 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe End Justifies the Mean: A Linear Ranking Rule for Proportional Sequential Decisions
May 12, 2026AI alignment and participatory design motivate a new democratic design problem: how to collectively choose a decision rule to use repeatedly. We study this problem for linear ranking rules, which repeatedly rank items $x_j$ within batches $X=(x_1,\dots,x_m)\in(\mathbb{R}^d)^m$, where each item's ranking is dictated by its score $\langle θ^*,x_j\rangle$ according to a fixed scoring vector $θ^*$. Given voters' preferred scoring vectors $θ^{(1)},\dots,θ^{(n)}$ and their population fractions $α^{(1)},\dots,α^{(n)}$, we ask how to choose a collective vector $θ^*$ satisfying individual proportionality (IP): every voter type $i$ should agree with the resulting rankings to an $α^{(i)}$-proportional degree, either on average over time (long-run IP) or even within each batch (per-batch IP). The default rule, the arithmetic mean of the $θ^{(i)}$, has been shown to be severely majoritarian; more generally, it is not clear that any fixed linear rule can balance many voters' disparate opinions. Our main result is that, surprisingly, there is a simple rule that does satisfy long-run IP: the angular mean, the spherical analog of the arithmetic mean. We then show that exact per-batch IP is impossible for fixed linear rules, but that the gap between per-batch and long-run IP shrinks quickly with batch size. Experiments on three real-world preference datasets show that all rules perform similarly when voters' preferences are homogeneous, while the angular mean substantially improves proportionality in high-disagreement regimes.
Fair, Manipulation-Robust, and Transparent Sortition
Jun 26, 2024Sortition, the random selection of political representatives, is increasingly being used around the world to choose participants of deliberative processes like Citizens' Assemblies. Motivated by sortition's practical importance, there has been a recent flurry of research on sortition algorithms, whose task it is to select a panel from among a pool of volunteers. This panel must satisfy quotas enforcing representation of key population subgroups. Past work has contributed an algorithmic approach for fulfilling this task while ensuring that volunteers' chances of selection are maximally equal, as measured by any convex equality objective. The question, then, is: which equality objective is the right one? Past work has mainly studied the objectives Minimax and Leximin, which respectively minimize the maximum and maximize the minimum chance of selection given to any volunteer. Recent work showed that both of these objectives have key weaknesses: Minimax is highly robust to manipulation but is arbitrarily unfair; oppositely, Leximin is highly fair but arbitrarily manipulable. In light of this gap, we propose a new equality objective, Goldilocks, that aims to achieve these ideals simultaneously by ensuring that no volunteer receives too little or too much chance of selection. We theoretically bound the extent to which Goldilocks achieves these ideals, finding that in an important sense, Goldilocks recovers among the best available solutions in a given instance. We then extend our bounds to the case where the output of Goldilocks is transformed to achieve a third goal, Transparency. Our empirical analysis of Goldilocks in real data is even more promising: we find that this objective achieves nearly instance-optimal minimum and maximum selection probabilities simultaneously in most real instances -- an outcome not even guaranteed to be possible for any algorithm.
Allocation Schemes in Analytic Evaluation: Applicant-Centric Holistic or Attribute-Centric Segmented?
Sep 18, 2022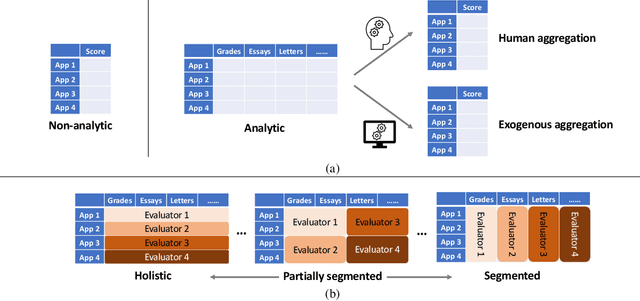
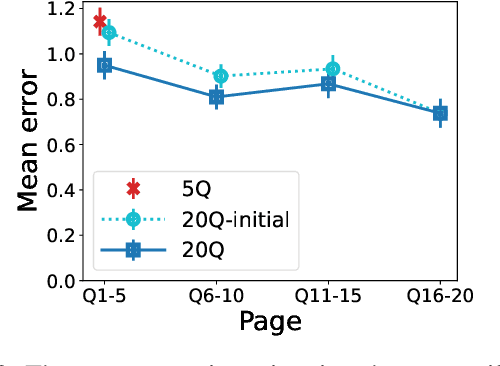
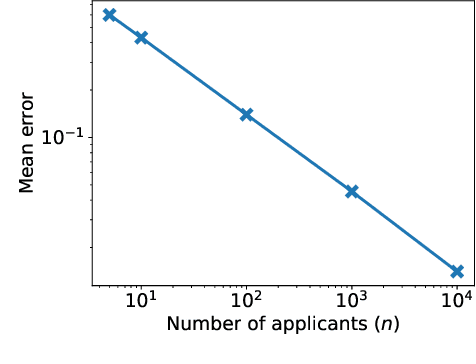
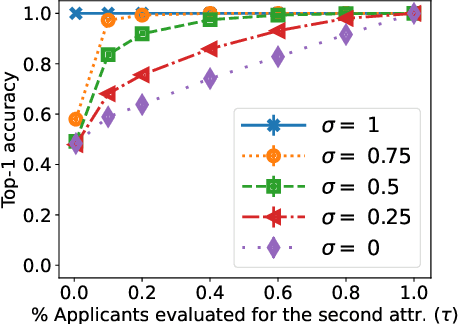
Many applications such as hiring and university admissions involve evaluation and selection of applicants. These tasks are fundamentally difficult, and require combining evidence from multiple different aspects (what we term "attributes"). In these applications, the number of applicants is often large, and a common practice is to assign the task to multiple evaluators in a distributed fashion. Specifically, in the often-used holistic allocation, each evaluator is assigned a subset of the applicants, and is asked to assess all relevant information for their assigned applicants. However, such an evaluation process is subject to issues such as miscalibration (evaluators see only a small fraction of the applicants and may not get a good sense of relative quality), and discrimination (evaluators are influenced by irrelevant information about the applicants). We identify that such attribute-based evaluation allows alternative allocation schemes. Specifically, we consider assigning each evaluator more applicants but fewer attributes per applicant, termed segmented allocation. We compare segmented allocation to holistic allocation on several dimensions via theoretical and experimental methods. We establish various tradeoffs between these two approaches, and identify conditions under which one approach results in more accurate evaluation than the other.