 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Multi-Instance Transfer Learning
Dec 10, 2014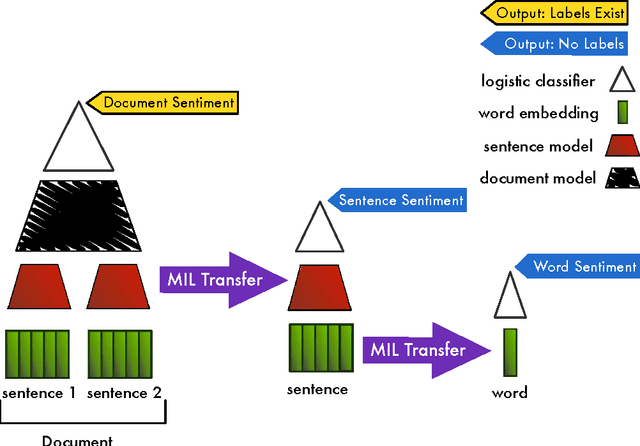

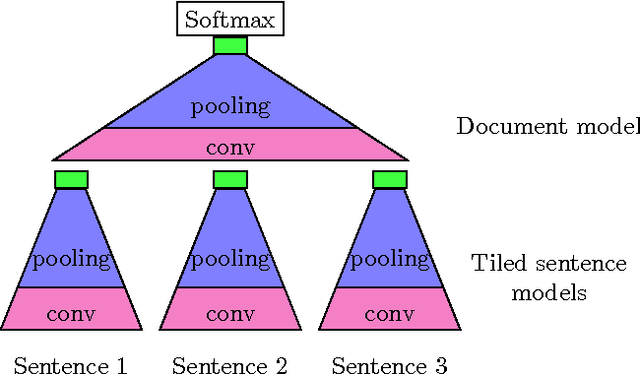

We present a new approach for transferring knowledge from groups to individuals that comprise them. We evaluate our method in text, by inferring the ratings of individual sentences using full-review ratings. This approach, which combines ideas from transfer learning, deep learning and multi-instance learning, reduces the need for laborious human labelling of fine-grained data when abundant labels are available at the group level.
Predicting Parameters in Deep Learning
Oct 27, 2014

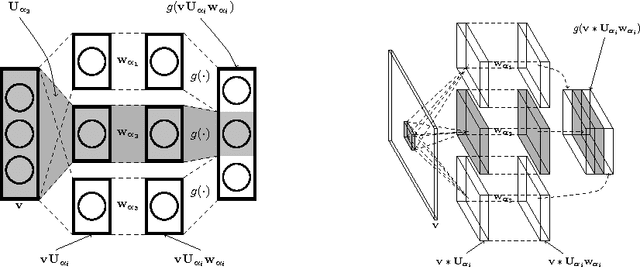
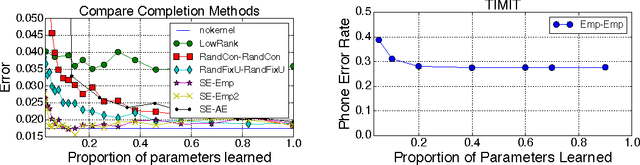
We demonstrate that there is significant redundancy in the parameterization of several deep learning models. Given only a few weight values for each feature it is possible to accurately predict the remaining values. Moreover, we show that not only can the parameter values be predicted, but many of them need not be learned at all. We train several different architectures by learning only a small number of weights and predicting the rest. In the best case we are able to predict more than 95% of the weights of a network without any drop in accuracy.
Proceedings of the Twenty-Eighth Conference on Uncertainty in Artificial Intelligence (2012)
Aug 28, 2014This is the Proceedings of the Twenty-Eighth Conference on Uncertainty in Artificial Intelligence, which was held on Catalina Island, CA August 14-18 2012.
