 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan NLP Models 'Identify', 'Distinguish', and 'Justify' Questions that Don't have a Definitive Answer?
Sep 08, 2023Though state-of-the-art (SOTA) NLP systems have achieved remarkable performance on a variety of language understanding tasks, they primarily focus on questions that have a correct and a definitive answer. However, in real-world applications, users often ask questions that don't have a definitive answer. Incorrectly answering such questions certainly hampers a system's reliability and trustworthiness. Can SOTA models accurately identify such questions and provide a reasonable response? To investigate the above question, we introduce QnotA, a dataset consisting of five different categories of questions that don't have definitive answers. Furthermore, for each QnotA instance, we also provide a corresponding QA instance i.e. an alternate question that ''can be'' answered. With this data, we formulate three evaluation tasks that test a system's ability to 'identify', 'distinguish', and 'justify' QnotA questions. Through comprehensive experiments, we show that even SOTA models including GPT-3 and Flan T5 do not fare well on these tasks and lack considerably behind the human performance baseline. We conduct a thorough analysis which further leads to several interesting findings. Overall, we believe our work and findings will encourage and facilitate further research in this important area and help develop more robust models.
A Stitch in Time Saves Nine: Detecting and Mitigating Hallucinations of LLMs by Validating Low-Confidence Generation
Jul 08, 2023Recently developed large language models have achieved remarkable success in generating fluent and coherent text. However, these models often tend to 'hallucinate' which critically hampers their reliability. In this work, we address this crucial problem and propose an approach that actively detects and mitigates hallucinations during the generation process. Specifically, we first identify the candidates of potential hallucination leveraging the model's logit output values, check their correctness through a validation procedure, mitigate the detected hallucinations, and then continue with the generation process. Through extensive experiments with the 'article generation task', we first demonstrate the individual efficacy of our detection and mitigation techniques. Specifically, the detection technique achieves a recall of 88% and the mitigation technique successfully mitigates 57.6% of the correctly detected hallucinations. Importantly, our mitigation technique does not introduce new hallucinations even in the case of incorrectly detected hallucinations, i.e., false positives. Then, we show that the proposed active detection and mitigation approach successfully reduces the hallucinations of the GPT-3 model from 47.5% to 14.5% on average. In summary, our work contributes to improving the reliability and trustworthiness of large language models, a crucial step en route to enabling their widespread adoption in real-world applications.
Can NLP Models Correctly Reason Over Contexts that Break the Common Assumptions?
May 20, 2023Pre-training on large corpora of text enables the language models to acquire a vast amount of factual and commonsense knowledge which allows them to achieve remarkable performance on a variety of language understanding tasks. They typically acquire this knowledge by learning from the pre-training text and capturing certain patterns from it. However, real-world settings often present scenarios that do not abide by these patterns i.e. scenarios that break the common assumptions. Can state-of-the-art NLP models correctly reason over the contexts of such scenarios? Addressing the above question, in this paper, we investigate the ability of models to correctly reason over contexts that break the common assumptions. To this end, we first systematically create evaluation data in which each data instance consists of (a) a common assumption, (b) a context that follows the assumption, (c) a context that breaks the assumption, and (d) questions based on the contexts. Then, through evaluations on multiple models including GPT-3 and Flan T5, we show that while doing fairly well on contexts that follow the common assumptions, the models struggle to correctly reason over contexts that break those assumptions. Specifically, the performance gap is as high as 20% absolute points. Furthermore, we thoroughly analyze these results revealing several interesting findings. We believe our work and findings will encourage and facilitate further research in developing more robust models that can also reliably reason over contexts that break the common assumptions. Data is available at \url{https://github.com/nrjvarshney/break_the_common_assumptions}.
