 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dual-Feature Extractor Framework for Accurate Back Depth and Spine Morphology Estimation from Monocular RGB Images
Jul 30, 2025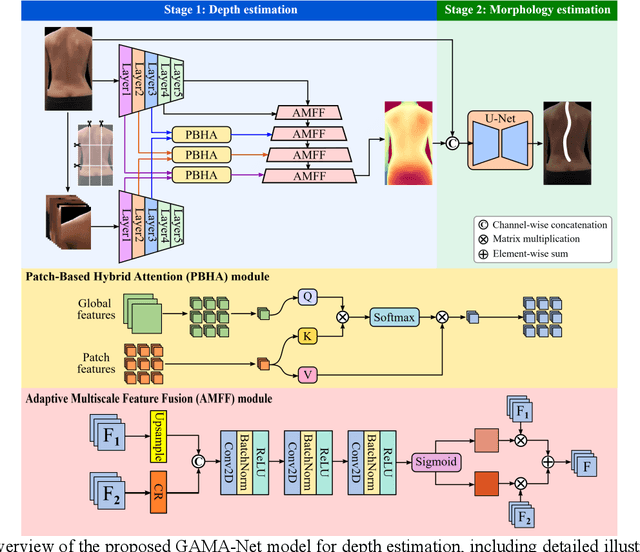

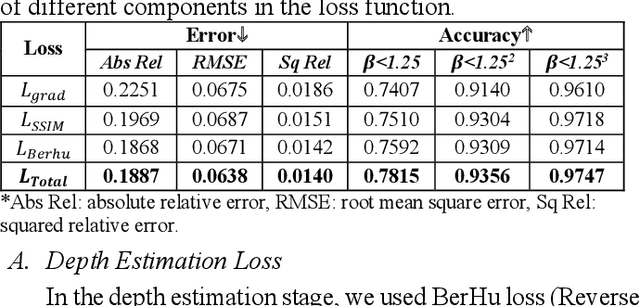

Scoliosis is a prevalent condition that impacts both physical health and appearance, with adolescent idiopathic scoliosis (AIS) being the most common form. Currently, the main AIS assessment tool, X-rays, poses significant limitations, including radiation exposure and limited accessibility in poor and remote areas. To address this problem, the current solutions are using RGB images to analyze spine morphology. However, RGB images are highly susceptible to environmental factors, such as lighting conditions, compromising model stability and generalizability. Therefore, in this study, we propose a novel pipeline to accurately estimate the depth information of the unclothed back, compensating for the limitations of 2D information, and then estimate spine morphology by integrating both depth and surface information. To capture the subtle depth variations of the back surface with precision, we design an adaptive multiscale feature learning network named Grid-Aware Multiscale Adaptive Network (GAMA-Net). This model uses dual encoders to extract both patch-level and global features, which are then interacted by the Patch-Based Hybrid Attention (PBHA) module. The Adaptive Multiscale Feature Fusion (AMFF) module is used to dynamically fuse information in the decoder. As a result, our depth estimation model achieves remarkable accuracy across three different evaluation metrics, with scores of nearly 78.2%, 93.6%, and 97.5%, respectively. To further validate the effectiveness of the predicted depth, we integrate both surface and depth information for spine morphology estimation. This integrated approach enhances the accuracy of spine curve generation, achieving an impressive performance of up to 97%.
Unsupervised Light Field Depth Estimation via Multi-view Feature Matching with Occlusion Prediction
Jan 20, 2023Depth estimation from light field (LF) images is a fundamental step for some applications. Recently, learning-based methods have achieved higher accuracy and efficiency than the traditional methods. However, it is costly to obtain sufficient depth labels for supervised training. In this paper, we propose an unsupervised framework to estimate depth from LF images. First, we design a disparity estimation network (DispNet) with a coarse-to-fine structure to predict disparity maps from different view combinations by performing multi-view feature matching to learn the correspondences more effectively. As occlusions may cause the violation of photo-consistency, we design an occlusion prediction network (OccNet) to predict the occlusion maps, which are used as the element-wise weights of photometric loss to solve the occlusion issue and assist the disparity learning. With the disparity maps estimated by multiple input combinations, we propose a disparity fusion strategy based on the estimated errors with effective occlusion handling to obtain the final disparity map. Experimental results demonstrate that our method achieves superior performance on both the dense and sparse LF images, and also has better generalization ability to the real-world LF images.