Theoretical Analysis of Bayesian Optimisation with Unknown Gaussian Process Hyper-Parameters
Jun 30, 2014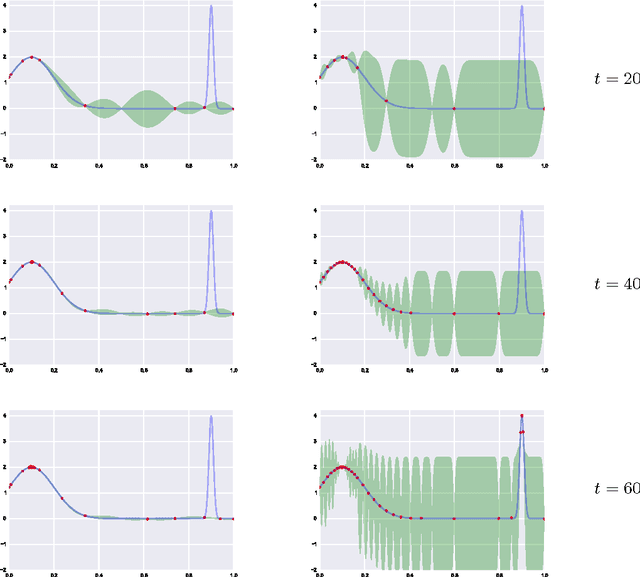
Bayesian optimisation has gained great popularity as a tool for optimising the parameters of machine learning algorithms and models. Somewhat ironically, setting up the hyper-parameters of Bayesian optimisation methods is notoriously hard. While reasonable practical solutions have been advanced, they can often fail to find the best optima. Surprisingly, there is little theoretical analysis of this crucial problem in the literature. To address this, we derive a cumulative regret bound for Bayesian optimisation with Gaussian processes and unknown kernel hyper-parameters in the stochastic setting. The bound, which applies to the expected improvement acquisition function and sub-Gaussian observation noise, provides us with guidelines on how to design hyper-parameter estimation methods. A simple simulation demonstrates the importance of following these guidelines.
Modelling, Visualising and Summarising Documents with a Single Convolutional Neural Network
Jun 15, 2014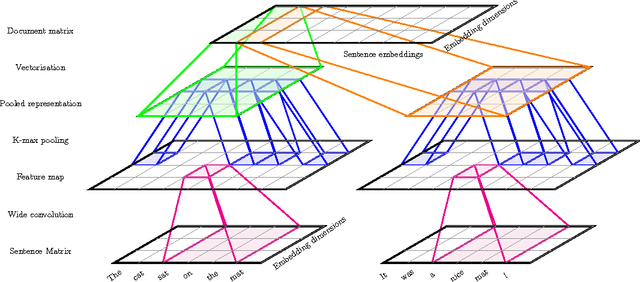

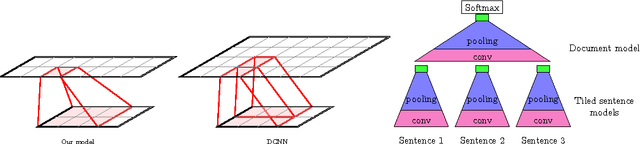
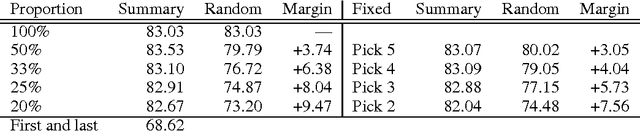
Capturing the compositional process which maps the meaning of words to that of documents is a central challenge for researchers in Natural Language Processing and Information Retrieval. We introduce a model that is able to represent the meaning of documents by embedding them in a low dimensional vector space, while preserving distinctions of word and sentence order crucial for capturing nuanced semantics. Our model is based on an extended Dynamic Convolution Neural Network, which learns convolution filters at both the sentence and document level, hierarchically learning to capture and compose low level lexical features into high level semantic concepts. We demonstrate the effectiveness of this model on a range of document modelling tasks, achieving strong results with no feature engineering and with a more compact model. Inspired by recent advances in visualising deep convolution networks for computer vision, we present a novel visualisation technique for our document networks which not only provides insight into their learning process, but also can be interpreted to produce a compelling automatic summarisation system for texts.
Distributed Parameter Estimation in Probabilistic Graphical Models
Jun 11, 2014

This paper presents foundational theoretical results on distributed parameter estimation for undirected probabilistic graphical models. It introduces a general condition on composite likelihood decompositions of these models which guarantees the global consistency of distributed estimators, provided the local estimators are consistent.
