 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble-Prong ConvLSTM for Spatiotemporal Occupancy Prediction in Dynamic Environments
Nov 18, 2020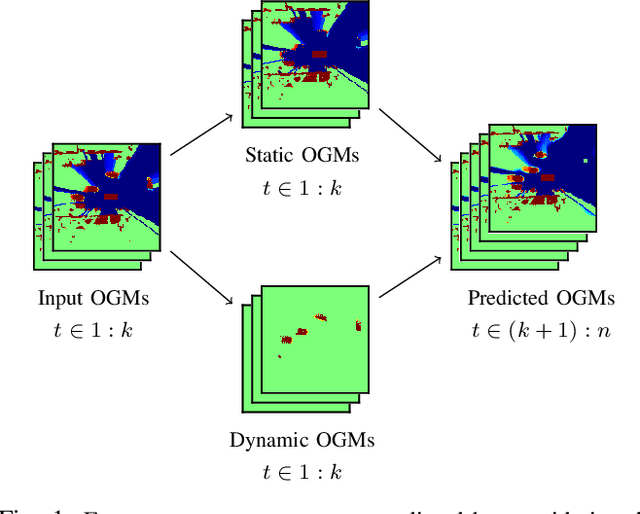
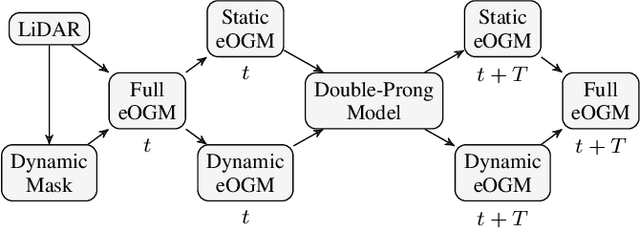
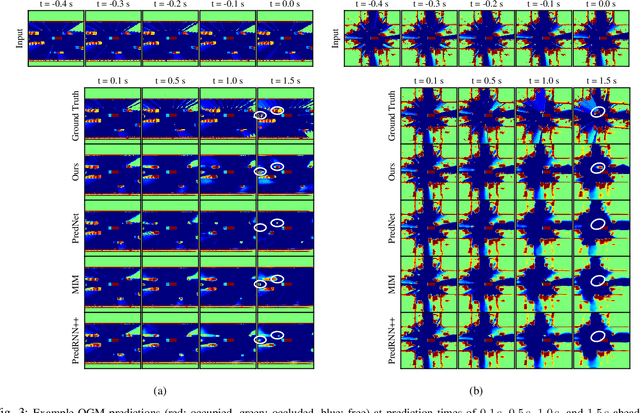
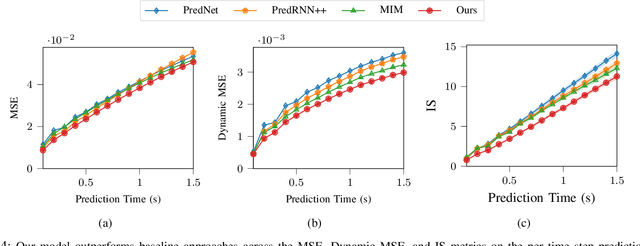
Predicting the future occupancy state of an environment is important to enable informed decisions for autonomous vehicles. Common challenges in occupancy prediction include vanishing dynamic objects and blurred predictions, especially for long prediction horizons. In this work, we propose a double-prong neural network architecture to predict the spatiotemporal evolution of the environment occupancy state. One prong is dedicated to predicting how the static environment will be observed by the moving ego vehicle. The other prong predicts how the dynamic objects in the environment will move. Experiments conducted on the real-world Waymo Open Dataset indicate that the fused output of the two prongs is capable of retaining dynamic objects and reducing blurriness in the predictions for longer time horizons than baseline models.
