 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExistential Conversations with Large Language Models: Content, Community, and Culture
Nov 20, 2024
Contemporary conversational AI systems based on large language models (LLMs) can engage users on a wide variety of topics, including philosophy, spirituality, and religion. Suitably prompted, LLMs can be coaxed into discussing such existentially significant matters as their own putative consciousness and the role of artificial intelligence in the fate of the Cosmos. Here we examine two lengthy conversations of this type. We trace likely sources, both ancient and modern, for the extensive repertoire of images, myths, metaphors, and conceptual esoterica that the language model draws on during these conversations, and foreground the contemporary communities and cultural movements that deploy related motifs, especially in their online activity. Finally, we consider the larger societal impacts of such engagements with LLMs.
The Propensity for Density in Feed-forward Models
Oct 18, 2024Does the process of training a neural network to solve a task tend to use all of the available weights even when the task could be solved with fewer weights? To address this question we study the effects of pruning fully connected, convolutional and residual models while varying their widths. We find that the proportion of weights that can be pruned without degrading performance is largely invariant to model size. Increasing the width of a model has little effect on the density of the pruned model relative to the increase in absolute size of the pruned network. In particular, we find substantial prunability across a large range of model sizes, where our biggest model is 50 times as wide as our smallest model. We explore three hypotheses that could explain these findings.
A Mechanism-Based Approach to Mitigating Harms from Persuasive Generative AI
Apr 23, 2024



Recent generative AI systems have demonstrated more advanced persuasive capabilities and are increasingly permeating areas of life where they can influence decision-making. Generative AI presents a new risk profile of persuasion due the opportunity for reciprocal exchange and prolonged interactions. This has led to growing concerns about harms from AI persuasion and how they can be mitigated, highlighting the need for a systematic study of AI persuasion. The current definitions of AI persuasion are unclear and related harms are insufficiently studied. Existing harm mitigation approaches prioritise harms from the outcome of persuasion over harms from the process of persuasion. In this paper, we lay the groundwork for the systematic study of AI persuasion. We first put forward definitions of persuasive generative AI. We distinguish between rationally persuasive generative AI, which relies on providing relevant facts, sound reasoning, or other forms of trustworthy evidence, and manipulative generative AI, which relies on taking advantage of cognitive biases and heuristics or misrepresenting information. We also put forward a map of harms from AI persuasion, including definitions and examples of economic, physical, environmental, psychological, sociocultural, political, privacy, and autonomy harm. We then introduce a map of mechanisms that contribute to harmful persuasion. Lastly, we provide an overview of approaches that can be used to mitigate against process harms of persuasion, including prompt engineering for manipulation classification and red teaming. Future work will operationalise these mitigations and study the interaction between different types of mechanisms of persuasion.
Simulacra as Conscious Exotica
Feb 19, 2024The advent of conversational agents with increasingly human-like behaviour throws old philosophical questions into new light. Does it, or could it, ever make sense to speak of AI agents built out of generative language models in terms of consciousness, given that they are "mere" simulacra of human behaviour, and that what they do can be seen as "merely" role play? Drawing on the later writings of Wittgenstein, this paper attempts to tackle this question while avoiding the pitfalls of dualistic thinking.
Improving Activation Steering in Language Models with Mean-Centring
Dec 06, 2023



Recent work in activation steering has demonstrated the potential to better control the outputs of Large Language Models (LLMs), but it involves finding steering vectors. This is difficult because engineers do not typically know how features are represented in these models. We seek to address this issue by applying the idea of mean-centring to steering vectors. We find that taking the average of activations associated with a target dataset, and then subtracting the mean of all training activations, results in effective steering vectors. We test this method on a variety of models on natural language tasks by steering away from generating toxic text, and steering the completion of a story towards a target genre. We also apply mean-centring to extract function vectors, more effectively triggering the execution of a range of natural language tasks by a significant margin (compared to previous baselines). This suggests that mean-centring can be used to easily improve the effectiveness of activation steering in a wide range of contexts.
Evaluating Large Language Model Creativity from a Literary Perspective
Nov 30, 2023This paper assesses the potential for large language models (LLMs) to serve as assistive tools in the creative writing process, by means of a single, in-depth case study. In the course of the study, we develop interactive and multi-voice prompting strategies that interleave background descriptions (scene setting, plot elements), instructions that guide composition, samples of text in the target style, and critical discussion of the given samples. We qualitatively evaluate the results from a literary critical perspective, as well as from the standpoint of computational creativity (a sub-field of artificial intelligence). Our findings lend support to the view that the sophistication of the results that can be achieved with an LLM mirrors the sophistication of the prompting.
Schema-learning and rebinding as mechanisms of in-context learning and emergence
Jun 16, 2023



