 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow do Authors' Perceptions of their Papers Compare with Co-authors' Perceptions and Peer-review Decisions?
Nov 22, 2022



How do author perceptions match up to the outcomes of the peer-review process and perceptions of others? In a top-tier computer science conference (NeurIPS 2021) with more than 23,000 submitting authors and 9,000 submitted papers, we survey the authors on three questions: (i) their predicted probability of acceptance for each of their papers, (ii) their perceived ranking of their own papers based on scientific contribution, and (iii) the change in their perception about their own papers after seeing the reviews. The salient results are: (1) Authors have roughly a three-fold overestimate of the acceptance probability of their papers: The median prediction is 70% for an approximately 25% acceptance rate. (2) Female authors exhibit a marginally higher (statistically significant) miscalibration than male authors; predictions of authors invited to serve as meta-reviewers or reviewers are similarly calibrated, but better than authors who were not invited to review. (3) Authors' relative ranking of scientific contribution of two submissions they made generally agree (93%) with their predicted acceptance probabilities, but there is a notable 7% responses where authors think their better paper will face a worse outcome. (4) The author-provided rankings disagreed with the peer-review decisions about a third of the time; when co-authors ranked their jointly authored papers, co-authors disagreed at a similar rate -- about a third of the time. (5) At least 30% of respondents of both accepted and rejected papers said that their perception of their own paper improved after the review process. The stakeholders in peer review should take these findings into account in setting their expectations from peer review.
Allocation Schemes in Analytic Evaluation: Applicant-Centric Holistic or Attribute-Centric Segmented?
Sep 18, 2022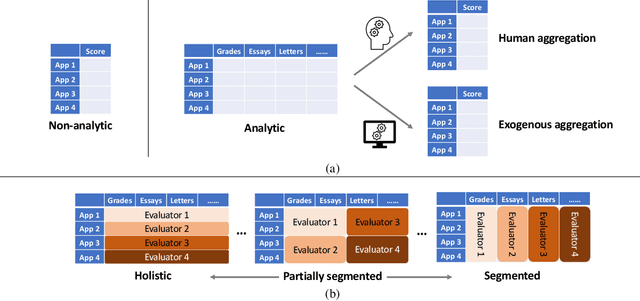
Many applications such as hiring and university admissions involve evaluation and selection of applicants. These tasks are fundamentally difficult, and require combining evidence from multiple different aspects (what we term "attributes"). In these applications, the number of applicants is often large, and a common practice is to assign the task to multiple evaluators in a distributed fashion. Specifically, in the often-used holistic allocation, each evaluator is assigned a subset of the applicants, and is asked to assess all relevant information for their assigned applicants. However, such an evaluation process is subject to issues such as miscalibration (evaluators see only a small fraction of the applicants and may not get a good sense of relative quality), and discrimination (evaluators are influenced by irrelevant information about the applicants). We identify that such attribute-based evaluation allows alternative allocation schemes. Specifically, we consider assigning each evaluator more applicants but fewer attributes per applicant, termed segmented allocation. We compare segmented allocation to holistic allocation on several dimensions via theoretical and experimental methods. We establish various tradeoffs between these two approaches, and identify conditions under which one approach results in more accurate evaluation than the other.
Tradeoffs in Preventing Manipulation in Paper Bidding for Reviewer Assignment
Jul 22, 2022
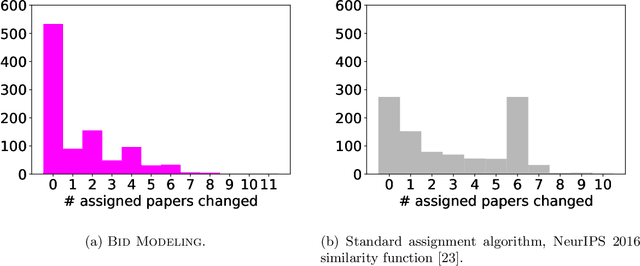
Many conferences rely on paper bidding as a key component of their reviewer assignment procedure. These bids are then taken into account when assigning reviewers to help ensure that each reviewer is assigned to suitable papers. However, despite the benefits of using bids, reliance on paper bidding can allow malicious reviewers to manipulate the paper assignment for unethical purposes (e.g., getting assigned to a friend's paper). Several different approaches to preventing this manipulation have been proposed and deployed. In this paper, we enumerate certain desirable properties that algorithms for addressing bid manipulation should satisfy. We then offer a high-level analysis of various approaches along with directions for future investigation.
