 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink about it! Improving defeasible reasoning by first modeling the question scenario
Oct 24, 2021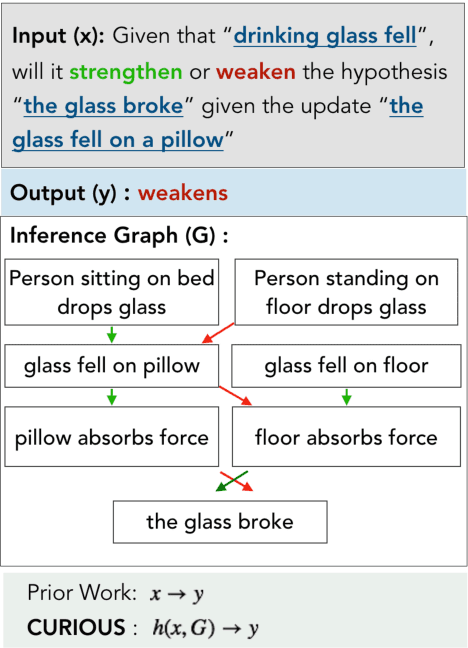
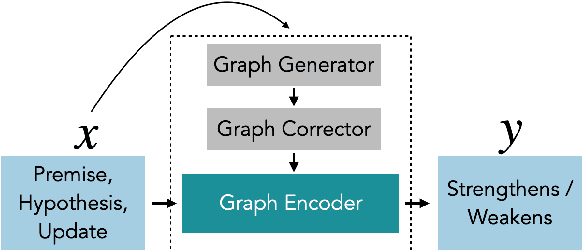
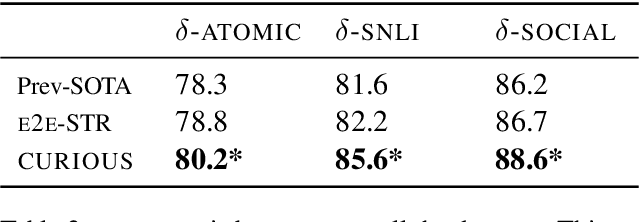
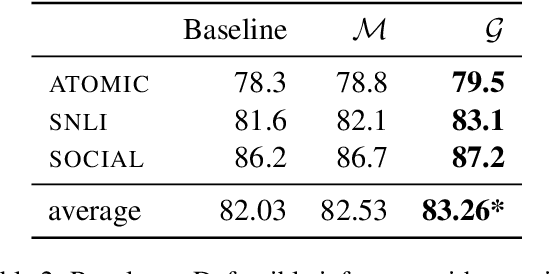
Defeasible reasoning is the mode of reasoning where conclusions can be overturned by taking into account new evidence. Existing cognitive science literature on defeasible reasoning suggests that a person forms a mental model of the problem scenario before answering questions. Our research goal asks whether neural models can similarly benefit from envisioning the question scenario before answering a defeasible query. Our approach is, given a question, to have a model first create a graph of relevant influences, and then leverage that graph as an additional input when answering the question. Our system, CURIOUS, achieves a new state-of-the-art on three different defeasible reasoning datasets. This result is significant as it illustrates that performance can be improved by guiding a system to "think about" a question and explicitly model the scenario, rather than answering reflexively. Code, data, and pre-trained models are located at https://github.com/madaan/thinkaboutit.