A Deep Architecture for Semantic Parsing
Apr 29, 2014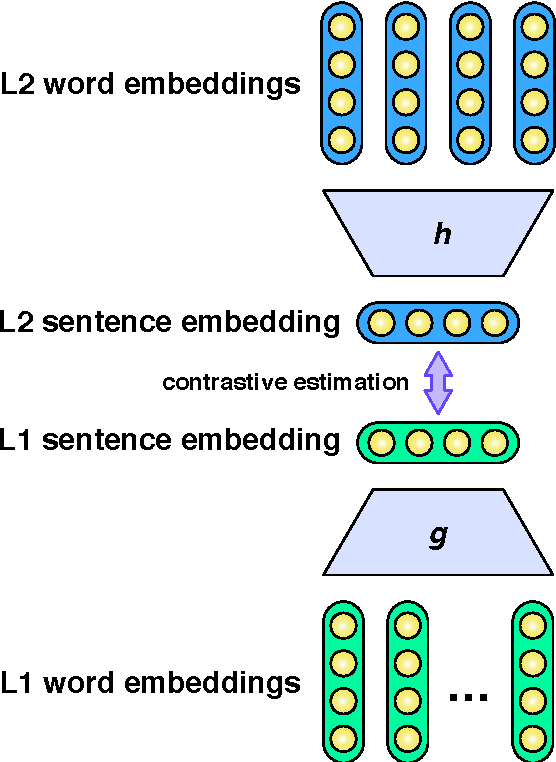
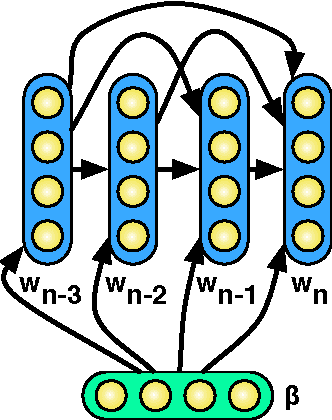
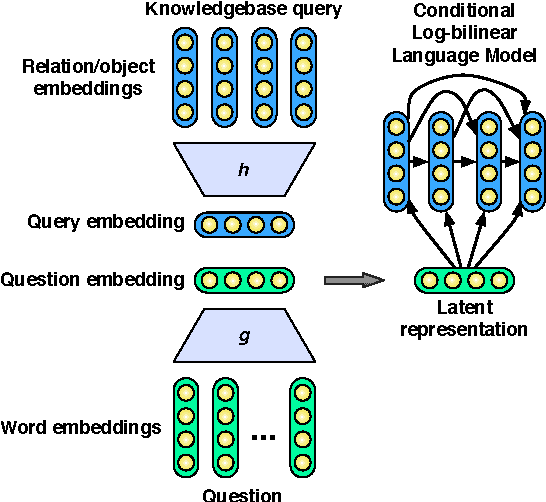
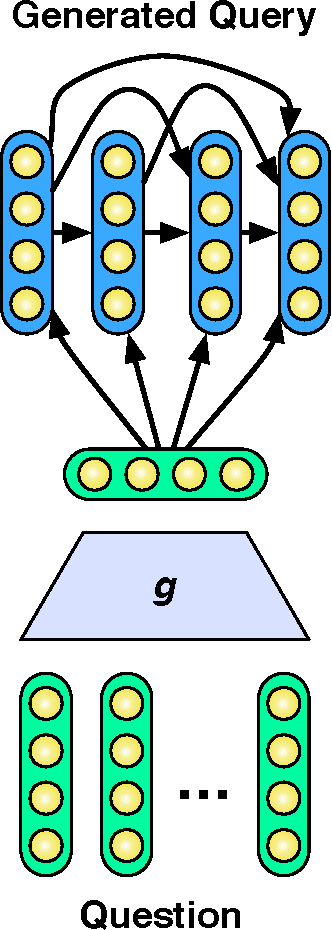
Many successful approaches to semantic parsing build on top of the syntactic analysis of text, and make use of distributional representations or statistical models to match parses to ontology-specific queries. This paper presents a novel deep learning architecture which provides a semantic parsing system through the union of two neural models of language semantics. It allows for the generation of ontology-specific queries from natural language statements and questions without the need for parsing, which makes it especially suitable to grammatically malformed or syntactically atypical text, such as tweets, as well as permitting the development of semantic parsers for resource-poor languages.
