 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Retrieval Augmentation for Multi-Modal Classification
Apr 16, 2021
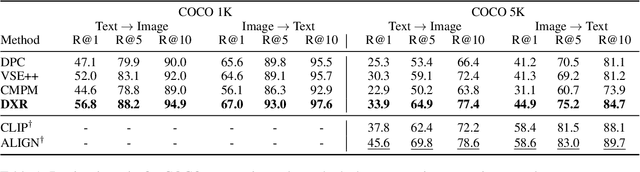
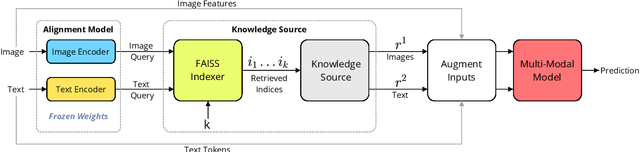
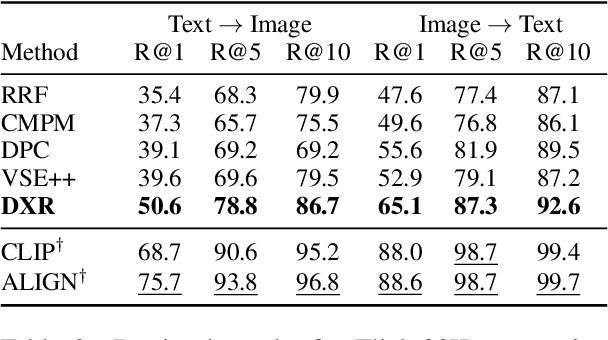
Recent advances in using retrieval components over external knowledge sources have shown impressive results for a variety of downstream tasks in natural language processing. Here, we explore the use of unstructured external knowledge sources of images and their corresponding captions for improving visual question answering (VQA). First, we train a novel alignment model for embedding images and captions in the same space, which achieves substantial improvement in performance on image-caption retrieval w.r.t. similar methods. Second, we show that retrieval-augmented multi-modal transformers using the trained alignment model improve results on VQA over strong baselines. We further conduct extensive experiments to establish the promise of this approach, and examine novel applications for inference time such as hot-swapping indices.
Training Vision Transformers for Image Retrieval
Feb 10, 2021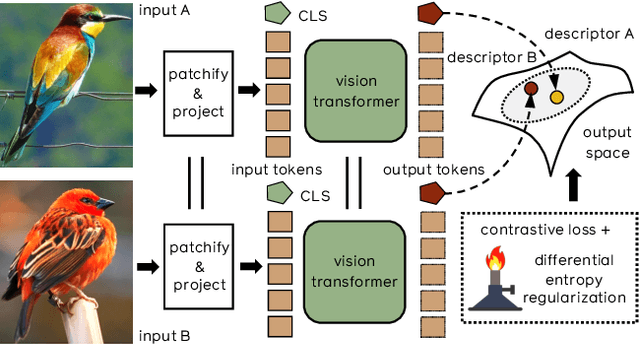
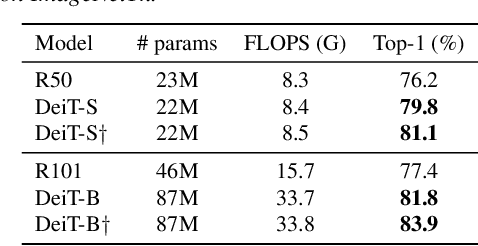
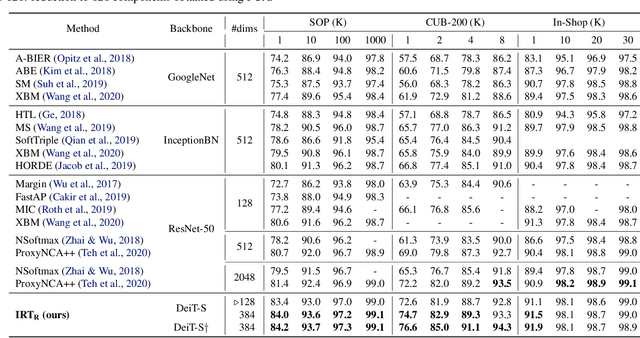
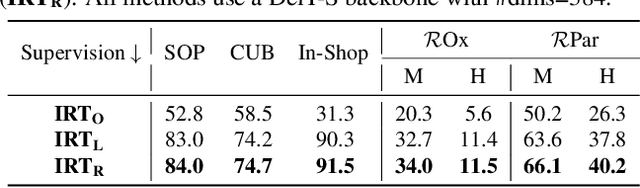
Transformers have shown outstanding results for natural language understanding and, more recently, for image classification. We here extend this work and propose a transformer-based approach for image retrieval: we adopt vision transformers for generating image descriptors and train the resulting model with a metric learning objective, which combines a contrastive loss with a differential entropy regularizer. Our results show consistent and significant improvements of transformers over convolution-based approaches. In particular, our method outperforms the state of the art on several public benchmarks for category-level retrieval, namely Stanford Online Product, In-Shop and CUB-200. Furthermore, our experiments on ROxford and RParis also show that, in comparable settings, transformers are competitive for particular object retrieval, especially in the regime of short vector representations and low-resolution images.
