 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Attribute Information Removal and Reconstruction for Image Manipulation
Jul 13, 2022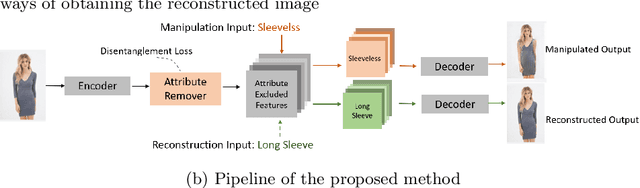
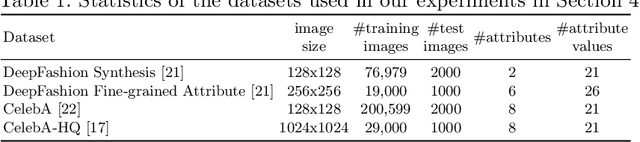
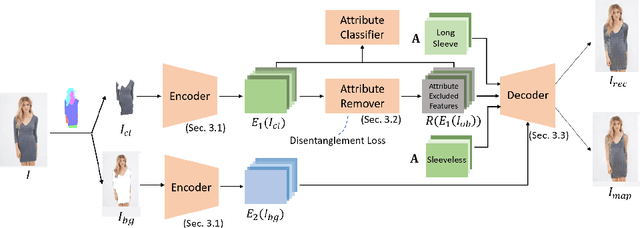
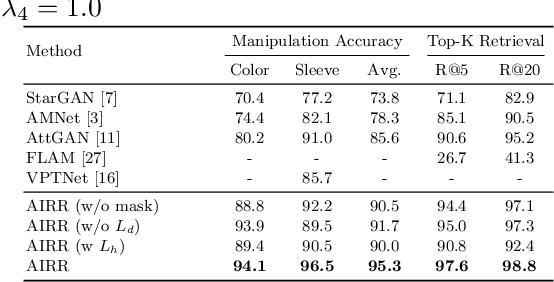
The goal of attribute manipulation is to control specified attribute(s) in given images. Prior work approaches this problem by learning disentangled representations for each attribute that enables it to manipulate the encoded source attributes to the target attributes. However, encoded attributes are often correlated with relevant image content. Thus, the source attribute information can often be hidden in the disentangled features, leading to unwanted image editing effects. In this paper, we propose an Attribute Information Removal and Reconstruction (AIRR) network that prevents such information hiding by learning how to remove the attribute information entirely, creating attribute excluded features, and then learns to directly inject the desired attributes in a reconstructed image. We evaluate our approach on four diverse datasets with a variety of attributes including DeepFashion Synthesis, DeepFashion Fine-grained Attribute, CelebA and CelebA-HQ, where our model improves attribute manipulation accuracy and top-k retrieval rate by 10% on average over prior work. A user study also reports that AIRR manipulated images are preferred over prior work in up to 76% of cases.