Bayesian Multi-Scale Optimistic Optimization
Feb 27, 2014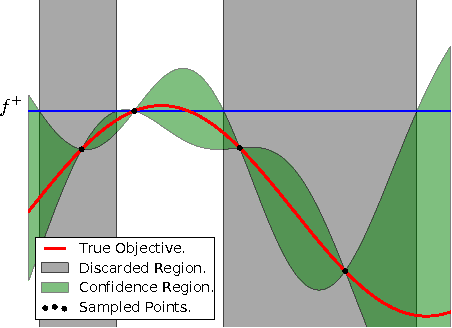

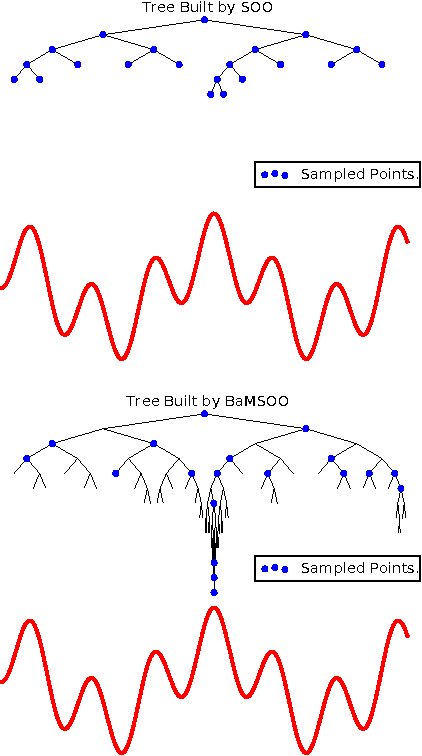
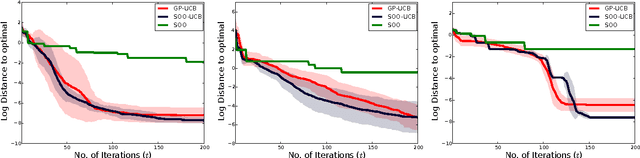
Bayesian optimization is a powerful global optimization technique for expensive black-box functions. One of its shortcomings is that it requires auxiliary optimization of an acquisition function at each iteration. This auxiliary optimization can be costly and very hard to carry out in practice. Moreover, it creates serious theoretical concerns, as most of the convergence results assume that the exact optimum of the acquisition function can be found. In this paper, we introduce a new technique for efficient global optimization that combines Gaussian process confidence bounds and treed simultaneous optimistic optimization to eliminate the need for auxiliary optimization of acquisition functions. The experiments with global optimization benchmarks and a novel application to automatic information extraction demonstrate that the resulting technique is more efficient than the two approaches from which it draws inspiration. Unlike most theoretical analyses of Bayesian optimization with Gaussian processes, our finite-time convergence rate proofs do not require exact optimization of an acquisition function. That is, our approach eliminates the unsatisfactory assumption that a difficult, potentially NP-hard, problem has to be solved in order to obtain vanishing regret rates.
