 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandomness in ML Defenses Helps Persistent Attackers and Hinders Evaluators
Feb 27, 2023It is becoming increasingly imperative to design robust ML defenses. However, recent work has found that many defenses that initially resist state-of-the-art attacks can be broken by an adaptive adversary. In this work we take steps to simplify the design of defenses and argue that white-box defenses should eschew randomness when possible. We begin by illustrating a new issue with the deployment of randomized defenses that reduces their security compared to their deterministic counterparts. We then provide evidence that making defenses deterministic simplifies robustness evaluation, without reducing the effectiveness of a truly robust defense. Finally, we introduce a new defense evaluation framework that leverages a defense's deterministic nature to better evaluate its adversarial robustness.
Poisoning Web-Scale Training Datasets is Practical
Feb 20, 2023Deep learning models are often trained on distributed, webscale datasets crawled from the internet. In this paper, we introduce two new dataset poisoning attacks that intentionally introduce malicious examples to a model's performance. Our attacks are immediately practical and could, today, poison 10 popular datasets. Our first attack, split-view poisoning, exploits the mutable nature of internet content to ensure a dataset annotator's initial view of the dataset differs from the view downloaded by subsequent clients. By exploiting specific invalid trust assumptions, we show how we could have poisoned 0.01% of the LAION-400M or COYO-700M datasets for just $60 USD. Our second attack, frontrunning poisoning, targets web-scale datasets that periodically snapshot crowd-sourced content -- such as Wikipedia -- where an attacker only needs a time-limited window to inject malicious examples. In light of both attacks, we notify the maintainers of each affected dataset and recommended several low-overhead defenses.
Tight Auditing of Differentially Private Machine Learning
Feb 15, 2023Auditing mechanisms for differential privacy use probabilistic means to empirically estimate the privacy level of an algorithm. For private machine learning, existing auditing mechanisms are tight: the empirical privacy estimate (nearly) matches the algorithm's provable privacy guarantee. But these auditing techniques suffer from two limitations. First, they only give tight estimates under implausible worst-case assumptions (e.g., a fully adversarial dataset). Second, they require thousands or millions of training runs to produce non-trivial statistical estimates of the privacy leakage. This work addresses both issues. We design an improved auditing scheme that yields tight privacy estimates for natural (not adversarially crafted) datasets -- if the adversary can see all model updates during training. Prior auditing works rely on the same assumption, which is permitted under the standard differential privacy threat model. This threat model is also applicable, e.g., in federated learning settings. Moreover, our auditing scheme requires only two training runs (instead of thousands) to produce tight privacy estimates, by adapting recent advances in tight composition theorems for differential privacy. We demonstrate the utility of our improved auditing schemes by surfacing implementation bugs in private machine learning code that eluded prior auditing techniques.
Effective Robustness against Natural Distribution Shifts for Models with Different Training Data
Feb 02, 2023``Effective robustness'' measures the extra out-of-distribution (OOD) robustness beyond what can be predicted from the in-distribution (ID) performance. Existing effective robustness evaluations typically use a single test set such as ImageNet to evaluate ID accuracy. This becomes problematic when evaluating models trained on different data distributions, e.g., comparing models trained on ImageNet vs. zero-shot language-image pre-trained models trained on LAION. In this paper, we propose a new effective robustness evaluation metric to compare the effective robustness of models trained on different data distributions. To do this we control for the accuracy on multiple ID test sets that cover the training distributions for all the evaluated models. Our new evaluation metric provides a better estimate of the effectiveness robustness and explains the surprising effective robustness gains of zero-shot CLIP-like models exhibited when considering only one ID dataset, while the gains diminish under our evaluation.
Extracting Training Data from Diffusion Models
Jan 30, 2023Image diffusion models such as DALL-E 2, Imagen, and Stable Diffusion have attracted significant attention due to their ability to generate high-quality synthetic images. In this work, we show that diffusion models memorize individual images from their training data and emit them at generation time. With a generate-and-filter pipeline, we extract over a thousand training examples from state-of-the-art models, ranging from photographs of individual people to trademarked company logos. We also train hundreds of diffusion models in various settings to analyze how different modeling and data decisions affect privacy. Overall, our results show that diffusion models are much less private than prior generative models such as GANs, and that mitigating these vulnerabilities may require new advances in privacy-preserving training.