Reinforcement Learning for Autonomous Driving with Latent State Inference and Spatial-Temporal Relationships
Nov 09, 2020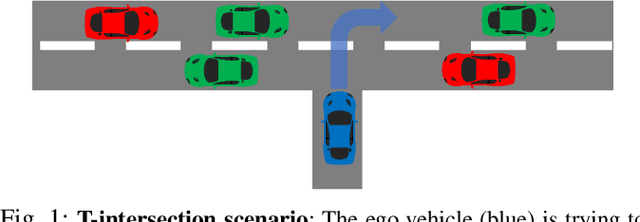
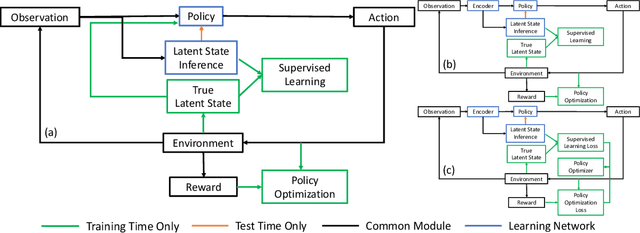
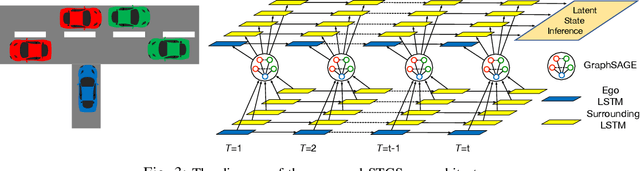
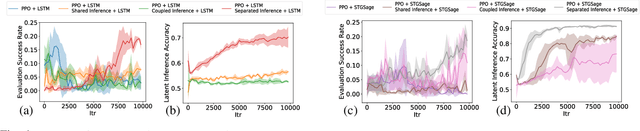
Deep reinforcement learning (DRL) provides a promising way for learning navigation in complex autonomous driving scenarios. However, identifying the subtle cues that can indicate drastically different outcomes remains an open problem with designing autonomous systems that operate in human environments. In this work, we show that explicitly inferring the latent state and encoding spatial-temporal relationships in a reinforcement learning framework can help address this difficulty. We encode prior knowledge on the latent states of other drivers through a framework that combines the reinforcement learner with a supervised learner. In addition, we model the influence passing between different vehicles through graph neural networks (GNNs). The proposed framework significantly improves performance in the context of navigating T-intersections compared with state-of-the-art baseline approaches.
Adaptive Stress Testing of Trajectory Predictions in Flight Management Systems
Nov 04, 2020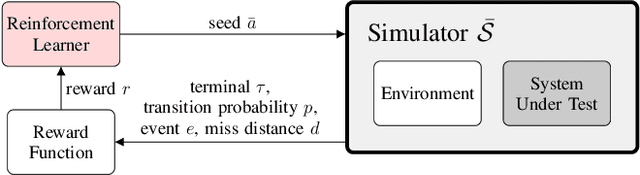
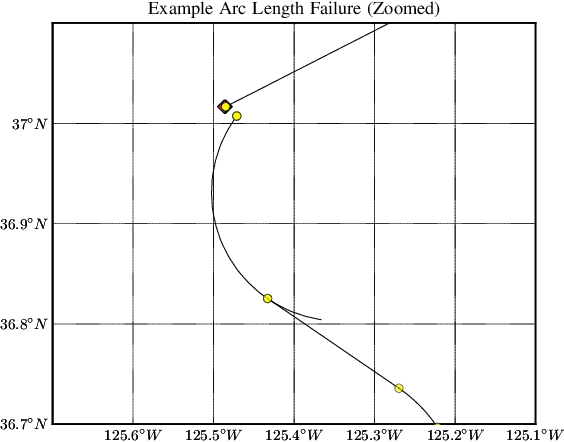
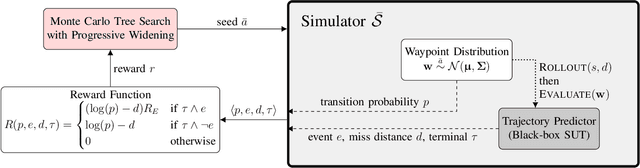
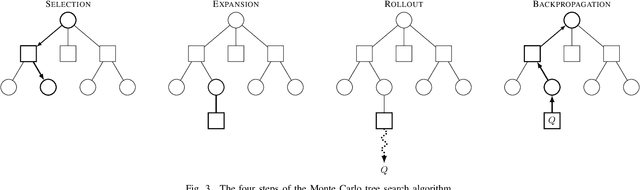
To find failure events and their likelihoods in flight-critical systems, we investigate the use of an advanced black-box stress testing approach called adaptive stress testing. We analyze a trajectory predictor from a developmental commercial flight management system which takes as input a collection of lateral waypoints and en-route environmental conditions. Our aim is to search for failure events relating to inconsistencies in the predicted lateral trajectories. The intention of this work is to find likely failures and report them back to the developers so they can address and potentially resolve shortcomings of the system before deployment. To improve search performance, this work extends the adaptive stress testing formulation to be applied more generally to sequential decision-making problems with episodic reward by collecting the state transitions during the search and evaluating at the end of the simulated rollout. We use a modified Monte Carlo tree search algorithm with progressive widening as our adversarial reinforcement learner. The performance is compared to direct Monte Carlo simulations and to the cross-entropy method as an alternative importance sampling baseline. The goal is to find potential problems otherwise not found by traditional requirements-based testing. Results indicate that our adaptive stress testing approach finds more failures and finds failures with higher likelihood relative to the baseline approaches.
