 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStretching the Effectiveness of MLE from Accuracy to Bias for Pairwise Comparisons
Jun 10, 2019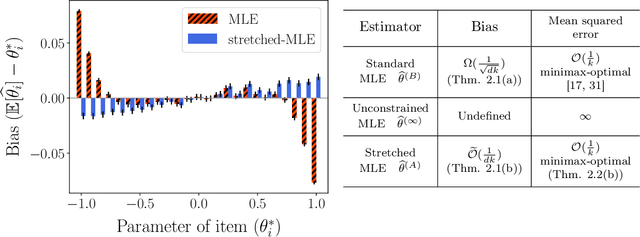
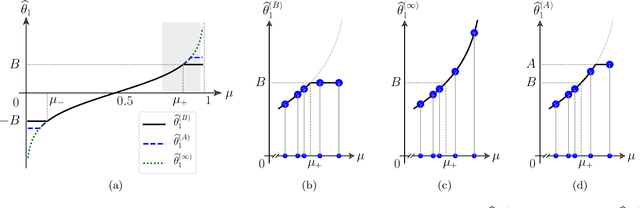
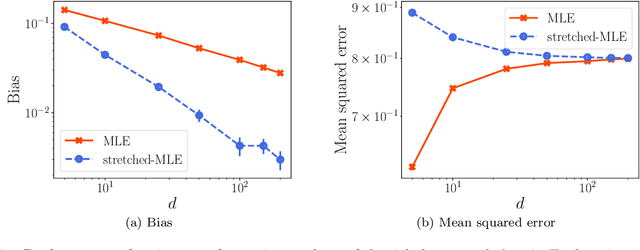
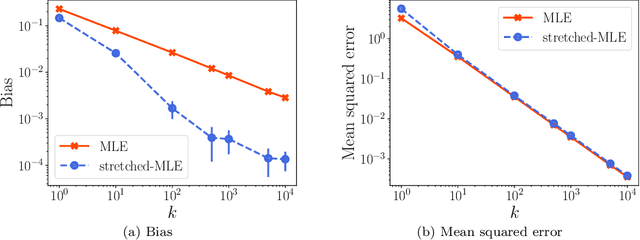
A number of applications (e.g., AI bot tournaments, sports, peer grading, crowdsourcing) use pairwise comparison data and the Bradley-Terry-Luce (BTL) model to evaluate a given collection of items (e.g., bots, teams, students, search results). Past work has shown that under the BTL model, the widely-used maximum-likelihood estimator (MLE) is minimax-optimal in estimating the item parameters, in terms of the mean squared error. However, another important desideratum for designing estimators is fairness. In this work, we consider fairness modeled by the notion of bias in statistics. We show that the MLE incurs a suboptimal rate in terms of bias. We then propose a simple modification to the MLE, which "stretches" the bounding box of the maximum-likelihood optimizer by a small constant factor from the underlying ground truth domain. We show that this simple modification leads to an improved rate in bias, while maintaining minimax-optimality in the mean squared error. In this manner, our proposed class of estimators provably improves fairness represented by bias without loss in accuracy.
Your 2 is My 1, Your 3 is My 9: Handling Arbitrary Miscalibrations in Ratings
Sep 13, 2018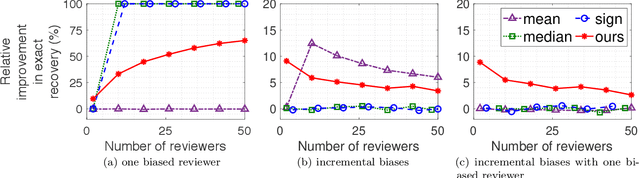
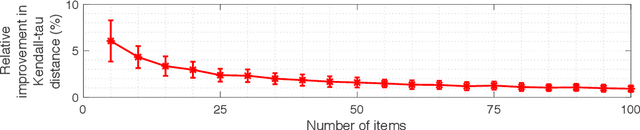
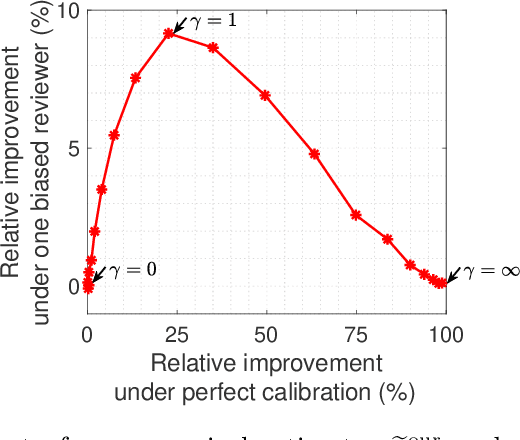
Cardinal scores (numeric ratings) collected from people are well known to suffer from miscalibrations. A popular approach to address this issue is to assume simplistic models of miscalibration (such as linear biases) to de-bias the scores. This approach, however, often fares poorly because people's miscalibrations are typically far more complex and not well understood. In the absence of simplifying assumptions on the miscalibration, it is widely believed by the crowdsourcing community that the only useful information in the cardinal scores is the induced ranking. In this paper, inspired by the framework of Stein's shrinkage, empirical Bayes, and the classic two-envelope problem, we contest this widespread belief. Specifically, we consider cardinal scores with arbitrary (or even adversarially chosen) miscalibrations which are only required to be consistent with the induced ranking. We design estimators which despite making no assumptions on the miscalibration, strictly and uniformly outperform all possible estimators that rely on only the ranking. Our estimators are flexible in that they can be used as a plug-in for a variety of applications, and we provide a proof-of-concept for A/B testing and ranking. Our results thus provide novel insights in the eternal debate between cardinal and ordinal data.