LRT: An Efficient Low-Light Restoration Transformer for Dark Light Field Images
Sep 06, 2022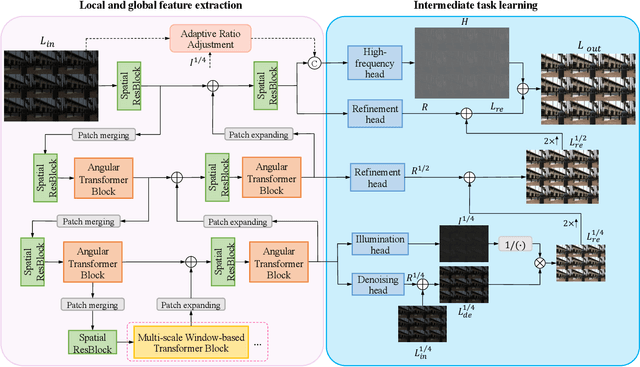

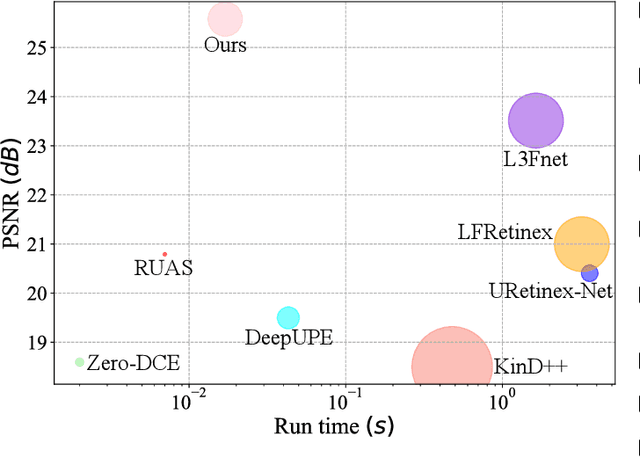

Light field (LF) images with the multi-view property have many applications, which can be severely affected by the low-light imaging. Recent learning-based methods for low-light enhancement have their own disadvantages, such as no noise suppression, complex training process and poor performance in extremely low-light conditions. Targeted on solving these deficiencies while fully utilizing the multi-view information, we propose an efficient Low-light Restoration Transformer (LRT) for LF images, with multiple heads to perform specific intermediate tasks, including denoising, luminance adjustment, refinement and detail enhancement, within a single network, achieving progressive restoration from small scale to full scale. We design an angular transformer block with a view-token scheme to model the global angular relationship efficiently, and a multi-scale window-based transformer block to encode the multi-scale local and global spatial information. To solve the problem of insufficient training data, we formulate a synthesis pipeline by simulating the major noise with the estimated noise parameters of LF camera. Experimental results demonstrate that our method can achieve superior performance on the restoration of extremely low-light and noisy LF images with high efficiency.