Out-of-Distribution Detection for Automotive Perception
Nov 03, 2020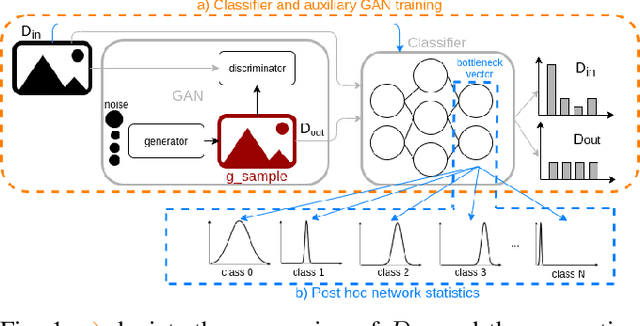
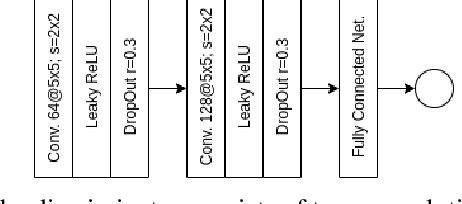
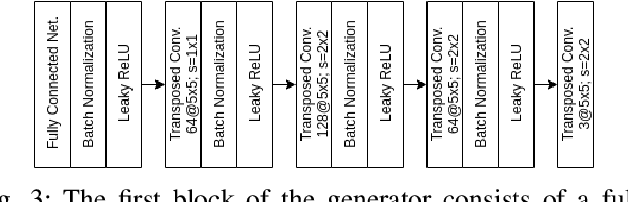
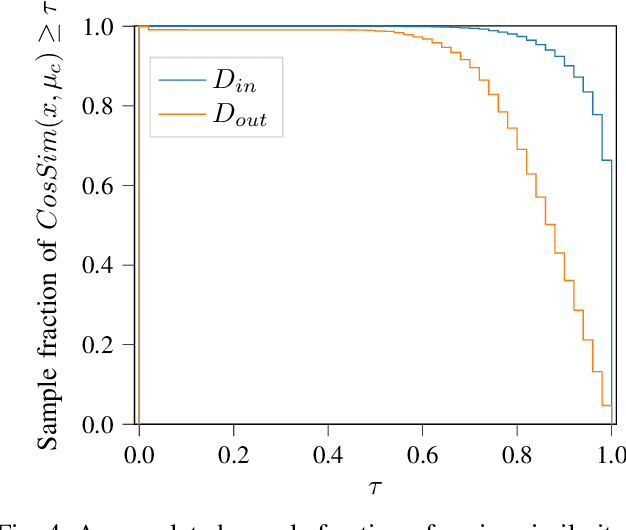
Neural networks (NNs) are widely used for object recognition tasks in autonomous driving. However, NNs can fail on input data not well represented by the training dataset, known as out-of-distribution (OOD) data. A mechanism to detect OOD samples is important in safety-critical applications, such as automotive perception, in order to trigger a safe fallback mode. NNs often rely on softmax normalization for confidence estimation, which can lead to high confidences being assigned to OOD samples, thus hindering the detection of failures. This paper presents a simple but effective method for determining whether inputs are OOD. We propose an OOD detection approach that combines auxiliary training techniques with post hoc statistics. Unlike other approaches, our proposed method does not require OOD data during training, and it does not increase the computational cost during inference. The latter property is especially important in automotive applications with limited computational resources and real-time constraints. Our proposed method outperforms state-of-the-art methods on real world automotive datasets.