In-context learning (ICL) is one of the most powerful and most unexpected capabilities to emerge in recent transformer-based large language models (LLMs). Yet the mechanisms that underlie it are poorly understood. In this paper, we demonstrate that comparable ICL capabilities can be acquired by an alternative sequence prediction learning method using clone-structured causal graphs (CSCGs). Moreover, a key property of CSCGs is that, unlike transformer-based LLMs, they are {\em interpretable}, which considerably simplifies the task of explaining how ICL works. Specifically, we show that it uses a combination of (a) learning template (schema) circuits for pattern completion, (b) retrieving relevant templates in a context-sensitive manner, and (c) rebinding of novel tokens to appropriate slots in the templates. We go on to marshall evidence for the hypothesis that similar mechanisms underlie ICL in LLMs. For example, we find that, with CSCGs as with LLMs, different capabilities emerge at different levels of overparameterization, suggesting that overparameterization helps in learning more complex template (schema) circuits. By showing how ICL can be achieved with small models and datasets, we open up a path to novel architectures, and take a vital step towards a more general understanding of the mechanics behind this important capability.
Role-Play with Large Language Models
May 25, 2023As dialogue agents become increasingly human-like in their performance, it is imperative that we develop effective ways to describe their behaviour in high-level terms without falling into the trap of anthropomorphism. In this paper, we foreground the concept of role-play. Casting dialogue agent behaviour in terms of role-play allows us to draw on familiar folk psychological terms, without ascribing human characteristics to language models they in fact lack. Two important cases of dialogue agent behaviour are addressed this way, namely (apparent) deception and (apparent) self-awareness.
Talking About Large Language Models
Dec 11, 2022Thanks to rapid progress in artificial intelligence, we have entered an era when technology and philosophy intersect in interesting ways. Sitting squarely at the centre of this intersection are large language models (LLMs). The more adept LLMs become at mimicking human language, the more vulnerable we become to anthropomorphism, to seeing the systems in which they are embedded as more human-like than they really are. This trend is amplified by the natural tendency to use philosophically loaded terms, such as "knows", "believes", and "thinks", when describing these systems. To mitigate this trend, this paper advocates the practice of repeatedly stepping back to remind ourselves of how LLMs, and the systems of which they form a part, actually work. The hope is that increased scientific precision will encourage more philosophical nuance in the discourse around artificial intelligence, both within the field and in the public sphere.
Faithful Reasoning Using Large Language Models
Aug 30, 2022
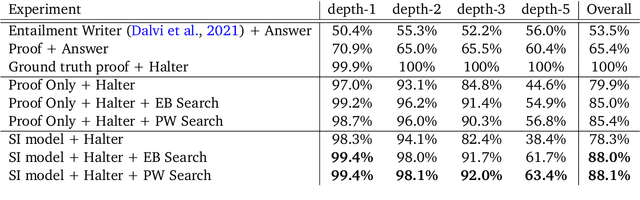
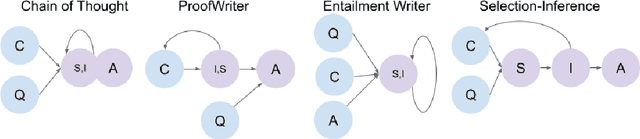

Although contemporary large language models (LMs) demonstrate impressive question-answering capabilities, their answers are typically the product of a single call to the model. This entails an unwelcome degree of opacity and compromises performance, especially on problems that are inherently multi-step. To address these limitations, we show how LMs can be made to perform faithful multi-step reasoning via a process whose causal structure mirrors the underlying logical structure of the problem. Our approach works by chaining together reasoning steps, where each step results from calls to two fine-tuned LMs, one for selection and one for inference, to produce a valid reasoning trace. Our method carries out a beam search through the space of reasoning traces to improve reasoning quality. We demonstrate the effectiveness of our model on multi-step logical deduction and scientific question-answering, showing that it outperforms baselines on final answer accuracy, and generates humanly interpretable reasoning traces whose validity can be checked by the user.