 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERTology Meets Biology: Interpreting Attention in Protein Language Models
Jul 13, 2020Transformer architectures have proven to learn useful representations for protein classification and generation tasks. However, these representations present challenges in interpretability. Through the lens of attention, we analyze the inner workings of the Transformer and explore how the model discerns structural and functional properties of proteins. We show that attention (1) captures the folding structure of proteins, connecting amino acids that are far apart in the underlying sequence, but spatially close in the three-dimensional structure, (2) targets binding sites, a key functional component of proteins, and (3) focuses on progressively more complex biophysical properties with increasing layer depth. We also present a three-dimensional visualization of the interaction between attention and protein structure. Our findings align with known biological processes and provide a tool to aid discovery in protein engineering and synthetic biology. The code for visualization and analysis is available at https://github.com/salesforce/provis.
DART: Open-Domain Structured Data Record to Text Generation
Jul 06, 2020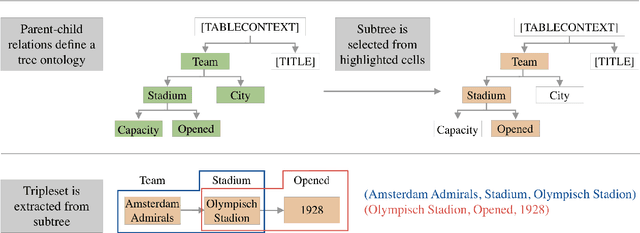
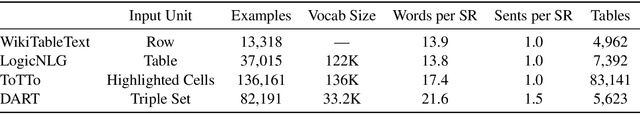
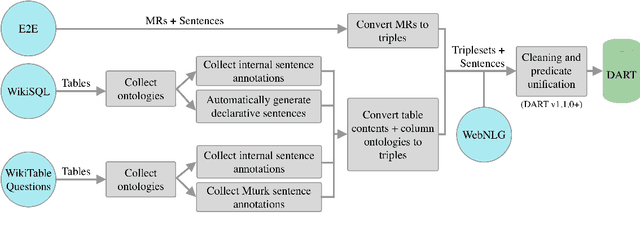
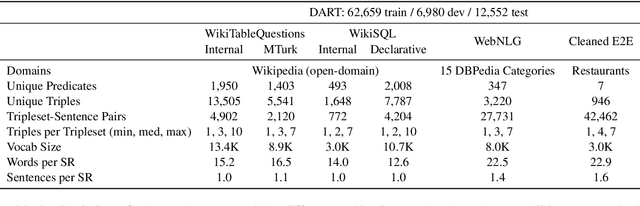
We introduce DART, a large dataset for open-domain structured data record to text generation. We consider the structured data record input as a set of RDF entity-relation triples, a format widely used for knowledge representation and semantics description. DART consists of 82,191 examples across different domains with each input being a semantic RDF triple set derived from data records in tables and the tree ontology of the schema, annotated with sentence descriptions that cover all facts in the triple set. This hierarchical, structured format with its open-domain nature differentiates DART from other existing table-to-text corpora. We conduct an analysis of DART on several state-of-the-art text generation models, showing that it introduces new and interesting challenges compared to existing datasets. Furthermore, we demonstrate that finetuning pretrained language models on DART facilitates out-of-domain generalization on the WebNLG 2017 dataset. DART is available at https://github.com/Yale-LILY/dart.
ESPRIT: Explaining Solutions to Physical Reasoning Tasks
May 14, 2020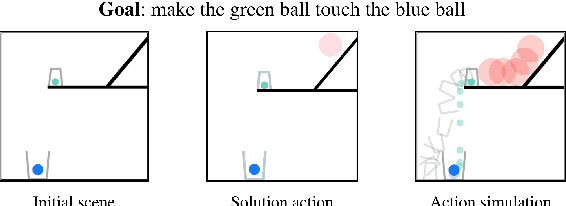

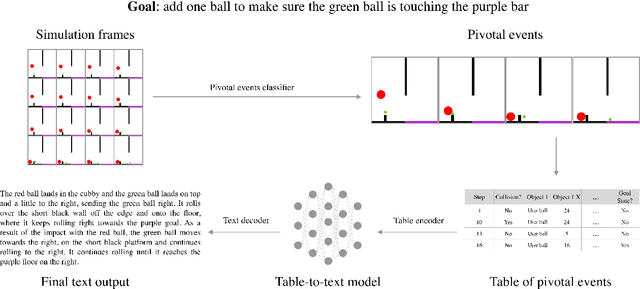
Neural networks lack the ability to reason about qualitative physics and so cannot generalize to scenarios and tasks unseen during training. We propose ESPRIT, a framework for commonsense reasoning about qualitative physics in natural language that generates interpretable descriptions of physical events. We use a two-step approach of first identifying the pivotal physical events in an environment and then generating natural language descriptions of those events using a data-to-text approach. Our framework learns to generate explanations of how the physical simulation will causally evolve so that an agent or a human can easily reason about a solution using those interpretable descriptions. Human evaluations indicate that ESPRIT produces crucial fine-grained details and has high coverage of physical concepts compared to even human annotations. Dataset, code and documentation are available at https://github.com/salesforce/esprit.