Evidential Sparsification of Multimodal Latent Spaces in Conditional Variational Autoencoders
Oct 22, 2020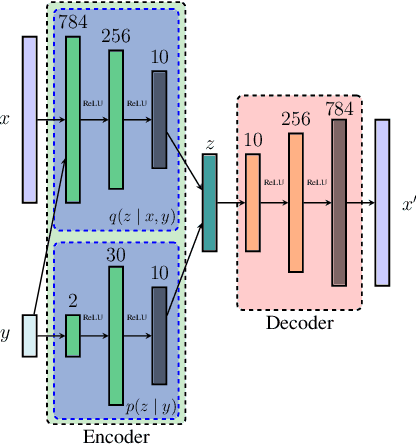
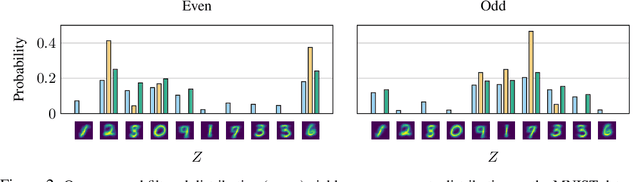
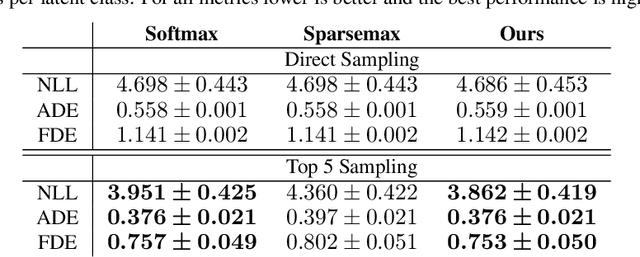
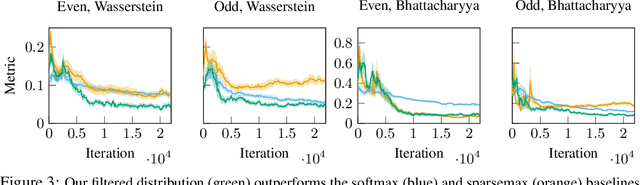
Discrete latent spaces in variational autoencoders have been shown to effectively capture the data distribution for many real-world problems such as natural language understanding, human intent prediction, and visual scene representation. However, discrete latent spaces need to be sufficiently large to capture the complexities of real-world data, rendering downstream tasks computationally challenging. For instance, performing motion planning in a high-dimensional latent representation of the environment could be intractable. We consider the problem of sparsifying the discrete latent space of a trained conditional variational autoencoder, while preserving its learned multimodality. As a post hoc latent space reduction technique, we use evidential theory to identify the latent classes that receive direct evidence from a particular input condition and filter out those that do not. Experiments on diverse tasks, such as image generation and human behavior prediction, demonstrate the effectiveness of our proposed technique at reducing the discrete latent sample space size of a model while maintaining its learned multimodality.
Runtime Safety Assurance Using Reinforcement Learning
Oct 20, 2020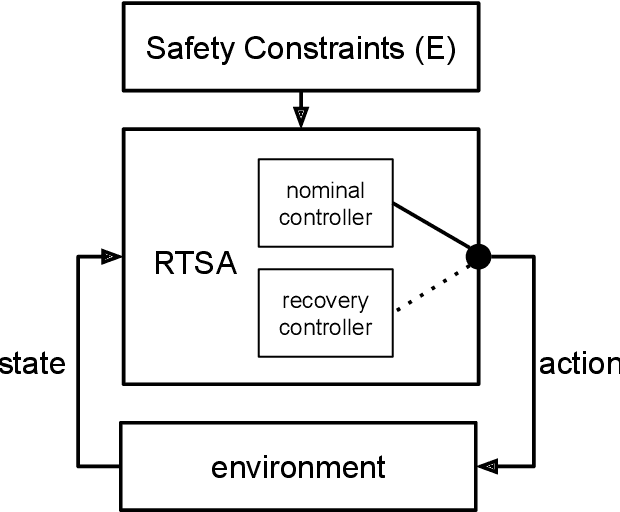
The airworthiness and safety of a non-pedigreed autopilot must be verified, but the cost to formally do so can be prohibitive. We can bypass formal verification of non-pedigreed components by incorporating Runtime Safety Assurance (RTSA) as mechanism to ensure safety. RTSA consists of a meta-controller that observes the inputs and outputs of a non-pedigreed component and verifies formally specified behavior as the system operates. When the system is triggered, a verified recovery controller is deployed. Recovery controllers are designed to be safe but very likely disruptive to the operational objective of the system, and thus RTSA systems must balance safety and efficiency. The objective of this paper is to design a meta-controller capable of identifying unsafe situations with high accuracy. High dimensional and non-linear dynamics in which modern controllers are deployed along with the black-box nature of the nominal controllers make this a difficult problem. Current approaches rely heavily on domain expertise and human engineering. We frame the design of RTSA with the Markov decision process (MDP) framework and use reinforcement learning (RL) to solve it. Our learned meta-controller consistently exhibits superior performance in our experiments compared to our baseline, human engineered approach.
