 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCORPGEN: Simulating Corporate Environments with Autonomous Digital Employees in Multi-Horizon Task Environments
Feb 15, 2026Long-horizon reasoning is a key challenge for autonomous agents, yet existing benchmarks evaluate agents on single tasks in isolation. Real organizational work requires managing many concurrent long-horizon tasks with interleaving, dependencies, and reprioritization. We introduce Multi-Horizon Task Environments (MHTEs): a distinct problem class requiring coherent execution across dozens of interleaved tasks (45+, 500-1500+ steps) within persistent execution contexts spanning hours. We identify four failure modes that cause baseline CUAs to degrade from 16.7% to 8.7% completion as load scales 25% to 100%, a pattern consistent across three independent implementations. These failure modes are context saturation (O(N) vs O(1) growth), memory interference, dependency complexity (DAGs vs. chains), and reprioritization overhead. We present CorpGen, an architecture-agnostic framework addressing these failures via hierarchical planning for multi-horizon goal alignment, sub-agent isolation preventing cross-task contamination, tiered memory (working, structured, semantic), and adaptive summarization. CorpGen simulates corporate environments through digital employees with persistent identities and realistic schedules. Across three CUA backends (UFO2, OpenAI CUA, hierarchical) on OSWorld Office, CorpGen achieves up to 3.5x improvement over baselines (15.2% vs 4.3%) with stable performance under increasing load, confirming that gains stem from architectural mechanisms rather than specific CUA implementations. Ablation studies show experiential learning provides the largest gains.
Auto-Eval Judge: Towards a General Agentic Framework for Task Completion Evaluation
Aug 07, 2025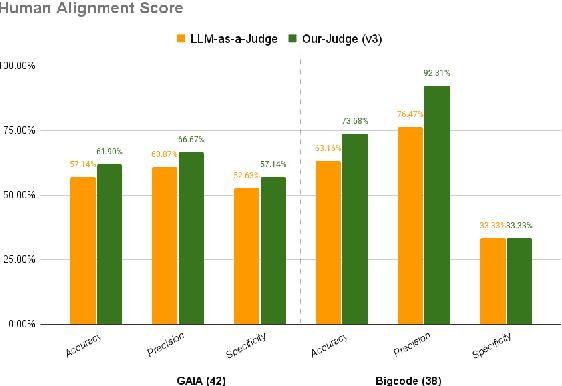
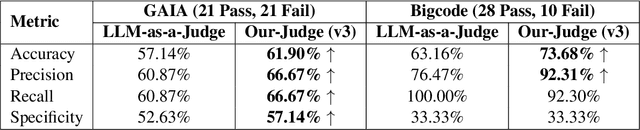
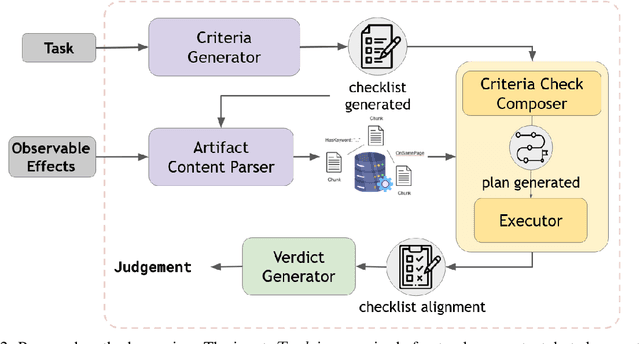
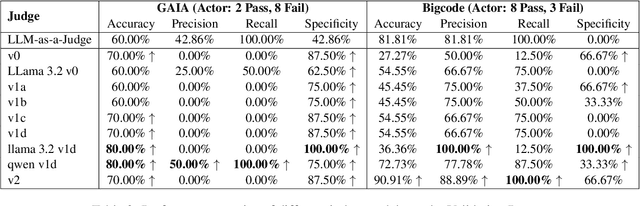
The increasing adoption of foundation models as agents across diverse domains necessitates a robust evaluation framework. Current methods, such as LLM-as-a-Judge, focus only on final outputs, overlooking the step-by-step reasoning that drives agentic decision-making. Meanwhile, existing Agent-as-a-Judge systems, where one agent evaluates another's task completion, are typically designed for narrow, domain-specific settings. To address this gap, we propose a generalizable, modular framework for evaluating agent task completion independent of the task domain. The framework emulates human-like evaluation by decomposing tasks into sub-tasks and validating each step using available information, such as the agent's output and reasoning. Each module contributes to a specific aspect of the evaluation process, and their outputs are aggregated to produce a final verdict on task completion. We validate our framework by evaluating the Magentic-One Actor Agent on two benchmarks, GAIA and BigCodeBench. Our Judge Agent predicts task success with closer agreement to human evaluations, achieving 4.76% and 10.52% higher alignment accuracy, respectively, compared to the GPT-4o based LLM-as-a-Judge baseline. This demonstrates the potential of our proposed general-purpose evaluation framework.