Continuous Surface Embeddings
Nov 24, 2020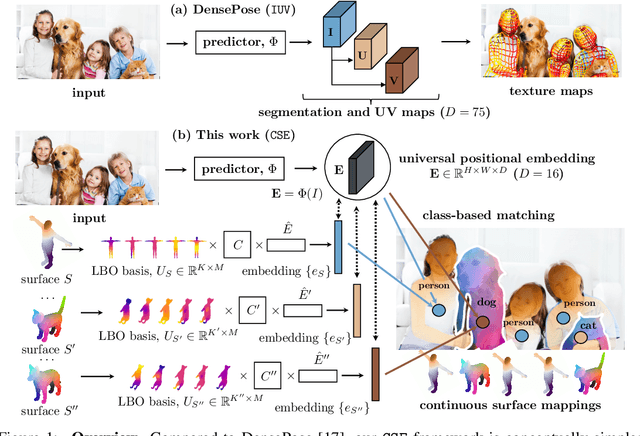
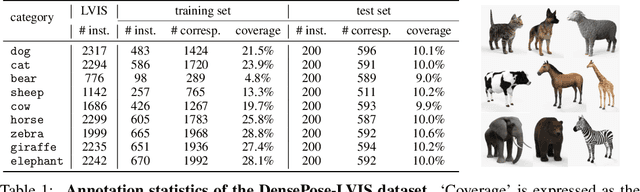
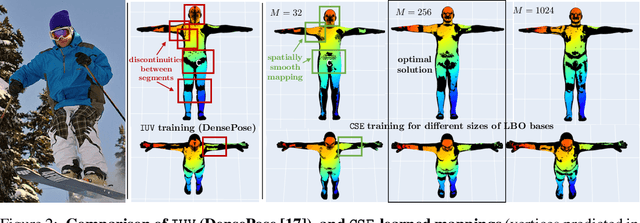
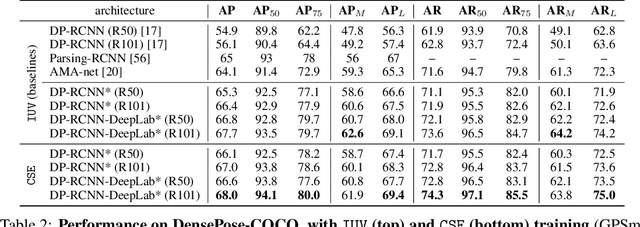
In this work, we focus on the task of learning and representing dense correspondences in deformable object categories. While this problem has been considered before, solutions so far have been rather ad-hoc for specific object types (i.e., humans), often with significant manual work involved. However, scaling the geometry understanding to all objects in nature requires more automated approaches that can also express correspondences between related, but geometrically different objects. To this end, we propose a new, learnable image-based representation of dense correspondences. Our model predicts, for each pixel in a 2D image, an embedding vector of the corresponding vertex in the object mesh, therefore establishing dense correspondences between image pixels and 3D object geometry. We demonstrate that the proposed approach performs on par or better than the state-of-the-art methods for dense pose estimation for humans, while being conceptually simpler. We also collect a new in-the-wild dataset of dense correspondences for animal classes and demonstrate that our framework scales naturally to the new deformable object categories.