Attention Augmented ConvLSTM for Environment Prediction
Oct 20, 2020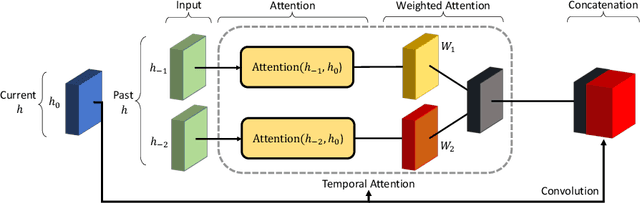
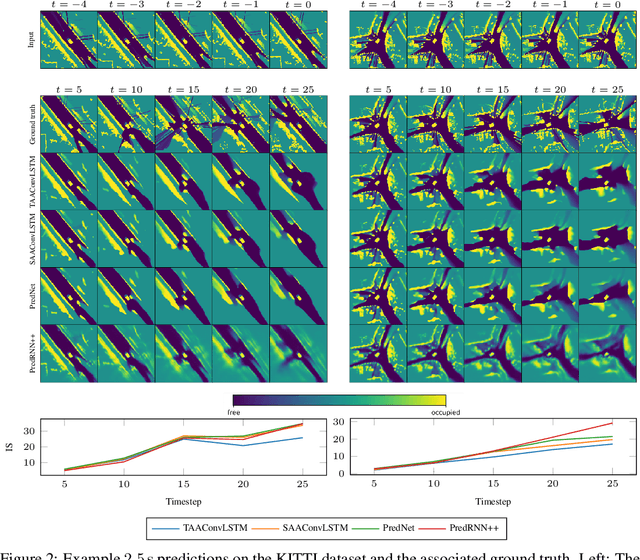

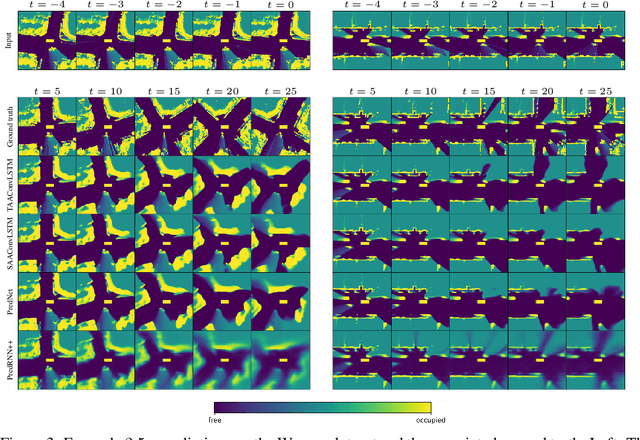
Safe and proactive planning in robotic systems generally requires accurate predictions of the environment. Prior work on environment prediction applied video frame prediction techniques to bird's-eye view environment representations, such as occupancy grids. ConvLSTM-based frameworks used previously often result in significant blurring and vanishing of moving objects, thus hindering their applicability for use in safety-critical applications. In this work, we propose two extensions to the ConvLSTM to address these issues. We present the Temporal Attention Augmented ConvLSTM (TAAConvLSTM) and Self-Attention Augmented ConvLSTM (SAAConvLSTM) frameworks for spatiotemporal occupancy prediction, and demonstrate improved performance over baseline architectures on the real-world KITTI and Waymo datasets.