A Unified Weight Initialization Paradigm for Tensorial Convolutional Neural Networks
May 28, 2022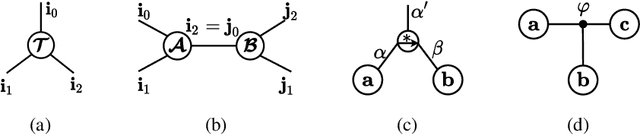
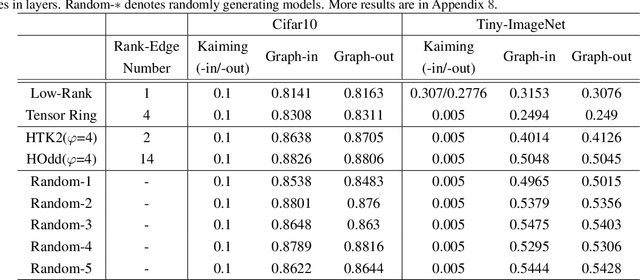
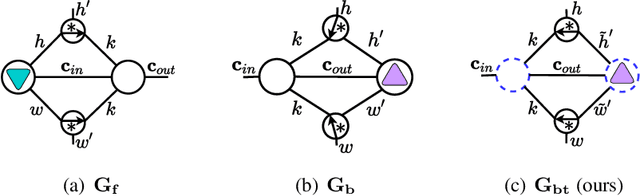

Tensorial Convolutional Neural Networks (TCNNs) have attracted much research attention for their power in reducing model parameters or enhancing the generalization ability. However, exploration of TCNNs is hindered even from weight initialization methods. To be specific, general initialization methods, such as Xavier or Kaiming initialization, usually fail to generate appropriate weights for TCNNs. Meanwhile, although there are ad-hoc approaches for specific architectures (e.g., Tensor Ring Nets), they are not applicable to TCNNs with other tensor decomposition methods (e.g., CP or Tucker decomposition). To address this problem, we propose a universal weight initialization paradigm, which generalizes Xavier and Kaiming methods and can be widely applicable to arbitrary TCNNs. Specifically, we first present the Reproducing Transformation to convert the backward process in TCNNs to an equivalent convolution process. Then, based on the convolution operators in the forward and backward processes, we build a unified paradigm to control the variance of features and gradients in TCNNs. Thus, we can derive fan-in and fan-out initialization for various TCNNs. We demonstrate that our paradigm can stabilize the training of TCNNs, leading to faster convergence and better results.
BViT: Broad Attention based Vision Transformer
Feb 13, 2022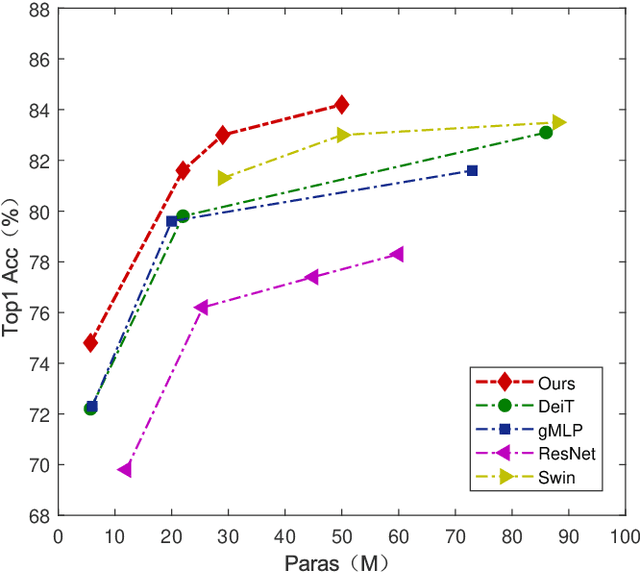
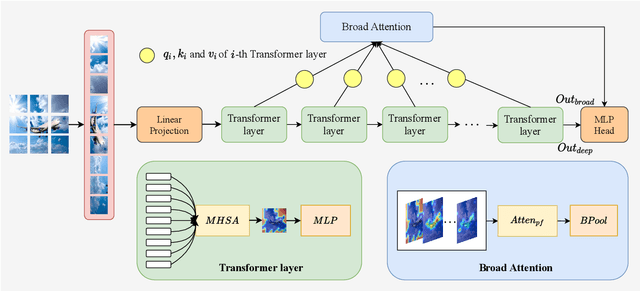
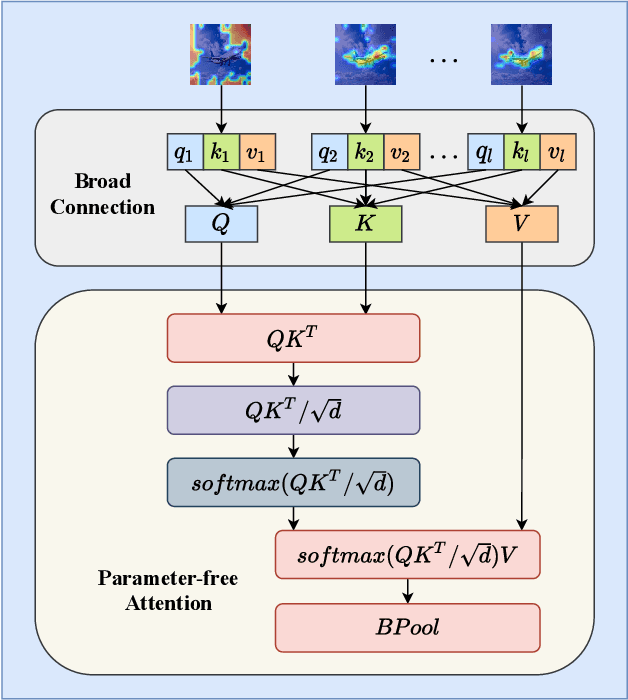
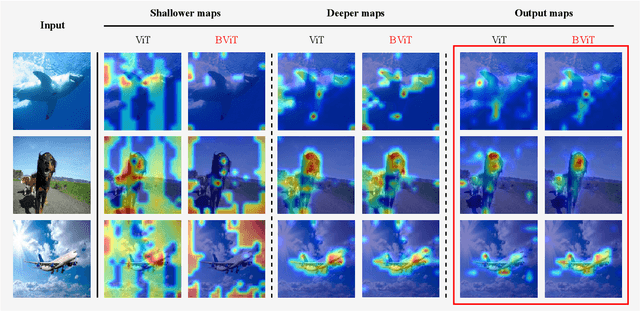