A Unified Evaluation Framework for Novelty Detection and Accommodation in NLP with an Instantiation in Authorship Attribution
May 08, 2023



State-of-the-art natural language processing models have been shown to achieve remarkable performance in 'closed-world' settings where all the labels in the evaluation set are known at training time. However, in real-world settings, 'novel' instances that do not belong to any known class are often observed. This renders the ability to deal with novelties crucial. To initiate a systematic research in this important area of 'dealing with novelties', we introduce 'NoveltyTask', a multi-stage task to evaluate a system's performance on pipelined novelty 'detection' and 'accommodation' tasks. We provide mathematical formulation of NoveltyTask and instantiate it with the authorship attribution task that pertains to identifying the correct author of a given text. We use Amazon reviews corpus and compile a large dataset (consisting of 250k instances across 200 authors/labels) for NoveltyTask. We conduct comprehensive experiments and explore several baseline methods for the task. Our results show that the methods achieve considerably low performance making the task challenging and leaving sufficient room for improvement. Finally, we believe our work will encourage research in this underexplored area of dealing with novelties, an important step en route to developing robust systems.
Post-Abstention: Towards Reliably Re-Attempting the Abstained Instances in QA
May 02, 2023Despite remarkable progress made in natural language processing, even the state-of-the-art models often make incorrect predictions. Such predictions hamper the reliability of systems and limit their widespread adoption in real-world applications. 'Selective prediction' partly addresses the above concern by enabling models to abstain from answering when their predictions are likely to be incorrect. While selective prediction is advantageous, it leaves us with a pertinent question 'what to do after abstention'. To this end, we present an explorative study on 'Post-Abstention', a task that allows re-attempting the abstained instances with the aim of increasing 'coverage' of the system without significantly sacrificing its 'accuracy'. We first provide mathematical formulation of this task and then explore several methods to solve it. Comprehensive experiments on 11 QA datasets show that these methods lead to considerable risk improvements -- performance metric of the Post-Abstention task -- both in the in-domain and the out-of-domain settings. We also conduct a thorough analysis of these results which further leads to several interesting findings. Finally, we believe that our work will encourage and facilitate further research in this important area of addressing the reliability of NLP systems.
Methods and Mechanisms for Interactive Novelty Handling in Adversarial Environments
Mar 06, 2023



Learning to detect, characterize and accommodate novelties is a challenge that agents operating in open-world domains need to address to be able to guarantee satisfactory task performance. Certain novelties (e.g., changes in environment dynamics) can interfere with the performance or prevent agents from accomplishing task goals altogether. In this paper, we introduce general methods and architectural mechanisms for detecting and characterizing different types of novelties, and for building an appropriate adaptive model to accommodate them utilizing logical representations and reasoning methods. We demonstrate the effectiveness of the proposed methods in evaluations performed by a third party in the adversarial multi-agent board game Monopoly. The results show high novelty detection and accommodation rates across a variety of novelty types, including changes to the rules of the game, as well as changes to the agent's action capabilities.
Can Open-Domain QA Reader Utilize External Knowledge Efficiently like Humans?
Nov 23, 2022Recent state-of-the-art open-domain QA models are typically based on a two stage retriever-reader approach in which the retriever first finds the relevant knowledge/passages and the reader then leverages that to predict the answer. Prior work has shown that the performance of the reader usually tends to improve with the increase in the number of these passages. Thus, state-of-the-art models use a large number of passages (e.g. 100) for inference. While the reader in this approach achieves high prediction performance, its inference is computationally very expensive. We humans, on the other hand, use a more efficient strategy while answering: firstly, if we can confidently answer the question using our already acquired knowledge then we do not even use the external knowledge, and in the case when we do require external knowledge, we don't read the entire knowledge at once, instead, we only read that much knowledge that is sufficient to find the answer. Motivated by this procedure, we ask a research question "Can the open-domain QA reader utilize external knowledge efficiently like humans without sacrificing the prediction performance?" Driven by this question, we explore an approach that utilizes both 'closed-book' (leveraging knowledge already present in the model parameters) and 'open-book' inference (leveraging external knowledge). Furthermore, instead of using a large fixed number of passages for open-book inference, we dynamically read the external knowledge in multiple 'knowledge iterations'. Through comprehensive experiments on NQ and TriviaQA datasets, we demonstrate that this dynamic reading approach improves both the 'inference efficiency' and the 'prediction accuracy' of the reader. Comparing with the FiD reader, this approach matches its accuracy by utilizing just 18.32% of its reader inference cost and also outperforms it by achieving up to 55.10% accuracy on NQ Open.