Global Optimization of Objective Functions Represented by ReLU Networks
Oct 08, 2020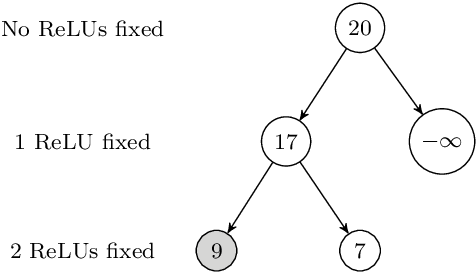
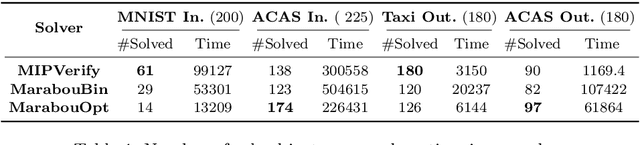
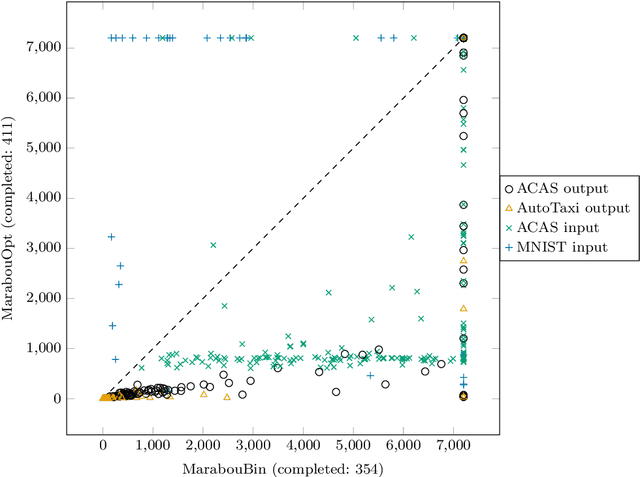
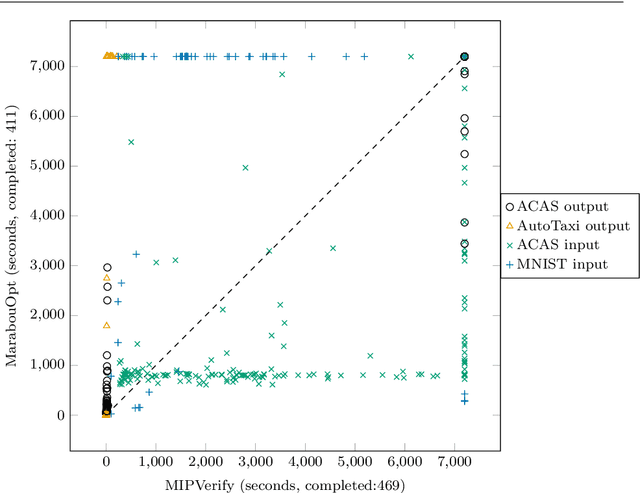
Neural networks (NN) learn complex non-convex functions, making them desirable solutions in many contexts. Applying NNs to safety-critical tasks demands formal guarantees about their behavior. Recently, a myriad of verification solutions for NNs emerged using reachability, optimization, and search based techniques. Particularly interesting are adversarial examples, which reveal ways the network can fail. They are widely generated using incomplete methods, such as local optimization, which cannot guarantee optimality. We propose strategies to extend existing verifiers to provide provably optimal adversarial examples. Naive approaches combine bisection search with an off-the-shelf verifier, resulting in many expensive calls to the verifier. Instead, our proposed approach yields tightly integrated optimizers, achieving better runtime performance. We extend Marabou, an SMT-based verifier, and compare it with the bisection based approach and MIPVerify, an optimization based verifier.