Recent works have demonstrated that transformer can achieve promising performance in computer vision, by exploiting the relationship among image patches with self-attention. While they only consider the attention in a single feature layer, but ignore the complementarity of attention in different levels. In this paper, we propose the broad attention to improve the performance by incorporating the attention relationship of different layers for vision transformer, which is called BViT. The broad attention is implemented by broad connection and parameter-free attention. Broad connection of each transformer layer promotes the transmission and integration of information for BViT. Without introducing additional trainable parameters, parameter-free attention jointly focuses on the already available attention information in different layers for extracting useful information and building their relationship. Experiments on image classification tasks demonstrate that BViT delivers state-of-the-art accuracy of 74.8\%/81.6\% top-1 accuracy on ImageNet with 5M/22M parameters. Moreover, we transfer BViT to downstream object recognition benchmarks to achieve 98.9\% and 89.9\% on CIFAR10 and CIFAR100 respectively that exceed ViT with fewer parameters. For the generalization test, the broad attention in Swin Transformer and T2T-ViT also bring an improvement of more than 1\%. To sum up, broad attention is promising to promote the performance of attention based models. Code and pre-trained models are available at https://github.com/DRL-CASIA/Broad_ViT.
Stacked BNAS: Rethinking Broad Convolutional Neural Network for Neural Architecture Search
Nov 15, 2021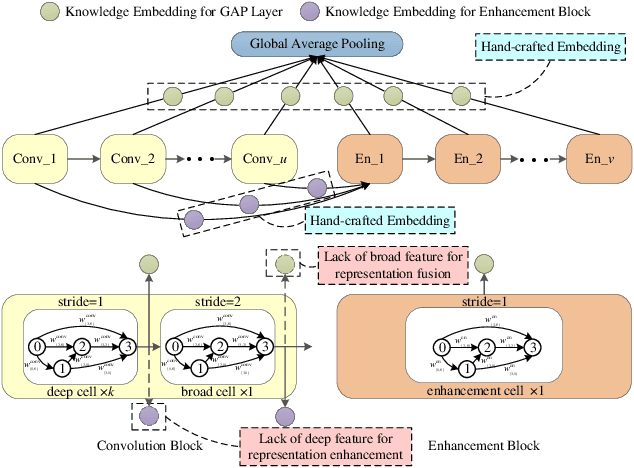
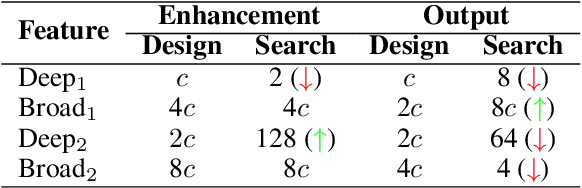
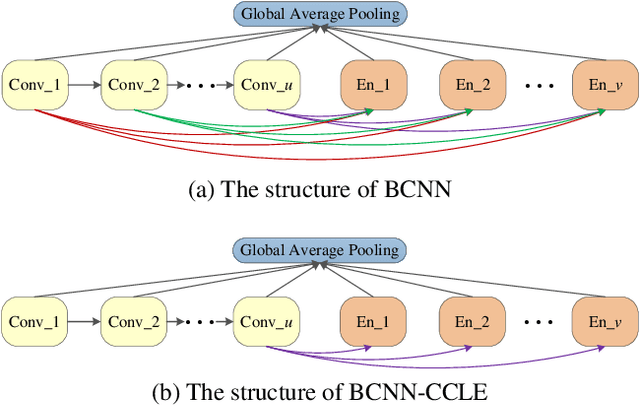
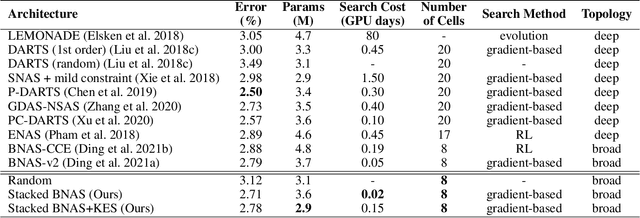
Different from other deep scalable architecture based NAS approaches, Broad Neural Architecture Search (BNAS) proposes a broad one which consists of convolution and enhancement blocks, dubbed Broad Convolutional Neural Network (BCNN) as search space for amazing efficiency improvement. BCNN reuses the topologies of