiLoad-GAN: A GAN-Based Synthetic Load Group Generation Method Considering Spatial-Temporal Correlations
Oct 03, 2022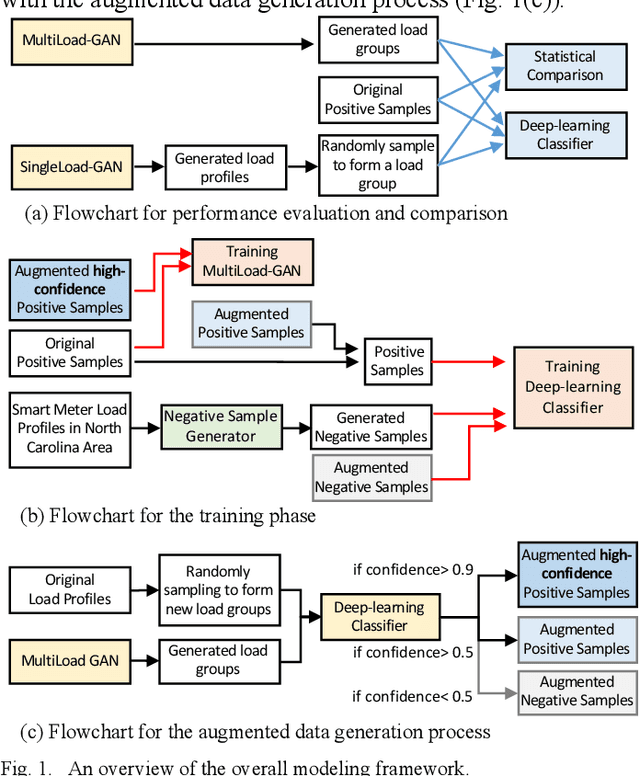
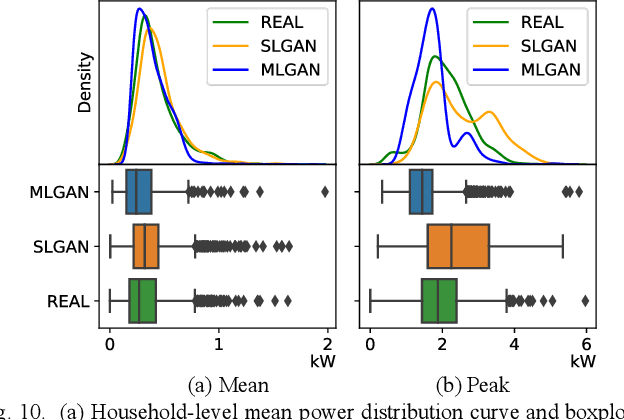
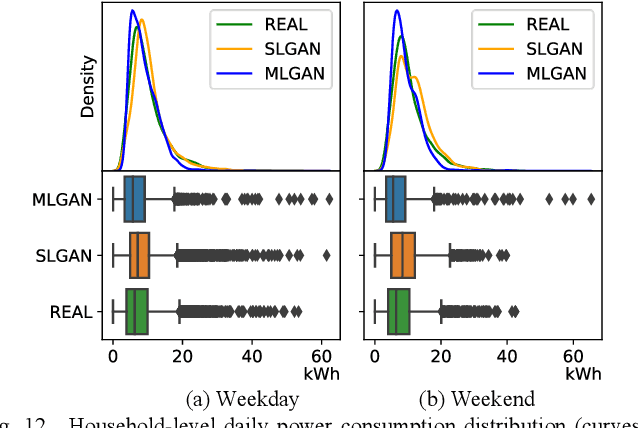
This paper presents a deep-learning framework, Multi-load Generative Adversarial Network (MultiLoad-GAN), for generating a group of load profiles in one shot. The main contribution of MultiLoad-GAN is the capture of spatial-temporal correlations among a group of loads to enable the generation of realistic synthetic load profiles in large quantity for meeting the emerging need in distribution system planning. The novelty and uniqueness of the MultiLoad-GAN framework are three-fold. First, it generates a group of load profiles bearing realistic spatial-temporal correlations in one shot. Second, two complementary metrics for evaluating realisticness of generated load profiles are developed: statistics metrics based on domain knowledge and a deep-learning classifier for comparing high-level features. Third, to tackle data scarcity, a novel iterative data augmentation mechanism is developed to generate training samples for enhancing the training of both the classifier and the MultiLoad-GAN model. Simulation results show that MultiLoad-GAN outperforms state-of-the-art approaches in realisticness, computational efficiency, and robustness. With little finetuning, the MultiLoad-GAN approach can be readily extended to generate a group of load or PV profiles for a feeder, a substation, or a service area.