Choosing How to Choose Papers
Aug 27, 2018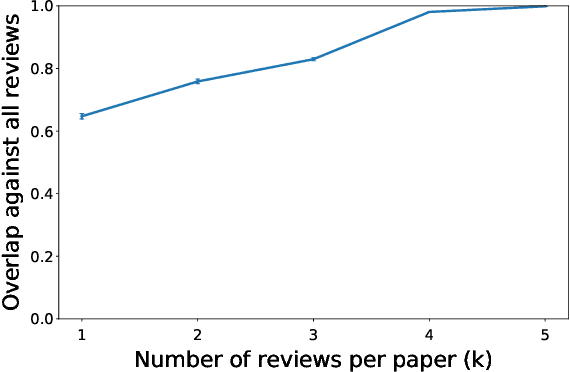

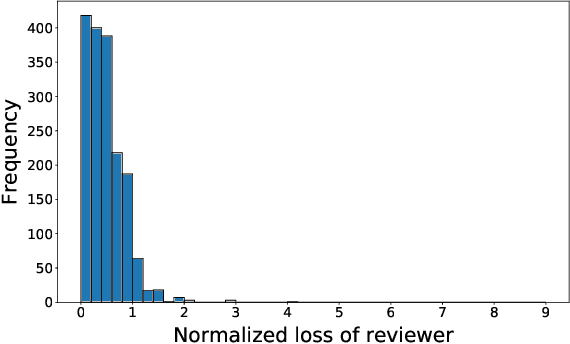
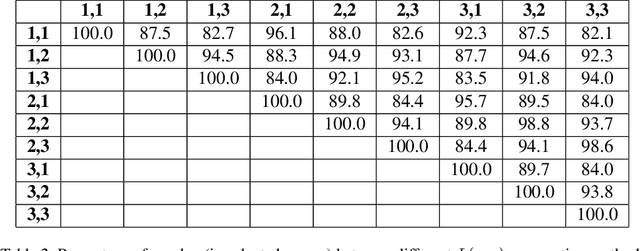
It is common to see a handful of reviewers reject a highly novel paper, because they view, say, extensive experiments as far more important than novelty, whereas the community as a whole would have embraced the paper. More generally, the disparate mapping of criteria scores to final recommendations by different reviewers is a major source of inconsistency in peer review. In this paper we present a framework --- based on $L(p,q)$-norm empirical risk minimization --- for learning the community's aggregate mapping. We draw on computational social choice to identify desirable values of $p$ and $q$; specifically, we characterize $p=q=1$ as the only choice that satisfies three natural axiomatic properties. Finally, we implement and apply our approach to reviews from IJCAI 2017.