Linear and Parallel Learning of Markov Random Fields
Feb 05, 2014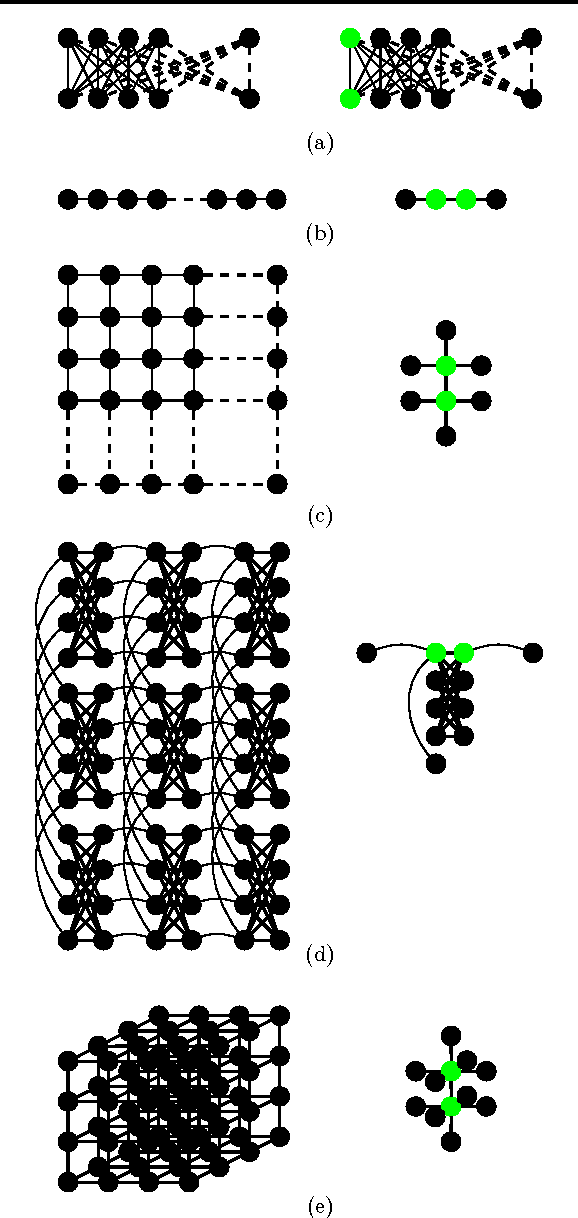
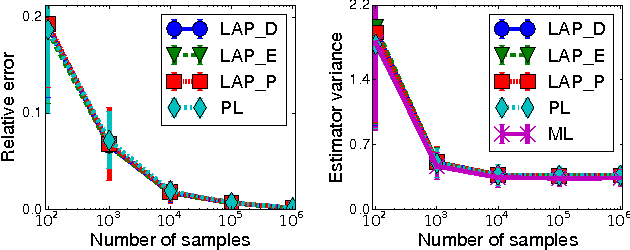
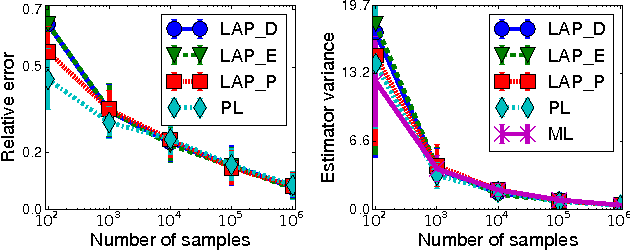
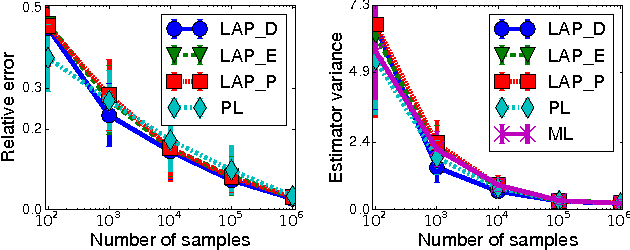
We introduce a new embarrassingly parallel parameter learning algorithm for Markov random fields with untied parameters which is efficient for a large class of practical models. Our algorithm parallelizes naturally over cliques and, for graphs of bounded degree, its complexity is linear in the number of cliques. Unlike its competitors, our algorithm is fully parallel and for log-linear models it is also data efficient, requiring only the local sufficient statistics of the data to estimate parameters.