Exemplar Fine-Tuning for 3D Human Pose Fitting Towards In-the-Wild 3D Human Pose Estimation
Apr 07, 2020

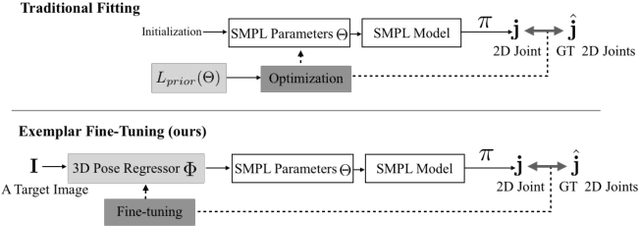
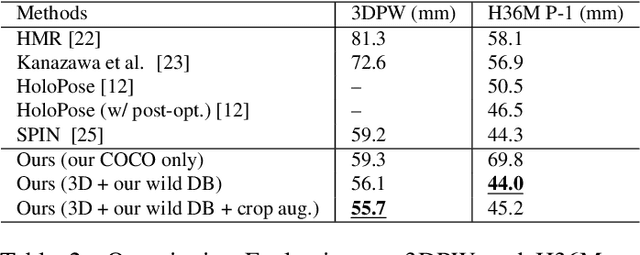
We propose a method for building large collections of human poses with full 3D annotations captured `in the wild', for which specialized capture equipment cannot be used. We start with a dataset with 2D keypoint annotations such as COCO and MPII and generates corresponding 3D poses. This is done via Exemplar Fine-Tuning (EFT), a new method to fit a 3D parametric model to 2D keypoints. EFT is accurate and can exploit a data-driven pose prior to resolve the depth reconstruction ambiguity that comes from using only 2D observations as input. We use EFT to augment these large in-the-wild datasets with plausible and accurate 3D pose annotations. We then use this data to strongly supervise a 3D pose regression network, achieving state-of-the-art results in standard benchmarks, including the ones collected outdoor. This network also achieves unprecedented 3D pose estimation quality on extremely challenging Internet videos.
Transferring Dense Pose to Proximal Animal Classes
Feb 28, 2020


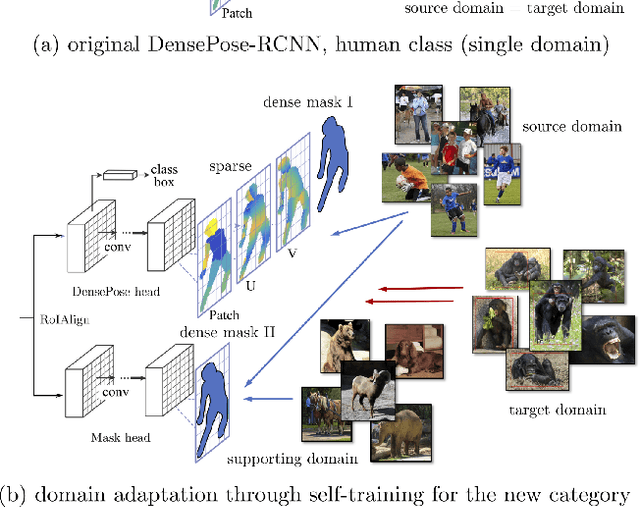
Recent contributions have demonstrated that it is possible to recognize the pose of humans densely and accurately given a large dataset of poses annotated in detail. In principle, the same approach could be extended to any animal class, but the effort required for collecting new annotations for each case makes this strategy impractical, despite important applications in natural conservation, science and business. We show that, at least for proximal animal classes such as chimpanzees, it is possible to transfer the knowledge existing in dense pose recognition for humans, as well as in more general object detectors and segmenters, to the problem of dense pose recognition in other classes. We do this by (1) establishing a DensePose model for the new animal which is also geometrically aligned to humans (2) introducing a multi-head R-CNN architecture that facilitates transfer of multiple recognition tasks between classes, (3) finding which combination of known classes can be transferred most effectively to the new animal and (4) using self-calibrated uncertainty heads to generate pseudo-labels graded by quality for training a model for this class. We also introduce two benchmark datasets labelled in the manner of DensePose for the class chimpanzee and use them to evaluate our approach, showing excellent transfer learning performance.