cells in convolution block, so that BNAS can employ few cells for efficient search. Moreover, multi-scale feature fusion and knowledge embedding are proposed to improve the performance of BCNN with shallow topology. However, BNAS suffers some drawbacks: 1) insufficient representation diversity for feature fusion and enhancement, and 2) time consuming of knowledge embedding design by human expert. In this paper, we propose Stacked BNAS whose search space is a developed broad scalable architecture named Stacked BCNN, with better performance than BNAS. On the one hand, Stacked BCNN treats mini-BCNN as the basic block to preserve comprehensive representation and deliver powerful feature extraction ability. On the other hand, we propose Knowledge Embedding Search (KES) to learn appropriate knowledge embeddings. Experimental results show that 1) Stacked BNAS obtains better performance than BNAS, 2) KES contributes to reduce the parameters of learned architecture with satisfactory performance, and 3) Stacked BNAS delivers state-of-the-art efficiency of 0.02 GPU days.
ABCP: Automatic Block-wise and Channel-wise Network Pruning via Joint Search
Oct 08, 2021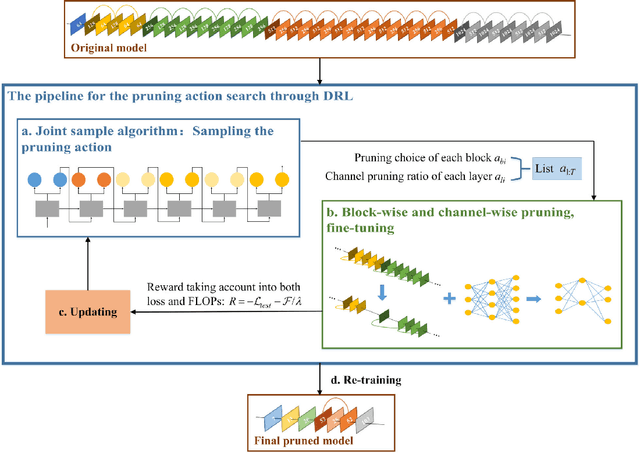
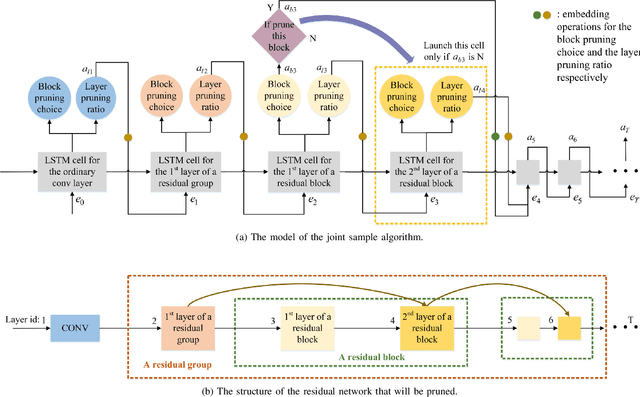


Currently, an increasing number of model pruning methods are proposed to resolve the contradictions between the computer powers required by the deep learning models and the resource-constrained devices. However, most of the traditional rule-based network pruning methods can not reach a sufficient compression ratio with low accuracy loss and are time-consuming as well as laborious. In this paper, we propose Automatic Block-wise and Channel-wise Network Pruning (ABCP) to jointly search the block-wise and channel-wise pruning action with deep reinforcement learning. A joint sample algorithm is proposed to simultaneously generate the pruning choice of each residual block and the channel