A Dataset on Malicious Paper Bidding in Peer Review
Jun 24, 2022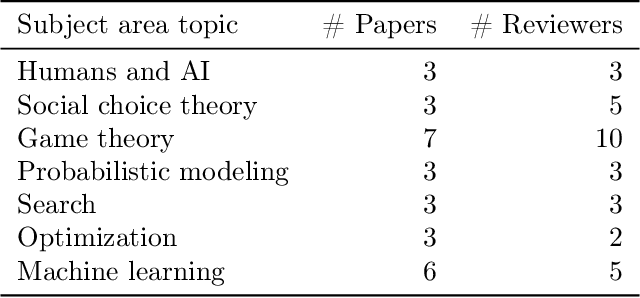

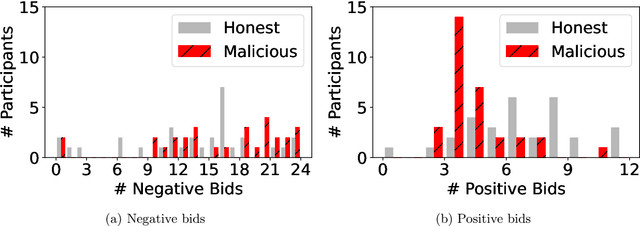
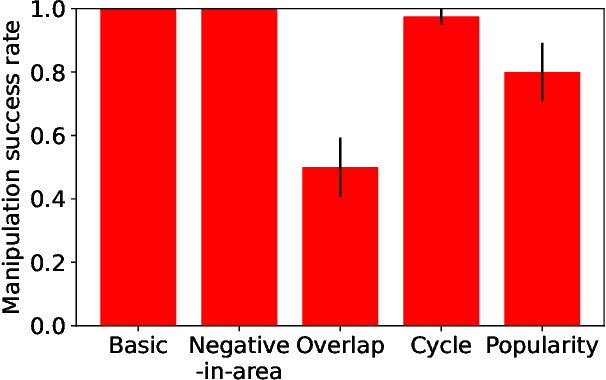
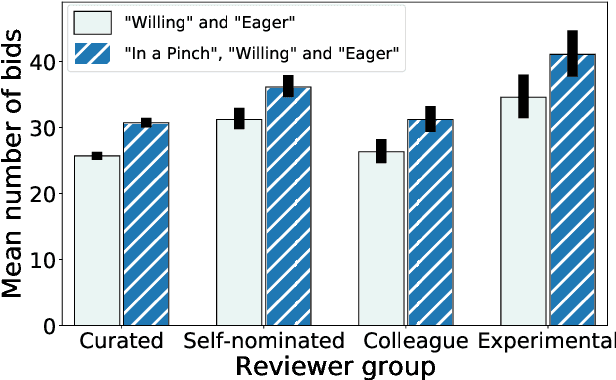
In conference peer review, reviewers are often asked to provide "bids" on each submitted paper that express their interest in reviewing that paper. A paper assignment algorithm then uses these bids (along with other data) to compute a high-quality assignment of reviewers to papers. However, this process has been exploited by malicious reviewers who strategically bid in order to unethically manipulate the paper assignment, crucially undermining the peer review process. For example, these reviewers may aim to get assigned to a friend's paper as part of a quid-pro-quo deal. A critical impediment towards creating and evaluating methods to mitigate this issue is the lack of any publicly-available data on malicious paper bidding. In this work, we collect and publicly release a novel dataset to fill this gap, collected from a mock conference activity where participants were instructed to bid either honestly or maliciously. We further provide a descriptive analysis of the bidding behavior, including our categorization of different strategies employed by participants. Finally, we evaluate the ability of each strategy to manipulate the assignment, and also evaluate the performance of some simple algorithms meant to detect malicious bidding. The performance of these detection algorithms can be taken as a baseline for future research on detecting malicious bidding.
