Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignNet: Unsupervised Entity Alignment
Paper and Code
Jul 21, 2020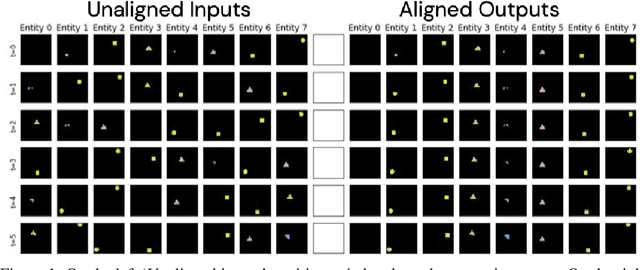

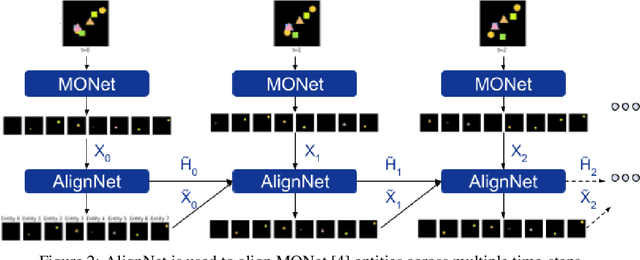
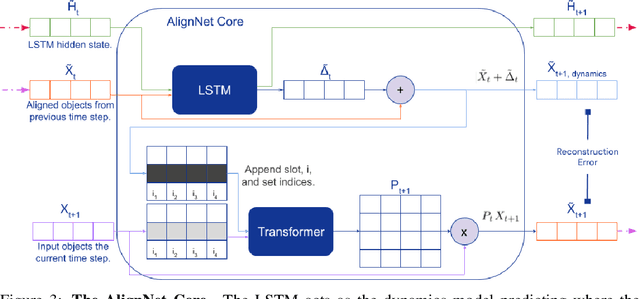
Recently developed deep learning models are able to learn to segment scenes into component objects without supervision. This opens many new and exciting avenues of research, allowing agents to take objects (or entities) as inputs, rather that pixels. Unfortunately, while these models provide excellent segmentation of a single frame, they do not keep track of how objects segmented at one time-step correspond (or align) to those at a later time-step. The alignment (or correspondence) problem has impeded progress towards using object representations in downstream tasks. In this paper we take steps towards solving the alignment problem, presenting the AlignNet, an unsupervised alignment module.
View paper on