Could you give me a hint? Generating inference graphs for defeasible reasoning
May 29, 2021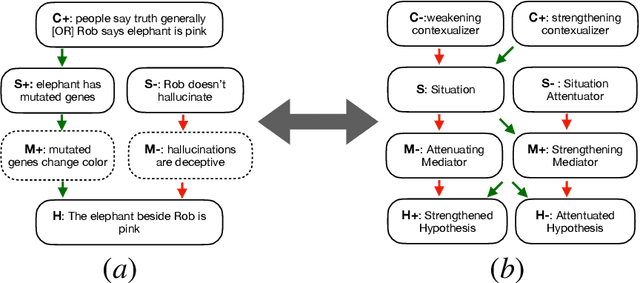

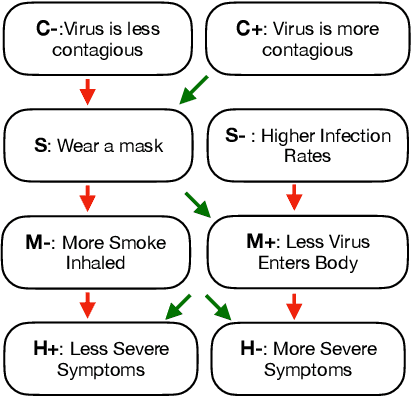

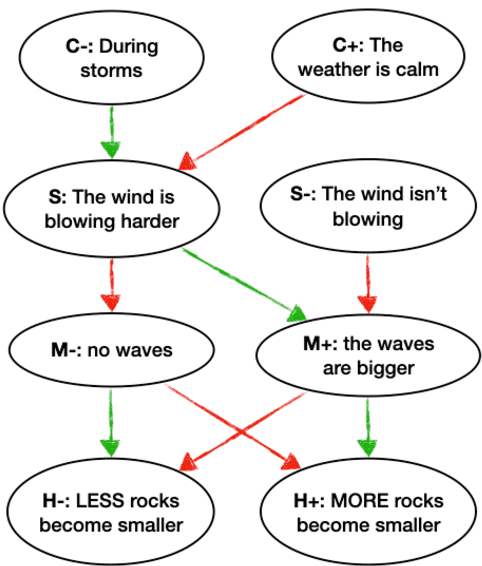
Defeasible reasoning is the mode of reasoning where conclusions can be overturned by taking into account new evidence. A commonly used method in cognitive science and logic literature is to handcraft argumentation supporting inference graphs. While humans find inference graphs very useful for reasoning, constructing them at scale is difficult. In this paper, we automatically generate such inference graphs through transfer learning from another NLP task that shares the kind of reasoning that inference graphs support. Through automated metrics and human evaluation, we find that our method generates meaningful graphs for the defeasible inference task. Human accuracy on this task improves by 20% by consulting the generated graphs. Our findings open up exciting new research avenues for cases where machine reasoning can help human reasoning. (A dataset of 230,000 influence graphs for each defeasible query is located at: https://tinyurl.com/defeasiblegraphs.)
Improving Neural Model Performance through Natural Language Feedback on Their Explanations
Apr 18, 2021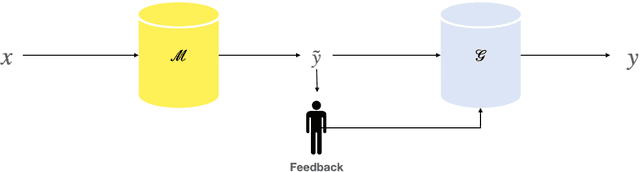
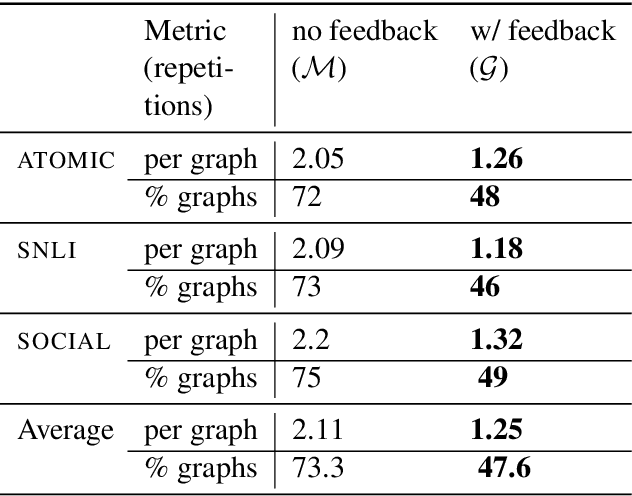
A class of explainable NLP models for reasoning tasks support their decisions by generating free-form or structured explanations, but what happens when these supporting structures contain errors? Our goal is to allow users to interactively correct explanation structures through natural language feedback. We introduce MERCURIE - an interactive system that refines its explanations for a given reasoning task by getting human feedback in natural language. Our approach generates graphs that have 40% fewer inconsistencies as compared with the off-the-shelf system. Further, simply appending the corrected explanation structures to the output leads to a gain of 1.2 points on accuracy on defeasible reasoning across all three domains. We release a dataset of over 450k graphs for defeasible reasoning generated by our system at https://tinyurl.com/mercurie .