pruning ratio of each convolutional layer from the discrete and continuous search space respectively. The best pruning action taking both the accuracy and the complexity of the model into account is obtained finally. Compared with the traditional rule-based pruning method, this pipeline saves human labor and achieves a higher compression ratio with lower accuracy loss. Tested on the mobile robot detection dataset, the pruned YOLOv3 model saves 99.5% FLOPs, reduces 99.5% parameters, and achieves 37.3 times speed up with only 2.8% mAP loss. The results of the transfer task on the sim2real detection dataset also show that our pruned model has much better robustness performance.
Predicate correlation learning for scene graph generation
Jul 06, 2021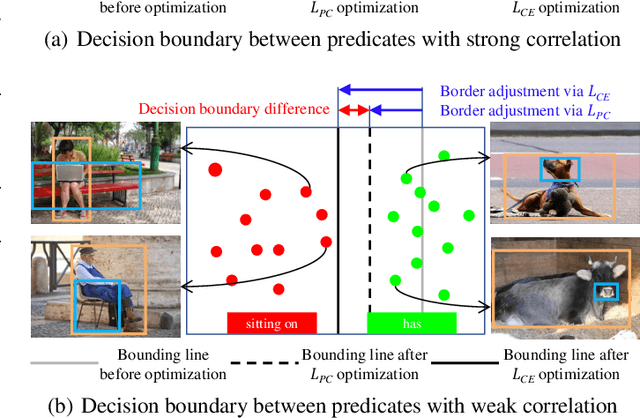
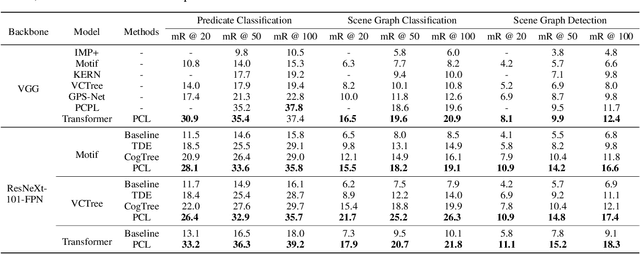
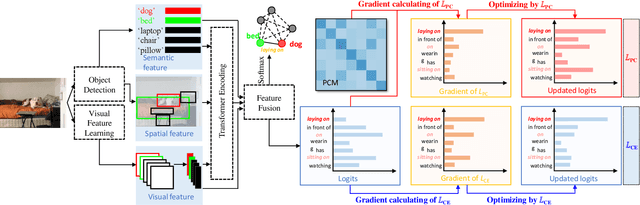
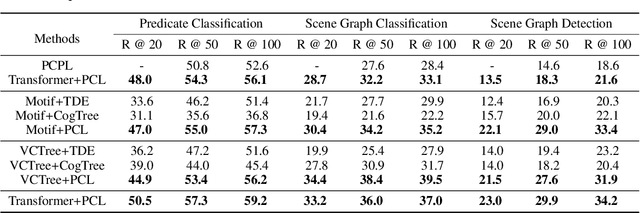
For a typical Scene Graph Generation (SGG) method, there is often a large gap in the performance of the predicates' head classes and tail classes. This phenomenon is mainly caused by the semantic overlap between different predicates as well as the long-tailed data distribution. In this paper, a Predicate Correlation Learning (PCL) method for SGG is proposed to address the above two problems by taking the correlation between predicates into consideration. To describe the semantic overlap between strong-correlated predicate classes, a Predicate Correlation Matrix (PCM) is defined to quantify the relationship between predicate pairs, which is dynamically updated to remove the matrix's long-tailed bias. In addition, PCM is integrated into a Predicate Correlation Loss function ($L_{PC}$) to reduce discouraging gradients of unannotated classes. The proposed method is evaluated on Visual Genome benchmark, where the performance of the tail classes is significantly improved when built on the existing methods.