Integrating Rankings into Quantized Scores in Peer Review
Apr 05, 2022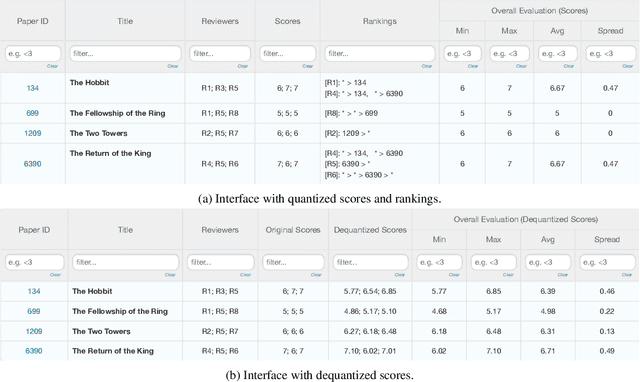
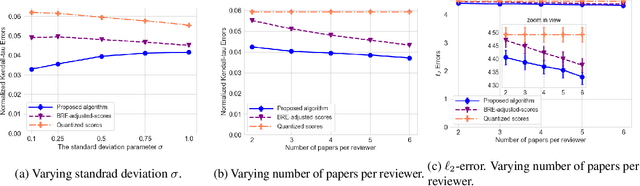
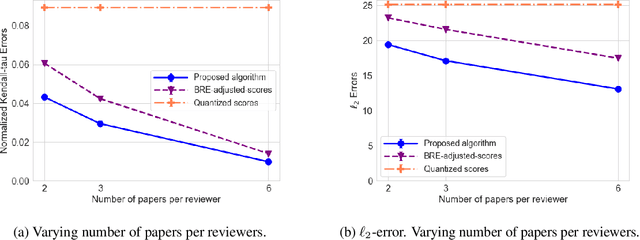
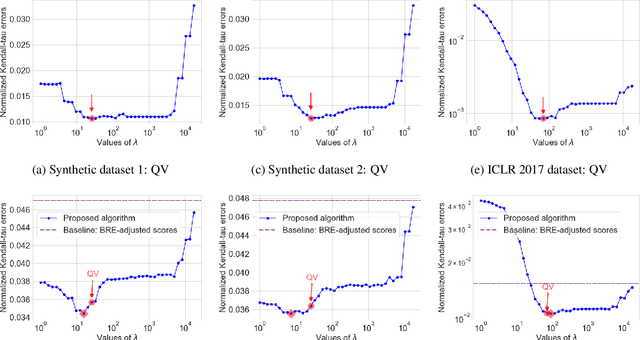
In peer review, reviewers are usually asked to provide scores for the papers. The scores are then used by Area Chairs or Program Chairs in various ways in the decision-making process. The scores are usually elicited in a quantized form to accommodate the limited cognitive ability of humans to describe their opinions in numerical values. It has been found that the quantized scores suffer from a large number of ties, thereby leading to a significant loss of information. To mitigate this issue, conferences have started to ask reviewers to additionally provide a ranking of the papers they have reviewed. There are however two key challenges. First, there is no standard procedure for using this ranking information and Area Chairs may use it in different ways (including simply ignoring them), thereby leading to arbitrariness in the peer-review process. Second, there are no suitable interfaces for judicious use of this data nor methods to incorporate it in existing workflows, thereby leading to inefficiencies. We take a principled approach to integrate the ranking information into the scores. The output of our method is an updated score pertaining to each review that also incorporates the rankings. Our approach addresses the two aforementioned challenges by: (i) ensuring that rankings are incorporated into the updates scores in the same manner for all papers, thereby mitigating arbitrariness, and (ii) allowing to seamlessly use existing interfaces and workflows designed for scores. We empirically evaluate our method on synthetic datasets as well as on peer reviews from the ICLR 2017 conference, and find that it reduces the error by approximately 30% as compared to the best performing baseline on the ICLR 2017 data.