Partial Gradient Optimal Thresholding Algorithms for a Class of Sparse Optimization Problems
Jul 19, 2021
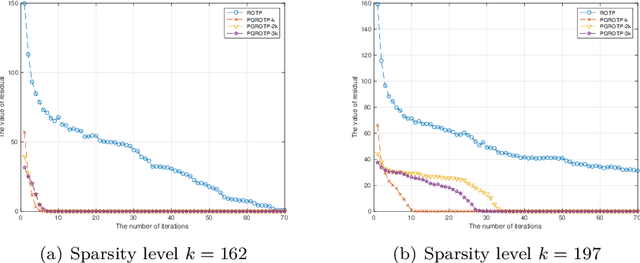
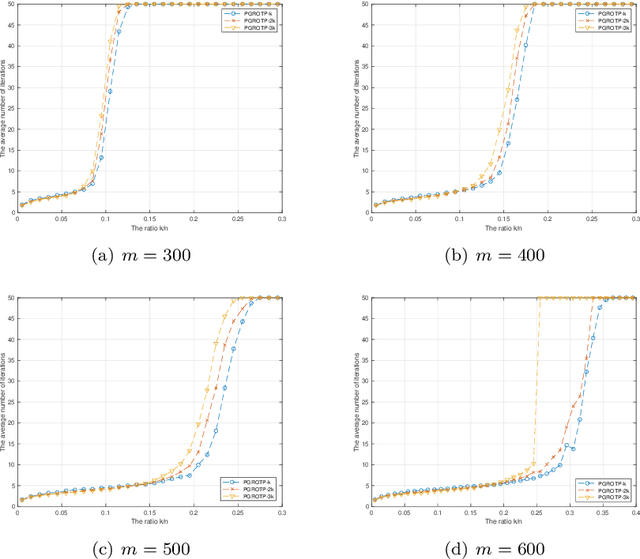
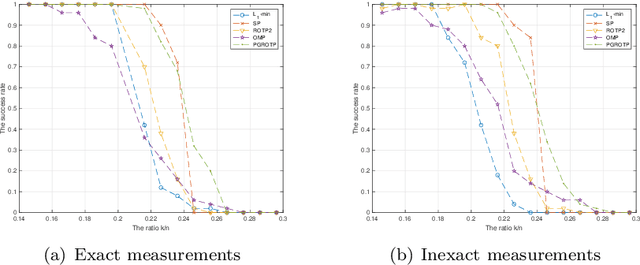
The optimization problems with a sparsity constraint is a class of important global optimization problems. A typical type of thresholding algorithms for solving such a problem adopts the traditional full steepest descent direction or Newton-like direction as a search direction to generate an iterate on which a certain thresholding is performed. Traditional hard thresholding discards a large part of a vector when the vector is dense. Thus a large part of important information contained in a dense vector has been lost in such a thresholding process. Recent study [Zhao, SIAM J Optim, 30(1), pp. 31-55, 2020] shows that the hard thresholding should be applied to a compressible vector instead of a dense vector to avoid a big loss of information. On the other hand, the optimal $k$-thresholding as a novel thresholding technique may overcome the intrinsic drawback of hard thresholding, and performs thresholding and objective function minimization simultaneously. This motivates us to propose the so-called partial gradient optimal thresholding method in this paper, which is an integration of the partial gradient and the optimal $k$-thresholding technique. The solution error bound and convergence for the proposed algorithms have been established in this paper under suitable conditions. Application of our results to the sparse optimization problems arising from signal recovery is also discussed. Experiment results from synthetic data indicate that the proposed algorithm called PGROTP is efficient and comparable to several existing algorithms.