C3DPO: Canonical 3D Pose Networks for Non-Rigid Structure From Motion
Oct 15, 2019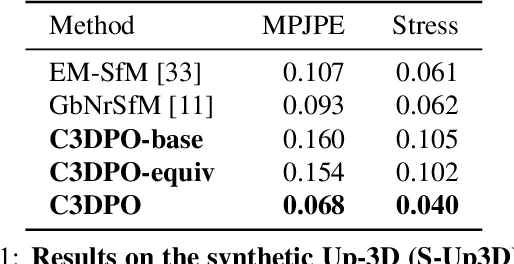
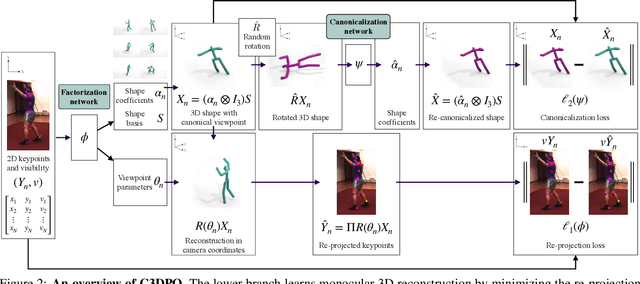
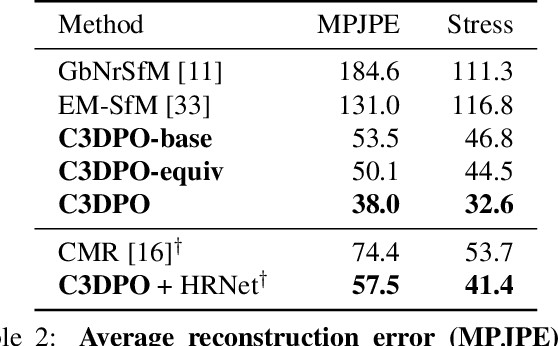
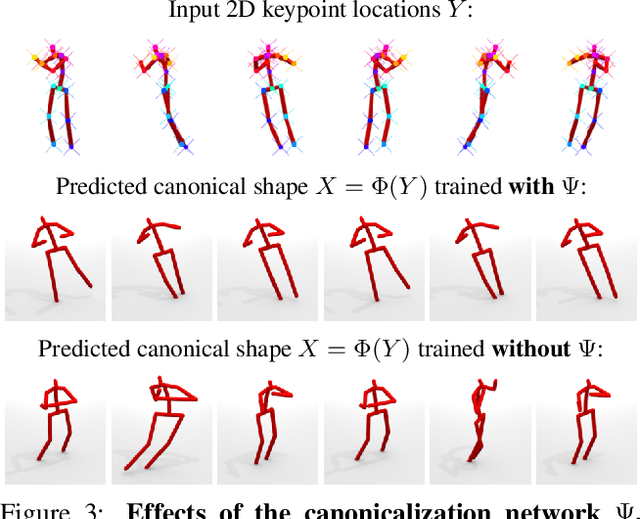
We propose C3DPO, a method for extracting 3D models of deformable objects from 2D keypoint annotations in unconstrained images. We do so by learning a deep network that reconstructs a 3D object from a single view at a time, accounting for partial occlusions, and explicitly factoring the effects of viewpoint changes and object deformations. In order to achieve this factorization, we introduce a novel regularization technique. We first show that the factorization is successful if, and only if, there exists a certain canonicalization function of the reconstructed shapes. Then, we learn the canonicalization function together with the reconstruction one, which constrains the result to be consistent. We demonstrate state-of-the-art reconstruction results for methods that do not use ground-truth 3D supervision for a number of benchmarks, including Up3D and PASCAL3D+. Source code has been made available at https://github.com/facebookresearch/c3dpo_nrsfm.