Improved POMDP Tree Search Planning with Prioritized Action Branching
Oct 07, 2020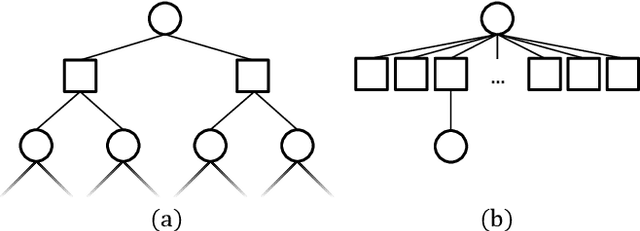
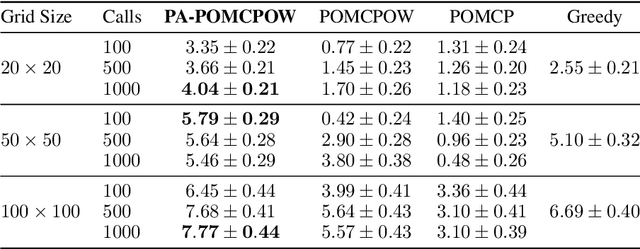
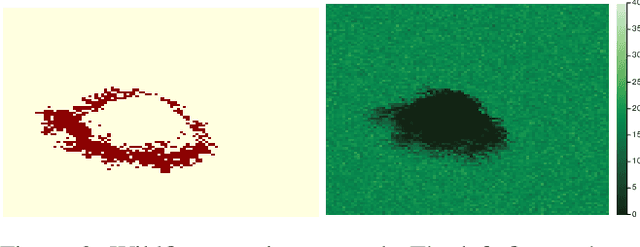
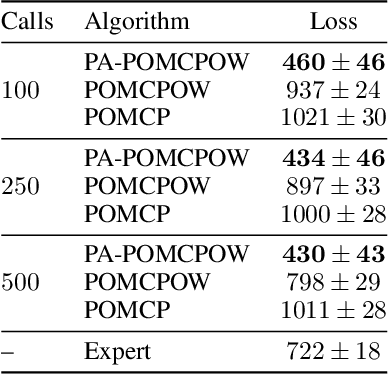
Online solvers for partially observable Markov decision processes have difficulty scaling to problems with large action spaces. This paper proposes a method called PA-POMCPOW to sample a subset of the action space that provides varying mixtures of exploitation and exploration for inclusion in a search tree. The proposed method first evaluates the action space according to a score function that is a linear combination of expected reward and expected information gain. The actions with the highest score are then added to the search tree during tree expansion. Experiments show that PA-POMCPOW is able to outperform existing state-of-the-art solvers on problems with large discrete action spaces.
Bayesian Optimized Monte Carlo Planning
Oct 07, 2020
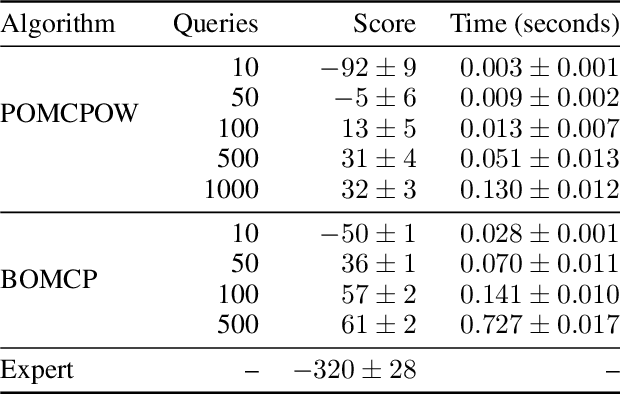
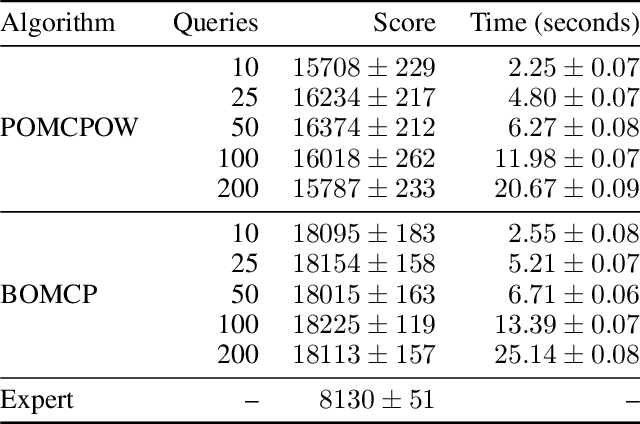
Online solvers for partially observable Markov decision processes have difficulty scaling to problems with large action spaces. Monte Carlo tree search with progressive widening attempts to improve scaling by sampling from the action space to construct a policy search tree. The performance of progressive widening search is dependent upon the action sampling policy, often requiring problem-specific samplers. In this work, we present a general method for efficient action sampling based on Bayesian optimization. The proposed method uses a Gaussian process to model a belief over the action-value function and selects the action that will maximize the expected improvement in the optimal action value. We implement the proposed approach in a new online tree search algorithm called Bayesian Optimized Monte Carlo Planning (BOMCP). Several experiments show that BOMCP is better able to scale to large action space POMDPs than existing state-of-the-art tree search solvers.