 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedefining Instance Matching: A Unified Framework for Part-Aware Matching in Panoptic Segmentation Evaluation
May 29, 2026The Panoptic Quality (PQ) metric is the standard for jointly evaluating instance and semantic segmentation. However, its original definition relies on a One-to-One matching between predicted and ground truth segments, which is only straightforward when the IoU threshold exceeds 0.5. Below 0.5, multiple matching strategies emerge in a poorly explored problem space. We systematically elucidate this space by recasting segment matching as a constrained bipartite assignment problem. Independently bounding the prediction- and ground-truth-side degrees yields four matching strategies: One-to-One, Many-to-One, One-to-Many, and Many-to-Many. We show that the first three are well-defined within the PQ framework, while Many-to-Many falls outside it. These strategies become relevant when instances are fragmented, adjacent objects are difficult to delineate, or annotations are noisy. Central to our framework is a vertex-based accounting of TP, FN, and FP, anchored to ground truth and predicted segments rather than to matching edges. We further show that the framework extends naturally to part-aware panoptic segmentation, and we explore part-aware evaluation on biomedical data. Across configurable case studies we report how different combinations of thresholds and matching strategies behave in practice. We release a unified open-source package built on Panoptica. It exposes Voronoi-based region-wise analysis, part-aware evaluation, and Area Under Threshold Curve computations as configurable options.
Is Medical Chest X-ray Data Anonymous?
Mar 15, 2021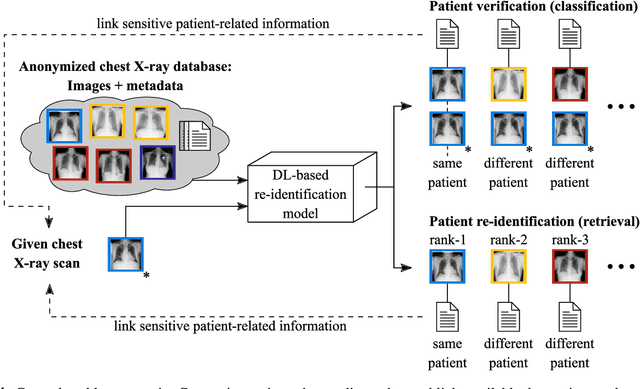
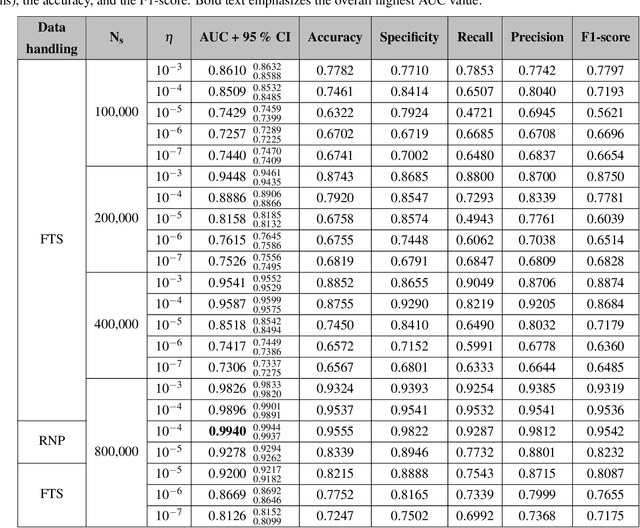
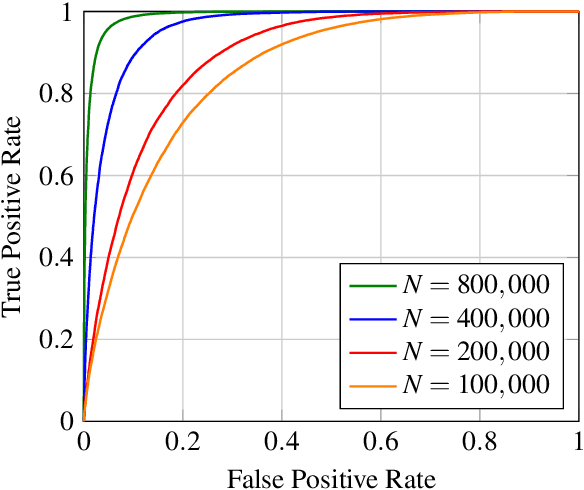
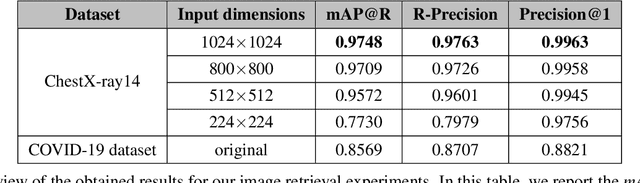
With the rise and ever-increasing potential of deep learning techniques in recent years, publicly available medical data sets became a key factor to enable reproducible development of diagnostic algorithms in the medical domain. Medical data contains sensitive patient-related information and is therefore usually anonymized by removing patient identifiers, e.g., patient names before publication. To the best of our knowledge, we are the first to show that a well-trained deep learning system is able to recover the patient identity from chest X-ray data. We demonstrate this using the publicly available large-scale ChestX-ray14 dataset, a collection of 112,120 frontal-view chest X-ray images from 30,805 unique patients. Our verification system is able to identify whether two frontal chest X-ray images are from the same person with an AUC of 0.9940 and a classification accuracy of 95.55%. We further highlight that the proposed system is able to reveal the same person even ten and more years after the initial scan. When pursuing a retrieval approach, we observe an mAP@R of 0.9748 and a precision@1 of 0.9963. Based on this high identification rate, a potential attacker may leak patient-related information and additionally cross-reference images to obtain more information. Thus, there is a great risk of sensitive content falling into unauthorized hands or being disseminated against the will of the concerned patients. Especially during the COVID-19 pandemic, numerous chest X-ray datasets have been published to advance research. Therefore, such data may be vulnerable to potential attacks by deep learning-based re-identification algorithms.