proScript: Partially Ordered Scripts Generation via Pre-trained Language Models
Apr 16, 2021
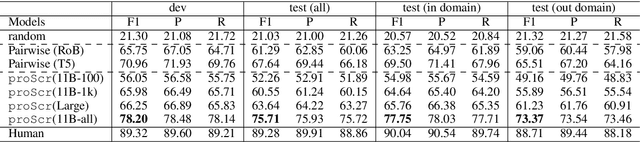
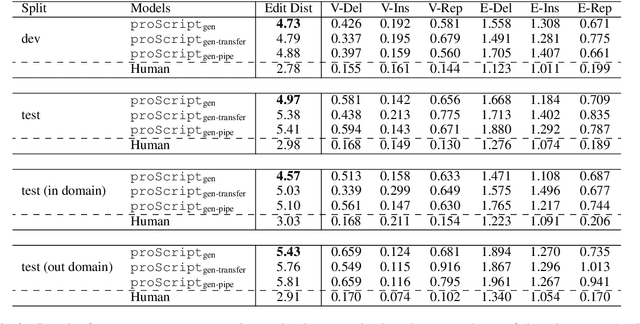
Scripts - standardized event sequences describing typical everyday activities - have been shown to help understand narratives by providing expectations, resolving ambiguity, and filling in unstated information. However, to date they have proved hard to author or extract from text. In this work, we demonstrate for the first time that pre-trained neural language models (LMs) can be be finetuned to generate high-quality scripts, at varying levels of granularity, for a wide range of everyday scenarios (e.g., bake a cake). To do this, we collected a large (6.4k), crowdsourced partially ordered scripts (named proScript), which is substantially larger than prior datasets, and developed models that generate scripts with combining language generation and structure prediction. We define two complementary tasks: (i) edge prediction: given a scenario and unordered events, organize the events into a valid (possibly partial-order) script, and (ii) script generation: given only a scenario, generate events and organize them into a (possibly partial-order) script. Our experiments show that our models perform well (e.g., F1=75.7 in task (i)), illustrating a new approach to overcoming previous barriers to script collection. We also show that there is still significant room for improvement toward human level performance. Together, our tasks, dataset, and models offer a new research direction for learning script knowledge.