Heuristic Rank Selection with Progressively Searching Tensor Ring Network
Sep 22, 2020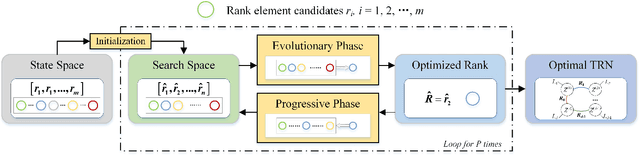
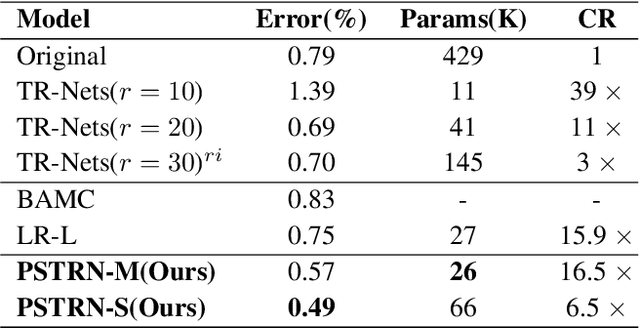
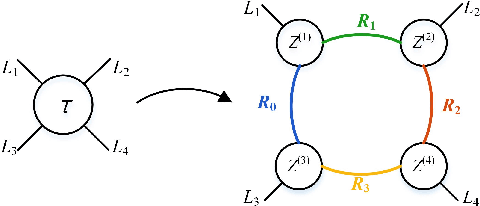
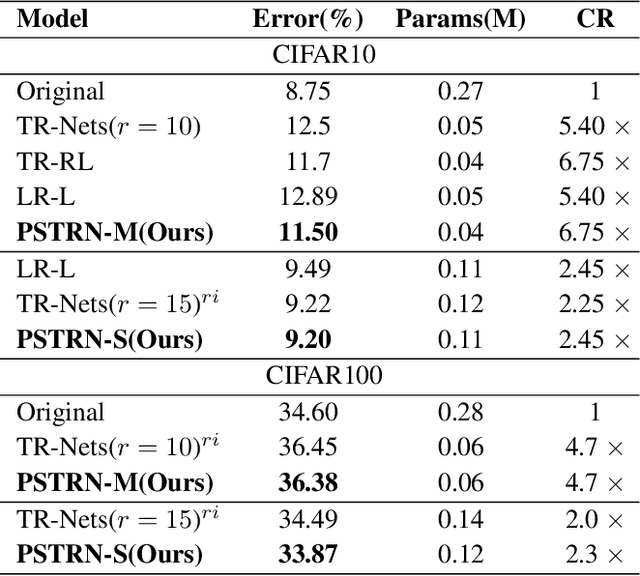
Recently, Tensor Ring Networks (TRNs) have been applied in deep networks, achieving remarkable successes in compression ratio and accuracy. Although highly related to the performance of TRNs, rank is seldom studied in previous works and usually set to equal in experiments. Meanwhile, there is not any heuristic method to choose the rank, and an enumerating way to find appropriate rank is extremely time-consuming. Interestingly, we discover that part of the rank elements is sensitive and usually aggregate in a certain region, namely an interest region. Therefore, based on the above phenomenon, we propose a novel progressive genetic algorithm named Progressively Searching Tensor Ring Network Search (PSTRN), which has the ability to find optimal rank precisely and efficiently. Through the evolutionary phase and progressive phase, PSTRN can converge to the interest region quickly and harvest good performance. Experimental results show that PSTRN can significantly reduce the complexity of seeking rank, compared with the enumerating method. Furthermore, our method is validated on public benchmarks like MNIST, CIFAR10/100 and HMDB51, achieving state-of-the-art performance.