Newton-Type Optimal Thresholding Algorithms for Sparse Optimization Problems
Apr 06, 2021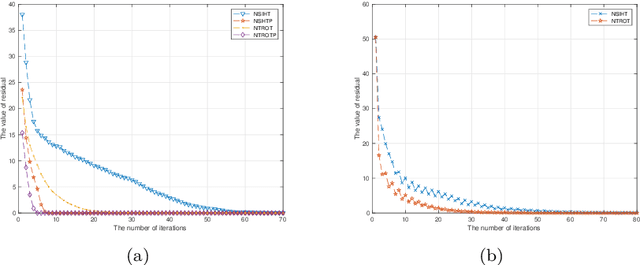
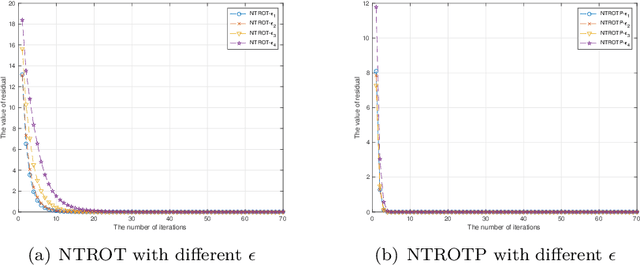
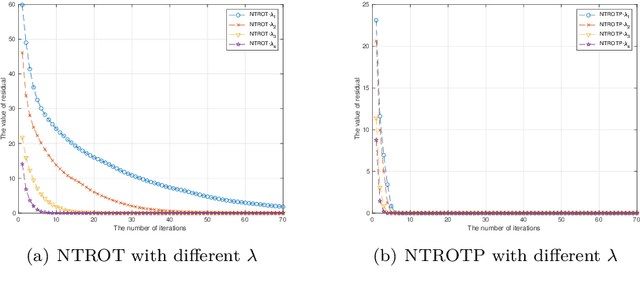
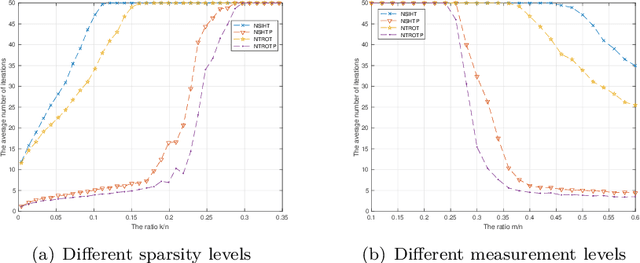
Sparse signals can be possibly reconstructed by an algorithm which merges a traditional nonlinear optimization method and a certain thresholding technique. Different from existing thresholding methods, a novel thresholding technique referred to as the optimal $k$-thresholding was recently proposed by Zhao [SIAM J Optim, 30(1), pp. 31-55, 2020]. This technique simultaneously performs the minimization of an error metric for the problem and thresholding of the iterates generated by the classic gradient method. In this paper, we propose the so-called Newton-type optimal $k$-thresholding (NTOT) algorithm which is motivated by the appreciable performance of both Newton-type methods and the optimal $k$-thresholding technique for signal recovery. The guaranteed performance (including convergence) of the proposed algorithms are shown in terms of suitable choices of the algorithmic parameters and the restricted isometry property (RIP) of the sensing matrix which has been widely used in the analysis of compressive sensing algorithms. The simulation results based on synthetic signals indicate that the proposed algorithms are stable and efficient for signal recovery.
Light Field View Synthesis via Aperture Flow and Propagation Confidence Map
Sep 07, 2020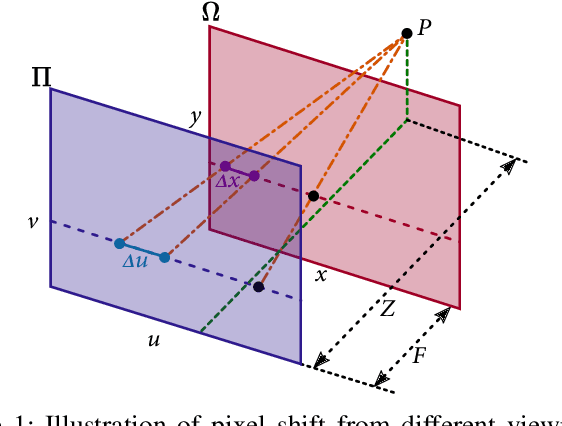


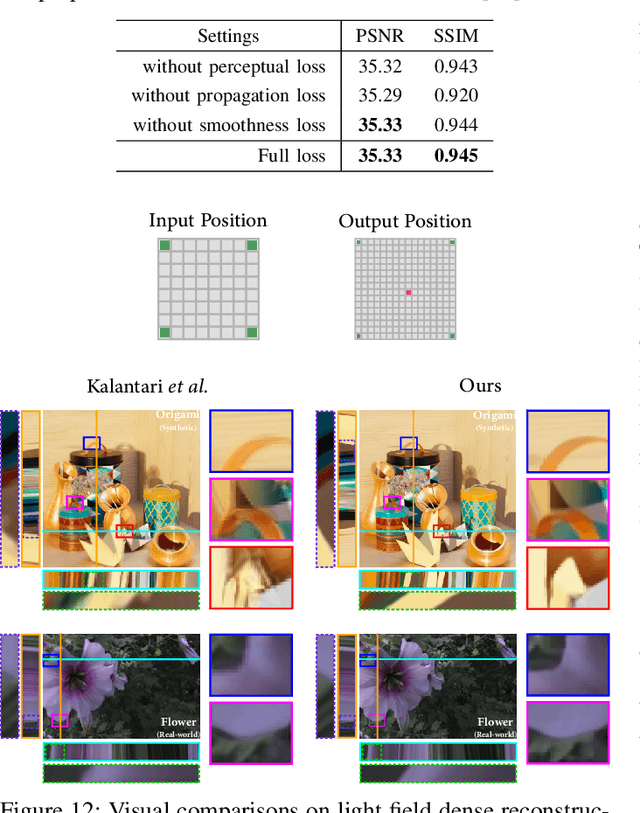