CURIE: An Iterative Querying Approach for Reasoning About Situations
Apr 05, 2021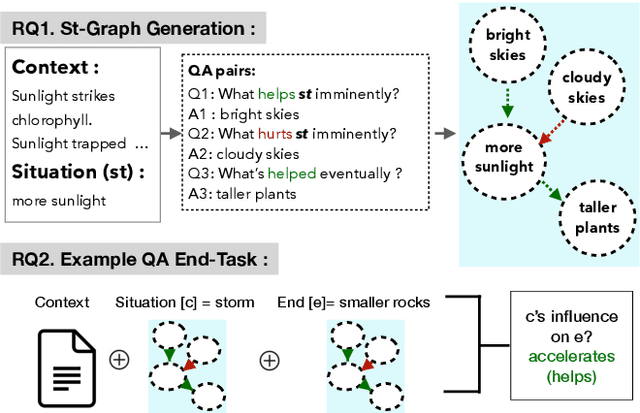
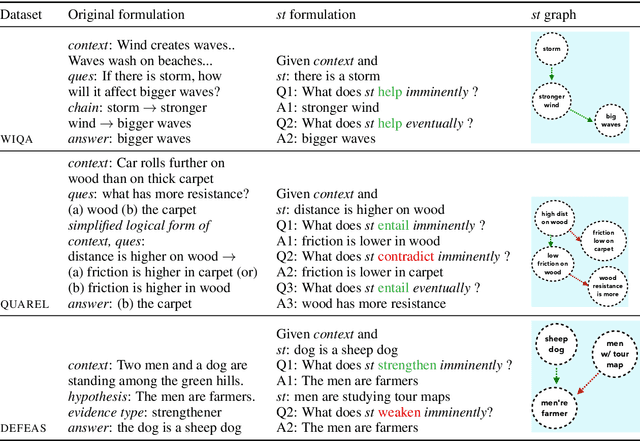
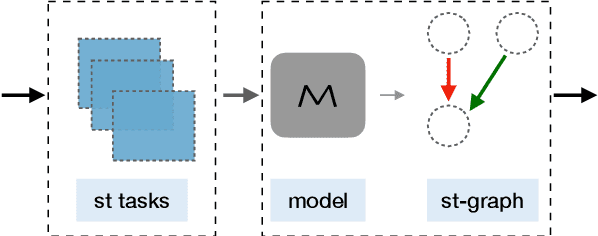
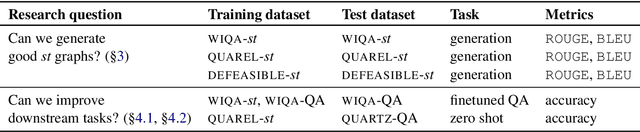
Recently, models have been shown to predict the effects of unexpected situations, e.g., would cloudy skies help or hinder plant growth? Given a context, the goal of such situational reasoning is to elicit the consequences of a new situation (st) that arises in that context. We propose a method to iteratively build a graph of relevant consequences explicitly in a structured situational graph (st-graph) using natural language queries over a finetuned language model (M). Across multiple domains, CURIE generates st-graphs that humans find relevant and meaningful in eliciting the consequences of a new situation. We show that st-graphs generated by CURIE improve a situational reasoning end task (WIQA-QA) by 3 points on accuracy by simply augmenting their input with our generated situational graphs, especially for a hard subset that requires background knowledge and multi-hop reasoning.
A Dataset for Tracking Entities in Open Domain Procedural Text
Oct 31, 2020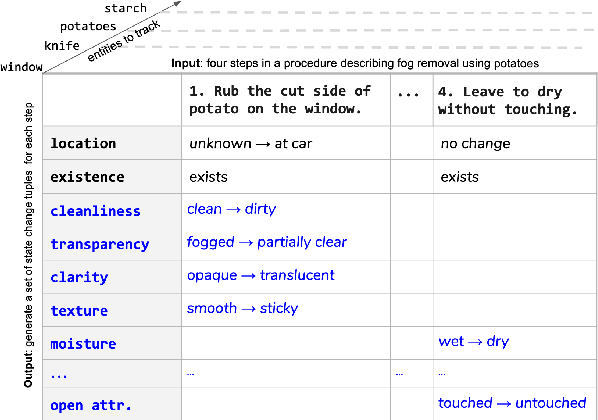
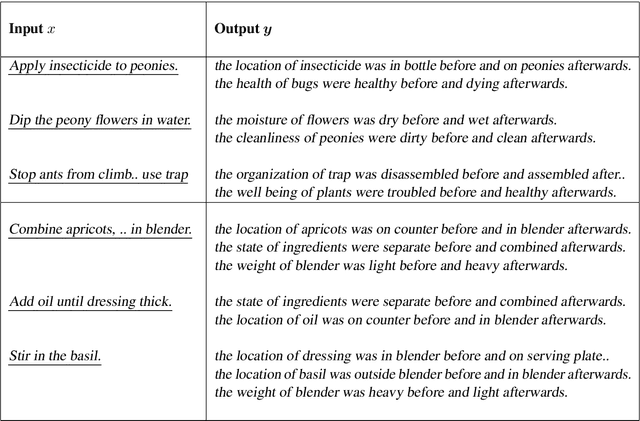
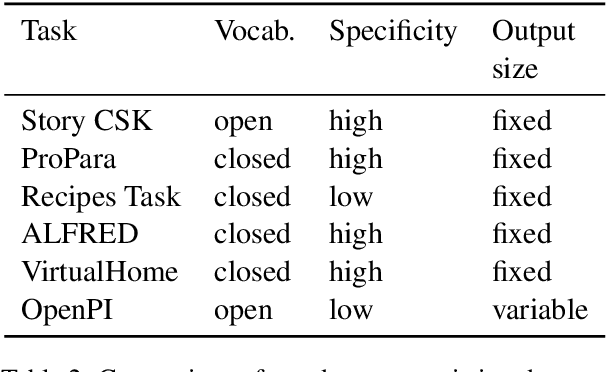

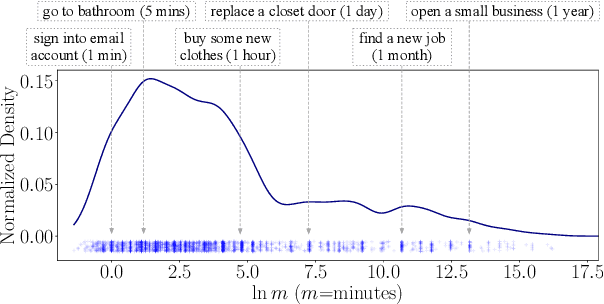
