 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Light Field Depth Estimation via Multi-view Feature Matching with Occlusion Prediction
Jan 20, 2023Depth estimation from light field (LF) images is a fundamental step for some applications. Recently, learning-based methods have achieved higher accuracy and efficiency than the traditional methods. However, it is costly to obtain sufficient depth labels for supervised training. In this paper, we propose an unsupervised framework to estimate depth from LF images. First, we design a disparity estimation network (DispNet) with a coarse-to-fine structure to predict disparity maps from different view combinations by performing multi-view feature matching to learn the correspondences more effectively. As occlusions may cause the violation of photo-consistency, we design an occlusion prediction network (OccNet) to predict the occlusion maps, which are used as the element-wise weights of photometric loss to solve the occlusion issue and assist the disparity learning. With the disparity maps estimated by multiple input combinations, we propose a disparity fusion strategy based on the estimated errors with effective occlusion handling to obtain the final disparity map. Experimental results demonstrate that our method achieves superior performance on both the dense and sparse LF images, and also has better generalization ability to the real-world LF images.
LRT: An Efficient Low-Light Restoration Transformer for Dark Light Field Images
Sep 06, 2022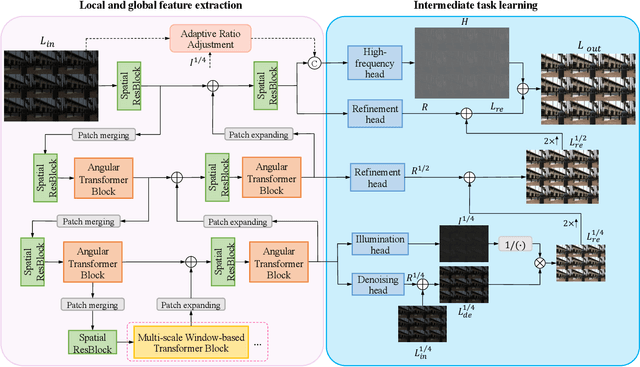

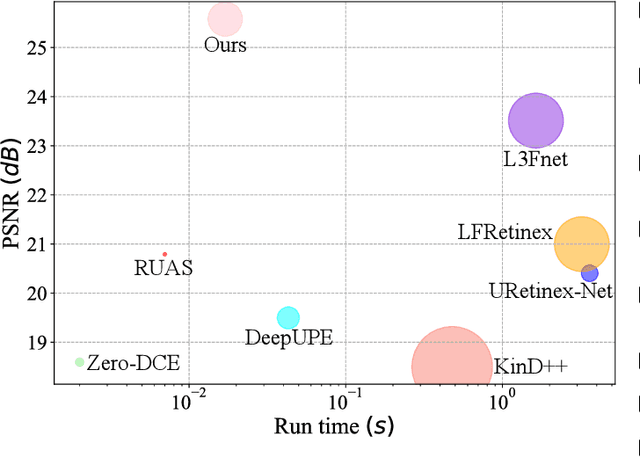

Light field (LF) images with the multi-view property have many applications, which can be severely affected by the low-light imaging. Recent learning-based methods for low-light enhancement have their own disadvantages, such as no noise suppression, complex training process and poor performance in extremely low-light conditions. Targeted on solving these deficiencies while fully utilizing the multi-view information, we propose an efficient Low-light Restoration Transformer (LRT) for LF images, with multiple heads to perform specific intermediate tasks, including denoising, luminance adjustment, refinement and detail enhancement, within a single network, achieving progressive restoration from small scale to full scale. We design an angular transformer block with a view-token scheme to model the global angular relationship efficiently, and a multi-scale window-based transformer block to encode the multi-scale local and global spatial information. To solve the problem of insufficient training data, we formulate a synthesis pipeline by simulating the major noise with the estimated noise parameters of LF camera. Experimental results demonstrate that our method can achieve superior performance on the restoration of extremely low-light and noisy LF images with high efficiency.
An Effective Image Restorer: Denoising and Luminance Adjustment for Low-photon-count Imaging
Nov 02, 2021



Imaging under photon-scarce situations introduces challenges to many applications as the captured images are with low signal-to-noise ratio and poor luminance. In this paper, we investigate the raw image restoration under low-photon-count conditions by simulating the imaging of quanta image sensor (QIS). We develop a lightweight framework, which consists of a multi-level pyramid denoising network (MPDNet) and a luminance adjustment (LA) module to achieve separate denoising and luminance enhancement. The main component of our framework is the multi-skip attention residual block (MARB), which integrates multi-scale feature fusion and attention mechanism for better feature representation. Our MPDNet adopts the idea of Laplacian pyramid to learn the small-scale noise map and larger-scale high-frequency details at different levels, and feature extractions are conducted on the multi-scale input images to encode richer contextual information. Our LA module enhances the luminance of the denoised image by estimating its illumination, which can better avoid color distortion. Extensive experimental results have demonstrated that our image restorer can achieve superior performance on the degraded images with various photon levels by suppressing noise and recovering luminance and color effectively.