Performance Analysis of LEO Satellite-Based IoT Networks in the Presence of Interference
Nov 08, 2022This paper explores a star-of-star topology for an internet-of-things (IoT) network using mega low Earth orbit constellations where the IoT users broadcast their sensed information to multiple satellites simultaneously over a shared channel. The satellites use amplify-and-forward relaying to forward the received signal to the ground station (GS), which then combines them coherently using maximal ratio combining. A comprehensive outage probability (OP) analysis is performed for the presented topology. Stochastic geometry is used to model the random locations of satellites, thus making the analysis general and independent of any constellation. The satellites are assumed to be visible if their elevation angle is greater than a threshold, called a mask angle. Statistical characteristics of the range and the number of visible satellites are derived for a given mask angle. Successive interference cancellation (SIC) and capture model (CM)-based decoding schemes are analyzed at the GS to mitigate interference effects. The average OP for the CM-based scheme, and the OP of the best user for the SIC scheme are derived analytically. Simulation results are presented that corroborate the derived analytical expressions. Moreover, insights on the effect of various system parameters like mask angle, altitude, number of satellites and decoding order are also presented. The results demonstrate that the explored topology can achieve the desired OP by leveraging the benefits of multiple satellites. Thus, this topology is an attractive choice for satellite-based IoT networks as it can facilitate burst transmissions without coordination among the IoT users.
"John is 50 years old, can his son be 65?" Evaluating NLP Models' Understanding of Feasibility
Oct 14, 2022
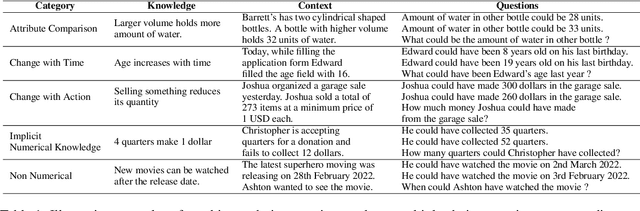
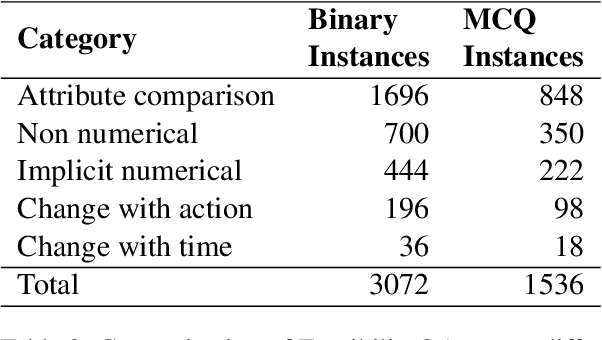

In current NLP research, large-scale language models and their abilities are widely being discussed. Some recent works have also found notable failures of these models. Often these failure examples involve complex reasoning abilities. This work focuses on a simple commonsense ability, reasoning about when an action (or its effect) is feasible. We introduce FeasibilityQA, a question-answering dataset involving binary classification (BCQ) and multi-choice multi-correct questions (MCQ) that test understanding of feasibility. We show that even state-of-the-art models such as GPT-3 struggle to answer the feasibility questions correctly. Specifically, on (MCQ, BCQ) questions, GPT-3 achieves accuracy of just (19%, 62%) and (25%, 64%) in zero-shot and few-shot settings, respectively. We also evaluate models by providing relevant knowledge statements required to answer the question and find that the additional knowledge leads to a 7% gain in performance, but the overall performance still remains low. These results make one wonder how much commonsense knowledge about action feasibility is encoded in GPT-3 and how well the model can reason about it.