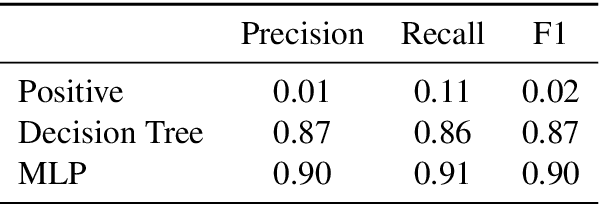
Double-Hard Debias: Tailoring Word Embeddings for Gender Bias Mitigation
May 03, 2020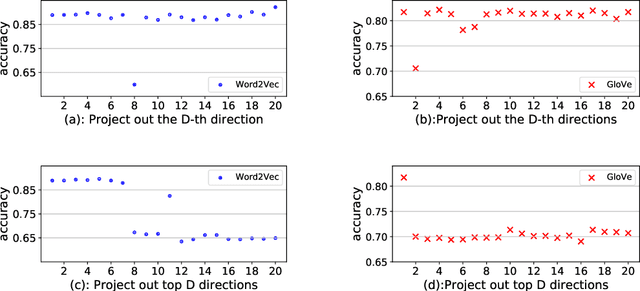
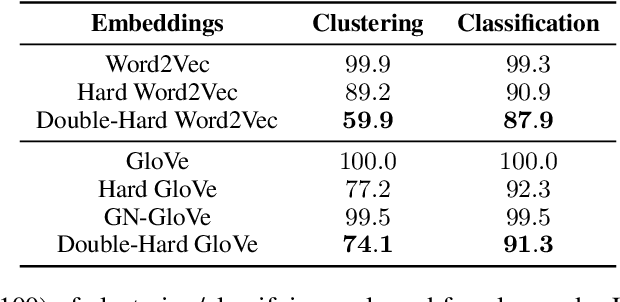
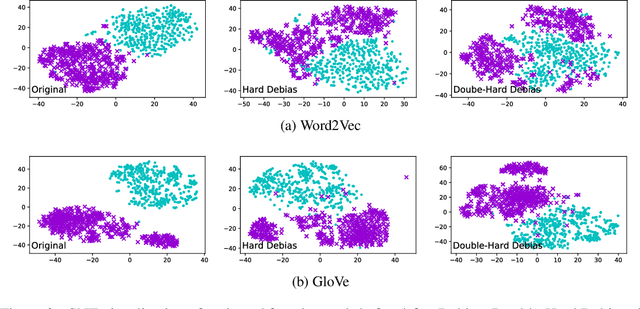
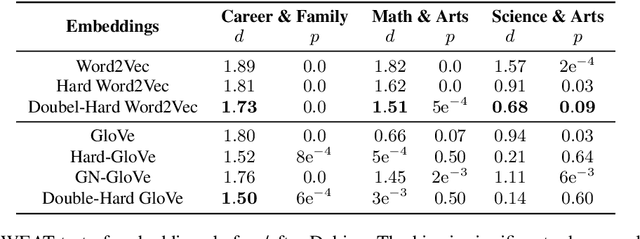
Word embeddings derived from human-generated corpora inherit strong gender bias which can be further amplified by downstream models. Some commonly adopted debiasing approaches, including the seminal Hard Debias algorithm, apply post-processing procedures that project pre-trained word embeddings into a subspace orthogonal to an inferred gender subspace. We discover that semantic-agnostic corpus regularities such as word frequency captured by the word embeddings negatively impact the performance of these algorithms. We propose a simple but effective technique, Double Hard Debias, which purifies the word embeddings against such corpus regularities prior to inferring and removing the gender subspace. Experiments on three bias mitigation benchmarks show that our approach preserves the distributional semantics of the pre-trained word embeddings while reducing gender bias to a significantly larger degree than prior approaches.