On Strategyproof Conference Peer Review
Jun 16, 2018
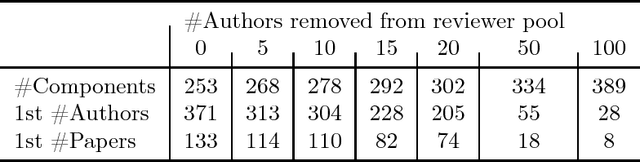

We consider peer review in a conference setting where there is typically an overlap between the set of reviewers and the set of authors. This overlap can incentivize strategic reviews to influence the final ranking of one's own papers. In this work, we address this problem through the lens of social choice, and present a theoretical framework for strategyproof and efficient peer review. We first present and analyze an algorithm for reviewer-assignment and aggregation that guarantees strategyproofness and a natural efficiency property called unanimity, when the authorship graph satisfies a simple property. Our algorithm is based on the so-called partitioning method, and can be thought as a generalization of this method to conference peer review settings. We then empirically show that the requisite property on the authorship graph is indeed satisfied in the ICLR-17 submission data, and further demonstrate a simple trick to make the partitioning method more practically appealing for conference peer review. Finally, we complement our positive results with negative theoretical results where we prove that under various ways of strengthening the requirements, it is impossible for any algorithm to be strategyproof and efficient.
PeerReview4All: Fair and Accurate Reviewer Assignment in Peer Review
Jun 16, 2018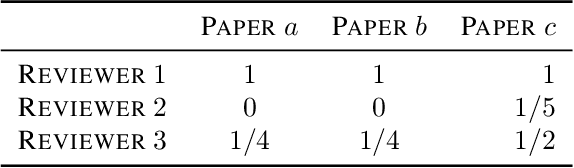

We consider the problem of automated assignment of papers to reviewers in conference peer review, with a focus on fairness and statistical accuracy. Our fairness objective is to maximize the review quality of the most disadvantaged paper, in contrast to the commonly used objective of maximizing the total quality over all papers. We design an assignment algorithm based on an incremental max-flow procedure that we prove is near-optimally fair. Our statistical accuracy objective is to ensure correct recovery of the papers that should be accepted. We provide a sharp minimax analysis of the accuracy of the peer-review process for a popular objective-score model as well as for a novel subjective-score model that we propose in the paper. Our analysis proves that our proposed assignment algorithm also leads to a near-optimal statistical accuracy. Finally, we design a novel experiment that allows for an objective comparison of various assignment algorithms, and overcomes the inherent difficulty posed by the absence of a ground truth in experiments on peer-review. The results of this experiment corroborate the theoretical guarantees of our algorithm.
Stochastically Transitive Models for Pairwise Comparisons: Statistical and Computational Issues
Sep 28, 2016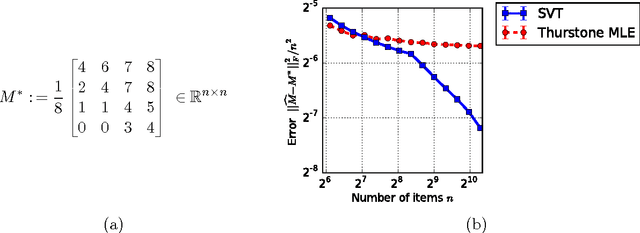
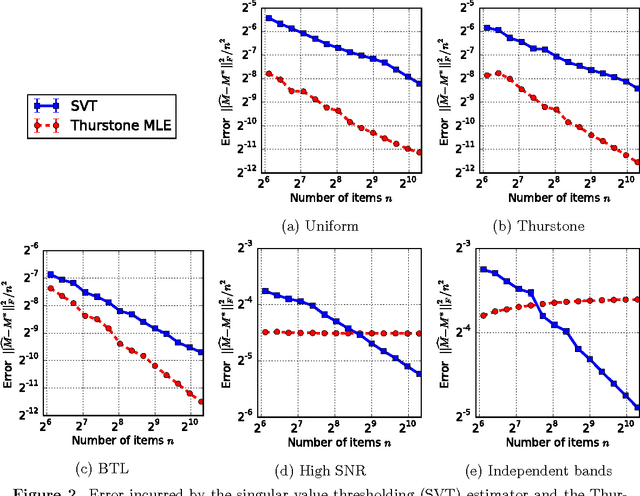
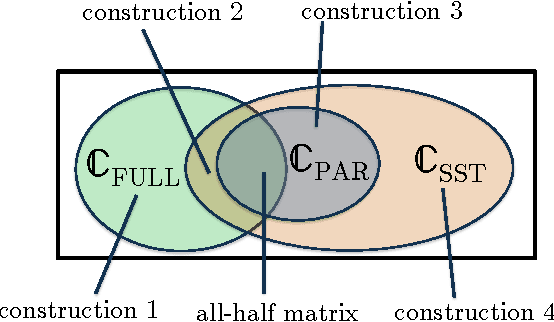
There are various parametric models for analyzing pairwise comparison data, including the Bradley-Terry-Luce (BTL) and Thurstone models, but their reliance on strong parametric assumptions is limiting. In this work, we study a flexible model for pairwise comparisons, under which the probabilities of outcomes are required only to satisfy a natural form of stochastic transitivity. This class includes parametric models including the BTL and Thurstone models as special cases, but is considerably more general. We provide various examples of models in this broader stochastically transitive class for which classical parametric models provide poor fits. Despite this greater flexibility, we show that the matrix of probabilities can be estimated at the same rate as in standard parametric models. On the other hand, unlike in the BTL and Thurstone models, computing the minimax-optimal estimator in the stochastically transitive model is non-trivial, and we explore various computationally tractable alternatives. We show that a simple singular value thresholding algorithm is statistically consistent but does not achieve the minimax rate. We then propose and study algorithms that achieve the minimax rate over interesting sub-classes of the full stochastically transitive class. We complement our theoretical results with thorough numerical simulations.