The Price of Strategyproofing Peer Assessment
Jan 25, 2022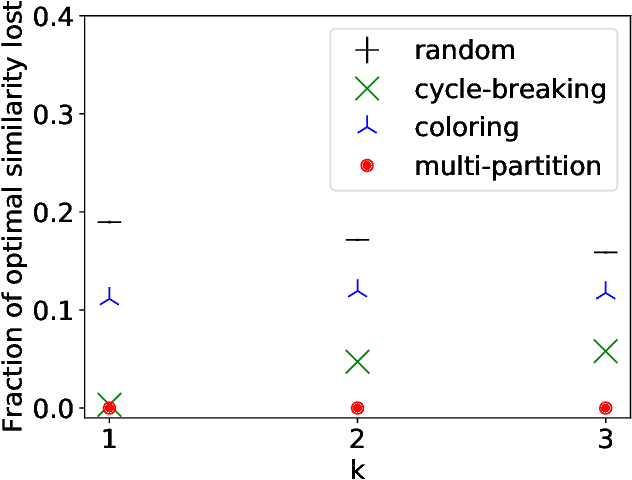
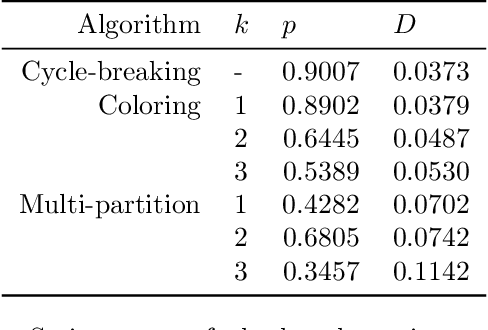
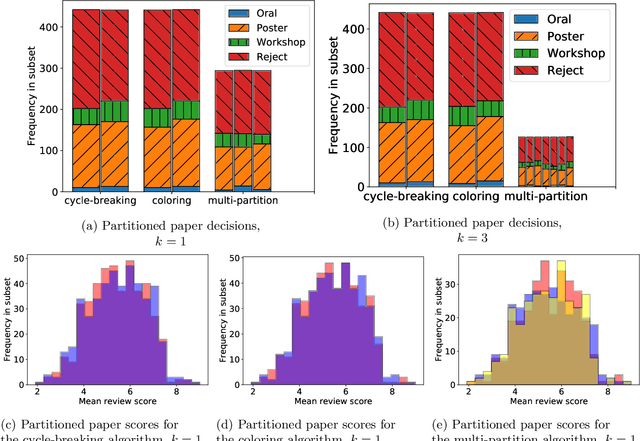
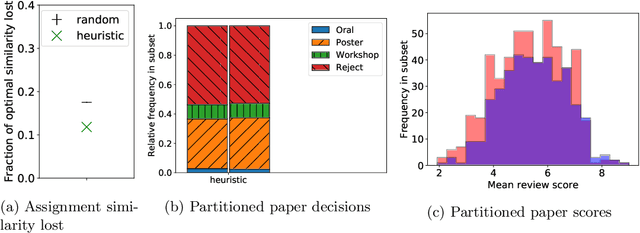
Strategic behavior is a fundamental problem in a variety of real-world applications that require some form of peer assessment, such as peer grading of assignments, grant proposal review, conference peer review, and peer assessment of employees. Since an individual's own work is in competition with the submissions they are evaluating, they may provide dishonest evaluations to increase the relative standing of their own submission. This issue is typically addressed by partitioning the individuals and assigning them to evaluate the work of only those from different subsets. Although this method ensures strategyproofness, each submission may require a different type of expertise for effective evaluation. In this paper, we focus on finding an assignment of evaluators to submissions that maximizes assigned expertise subject to the constraint of strategyproofness. We analyze the price of strategyproofness: that is, the amount of compromise on the assignment quality required in order to get strategyproofness. We establish several polynomial-time algorithms for strategyproof assignment along with assignment-quality guarantees. Finally, we evaluate the methods on a dataset from conference peer review.