We present the first dataset for tracking state changes in procedural text from arbitrary domains by using an unrestricted (open) vocabulary. For example, in a text describing fog removal using potatoes, a car window may transition between being foggy, sticky,opaque, and clear. Previous formulations of this task provide the text and entities involved,and ask how those entities change for just a small, pre-defined set of attributes (e.g., location), limiting their fidelity. Our solution is a new task formulation where given just a procedural text as input, the task is to generate a set of state change tuples(entity, at-tribute, before-state, after-state)for each step,where the entity, attribute, and state values must be predicted from an open vocabulary. Using crowdsourcing, we create OPENPI1, a high-quality (91.5% coverage as judged by humans and completely vetted), and large-scale dataset comprising 29,928 state changes over 4,050 sentences from 810 procedural real-world paragraphs from WikiHow.com. A current state-of-the-art generation model on this task achieves 16.1% F1 based on BLEU metric, leaving enough room for novel model architectures.
Do Dogs have Whiskers? A New Knowledge Base of hasPart Relations
Jun 12, 2020

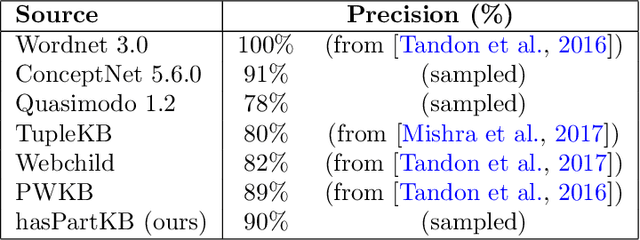
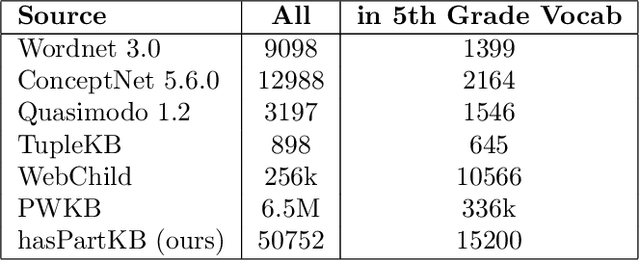
We present a new knowledge-base of hasPart relationships, extracted from a large corpus of generic statements. Complementary to other resources available, it is the first which is all three of: accurate (90% precision), salient (covers relationships a person may mention), and has high coverage of common terms (approximated as