This paper presents a learning-based approach to synthesize the view from an arbitrary camera position given a sparse set of images. A key challenge for this novel view synthesis arises from the reconstruction process, when the views from different input images may not be consistent due to obstruction in the light path. We overcome this by jointly modeling the epipolar property and occlusion in designing a convolutional neural network. We start by defining and computing an aperture flow map, which approximates the parallax and measures the pixel-wise shift between two views. While this relates to free-space rendering and can fail near the object boundaries, we further develop a propagation confidence map to address pixel occlusion in these challenging regions. The proposed method is evaluated on diverse real-world and synthetic light field scenes, and it shows outstanding performance over several state-of-the-art techniques.
High-Order Residual Network for Light Field Super-Resolution
Mar 29, 2020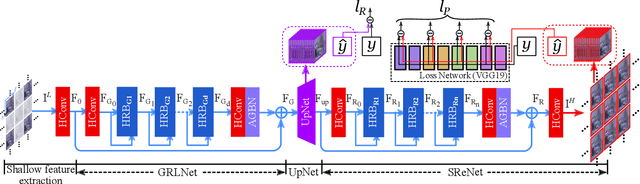
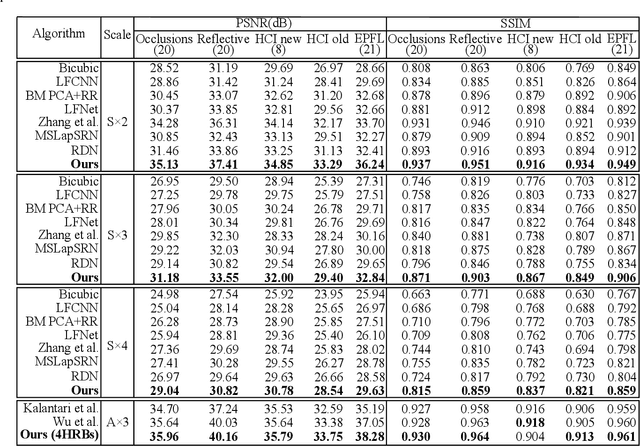
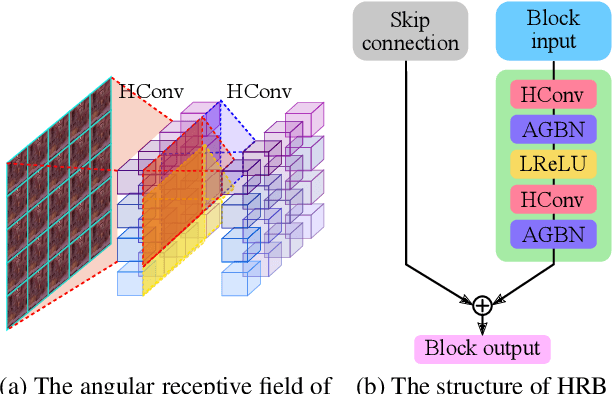
Plenoptic cameras usually sacrifice the spatial resolution of their SAIs to acquire geometry information from different viewpoints. Several methods have been proposed to mitigate such spatio-angular trade-off, but seldom make use of the structural properties of the light field (LF) data efficiently. In this paper, we propose a novel high-order residual network to learn the geometric features hierarchically from the LF for reconstruction. An important component in the proposed network is the high-order residual block (HRB), which learns the local geometric features by considering the information from all input views. After fully obtaining the local features learned from each HRB, our model extracts the representative geometric features for spatio-angular upsampling through the global residual learning. Additionally, a refinement network is followed to further enhance the spatial details by minimizing a perceptual