* Added a link to the source code into the abstract
COPHY: Counterfactual Learning of Physical Dynamics
Sep 26, 2019



Understanding causes and effects in mechanical systems is an essential component of reasoning in the physical world. This work poses a new problem of counterfactual learning of object mechanics from visual input. We develop the COPHY benchmark to assess the capacity of the state-of-the-art models for causal physical reasoning in a synthetic 3D environment and propose a model for learning the physical dynamics in a counterfactual setting. Having observed a mechanical experiment that involves, for example, a falling tower of blocks, a set of bouncing balls or colliding objects, we learn to predict how its outcome is affected by an arbitrary intervention on its initial conditions, such as displacing one of the objects in the scene. The alternative future is predicted given the altered past and a latent representation of the confounders learned by the model in an end-to-end fashion with no supervision. We compare against feedforward video prediction baselines and show how observing alternative experiences allows the network to capture latent physical properties of the environment, which results in significantly more accurate predictions at the level of super human performance.
Slim DensePose: Thrifty Learning from Sparse Annotations and Motion Cues
Jun 13, 2019
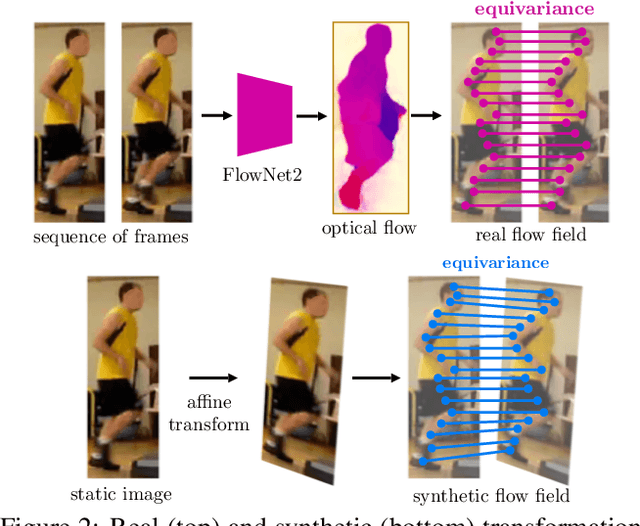
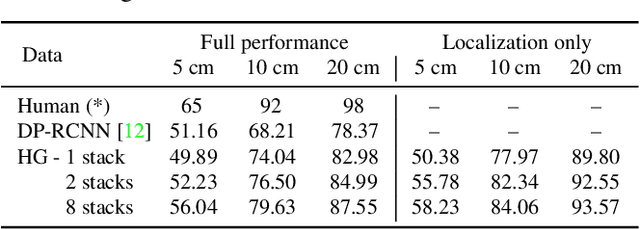

DensePose supersedes traditional landmark detectors by densely mapping image pixels to body surface coordinates. This power, however, comes at a greatly increased annotation time, as supervising the model requires to manually label hundreds of points per pose instance. In this work, we thus seek methods to significantly slim down the DensePose annotations, proposing more efficient data collection strategies. In particular, we demonstrate that if annotations are collected in video frames, their efficacy can be multiplied for free by using motion cues. To explore this idea, we introduce DensePose-Track, a dataset of videos where selected frames are annotated in the traditional DensePose manner. Then, building on geometric properties of the DensePose mapping, we use the video dynamic to propagate ground-truth annotations in time as well as to learn from Siamese equivariance constraints. Having performed exhaustive empirical evaluation of various data annotation and learning strategies, we demonstrate that doing so can deliver significantly improved pose estimation results over strong baselines. However, despite what is suggested by some recent works, we show that merely synthesizing motion patterns by applying geometric transformations to isolated frames is significantly less effective, and that motion cues help much more when they are extracted from videos.