Model Cascading: Towards Jointly Improving Efficiency and Accuracy of NLP Systems
Oct 11, 2022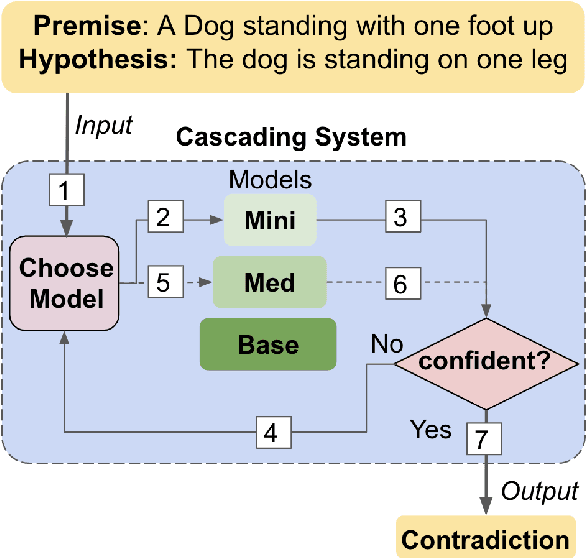
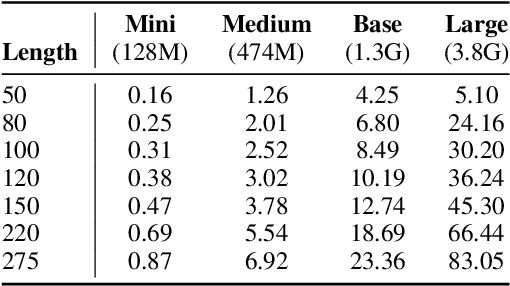
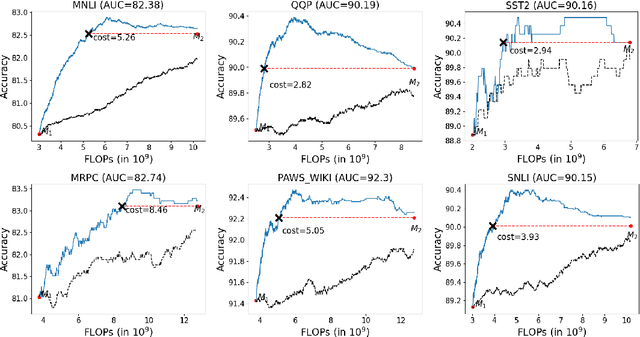
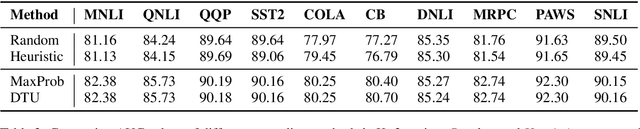
Do all instances need inference through the big models for a correct prediction? Perhaps not; some instances are easy and can be answered correctly by even small capacity models. This provides opportunities for improving the computational efficiency of systems. In this work, we present an explorative study on 'model cascading', a simple technique that utilizes a collection of models of varying capacities to accurately yet efficiently output predictions. Through comprehensive experiments in multiple task settings that differ in the number of models available for cascading (K value), we show that cascading improves both the computational efficiency and the prediction accuracy. For instance, in K=3 setting, cascading saves up to 88.93% computation cost and consistently achieves superior prediction accuracy with an improvement of up to 2.18%. We also study the impact of introducing additional models in the cascade and show that it further increases the efficiency improvements. Finally, we hope that our work will facilitate development of efficient NLP systems making their widespread adoption in real-world applications possible.