loss. Compared with previous work, our model is tailored to the rich structure inherent in the LF, and therefore can reduce the artifacts near non-Lambertian and occlusion regions. Experimental results show that our approach enables high-quality reconstruction even in challenging regions and outperforms state-of-the-art single image or LF reconstruction methods with both quantitative measurements and visual evaluation.
High-dimensional Dense Residual Convolutional Neural Network for Light Field Reconstruction
Oct 12, 2019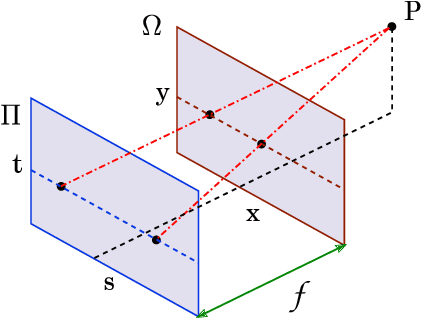
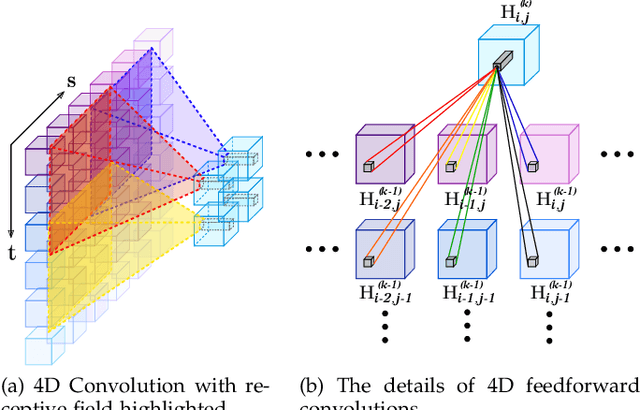

We consider the problem of high-dimensional light field reconstruction and develop a learning-based framework for spatial and angular super-resolution. Many current approaches either require disparity clues or restore the spatial and angular details separately. Such methods have difficulties with non-Lambertian surfaces or occlusions. In contrast, we formulate light field super-resolution (LFSR) as tensor restoration and develop a learning framework based on a two-stage restoration with 4-dimensional (4D) convolution. This allows our model to learn the features capturing the geometry information encoded in multiple adjacent views. Such geometric features vary near the occlusion regions and indicate the foreground object border. To train a feasible network, we propose a novel normalization operation based on a group of views in the feature maps, design a stage-wise loss function, and develop the multi-range training strategy to further improve the performance. Evaluations are conducted on a number of light field datasets including real-world scenes, synthetic data, and microscope light fields. The proposed method achieves superior performance and less execution time comparing with other state-of-the-art schemes.