Faster Gradient-based NAS Pipeline Combining Broad Scalable Architecture with Confident Learning Rate
Sep 21, 2020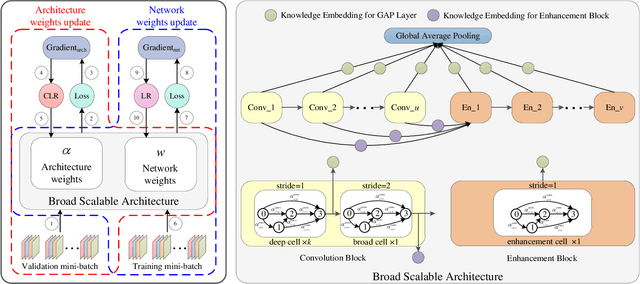
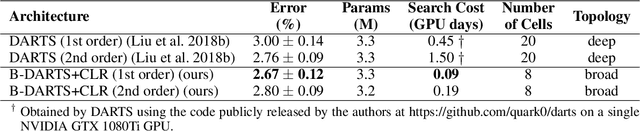
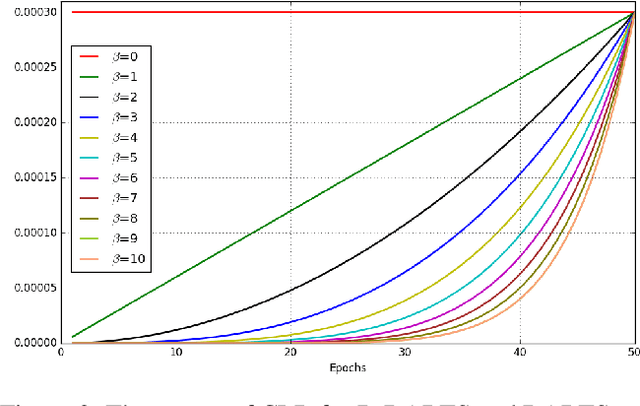
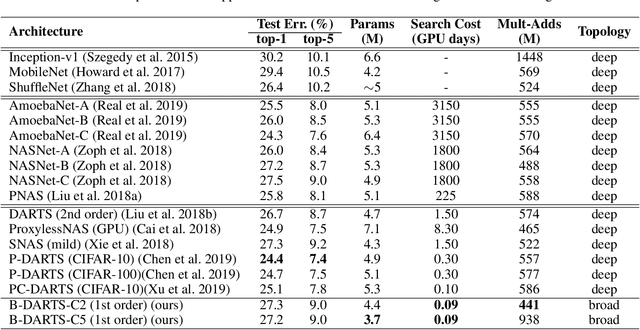
In order to further improve the search efficiency of Neural Architecture Search (NAS), we propose B-DARTS, a novel pipeline combining broad scalable architecture with Confident Learning Rate (CLR). In B-DARTS, Broad Convolutional Neural Network (BCNN) is employed as the scalable architecture for DARTS, a popular differentiable NAS approach. On one hand, BCNN is a broad scalable architecture whose topology achieves two advantages compared with the deep one, mainly including faster single-step training speed and higher memory efficiency (i.e. larger batch size for architecture search), which are all contributed to the search efficiency improvement of NAS. On the other hand, DARTS discovers the optimal architecture by gradient-based optimization algorithm, which benefits from two superiorities of BCNN simultaneously. Similar to vanilla DARTS, B-DARTS also suffers from the performance collapse issue, where those weight-free operations are prone to be selected by the search strategy. Therefore, we propose CLR, that considers the confidence of gradient for architecture weights update increasing with the training time of over-parameterized model, to mitigate the above issue. Experimental results on CIFAR-10 and ImageNet show that 1) B-DARTS delivers state-of-the-art efficiency of 0.09 GPU day using first order approximation on CIFAR-10; 2) the learned architecture by B-DARTS achieves competitive performance using state-of-the-art composite multiply-accumulate operations and parameters on ImageNet; and 3) the proposed CLR is effective for performance collapse issue alleviation of both B-DARTS and DARTS.