Near-Optimal Reviewer Splitting in Two-Phase Paper Reviewing and Conference Experiment Design
Aug 13, 2021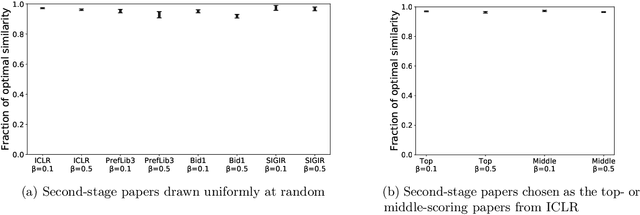
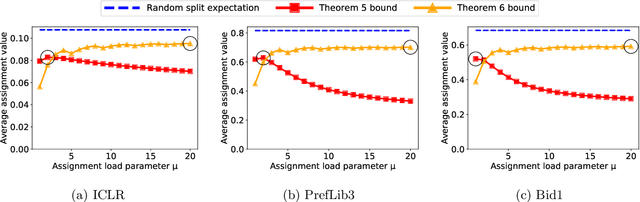
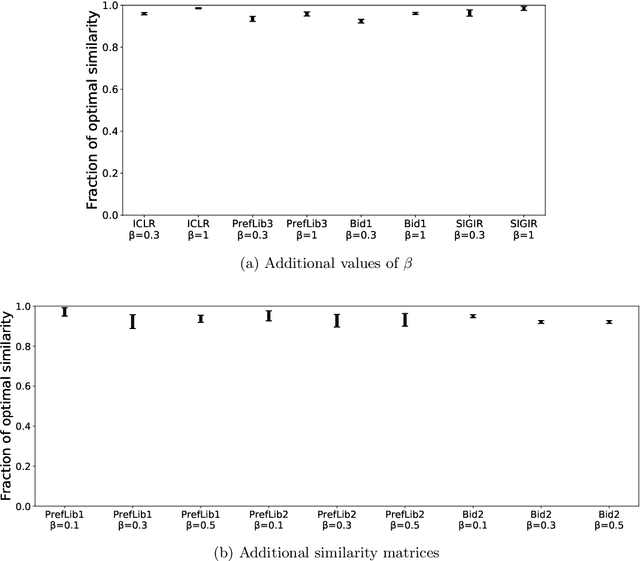
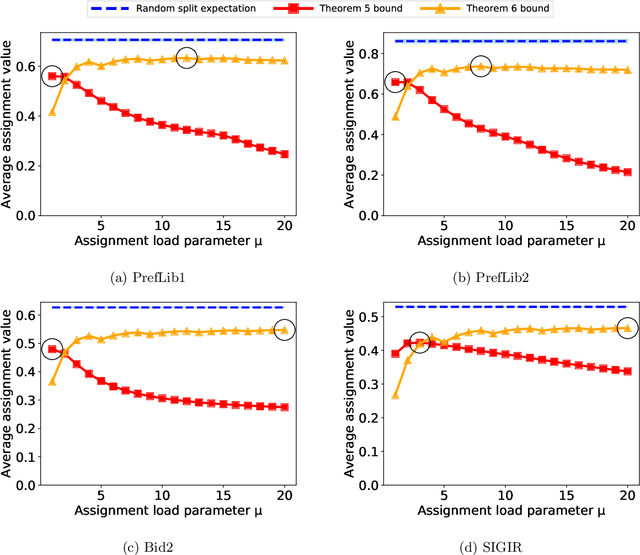
Many scientific conferences employ a two-phase paper review process, where some papers are assigned additional reviewers after the initial reviews are submitted. Many conferences also design and run experiments on their paper review process, where some papers are assigned reviewers who provide reviews under an experimental condition. In this paper, we consider the question: how should reviewers be divided between phases or conditions in order to maximize total assignment similarity? We make several contributions towards answering this question. First, we prove that when the set of papers requiring additional review is unknown, a simplified variant of this problem is NP-hard. Second, we empirically show that across several datasets pertaining to real conference data, dividing reviewers between phases/conditions uniformly at random allows an assignment that is nearly as good as the oracle optimal assignment. This uniformly random choice is practical for both the two-phase and conference experiment design settings. Third, we provide explanations of this phenomenon by providing theoretical bounds on the suboptimality of this random strategy under certain natural conditions. From these easily-interpretable conditions, we provide actionable insights to conference program chairs about whether a random reviewer split is suitable for their conference.