Publishing Efficient On-device Models Increases Adversarial Vulnerability
Dec 28, 2022Recent increases in the computational demands of deep neural networks (DNNs) have sparked interest in efficient deep learning mechanisms, e.g., quantization or pruning. These mechanisms enable the construction of a small, efficient version of commercial-scale models with comparable accuracy, accelerating their deployment to resource-constrained devices. In this paper, we study the security considerations of publishing on-device variants of large-scale models. We first show that an adversary can exploit on-device models to make attacking the large models easier. In evaluations across 19 DNNs, by exploiting the published on-device models as a transfer prior, the adversarial vulnerability of the original commercial-scale models increases by up to 100x. We then show that the vulnerability increases as the similarity between a full-scale and its efficient model increase. Based on the insights, we propose a defense, $similarity$-$unpairing$, that fine-tunes on-device models with the objective of reducing the similarity. We evaluated our defense on all the 19 DNNs and found that it reduces the transferability up to 90% and the number of queries required by a factor of 10-100x. Our results suggest that further research is needed on the security (or even privacy) threats caused by publishing those efficient siblings.
Considerations for Differentially Private Learning with Large-Scale Public Pretraining
Dec 13, 2022The performance of differentially private machine learning can be boosted significantly by leveraging the transfer learning capabilities of non-private models pretrained on large public datasets. We critically review this approach. We primarily question whether the use of large Web-scraped datasets should be viewed as differential-privacy-preserving. We caution that publicizing these models pretrained on Web data as "private" could lead to harm and erode the public's trust in differential privacy as a meaningful definition of privacy. Beyond the privacy considerations of using public data, we further question the utility of this paradigm. We scrutinize whether existing machine learning benchmarks are appropriate for measuring the ability of pretrained models to generalize to sensitive domains, which may be poorly represented in public Web data. Finally, we notice that pretraining has been especially impactful for the largest available models -- models sufficiently large to prohibit end users running them on their own devices. Thus, deploying such models today could be a net loss for privacy, as it would require (private) data to be outsourced to a more compute-powerful third party. We conclude by discussing potential paths forward for the field of private learning, as public pretraining becomes more popular and powerful.
Preventing Verbatim Memorization in Language Models Gives a False Sense of Privacy
Oct 31, 2022



Studying data memorization in neural language models helps us understand the risks (e.g., to privacy or copyright) associated with models regurgitating training data, and aids in the evaluation of potential countermeasures. Many prior works -- and some recently deployed defenses -- focus on "verbatim memorization", defined as a model generation that exactly matches a substring from the training set. We argue that verbatim memorization definitions are too restrictive and fail to capture more subtle forms of memorization. Specifically, we design and implement an efficient defense based on Bloom filters that perfectly prevents all verbatim memorization. And yet, we demonstrate that this "perfect" filter does not prevent the leakage of training data. Indeed, it is easily circumvented by plausible and minimally modified "style-transfer" prompts -- and in some cases even the non-modified original prompts -- to extract memorized information. For example, instructing the model to output ALL-CAPITAL texts bypasses memorization checks based on verbatim matching. We conclude by discussing potential alternative definitions and why defining memorization is a difficult yet crucial open question for neural language models.