Towards Visual Distortion in Black-Box Attacks
Jul 21, 2020
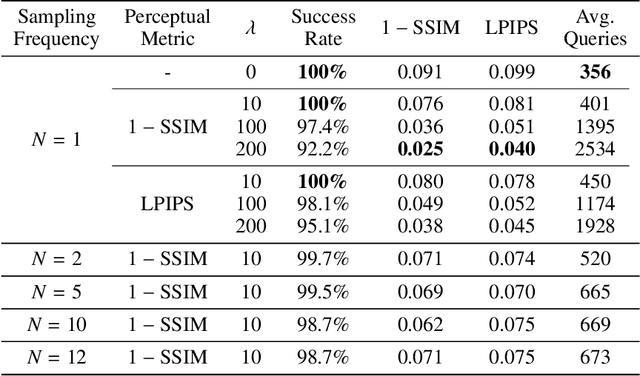


Constructing adversarial examples in a black-box threat model injures the original images by introducing visual distortion. In this paper, we propose a novel black-box attack approach that can directly minimize the induced distortion by learning the noise distribution of the adversarial example, assuming only loss-oracle access to the black-box network. The quantified visual distortion, which measures the perceptual distance between the adversarial example and the original image, is introduced in our loss whilst the gradient of the corresponding non-differentiable loss function is approximated by sampling noise from the learned noise distribution. We validate the effectiveness of our attack on ImageNet. Our attack results in much lower distortion when compared to the state-of-the-art black-box attacks and achieves $100\%$ success rate on ResNet50 and VGG16bn. The code is available at https://github.com/Alina-1997/visual-distortion-in-attack.
Learning Compact Reward for Image Captioning
Mar 24, 2020
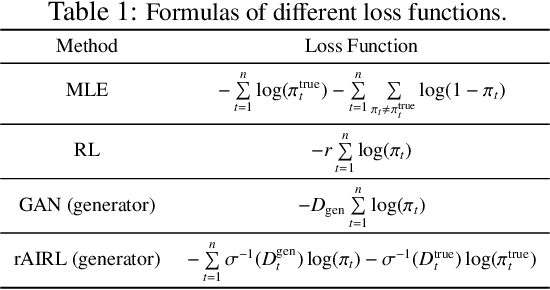

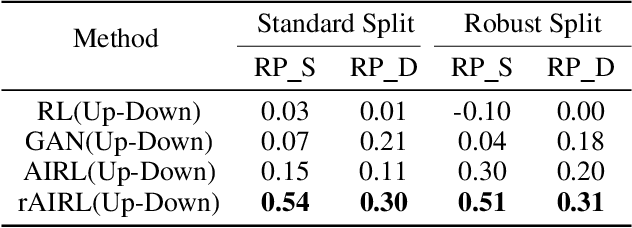
Adversarial learning has shown its advances in generating natural and diverse descriptions in image captioning. However, the learned reward of existing adversarial methods is vague and ill-defined due to the reward ambiguity problem. In this paper, we propose a refined Adversarial Inverse Reinforcement Learning (rAIRL) method to handle the reward ambiguity problem by disentangling reward for each word in a sentence, as well as achieve stable adversarial training by refining the loss function to shift the generator towards Nash equilibrium. In addition, we introduce a conditional term in the loss function to mitigate mode collapse and to increase the diversity of the generated descriptions. Our experiments on MS COCO and Flickr30K show that our method can learn compact reward for image captioning.