Object Level Visual Reasoning in Videos
Sep 20, 2018

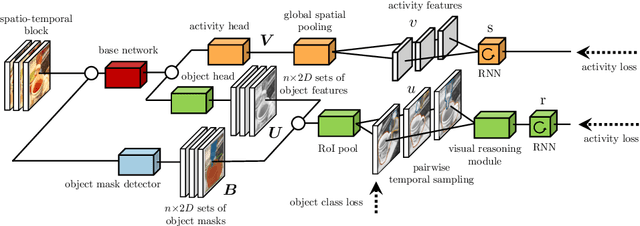
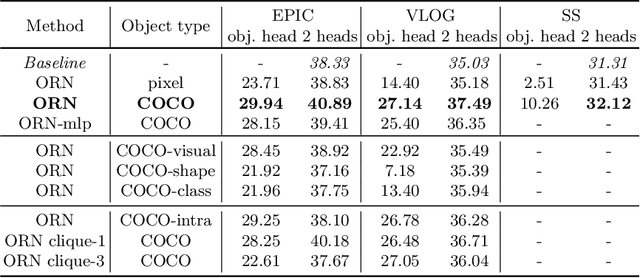
Human activity recognition is typically addressed by detecting key concepts like global and local motion, features related to object classes present in the scene, as well as features related to the global context. The next open challenges in activity recognition require a level of understanding that pushes beyond this and call for models with capabilities for fine distinction and detailed comprehension of interactions between actors and objects in a scene. We propose a model capable of learning to reason about semantically meaningful spatiotemporal interactions in videos. The key to our approach is a choice of performing this reasoning at the object level through the integration of state of the art object detection networks. This allows the model to learn detailed spatial interactions that exist at a semantic, object-interaction relevant level. We evaluate our method on three standard datasets (Twenty-BN Something-Something, VLOG and EPIC Kitchens) and achieve state of the art results on all of them. Finally, we show visualizations of the interactions learned by the model, which illustrate object classes and their interactions corresponding to different activity classes.
* Accepted at ECCV 2018 - long version (16 pages + ref)
Dense Pose Transfer
Sep 06, 2018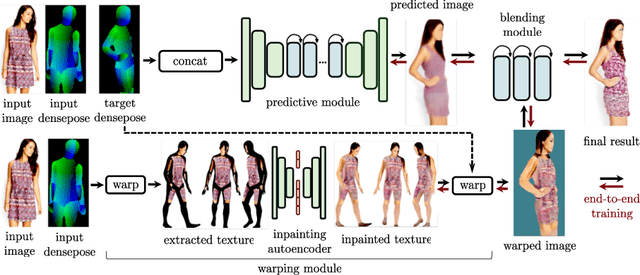
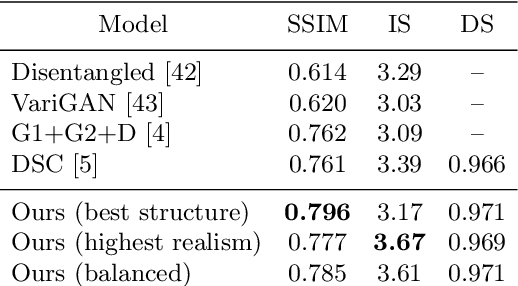
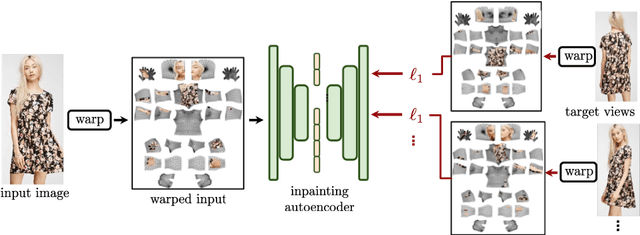
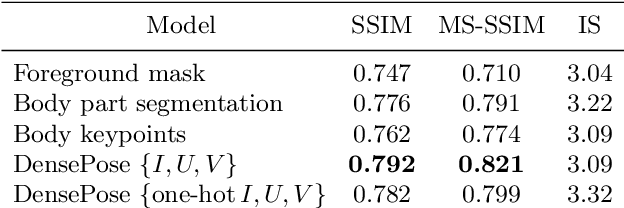
In this work we integrate ideas from surface-based modeling with neural synthesis: we propose a combination of surface-based pose estimation and deep generative models that allows us to perform accurate pose transfer, i.e. synthesize a new image of a person based on a single image of that person and the image of a pose donor. We use a dense pose estimation system that maps pixels from both images to a common surface-based coordinate system, allowing the two images to be brought in correspondence with each other. We inpaint and refine the source image intensities in the surface coordinate system, prior to warping them onto the target pose. These predictions are fused with those of a convolutional predictive module through a neural synthesis module allowing for training the whole pipeline jointly end-to-end, optimizing a combination of adversarial and perceptual losses. We show that dense pose estimation is a substantially more powerful conditioning input than landmark-, or mask-based alternatives, and report systematic improvements over state of the art generators on DeepFashion and MVC datasets.