Active Ranking from Pairwise Comparisons and when Parametric Assumptions Don't Help
Sep 23, 2016

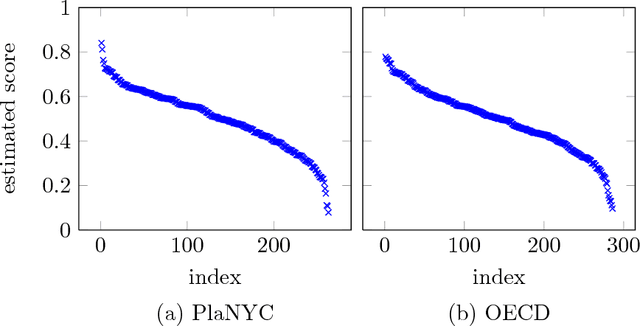
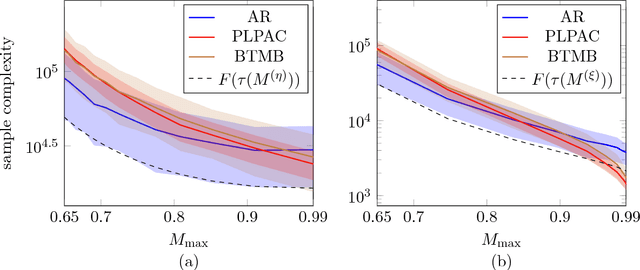
We consider sequential or active ranking of a set of n items based on noisy pairwise comparisons. Items are ranked according to the probability that a given item beats a randomly chosen item, and ranking refers to partitioning the items into sets of pre-specified sizes according to their scores. This notion of ranking includes as special cases the identification of the top-k items and the total ordering of the items. We first analyze a sequential ranking algorithm that counts the number of comparisons won, and uses these counts to decide whether to stop, or to compare another pair of items, chosen based on confidence intervals specified by the data collected up to that point. We prove that this algorithm succeeds in recovering the ranking using a number of comparisons that is optimal up to logarithmic factors. This guarantee does not require any structural properties of the underlying pairwise probability matrix, unlike a significant body of past work on pairwise ranking based on parametric models such as the Thurstone or Bradley-Terry-Luce models. It has been a long-standing open question as to whether or not imposing these parametric assumptions allows for improved ranking algorithms. For stochastic comparison models, in which the pairwise probabilities are bounded away from zero, our second contribution is to resolve this issue by proving a lower bound for parametric models. This shows, perhaps surprisingly, that these popular parametric modeling choices offer at most logarithmic gains for stochastic comparisons.