ERASER: A Benchmark to Evaluate Rationalized NLP Models
Nov 08, 2019
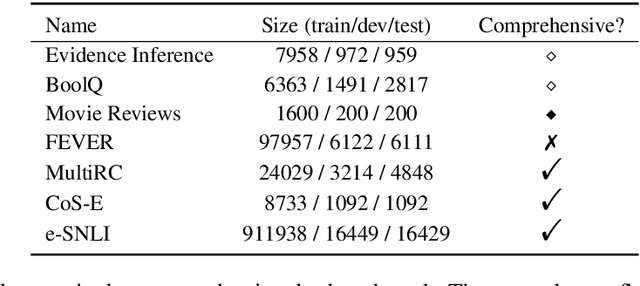
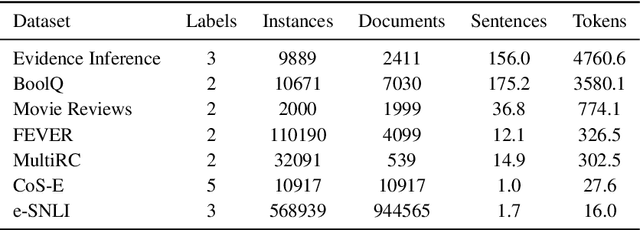
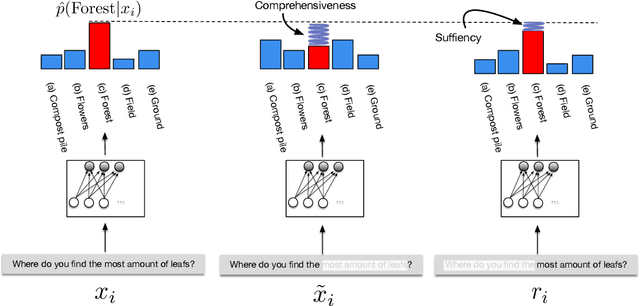
State-of-the-art models in NLP are now predominantly based on deep neural networks that are generally opaque in terms of how they come to specific predictions. This limitation has led to increased interest in designing more interpretable deep models for NLP that can reveal the `reasoning' underlying model outputs. But work in this direction has been conducted on different datasets and tasks with correspondingly unique aims and metrics; this makes it difficult to track progress. We propose the Evaluating Rationales And Simple English Reasoning (ERASER) benchmark to advance research on interpretable models in NLP. This benchmark comprises multiple datasets and tasks for which human annotations of "rationales" (supporting evidence) have been collected. We propose several metrics that aim to capture how well the rationales provided by models align with human rationales, and also how faithful these rationales are (i.e., the degree to which provided rationales influenced the corresponding predictions). Our hope is that releasing this benchmark facilitates progress on designing more interpretable NLP systems. The benchmark, code, and documentation are available at: www.eraserbenchmark.com .
Explain Yourself! Leveraging Language Models for Commonsense Reasoning
Jun 06, 2019

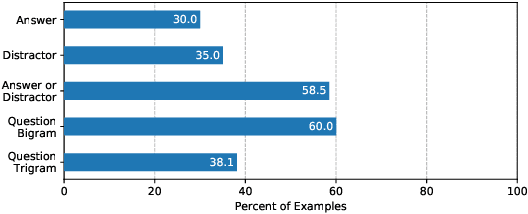

Deep learning models perform poorly on tasks that require commonsense reasoning, which often necessitates some form of world-knowledge or reasoning over information not immediately present in the input. We collect human explanations for commonsense reasoning in the form of natural language sequences and highlighted annotations in a new dataset called Common Sense Explanations (CoS-E). We use CoS-E to train language models to automatically generate explanations that can be used during training and inference in a novel Commonsense Auto-Generated Explanation (CAGE) framework. CAGE improves the state-of-the-art by 10% on the challenging CommonsenseQA task. We further study commonsense reasoning in DNNs using both human and auto-generated explanations including transfer to out-of-domain tasks. Empirical results indicate that we can effectively leverage language models for commonsense reasoning.