within a 10 year old's vocabulary), as well as having several times more hasPart entries than in the popular ontologies ConceptNet and WordNet. In addition, it contains information about quantifiers, argument modifiers, and links the entities to appropriate concepts in Wikipedia and WordNet. The knowledge base is available at https://allenai.org/data/haspartkb
What-if I ask you to explain: Explaining the effects of perturbations in procedural text
May 04, 2020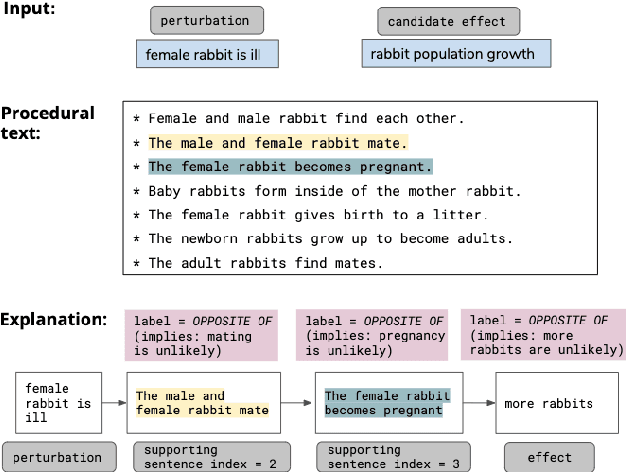
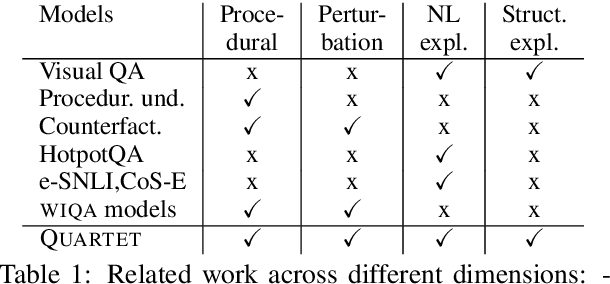

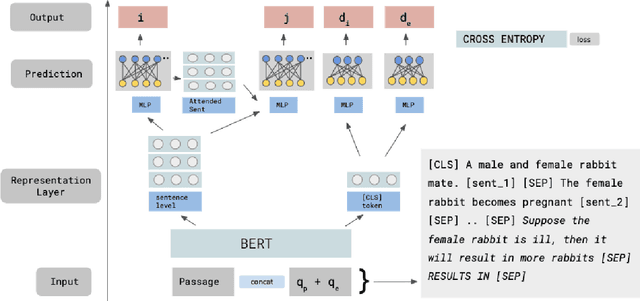
We address the task of explaining the effects of perturbations in procedural text, an important test of process comprehension. Consider a passage describing a rabbit's life-cycle: humans can easily explain the effect on the rabbit population if a female rabbit becomes ill -- i.e., the female rabbit would not become pregnant, and as a result not have babies leading to a decrease in rabbit population. We present QUARTET, a system that constructs such explanations from paragraphs, by modeling the explanation task as a multitask learning problem. QUARTET provides better explanations (based on the sentences in the procedural text) compared to several strong baselines on a recent process comprehension benchmark. We also present a surprising secondary effect: our model also achieves a new SOTA with a 7% absolute F1 improvement on a downstream QA task. This illustrates that good explanations do not have to come at the expense of end task performance.