Debiasing Evaluations That are Biased by Evaluations
Dec 01, 2020It is common to evaluate a set of items by soliciting people to rate them. For example, universities ask students to rate the teaching quality of their instructors, and conference organizers ask authors of submissions to evaluate the quality of the reviews. However, in these applications, students often give a higher rating to a course if they receive higher grades in a course, and authors often give a higher rating to the reviews if their papers are accepted to the conference. In this work, we call these external factors the "outcome" experienced by people, and consider the problem of mitigating these outcome-induced biases in the given ratings when some information about the outcome is available. We formulate the information about the outcome as a known partial ordering on the bias. We propose a debiasing method by solving a regularized optimization problem under this ordering constraint, and also provide a carefully designed cross-validation method that adaptively chooses the appropriate amount of regularization. We provide theoretical guarantees on the performance of our algorithm, as well as experimental evaluations.
A Large Scale Randomized Controlled Trial on Herding in Peer-Review Discussions
Nov 30, 2020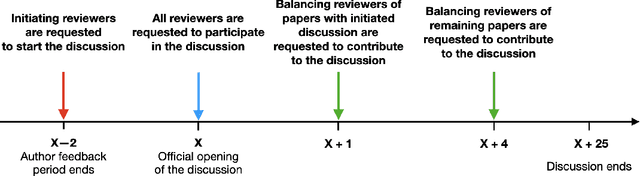


Peer review is the backbone of academia and humans constitute a cornerstone of this process, being responsible for reviewing papers and making the final acceptance/rejection decisions. Given that human decision making is known to be susceptible to various cognitive biases, it is important to understand which (if any) biases are present in the peer-review process and design the pipeline such that the impact of these biases is minimized. In this work, we focus on the dynamics of between-reviewers discussions and investigate the presence of herding behaviour therein. In that, we aim to understand whether reviewers and more senior decision makers get disproportionately influenced by the first argument presented in the discussion when (in case of reviewers) they form an independent opinion about the paper before discussing it with others. Specifically, in conjunction with the review process of ICML 2020 -- a large, top tier machine learning conference -- we design and execute a randomized controlled trial with the goal of testing for the conditional causal effect of the discussion initiator's opinion on the outcome of a paper.
A Novice-Reviewer Experiment to Address Scarcity of Qualified Reviewers in Large Conferences
Nov 30, 2020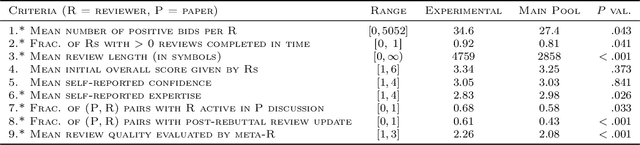
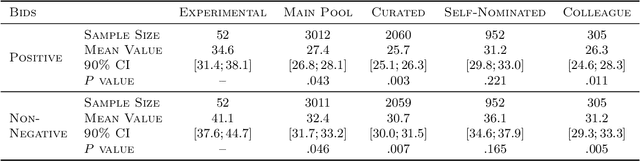
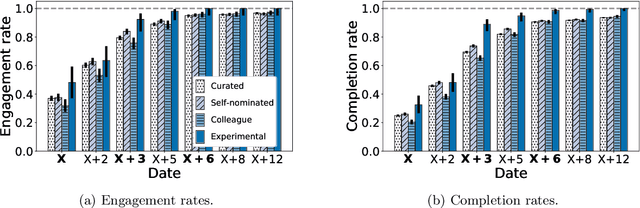
Conference peer review constitutes a human-computation process whose importance cannot be overstated: not only it identifies the best submissions for acceptance, but, ultimately, it impacts the future of the whole research area by promoting some ideas and restraining others. A surge in the number of submissions received by leading AI conferences has challenged the sustainability of the review process by increasing the burden on the pool of qualified reviewers which is growing at a much slower rate. In this work, we consider the problem of reviewer recruiting with a focus on the scarcity of qualified reviewers in large conferences. Specifically, we design a procedure for (i) recruiting reviewers from the population not typically covered by major conferences and (ii) guiding them through the reviewing pipeline. In conjunction with ICML 2020 -- a large, top-tier machine learning conference -- we recruit a small set of reviewers through our procedure and compare their performance with the general population of ICML reviewers. Our experiment reveals that a combination of the recruiting and guiding mechanisms allows for a principled enhancement of the reviewer pool and results in reviews of superior quality compared to the conventional pool of reviews as evaluated by senior members of the program committee (meta-reviewers).