Exploiting correlation and budget constraints in Bayesian multi-armed bandit optimization
Nov 11, 2013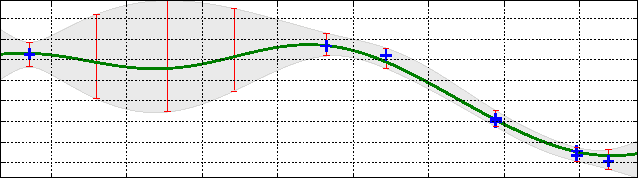
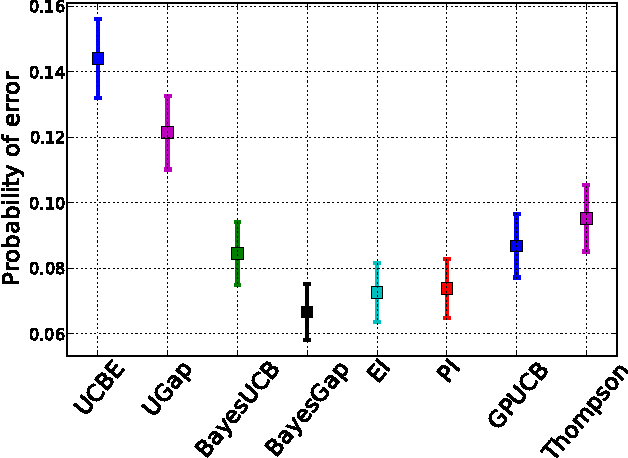
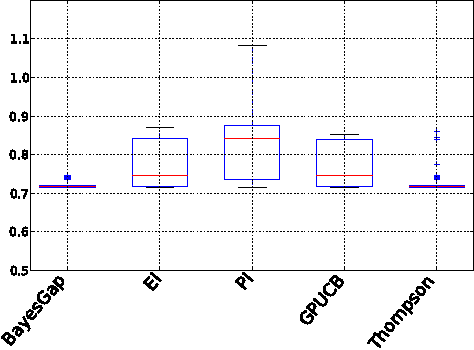
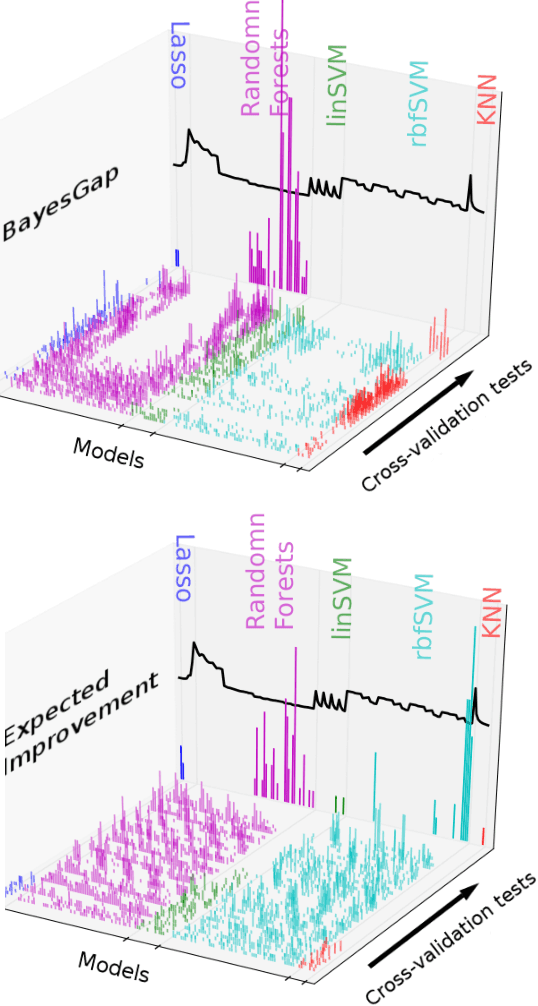
We address the problem of finding the maximizer of a nonlinear smooth function, that can only be evaluated point-wise, subject to constraints on the number of permitted function evaluations. This problem is also known as fixed-budget best arm identification in the multi-armed bandit literature. We introduce a Bayesian approach for this problem and show that it empirically outperforms both the existing frequentist counterpart and other Bayesian optimization methods. The Bayesian approach places emphasis on detailed modelling, including the modelling of correlations among the arms. As a result, it can perform well in situations where the number of arms is much larger than the number of allowed function evaluation, whereas the frequentist counterpart is inapplicable. This feature enables us to develop and deploy practical applications, such as automatic machine learning toolboxes. The paper presents comprehensive comparisons of the proposed approach, Thompson sampling, classical Bayesian optimization techniques, more recent Bayesian bandit approaches, and state-of-the-art best arm identification methods. This is the first comparison of many of these methods in the literature and allows us to examine the relative merits of their different features.