Everything Happens for a Reason: Discovering the Purpose of Actions in Procedural Text
Sep 18, 2019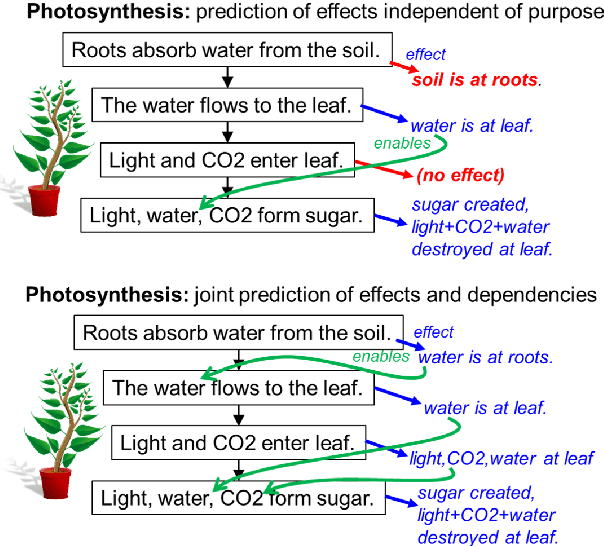
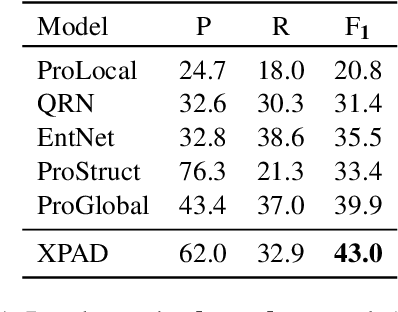
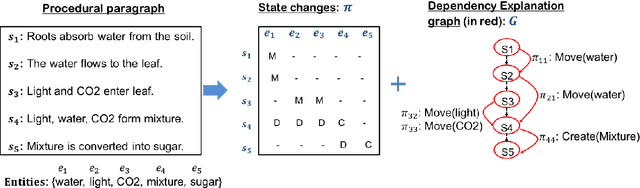
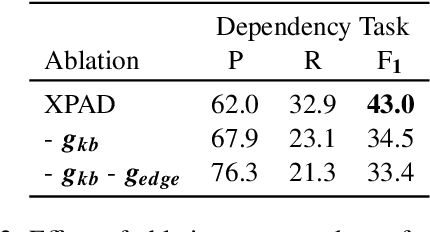
Our goal is to better comprehend procedural text, e.g., a paragraph about photosynthesis, by not only predicting what happens, but why some actions need to happen before others. Our approach builds on a prior process comprehension framework for predicting actions' effects, to also identify subsequent steps that those effects enable. We present our new model (XPAD) that biases effect predictions towards those that (1) explain more of the actions in the paragraph and (2) are more plausible with respect to background knowledge. We also extend an existing benchmark dataset for procedural text comprehension, ProPara, by adding the new task of explaining actions by predicting their dependencies. We find that XPAD significantly outperforms prior systems on this task, while maintaining the performance on the original task in ProPara. The dataset is available at http://data.allenai.org/propara
From 'F' to 'A' on the N.Y. Regents Science Exams: An Overview of the Aristo Project
Sep 11, 2019
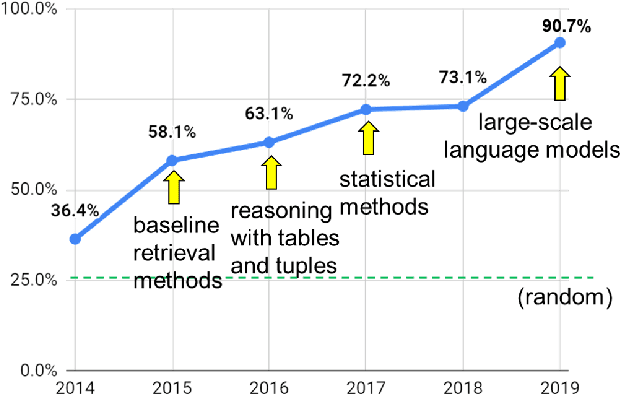


AI has achieved remarkable mastery over games such as Chess, Go, and Poker, and even Jeopardy, but the rich variety of standardized exams has remained a landmark challenge. Even in 2016, the best AI system achieved merely 59.3% on an 8th Grade science exam challenge. This paper reports unprecedented success on the Grade 8 New York Regents Science Exam, where for the first time a system scores more than 90% on the exam's non-diagram, multiple choice (NDMC) questions. In addition, our Aristo system, building upon the success of recent language models, exceeded 83% on the corresponding Grade 12 Science Exam NDMC questions. The results, on unseen test questions, are robust across different test years and different variations of this kind of test. They demonstrate that modern NLP methods can result in mastery on this task. While not a full solution to general question-answering (the questions are multiple choice, and the domain is restricted to 8th Grade science), it represents a significant milestone for the field.