A Permutation-based Model for Crowd Labeling: Optimal Estimation and Robustness
Jun 30, 2016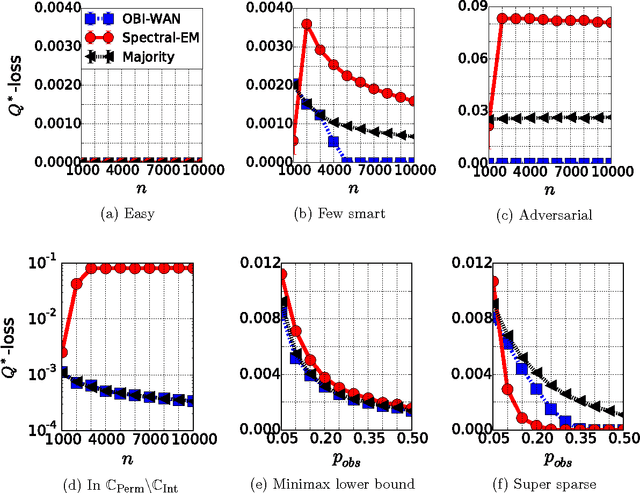
The aggregation and denoising of crowd labeled data is a task that has gained increased significance with the advent of crowdsourcing platforms and massive datasets. In this paper, we propose a permutation-based model for crowd labeled data that is a significant generalization of the common Dawid-Skene model, and introduce a new error metric by which to compare different estimators. Working in a high-dimensional non-asymptotic framework that allows both the number of workers and tasks to scale, we derive optimal rates of convergence for the permutation-based model. We show that the permutation-based model offers significant robustness in estimation due to its richness, while surprisingly incurring only a small additional statistical penalty as compared to the Dawid-Skene model. Finally, we propose a computationally-efficient method, called the OBI-WAN estimator, that is uniformly optimal over a class intermediate between the permutation-based and the Dawid-Skene models, and is uniformly consistent over the entire permutation-based model class. In contrast, the guarantees for estimators available in prior literature are sub-optimal over the original Dawid-Skene model.
Simple, Robust and Optimal Ranking from Pairwise Comparisons
Apr 27, 2016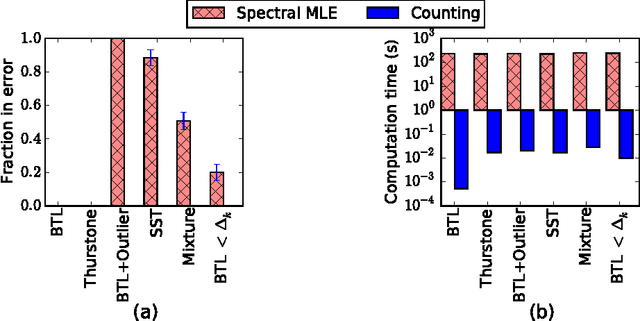
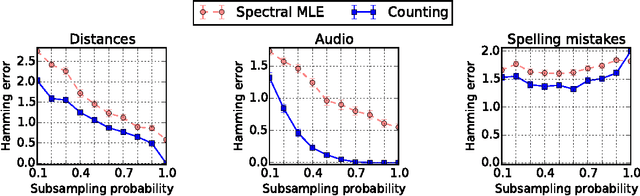
We consider data in the form of pairwise comparisons of n items, with the goal of precisely identifying the top k items for some value of k < n, or alternatively, recovering a ranking of all the items. We analyze the Copeland counting algorithm that ranks the items in order of the number of pairwise comparisons won, and show it has three attractive features: (a) its computational efficiency leads to speed-ups of several orders of magnitude in computation time as compared to prior work; (b) it is robust in that theoretical guarantees impose no conditions on the underlying matrix of pairwise-comparison probabilities, in contrast to some prior work that applies only to the BTL parametric model; and (c) it is an optimal method up to constant factors, meaning that it achieves the information-theoretic limits for recovering the top k-subset. We extend our results to obtain sharp guarantees for approximate recovery under the Hamming distortion metric, and more generally, to any arbitrary error requirement that satisfies a simple and natural monotonicity condition.
Feeling the Bern: Adaptive Estimators for Bernoulli Probabilities of Pairwise Comparisons
Mar 22, 2016
We study methods for aggregating pairwise comparison data in order to estimate outcome probabilities for future comparisons among a collection of n items. Working within a flexible framework that imposes only a form of strong stochastic transitivity (SST), we introduce an adaptivity index defined by the indifference sets of the pairwise comparison probabilities. In addition to measuring the usual worst-case risk of an estimator, this adaptivity index also captures the extent to which the estimator adapts to instance-specific difficulty relative to an oracle estimator. We prove three main results that involve this adaptivity index and different algorithms. First, we propose a three-step estimator termed Count-Randomize-Least squares (CRL), and show that it has adaptivity index upper bounded as $\sqrt{n}$ up to logarithmic factors. We then show that that conditional on the hardness of planted clique, no computationally efficient estimator can achieve an adaptivity index smaller than $\sqrt{n}$. Second, we show that a regularized least squares estimator can achieve a poly-logarithmic adaptivity index, thereby demonstrating a $\sqrt{n}$-gap between optimal and computationally achievable adaptivity. Finally, we prove that the standard least squares estimator, which is known to be optimally adaptive in several closely related problems, fails to adapt in the context of estimating pairwise probabilities.