* Accepted at ACL, 11 pages total
Stacking With Auxiliary Features
May 27, 2016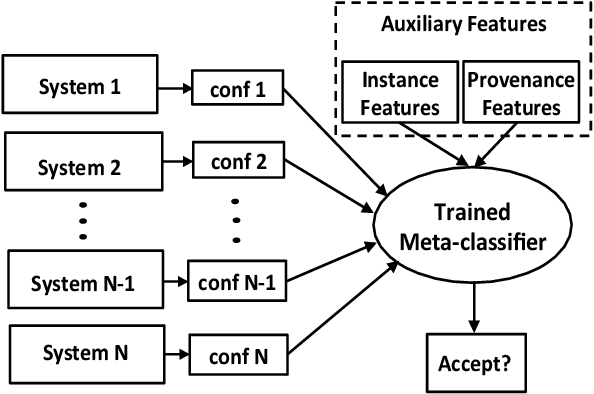
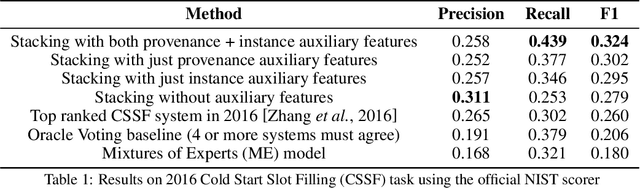

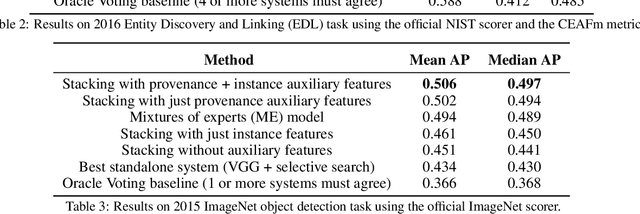
Ensembling methods are well known for improving prediction accuracy. However, they are limited in the sense that they cannot discriminate among component models effectively. In this paper, we propose stacking with auxiliary features that learns to fuse relevant information from multiple systems to improve performance. Auxiliary features enable the stacker to rely on systems that not just agree on an output but also the provenance of the output. We demonstrate our approach on three very different and difficult problems -- the Cold Start Slot Filling, the Tri-lingual Entity Discovery and Linking and the ImageNet object detection tasks. We obtain new state-of-the-art results on the first two tasks and substantial improvements on the detection task, thus verifying the power and generality of our approach.
Supervised and Unsupervised Ensembling for Knowledge Base Population
Apr 16, 2016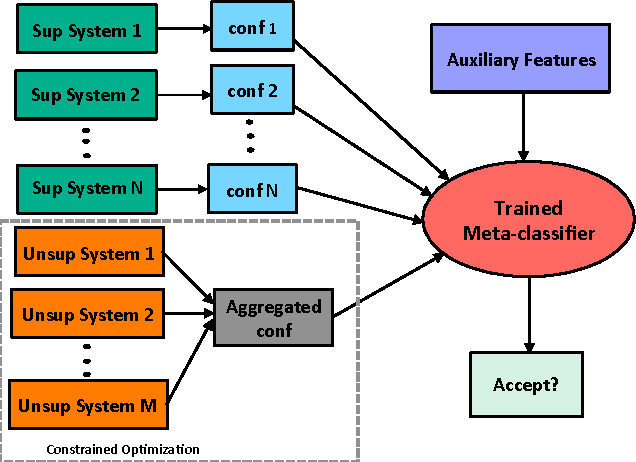

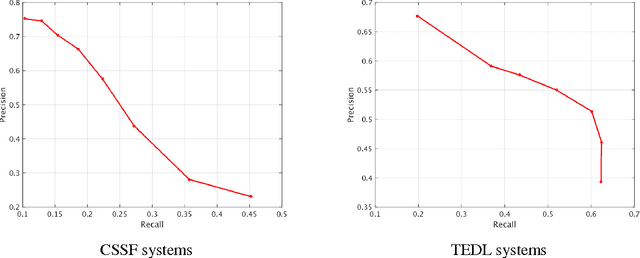

We present results on combining supervised and unsupervised methods to ensemble multiple systems for two popular Knowledge Base Population (KBP) tasks, Cold Start Slot Filling (CSSF) and Tri-lingual Entity Discovery and Linking (TEDL). We demonstrate that our combined system along with auxiliary features outperforms the best performing system for both tasks in the 2015 competition, several ensembling baselines, as well as the state-of-the-art stacking approach to ensembling KBP systems. The success of our technique on two different and challenging problems demonstrates the power and generality of our combined approach to ensembling.