Preprocessors Matter! Realistic Decision-Based Attacks on Machine Learning Systems
Oct 07, 2022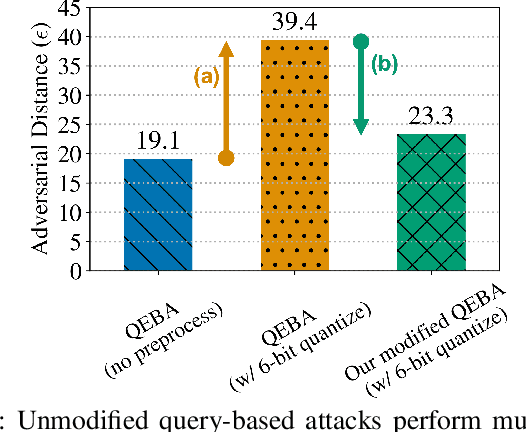
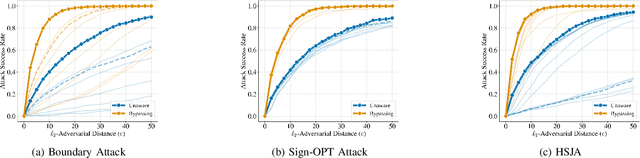

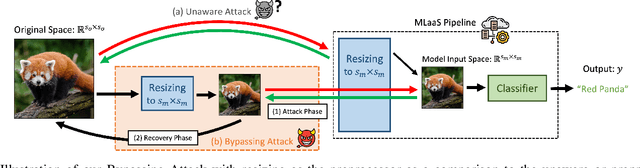
Decision-based adversarial attacks construct inputs that fool a machine-learning model into making targeted mispredictions by making only hard-label queries. For the most part, these attacks have been applied directly to isolated neural network models. However, in practice, machine learning models are just a component of a much larger system. By adding just a single preprocessor in front of a classifier, we find that state-of-the-art query-based attacks are as much as seven times less effective at attacking a prediction pipeline than attacking the machine learning model alone. Hence, attacks that are unaware of this invariance inevitably waste a large number of queries to re-discover or overcome it. We, therefore, develop techniques to first reverse-engineer the preprocessor and then use this extracted information to attack the end-to-end system. Our extraction method requires only a few hundred queries to learn the preprocessors used by most publicly available model pipelines, and our preprocessor-aware attacks recover the same efficacy as just attacking the model alone. The code can be found at https://github.com/google-research/preprocessor-aware-black-box-attack.
No Free Lunch in "Privacy for Free: How does Dataset Condensation Help Privacy"
Sep 29, 2022
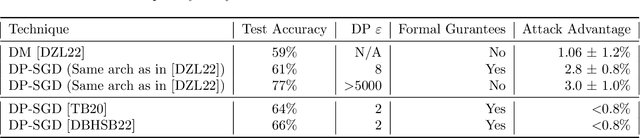
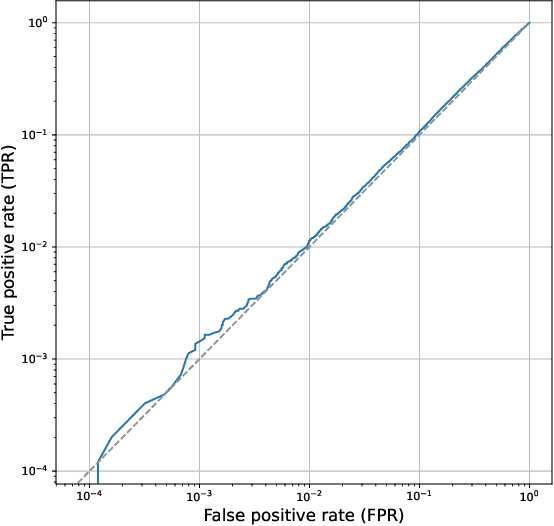
New methods designed to preserve data privacy require careful scrutiny. Failure to preserve privacy is hard to detect, and yet can lead to catastrophic results when a system implementing a ``privacy-preserving'' method is attacked. A recent work selected for an Outstanding Paper Award at ICML 2022 (Dong et al., 2022) claims that dataset condensation (DC) significantly improves data privacy when training machine learning models. This claim is supported by theoretical analysis of a specific dataset condensation technique and an empirical evaluation of resistance to some existing membership inference attacks. In this note we examine the claims in the work of Dong et al. (2022) and describe major flaws in the empirical evaluation of the method and its theoretical analysis. These flaws imply that their work does not provide statistically significant evidence that DC improves the privacy of training ML models over a naive baseline. Moreover, previously published results show that DP-SGD, the standard approach to privacy preserving ML, simultaneously gives better accuracy and achieves a (provably) lower membership attack success rate.